基于变化熵的超高维特征筛选研究
2018-09-04来鹏狄晴时倩倩
来鹏,狄晴,时倩倩
(南京信息工程大学 数学与统计学院,江苏 南京 210044)
0 引言
在基因表达数据、调查问卷数据、证券投资组合数据等领域的研究中,常常会面临高维,甚至超高维数据分析问题。然而,由于高维问题所带来的“维数灾难”的影响,使得高维数据挖掘变得异常困难,目前比较有效的解决方法主要通过降维将数据从高维降到低维,然后用低维数据的处理办法进行建模分析。
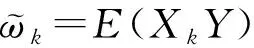
在信息科学、计算机科学等领域的算法研究中,信息熵、信息增益、关联规则等可用于研究变量或项集之间的相互关系。特别的,运用于数据挖掘的广义规则算法(GRI[9])可以有效地对数据进行关联分析,其所采用的核心指标变化熵J值[9]可以衡量变量间的相关关系。因此,J值的特点启发我们可以将其引入超高维判别分类问题中,用于判断预测变量与响应变量之间的相关程度,提出一种新的超高维判别分类特征筛选降维方法,并从理论上证明其筛选相合性质,通过数值模拟和文本分类实例分析其有限样本性质。
1 特征筛选
在信息论中常用信息量来衡量事件的不确定性,事件发生的概率越大,不确定性越小,信息量也就越小。熵则用来衡量系统的混乱程度,代表系统中信息量的总和。在随机变量X发生的条件下,随机变量Y发生所新带来的熵定义为Y的条件熵,用来衡量在X的条件下Y的不确定性。信息增益表示得知特征X的信息而使得Y的信息不确定性减少的程度,即用来衡量特征X区分数据集的能力。信息增益越大表示X对Y的影响越大,即X与Y是不相互独立的。通过对熵、条件熵、信息增益的研究,在熵和信息增益的基础上,一个新的变化熵(J值[9])被提出,可用于研究变量间相关联系:令Y和X为二分类变量,P(y|x)表示在X发生的条件下Y发生的条件概率,定义如下分布律:

YX101P(y|x)1-P(y|x)P(x) 01-P(x) P(y)1-P(y)

从J值的定义可看出,它反映了Y在给定X下的条件概率分布与Y的先验分布之间的差异的调整结果。当Y与X独立时,P(y|x)=P(y),J值为0;而当Y与X不独立时,P(y|x)≠P(y),经过简单的数学推导可以发现,J(Y|X)在P(y|x)=P(y)时取得最小值,由此可见当Y与X不独立时J(Y|X)大于0,并且相关性越大,J值越大。因此可根据J值的大小来判断预测变量同响应变量之间是否有关联,通过比较每个协变量与响应变量间J值的大小将其应用于超高维特征筛选降维研究中。
设响应变量Y为二分类变量,X=(X1,…,Xp)T为p维协变量,维数p随样本量呈指数级增长,呈现超高维特征。通常超高维数据满足稀疏性假设,即只有少数协变量与响应变量有关,绝大多数协变量与Y独立。因此,可定义真正重要的变量指标集合为:
D={k:对y=0或1,F(y|X)与Xk相关}.
