基于模式识别的企业财务风险预测方法
2018-09-11青岛大学会计学系山东青岛266071
(青岛大学会计学系山东青岛266071)
一、引言
企业的财务风险主要是指企业在经营、筹资、投资方面面临的不确定性,具体指企业财务结构不合理、融资不当使公司可能丧失偿债能力而导致投资者预期收益下降的风险(黄婉婷,2013)。企业财务风险控制是财务管理的重要内容,加强对企业财务风险的识别,为决策者、管理者和投资者提供及时有效的财务信息,保障各方的利益具有重要意义。对企业财务风险的预测的研究方法,是根据企业的财务或非财务的指标,建立各种风险预测模型。主要有基于统计理论的线性回归模型,如Z-Score财务风险预警模型(严碧红、马广奇,2011);以人工神经网络为代表的非线性模型,研究文献很多,这些非线性模型实际上是一种基于模式识别的判别方法。本文以模式识别理论为指导,来建立财务风险预测的模式识别模型。依据构建模式识别系统的方法,研究企业财务风险分类、风险特征提取、模式分类器的设计、分类器训练和测试,并用21家化肥类上市公司最近4年的财务数据进行实证分析。
二、企业财务风险的模式识别系统
(一)模式识别理论及其在企业财务风险预测中的应用
模式识别诞生于上世纪20年代,随着计算机技术的发展,在60年代形成的一门人工智能学科。它对事物的时间或空间分布信息进行分析,根据事物的样本特征对样本进行分类。模式识别技术在经济领域应用例子众多,如对CPI代表规格品价格走势形态中的平稳走势的识别 (王浩,2014),基于BP神经网络的财务风险预警系统(何珊,2016)等。模式识别研究方法主要有统计模式识别、结构模式识别、模糊模式识别和人工神经网络。这些方法的理论基础不同,各有特点。其中,人工神经网络是一种应用大脑突触联结的结构进行信息处理的数学运算模型,由大量的节点(神经元)和彼此的相互连接构成。每个节点代表一种特定的输出函数,每两个节点间的连接代表一个通过该连接信号的权重。网络的输出则依连接方式、权重值和激励函数的不同而不同。人工神经网络模型中应用最多也是最成功的当属以采用BP学习算法的多层感知器(以下简称BP神经网络)为代表,其方法是将样本空间分为训练集和测试集两个集合,采用有监督的学习方式用训练集样本对BP神经网络进行训练,用测试集样本对BP神经网络的分类效果进行评价。BP网络具有高度的非线性映射能力,而且它不要求大样本训练集空间。本文采用BP神经网络构造财务风险预测的模式识别系统的分类器。
(二)财务风险预测的模式识别系统的组成
基于模式识别财务风险预测的模式识别系统主要由三部分组成:数据获取和预处理,特征提取和选择,分类决策,如图1所示。

图1 企业财务风险预测的模式识别系统
1.数据获取和预处理。企业的财务风险的发生是一个渐进的发展过程,企业的财务状况在不加以控制的情况下会由轻度财务危机转化成重度财务危机。财务状况发生变化前,当期财务报表中的指标会提前出现异动,因此,可以选择企业的资产负债表、利润表、现金流量表中的若干指标数据作为系统的输入值,来预测企业未来财务状况的变化。
