一种基于卷积自编码器的文档聚类模型
2018-09-10冯永强李亚军
冯永强 李亚军


摘 要:文档聚类是将文档集自动归成若干类别的过程,是对文本信息进行分类的有效方式。为了解决半结构化的文本数据转化为结构化数据时出现的数据高维性问题,本文提出了一种卷积自编码器的文档聚类模型CASC,利用卷积神经网络和自编码器的特征提取能力,在尽可能保留原始数据内部结构的同时,将其嵌入到低維潜在空间,然后使用谱聚类算法进行聚类。实验表明,CASC模型在保证聚类准确率不降低的前提下减少了算法运行时间,同时也降低了算法时间复杂度。
关键词:聚类;卷积神经网络;自编码器;无监督模型
中图分类号:TP391;TN911.2 文献标识码:A 文章编号:2096-4706(2018)02-0012-04
A Document Clustering Model Based on Convolutional Autoencoder
FENG Yongqiang1,LI Yajun2
(1.Tianjin Haihe Dairy Company,Tianjin 300410,China;2. Tianjin University of Science and Technology College of Computer Science and Information Engineering,Tianjin 300457,China)
Abstract:Document clustering is a process of automatically categorizing document sets into several categories and is an effective means of organizing textual information. Aiming at the problem of high dimensionality of data when converting semi-structured text data into structured data,this paper proposes a document clustering model called Convolutional Self-Encoder (CASC),which uses convolutional neural network and self-encoder feature extraction capabilities,the best possible to retain the internal structure of the original data while embedded in low-dimensional potential space,and then use the spectral clustering algorithm for clustering. Experiments show that the CASC algorithm can reduce the algorithm running time and reduce the time complexity of the algorithm without reducing the accuracy of clustering.
Keywords:clustering;convolution neural network;autoencoder;unsupervised model
引 言
近年来,随着时代的进步与发展,互联网的普及程度越来越高,人们可以在互联网上接触到大量的信息并发表自己的观点,其中绝大部分信息都表现为文本形式,并且存在大量噪声,因此,如何才能从大量的文本信息中快速提取出潜在有用的和用户感兴趣的内容成为一个需要解决的问题。
目前互联网上的许多文本数据,如新闻、用户发布的微博和人们在论坛上发表的言论等,都没有明显的类别信息,是一种无标签数据。因此,如何将这些文本数据自动归成若干类别成为自然语言处理领域的一个研究热点。
文档聚类是将无标签的文档集按照内容相似性进行自动归类的过程,文本聚类的目标是将文档集合理划分为若干类,使得同一类中的文档相似度尽可能地大,而不同类之间的文档相似度尽可能地小[1,2]。
在对文档集进行聚类之前,需要使用某种算法将文档表示成计算机可以识别的向量,如词袋模型[3]、TF-IDF算法[4]、word2vec算法[5,6]等。Johnson等人提出基于层次的层次聚类法[7],该方法通过某种相似性来度量计算节点之间的相似性,并按照相似度降序排列,逐步将各个节点重新连接起来。
随后Hartigan等人提出基于划分的k-means算法[8],以空间中K个点为中心进行聚类,然后选择距离中心点最近的点进行归类,之后又出现许多方法对其进行改进,例如k-means++算法[9]、Fuzzy C-means算法[10]等。
而后又有人提出基于密度的DBSCAN算法[11]和基于图论的谱聚类算法[12]等。但是由于表示后的文档向量的高维性,既导致了维数灾难现象的发生,也掩盖了数据的内在特性,从而使得上述算法性能较差。
随着神经网络的发展和深度学习技术的兴起,使用神经网络如自编码器来学习数据的内在特征成为一种新的可能,且可以将数据嵌入到低维潜在空间中,能一定程度上改善数据高维性问题,其中卷积神经网络(Convolutional Neural Networks,CNN)[13]可以利用其卷积和池化操作学习到强鲁棒性特征。