其中F(y|X)表示给定X下Y的条件分布。由此可见,若k∈D,则Xk为影响Y取值分类的重要协变量。
(1)

(2)

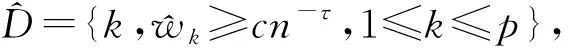
接下来,给出J-SIS特征筛选过程的渐近性质,为便于定理提出,列出如下条件:
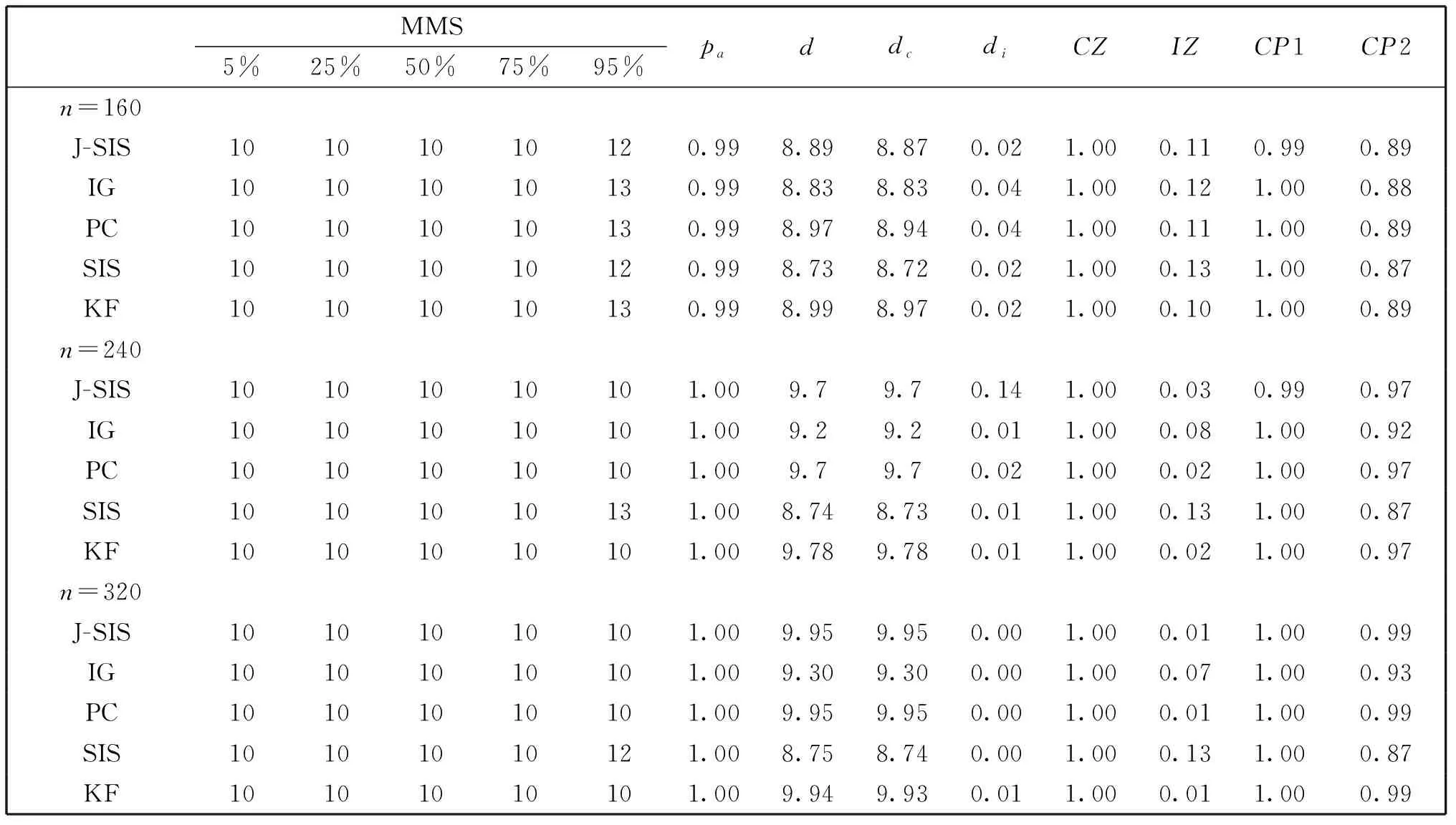
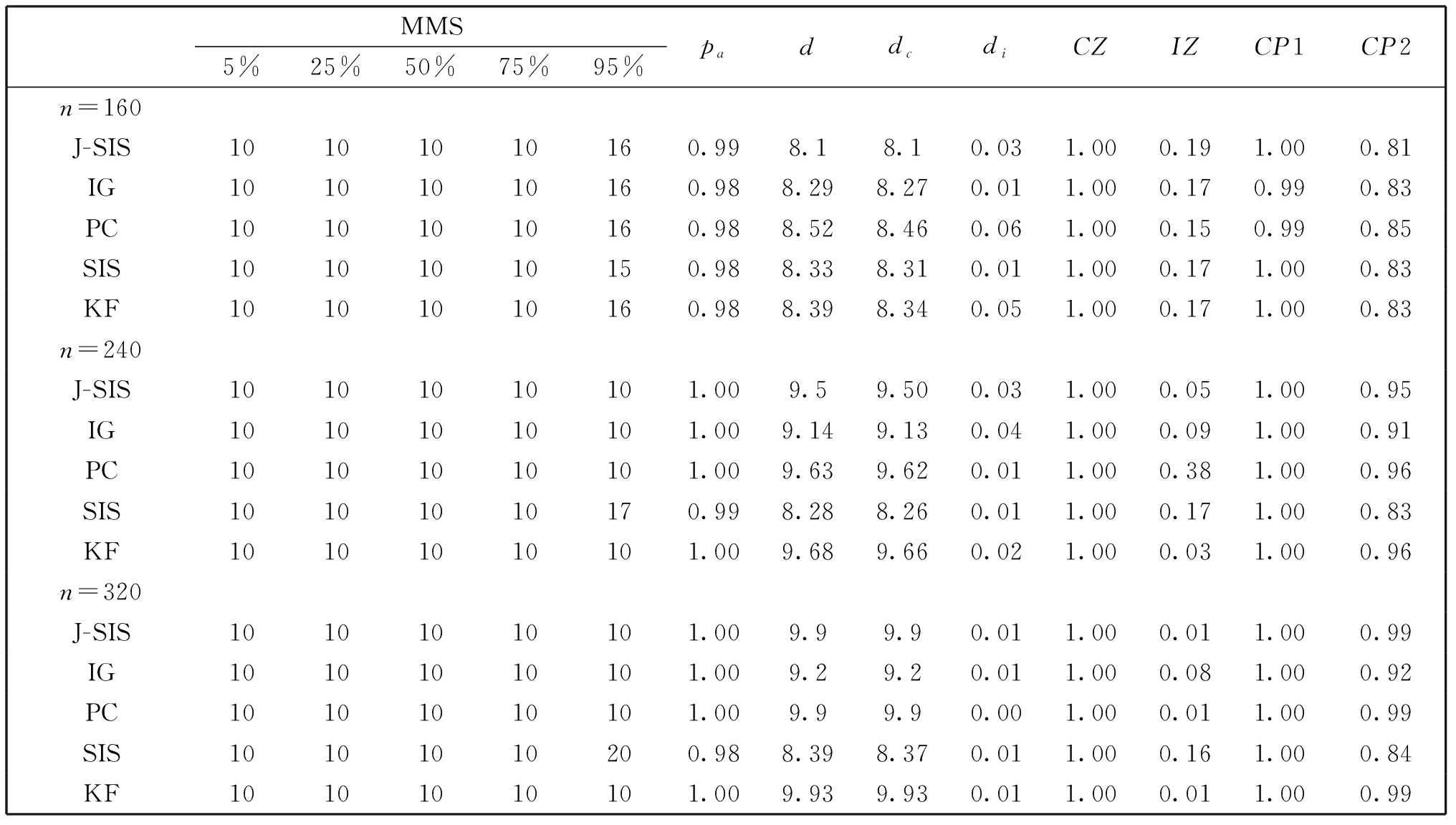
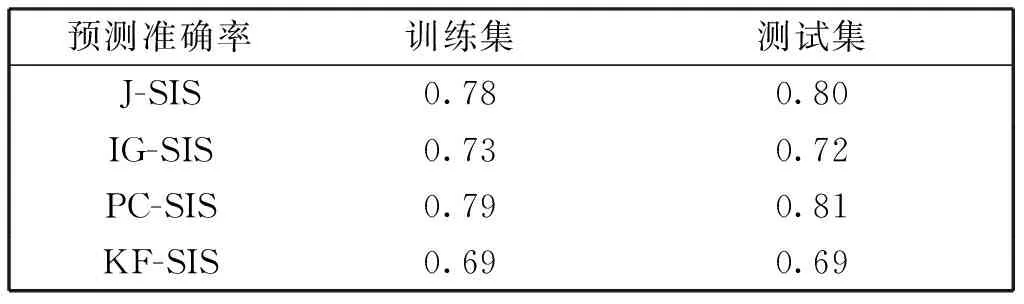
C1存在两个正常数0 C3协变量的维数p满足p=O(exp(nα)),有0<α<1-2τ。 注:这些条件在超高维分析文献中是很常规的假设。条件C1在超高维数据中被广泛使用,如Cui等[10],该条件确保响应变量Y和协变量Xk每个类别的比例不会太小也不会太大。条件C2在变量筛选中是很典型的,如Fan和Lv[1]和Liu等[11]的条件中也用了相同的假设。条件C3表明了所研究数据的超高维数据特性。 定理1 (确定性筛选性质)在条件C1-C3的约束下,存在正常数b1和b2,有 且当n→∞时,有 其中sn=|D|,为D中元素个数。 |logpyk-logpy|≤|logpyk|+|logpy|<2|logc1|, |log(1-py)-log(1-pyk)|<2|log(1-c2)|. 因此利用Hoeffding不等式可得 (3) 同理,对I11,并根据Liu等[11]中的引理4,可得 其中,f (α)为反应动力学方程,k ( T)是与温度相关的反应速率;常采用的是阿尼乌斯公式(3),E为活化能,A为指前因子,R为通用气体常数[25]。在非等温动力学反应研究中,将温度T随时间t变化的升温速率β= T t代入式(1)即可得到非等温动力学方程: (4) 采用类似的方法,可以证明∃c2,c3,对于I2-I6可得: (5) (6) (7) (8) (9) 在模拟研究中,我们考虑两种二值分类问题,一种为响应变量均衡分类,一种为非均衡分类。