2.特征提取和选择。选择每股基本指标、成长能力指标、盈利能力和质量指标、运营能力指标和财务风险指标等财务数据,作为表示企业财务风险的特征分量。由于这些财务指标间有的相互重叠,有的有较强的相关性,因此,有必要对样本的特征向量进行降维,尽量用少的特征数据来反映企业的财务状况。这样既可简化BP神经网络的结构,也有利于加快BP神经网络设计过程中的输出误差的收敛速度。
对特征向量进行降维处理的方法很多,本文采用因子分析法。它是多元统计分析中常用的一种方法,通过研究众多变量之间的内部依赖关系,用少数几个变量表示观测数据基本结构,来反映原来众多变量的主要信息。
3.分类决策。BP神经网络由三部分组成:一层为神经元组成的输入层,输入层神经元的数量由特征向量的维数决定;一层(或多层)为计算节点的隐藏层;一层为输出层,输出层数量由企业风险类别数决定。
三、企业财务风险预测的模式识别系统实现方法与步骤
(一)企业财务风险新分类方法
侯芝芳(2014)以上市企业是否被ST作为财务发生危机的标志,而作为对比,将同类型的非ST企业的财务状况视为正常;刘君力、刘吉成(2012)用EVA(经济增加值)指标是否大于0作为区分财务状况正常与危机的标准。为了反映企业财务风险的变化趋势,本文根据企业当期和前期净利润的对比,将公司财务风险划分为持续盈利、亏转盈、盈转亏和持续亏损四类,这样能更好地对企业财务风险进行预测。
(二)企业财务风险特征指标和处理方法
根据上市公司年报公布的内容,选择的财务风险指标体系如表1所示。这20项指标具有代表性和良好的预测性能,可以充分反映企业的财务状况。
(三)特征处理方法
采用因子分析法对样本的特征向量进行降维处理。因子分析的步骤如下:(1)选择分析的变量。原始变量之间有较强的相关性是因子分析的前提条件。(2)计算原始变量的相关系数矩阵。相关系数矩阵是估计因子结构的基础。(3)提取公因子。确定因子求解的方法和因子个数,目的是计算因子的载荷矩阵。因子求解的方法主要有主成分分析法、主因子法和最大似然估计法。因子个数的确定根据因子方差的大小确定,取方差大于1(或特征值大于1)的那些因子。(4)因子旋转。对因子的载荷矩阵进行正交变换,求取旋转因子载荷矩阵,目的是辅助理解提取因子的实际意义。(5)计算因子得分。本文采用因子得分作为财务风险预测特征向量的分量。

表1 上市公司财务风险研究相关指标体系表
(四)分类器的结构设计与实现步骤。
本文采用三层BP神经网络作为模式识别的分类器。输入层节点数是财务风险预测的特征向量的维数,输出节点数有四个,分别对应上文中的四类财务风险;采用经验公式间的常数,n、m 分别为输入输出节点数,确定隐含层节点的数量。采用BP神经网络实现分类器,主要有四步:样本特征数据归一化处理;前馈网络创建函数;训练一个神经网络;使用网络进行仿真。
四、实验分析
(一)数据收集
本文依据上市公司的行业划分,选取了沪深两地上市化肥类公司作为研究样本,公司分布在主板、中小板和创业板。化肥类上市公司,其产品类别、资本结构、经营方式相似,面临着相同的宏观和微观经济形势,化肥行业属于周期性行业,盈利水平波动比较大,因此,非常适合用来做财务风险预警研究。