针对文本数据高维性问题,本文提出一种基于卷积神经网络的文档聚类算法CASC(Convolutional Autoencoder Spectral Clustering),即首先使用word2vec算法将文档表示为高维向量,然后利用卷积神经网络和自编码器的特征提取能力,将文档向量嵌入到低维潜在空间中,最后使用谱聚类算法将得到的文档低维表示进行聚类,从而避免数据高维性带来的诸多问题。
1 卷积自编码器介绍
自编码器是一种前馈神经网络,最简单的自编码器由三层神经网络构成:输入层、隐藏层和输出层,其中输入层到隐藏层称为编码器部分,隐藏层到输出层称为解码器部分。编码器的输入节点个数和解码器的输出节点个数相等,目的是通过训练学习到一个恒等映射,使输入尽可能和输出相等,从而找出原始数据之间潜在的隐藏关联。假设原始数据用x={x1,x2,…,xm}表示,解码器的输出用表示,中间隐藏层用h={h1,h2,…,hk}表示,映射函数为σe和σd,相邻两层网络的连接权重用W(1)={w11(1),w12(1),…,wkm(1)}和W(2)={w11(2),w12(2),…,wkm(2)}表示,偏置项分别用b(1)={b1(1),b2(1),…,bk(1)}和b(2)={b1(2),b2(2),…,bm(2)}表示,通过反向传播算法训练不断调整输入层和输出层各自分别与中间隐藏层之间的连接权重和偏置项,使得=σd(σe(x))≈x,即尽可能使解码器得到的重构输出与原始数据相等。编码器的输出hj和最终得到的原始数据x的重构输出分别如式(1)和式(2)所示:
训练自编码器的目标是最小化原始数据和重构数据之间的误差L,在文档聚类中,由于已经将文档表示成连续向量,故可以使用平方误差来计算L,如式(3)所示:
其中第二项为正则项,用于避免模型过拟合问题,η为正则系数。
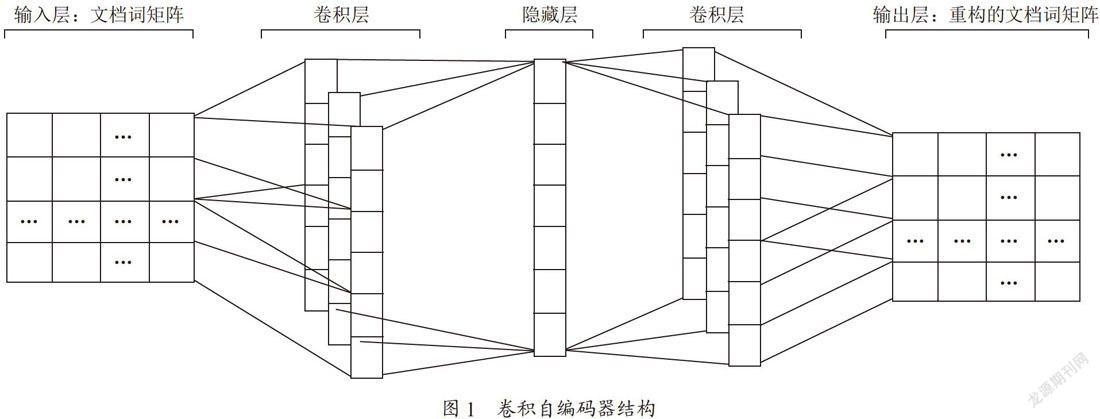
自编码器可以说是一个算法思想,其编码器和解码器部分可以使用任何形式的神经网络来构成不同的自编码器,由于卷积神经网络可以有效地分层提取原始数据的内在特征,因此可以使用它来构成编码器部分,使用反卷积网络来构成解码器部分,即构成一个卷积自编码器,其结构如图1所示。
假设卷积自编码器有N个卷积核,第k个卷积核为Nk,偏置分别为bk、ck,其余参数与自编码器相同,对于输入数据x,第k个卷积核的输入及解码层的重构数据分别如式(4)和式(5)所示:
其中表示第k个特征图的权重矩阵Wk的转置,*表示二维卷积运算。卷积自编码器的训练方法与自编码器相同。
2 CASC模型的构建
CASC模型主要由三部分构成:文档预处理、文档向量嵌入表示和聚类。文档预处理主要包括中文分词、去除停用词以及文档向量表示,其中中文分词和去除停用词使用分词库Jieba完成,文档向量表示则使用基于word2vec的方法。word2vec是一种通过训练神经网络得到词的向量表示的方法,有CBOW和Skip-gram兩种实现方式,本文使用Skip-gram方法来得到词向量,该方法根据当前词来预测该词周围的词,从而学习到当前词的向量表示。在得到所有词的词向量后,将每篇文档看成是所包含词的组合,由此该文档所含词的词向量堆叠构成文档词矩阵来表示该文档。假设Dj表示第j篇文档的向量表示,nj表示第j篇文档所含单词的数量,wi表示通过Skip-gram训练得到的词向量,那么最终构成的nj×d文档词矩阵如式(6)所示:
以上得到的文档向量通常来说维数较高,含有较多冗余信息,如果直接进行聚类则难以捕捉到其内部潜在关联。因此在CASC模型中,使用卷积自编码器将得到的高维文档矩阵通过训练学习嵌入到低维潜在向量空间中,在降低向量维度的同时,最大程度地保留原始数据的内部结构,以缩短聚类所需时间。将文档矩阵嵌入到低维潜在空间后,使用得到的低维向量表示进行谱聚类进而得到最终的聚类结果。算法流程图如图2所示。
3 实验
3.1 实验设置
为检验CASC模型的聚类效果,本文使用爬取的食品安全新闻所构成的数据集进行实验,该数据集共有11530篇新闻文档,并手动分为8类,聚类的类别数也与此相同。数据集进行了中文分词、去除停用词等预处理,其中分词使用Jieba分词库,经过预处理后总计剩余3932805个词,去重后剩余95334个独立词,实验环境采用Windows 7旗舰版64位操作系统和Python 3.5.2。
实验中卷积自编码器共有4层,其中有两层相同的卷积层、中间隐藏层和输出层,卷积层和隐藏层的激励函数使用ReLU函数,其形式为?(x)=max(0,x),且实用批量规范化(BatchNormalization)[14]以避免过拟合。
本文使用学习率为0.001的RMSProp优化算法来训练卷积自编码器,训练步数为10000步。其他超参数如表1所示。本文算法与经典的k-means算法和谱聚类算法进行了对比实验。
3.2 实验结果及分析
本文使用查准率(Precision)、召回率(Recall)、F1值以及算法运行时间作为模型评价标准。查准率是指在经过聚类算法之后,正确被聚类的样本数量,数值越大,说明效果越好。召回率则指在实际聚类结果中被正确聚类的样本数量在应该被正确聚类的样本数量中占有的比例。F1是准确率与召回率的复合指标,数值越大,说明效果越好。三者公式如下:
其中P指准确率,其变量m指被正确聚类的文档数量,n指未被正确聚类的文档数量,R指召回率,p指聚为同一类的文档数量,q指此类中应该有的文档数量。
实验结果如表2所示。