在均衡分类情况下,生成服从0-1分布的n个响应变量的随机样本Yi,且P(Yi=1)=0.5.定义真正重要的协变量指标集合D={1,2,…,10},即d0=|D|=10,生成二值分类协变量的随机样本Xki满足当1≤k≤d0时P(Xki=0|Yi=r)=θrk,即P(Xki=1|Yi=r)=1-θrk,其中i=1,2,…,n,r=0,1,θrk的取值在表1中给出,而对d0 表1 模拟参数设置 表2 均衡情况P(Yi=1)=1/2的模拟结果 在响应变量为等概率0-1分布时,可以看出J-SIS得到的结果是比较好的,选择出所有重要变量时所选择模型大小均在10左右,接近重要变量个数。其他几种方法,SIS,PC-SIS总体效果较好,但在某些评价指标还是劣于本文方法。J-SIS与KF-SIS,PC-SIS的结果接近,优于IG-SIS。此外,随着样本量的增大,筛选结果会变好。 在Y的两个值发生的概率不相等时,表3中的结果与表2相似,SIS的筛选效果仍然是几种方法中比较差的。在样本量不同的几种情况下,PC-SIS的结果从di(不重要的变量被错误的选择为重要变量的个数)来看略优于本文提出的方法,但在n=240时,PC-SIS的IZ值异常;IG-SIS与Y均衡取值时的结果相似,同样在dc和CP1来看劣于本文的J-SIS;KF-SIS与本文的方法相比,在n=160时,从pa和di来看都不如本文的方法。总体来看,本文所提方法计算简单,结果准确,具有一定优势。 表3 非均衡情况P(Yi=1)=1/3的模拟结果 综上可以得出,数据模拟得出的结果较为理想,在2 000个协变量中能有效地筛选出重要的变量,所提出的J-SIS方法与理论结果是一致的,在超高维数据特征筛选中有很强的可行性。