以未知对未知—智能安全自我进化*
2018-09-03林榆坚梁宁波
林榆坚,梁宁波
(北京安赛创想科技有限公司,北京 100083)
0 引 言
以信息技术为代表的新一轮科技和产业革命给世界各国主权、安全、发展利益带来了许多新的挑战。近年来,国家级网络武器及其相关工具和技术的扩散,给各国关键基础设施造成了极大挑战。当前,全球互联网治理体系变革进入关键时期,构建网络空间命运共同体日益成为国际社会的广泛共识。
全球网络攻击事件统计(如图1所示)显示,未知威胁攻击、Account Hijacking账户劫持攻击、Targeted Attack针对性攻击、DDoS攻击,攻击比例上呈逐年上升趋势。国计民生的基础设施系统是攻击的重点领域,其中涉及金融、能源、交通等,其目标性、隐蔽性极强,传统的消缺补漏、静态防御、“封、堵、查、杀”在这些攻击面前捉襟见肘。
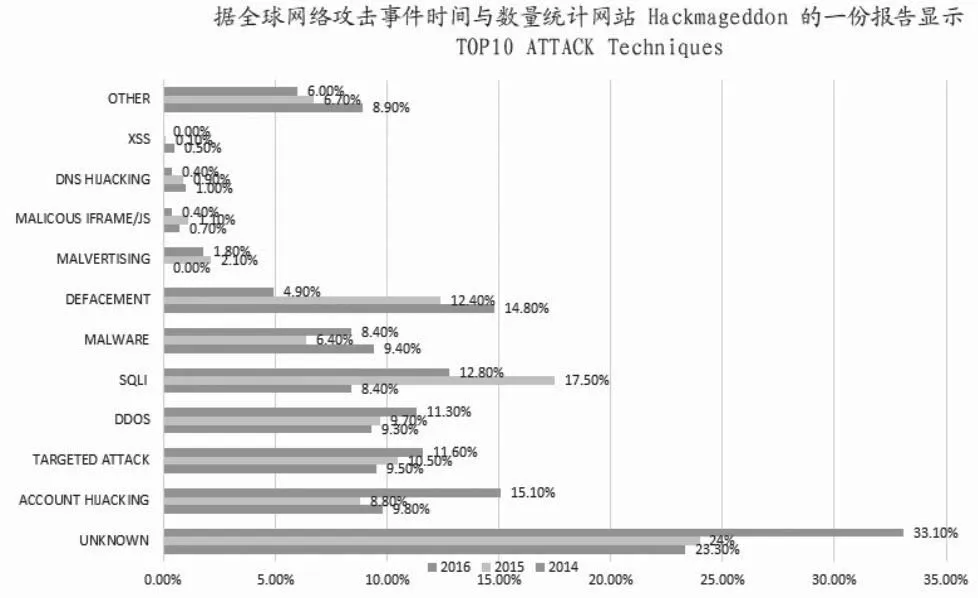
图1 全球网络攻击事件统计
美国中情局对其黑客武器库的失控,如同一把宝剑悬着以划“域”而治。固守边界防御思路治理下的各国关键基础设施上空,大范围安全事件随时可能发生。2017年,WannaCry勒索病毒是一个典型的安全事件,短短4日,席卷150多个国家,造成80亿美元损失,涉及金融、能源、医疗等众多行业[1]。如何避免突击式的补救,成为当下急需解决的问题。
改变以往的边界防御思路,从数据安全保护角度出发,通过对业务数据进行动态评估,分析出业务数据的价值,从而根据不同价值等级进行动态的策略规则防护。
1 防御构想
动态防御,很早就是网络安全领域追诉的目标,经历了从设备联动布防到现在对人工智能的关注。在当下网络安全环境中,利用IPS、FW等设备的动态关联,已经不能满足动态的需要。人工智能以其高效数据处理和分析的速度、准确性等优势,受到了人们的青睐。其中,数据和算法是保障高信度和高效度分析结果的核心。脱离全面有效数据的喂养,准确分析将无从谈起;离开有效算法和算法集间的交叉验证,就会走向信度和效度极度脆弱的一面。
构建真正意义上的“以未知对未知”的动态防御,数据和算法是核心。获取全面的具有代表性的数据,才能避免人工智能鲁棒性的出现,才能提供更加准确可靠的分析结果。算法决定检测准确度的上限。只有对算法的优缺点进行验证、分析,才能在实战中做好算法集的动态调配。
“以未知对未知”,是在人工智能的技术前提下,基于Netflow和sFlow两种协议字段融合,克服单一网络协议的数据局限性弊端,降低网络数据存储量和运行主机的CPU负载率,结合算法集对流动变化的数据自适应,通过关键因素的风险区间和概率分布,对未来结果做出精准判断,产出不断进化的防御规则,以应对新时代网络安全的需求。
2 “以未知对未知”的防御体系设计
“以未知对未知”防御体系设计(如图2所示)共分三个部分。第一部分是未知数据的采集、梳理、融合、范化、精炼,形成标准的数据格式;第二部分是自适应算法集,包含支持向量机算法、Apriori与FP-Growth算法、隐式马尔科夫算法、朴素贝叶斯算法等,每个算法单独并行运算,威胁验证后,提交给态势数据库;第三部分,态势数据库一方面将威胁情报梳理呈现,另一方面根据网络状况进行资源管理策略调整,影响安全防御系统策略变更。