由表2可知,在聚类数目相同的情况下,CASC算法在查准率、召回率以及F1指标上均优于其他两种算法,可见卷积自编码器在将高维向量嵌入到低维空间时并未因损失太多信息而导致聚类性能下降,而基于图论的谱聚类算法在处理高维样本向量时一定程度上要优于k-means算法。由图3可知,CASC算法运行时间最短,这得益于卷积自编码器大大地降低了文档向量维度,减少了算法时间复杂度,而其他两种算法由于需要进行高维向量的大量运算,耗费时间较多。
4 结 论
针对半结构化的文本数据转化为结构化数据时带来的数据高维性问题,本文提出了CASC算法,通过探索利用卷积神经网络和自编码器的特征提取能力,最大程度地保留原始数据内部结构,来发掘其潜在关联,并使用较低的文档向量维度来替代原始高维向量进行聚类,在不降低聚类准确率的前提下缩短了算法运行时间,降低了算法时间复杂度。
同时,聚类算法作为一种无监督模型在文档自动处理中占有重要地位,如何进一步结合深度学习技术来提升聚类算法性能值得我们进行更深入地研究。
参考文献:
[1] Xu Jiaming et al. "Short text clustering via convolutional neural networks."2015.
[2] 谭晋秀,何跃.基于k-means文本聚类的新浪微博个性化博文推荐研究 [J].情报科学,2016,34(4):74-79.
[3] John Langford,Joelle Pineau.Proceedings of the 29th international conference on machine learning (icml-12) [J].CoRR,2012.
[4] Gerard Salton,Christopher Buckley.Term-weighting approaches in automatic text retrieval [J].Information Processing & Management,1988,24(5):513-523.
[5] Mikolov T,Sutskever I,Chen K,et al. Distributed Representations of Words and Phrases and their Compositionality [J].Advances in Neural Information Processing Systems,2013,26:3111-3119.
[6] Mikolov T,Chen K,Corrado G,et al. Efficient Estimation of Word Representations in Vector Space [J].Computer Science,2013.
[7] Stephen Johnson.Hierarchical clustering schemes [J].Psychometrika,1967.
[8] HARTIGAN JA,WONG MA.Algorithm as 136:a k-means clustering algorithm [J].Appl Stat,1979,28(1):100.
[9] Arthur,David,and Sergei Vassilvitskii. "k-means++: The advantages of careful seeding." Proceedings of the eighteenth annual ACM-SIAM symposium on Discrete algorithms. Society for Industrial and Applied Mathematics,2007.
[10] NAYAK J,NAIK B,BEHERA HS.Fuzzy c-means (fcm) clustering algorithm:a decade review from 2000 to 2014[M].New Delhi:Springer India,2015:133-149.
[11] Ester,Martin,et al. "A density-based algorithm for discovering clusters in large spatial databases with noise."Kdd. Vol.96.No.34.1996.
[12] Krzysztof Cios,Mark Shields.Advances in neural information processing systems 7 [J].Neurocomputing,1997,16(3):263.
[13] Yunlan Tan,Pengjie Tang,Yimin Zhou,et al.Photograph aesthetical evaluation and classification with deep convolutional neural networks [J].Neurocomputing,2016.
[14] Ioffe S,Szegedy C. Batch Normalization:Accelerating Deep Network Training by Reducing Internal Covariate Shift [J].2015:448-456.
作者簡介:冯永强(1963-),男,汉族,天津人,天津海河乳业公司研发部经理,高级工程师;李亚军(1993-),汉族,河南新乡人,计算机应用技术专业硕士研究生。