特别的,通过几种方法运算速度的比较,J-SIS方法具有明显优势。在R语言环境下,运行100次模拟,J-SIS方法只需要25.83 s,J-SIS方法需要44.17 s,J-SIS方法需要32.57 s,J-SIS和J-SIS都超过3 min。 为了探讨所提出J-SIS方法在实际问题中的应用表现,考虑从农场广告中收集的文本数据(http:∥ar-chive.ics.uci.edu/ml/datasets/Farm+Ads),该数据是从12个网站上搜集的关于农场动物的广告数据,每条广告代表一个样本,1和-1分别表示发布者认可或不认可该广告。将这些文本数据去除一些符号、空格和常见的停用词以后,可发现该文本数据包含2 833个特征词,4 169个样本,即p为2 833,n=4 196,将每条广告中这些单词出现与否记为1和0,是否采用该广告为响应变量,则可研究是否认可广告与关键词之间的相互联系。 为了判断所提方法的实例分析效果,采用70%的样本数据作为训练数据,其他30%的样本数据作为测试集。对训练样本,采用数值模拟中提到的几种方法进行特征筛选,由于在数值模拟部分我们得出SIS是这几种方法中效果较差的,并且在实例中无模型假设,所以只利用本文的J-SIS,以及提到的IG-SIS,PC-SIS和KF-SIS进行筛选和预测。对数据进行特征筛选得到部分筛选单词排序结果如表4。 表4 筛选出的特征单词 可以看出这些单词与农场有关,所以筛选出的特征词是符合实际的。分别对训练集和测试集利用所筛选出的前30个重要协变量进行分类预测,计算出它们的预测精确度如表5所示,可以看出,本文所提出方法具有较好的判别预测效果。 从表5来看,J-SIS与PC-SIS相比,在实例中判别预测效果较逊色。从实例分析和数值模拟中,都可以看出两种方法具有类似的分析效果。