根据东方财富网发布的 2013、2014、2015、2016年度上市化肥公司的财务报告,剔除在报告期内被ST的公司,选择藏格控股、中旗股份、鲁北化工、华鲁恒生、史丹利、司尔特、新洋丰、芭田股份、金正大、红太阳、澄星股份、云图控股、鲁西化工、华昌化工、东凌国际、湖北宜化、云天化、六国化工、泸天化、阳煤化工、四川美丰共21家化肥类上市公司的财务数据,进行整理后内容包括表1中所列的19项财务指标。
以2013年和2014年度的数据作为训练集,以2015年度数据作为测试集,具体财务风险的情况如表2所示。
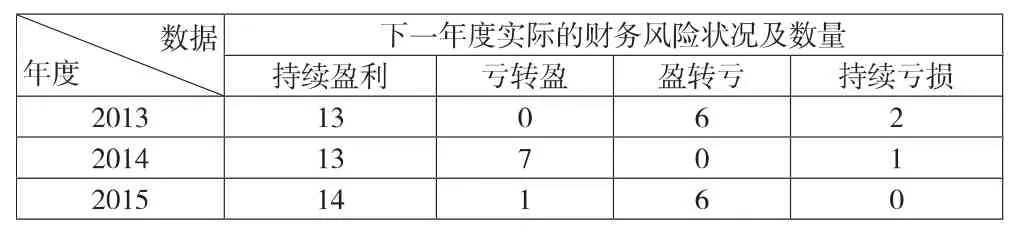
表2 21家上市化肥类公司实际财务风险状况表
对表1中所列的19项财务指标,按照财务风险类别的持续盈利、亏转盈、盈转亏和持续亏损分别进行描述性统计,各项指标的平均值如表3所示。通过对比分析,可以看出,持续盈利的企业样本的大多数财务指标均优于其他风险类型样本企业的指标。如,基本每股收益均值为0.5531元,而其他三类分别为-0.8395元、0.1639元、-0.2476元;净资产收益率、总资产收益率、毛利率和净利率分别为8.9988%、5.0488%、16.7955%和5.1208%,相对于其他三类风险类型企业优势明显。说明能够持续盈利的企业,当期的盈利能力也是比较高的。对比样本企业的资产负债率,持续盈利企业平均资产负债率仅为50%,而亏转盈、盈转亏和持续亏损的企业样本的平均资产负债率分别为77%、70.8%和75%,说明化肥类企业的财务风险与资产负债率呈负相关。表3数据表明,本文所选的企业财务指标对判别企业的财务风险是有效的。但是,企业的财务风险形成的原因是复杂的,无法直观地进行判断,这是开展企业财务风险预测方法研究的动因。
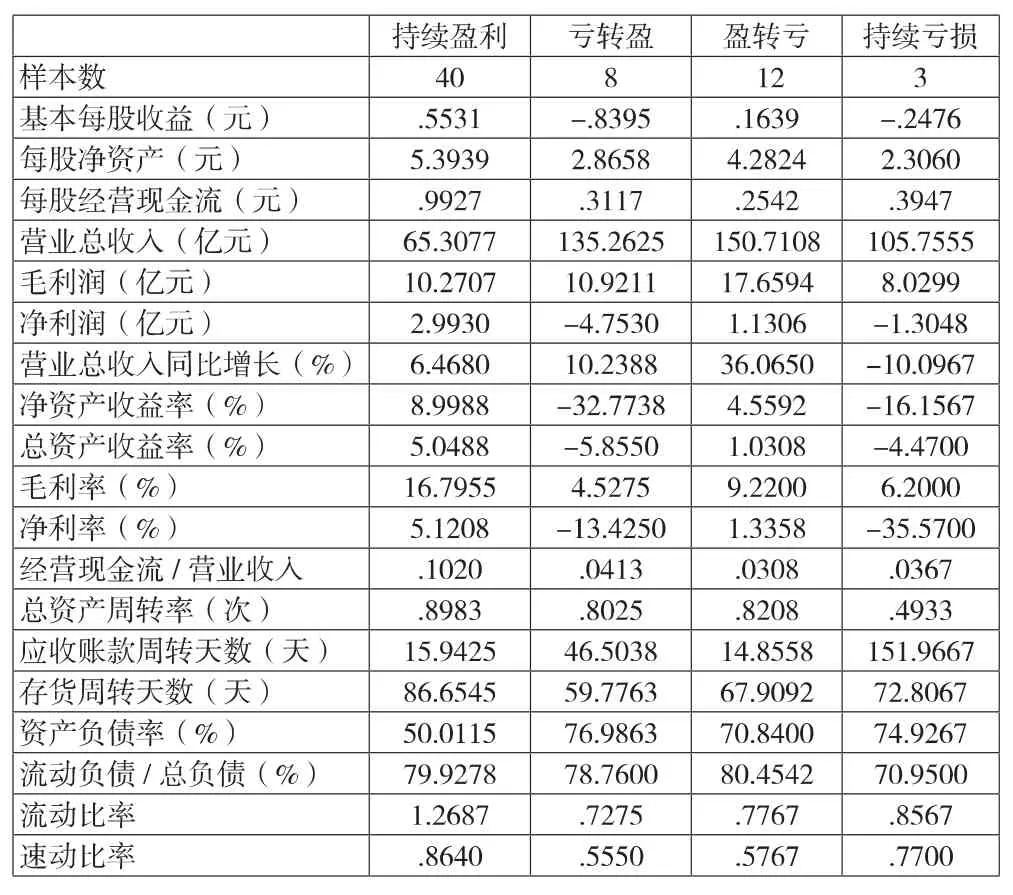
表3 按企业财务风险类别统计的财务指标平均值表
(二)特征提取
由于2013—2015年度化肥行业的财务数据变化比较大,本文分年度对这21家上市公司的财务数据进行因子分析。以下是使用SPSS 19.0的“因子分析”功能对2013年度财务数据进行因子分析的过程及结果。
1.KMO和Bartlett的球形度检验。结果显示KMO值为0.733,表明很适合因子分析,Bartlett的球形度检验的显著性Sig值为0.000,说明数据来自正态分布总体,适合进一步分析。
2.主成分因子的提取。表4显示,分析2013年度21个样本的19项指标,提取10个主成分因子,其累计方差贡献率达到97.294%,因此,可将样本的特征向量由19维压缩到10维。表5为成分得分系数矩阵,记为A,A的维数为19×10,原始数据样本集用矩阵X表示,X的维数为21×19,提取的特征数据样本集用矩阵Y表示,则Y=X·A,Y的维数为20×10。

表4 解释的总方差

表5 成分得分系数矩阵