对于PC-SIS来说,在训练和测试集上表现都欠佳,但在数据分析尝试中可以发现,如果将所有数据不加分割的进行建模分析,则PC-SIS会有较好的表现,这说明该方法容易出现过拟合的问题。总的来说,本文所提出方法和其他方法在建模预测效果上略有优势,但是在方法的运算速度上则有比较明显的优势,能够更快速的实现筛选降维。 表5 训练集和测试集预测结果 超高维判别分类问题作为大数据时代下的一类复杂数据分析问题,对其的研究具有重要的理论与实践意义,本文对于超高维二分类判别分析问题进行了研究,推广了现有降维方法,基于信息论中熵的概念,结合关联分析中的分类规则原理,提出了基于变化熵J值的J-SIS特征筛选方法,讨论了在协变量的维数p会随着样本量的增加呈指数增长时,可通过对协变量与响应变量间J值大小的计算进行排序筛选降维。本文所提出方法不需要参数模型假设,具有无模型假设的特点,并且在较弱的假设条件下,证明了所给出J-SIS筛选过程满足筛选相合性质,从理论和数值模拟、实例分析方面验证了所提出结论,说明所给出方法具有更广泛和宽松的应用环境。此外,在文本分类判别中,如果想进一步研究关键词之间的交互作用,本文所提出方法可以进一步计算关键词之间在给定响应变量下的J值,从而进行推广应用。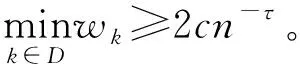

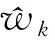
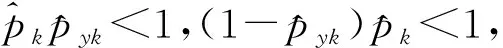



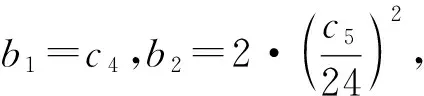


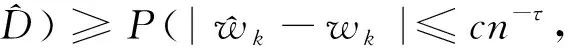
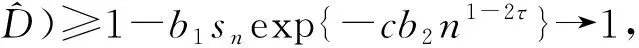
2 数值模拟

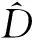
3 实例分析
4 结论