用同样的方法,对2014年和2015年度的样本数据进行处理,2013年和2014年的数据组成训练集,存在文本文件trainData.txt中,2015年的数据组成测试集,存在文本文件testData.txt中。
(三)企业财务风险识别系统的Matlab编程实现及结果分析
本文企业财务风险分为 4类(用 1、2、3、4 表示),财务风险的特征向量维数为10。采用三层BP网络来实现系统的构建、训练和测试,输入层有10个节点,根据经验,中间层有10个节点,输出层有4个节点。训练数据在trainData.txt文件中,含42个样本,测试数据在testData.txt中,含21个样本。系统的Matlab 7.0编程实现代码如下:


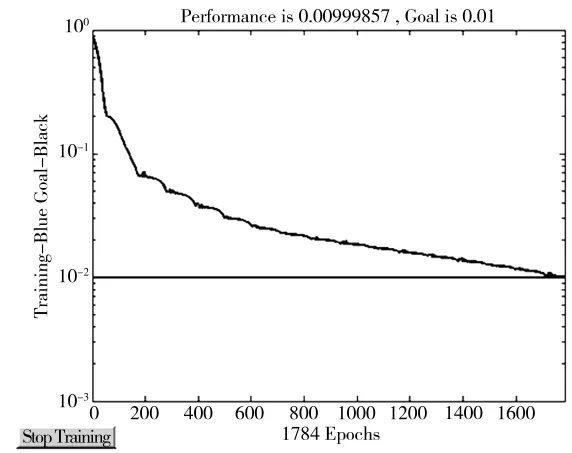
图2 神经网络的训练收敛过程图
图2为神经网络的训练收敛过程图,测试的21个样本中,18个识别正确,识别率是85.714%,详细数据见表6财务风险状况预测结果表。其中,预测错误的样本分别为将六国化工和四川美丰的“盈转亏”都错判成“持续盈利”,将中旗股份的“持续盈利”错判成“盈转亏”。表6显示,本文模型对盈利预测的准确度较高,大于对亏损预测的准确度。这是由于本文只研究了21家化肥类上市公司的数据,总体训练样本数较少,亏损的样本数更是缺乏,影响了系统的性能。尽管如此,用2015年化肥行业的财务数据预测该行业2016年度盈亏的正确率达到了85.714%,基本满足了利用前两年的公司财务数据,对下一年度公司财务风险预测的需要,证明了本文方法的可行性和有效性。
基于模式识别的企业财务风险识别方法具有普遍的适用性,只需要选择其他行业的财务数据构建系统的训练集和测试集,就可以用文中的Matlab程序进行运算,研究相应行业的财务风险问题。

表6 财务风险状况预测结果表
五、结论
本文基于模式识别理论研究了企业财务风险的预测方法。将企业财务风险类别划分为“持续盈利”“亏转盈”“盈转亏”和“持续亏损”四类,相比将企业财务风险类别划分为“正常”和“ST”两类,更加科学,更加具有指导意义。对21家化肥类上市公司的三年财务数据进行因子分析以降低企业财务风险特征向量的维度,从而简化了企业财务风险识别模型的复杂度;用BP神经网络建立了企业财务风险识别模型,并用MATLAB编程实现了系统分类器的设计和训练。实验结果表明,利用企业前期和当期的财务数据,可较为客观和准确地预测企业下一财务报告期可能的财务风险。本文模型具有较高的财务风险预测准确率,可有效避免由于人工预测的主观性造成的预测风险偏差。
进一步提高企业财务风险识别系统的准确度,可从以下两个方面进行:一是加强对企业财务风险特征研究。本文只采用了企业的财务数据描述企业的财务风险,但是,企业的非财务数据,如资产规模、反映公司股权结构的第一大股东持股比例等,都会影响公司的财务状况,引入这些非财务数据,研究企业的财务风险特征,可进一步提高系统的识别准确度。二是收集更多的训练样本,用大样本数据训练BP神经网络,提高训练精度。