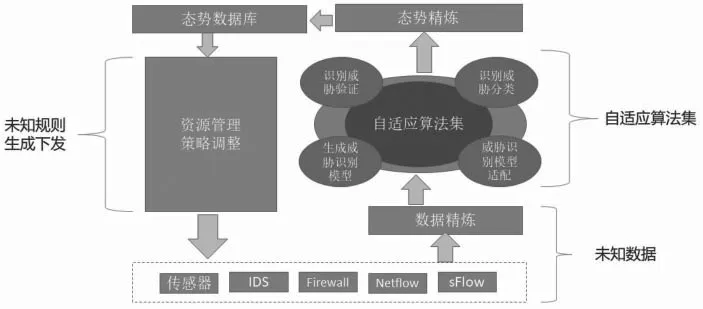
图2 “未知对未知”防御架构
2.1 数据采集方法研究
采集具有代表性的原始数据,是“未知对未知”防御的重要基础。
由于网络流量中包含了源/目的地址、源/目的端口、协议类型等丰富的网络信息,能够实时反映当前网络中出现的安全信息和行为描述。因此,网络流量为在网络异常检测方面最具有代表性的元数据。由于其他安全设备和网络设备品牌各异,采集数据的协议也不尽相同。这些设备采集的和二次加工的数据暂且纳入第三方信息管理平台,为威胁验证提供参考。
近几年,应用比较广泛的网络流技术主要包括NetFlow(Ciso公司)、J-Flow(Juniper公司)、sFlow(HP,InMon,Foundry Networks公司)和NetStream(华为公司)。其中,J-Flow和NetStream这2种网络流的原理和内容基本与NetFlow相类似,故可以认为目前应用的常见网络流主要以NetFlow和sFlow为主[2]。
2.1.1 基于NetFlow的流量采集方法
NetFlow是由Cisco创造的一种流量轮廓监控技术,简单来说就是一种数据交换方式。NetFlow提供网络流量的会话级视图,记录下每个TCP/IP事务的信息,易于管理和易读。
NetFlow利用标准的交换模式处理数据流的第1个IP包数据生成NetFlow缓存,随后同样的数据基于缓存信息在同1个数据流中进行传输,不再匹配相关的访问控制等策略。NetFlow缓存同时包含了随后数据流的统计信息。NetFlow有2个核心的组件:NetFlow缓存,存储IP流信息;NetFlow的数据导出或传输机制,将数据发送到网络管理采集器。
利用NetFlow技术可以检测网络上IP Flow信息,包括(5W1H):
who:源IP地址;
when:开始时间、结束时间;
where:从哪——From(源IP,源端口);到哪——To(目的IP,目的端口);
what:协议类型,目标IP,目标端口;
how:流量大小,流量包数;
why:基线,阈值,特征。
这些数据可以形成标准的七元组。用七元组来区分每一个Flow是其重要的特点。七元组主要包括,源IP地址、源端口号、目的IP地址、目的端口号、协议类、服务种类和输入接口。
2.1.2 基于sFlow的流量采集方法
sFlow(RFC 3176)是基于标准的最新网络导出协议[3]。sFlow已经成为一项线速运行的“永远在线”技术,可以将sFlow技术嵌入到网络路由器和交换机ASIC芯片中。与使用镜像端口、探针和旁路监测技术的传统网络监视解决方案相比,sFlow能够明显降低实施费用,同时可以使面向每一个端口的全企业网络监视解决方案成为可能。
sFlow系统的基本原理为:分布在网络不同位置的sFlow代理把sFlow数据报源源不断地传送给中央sFlow采集器,采集器对sFlow数据报进行分析并生成丰富、实时、全网范围的传输流视图。
sFlow是一种纯数据包采样技术,即每一个被采样的X包的长度被记录下来,而大部分的包则被丢弃,只留下样本被传送给采集器。由于这项技术是基于样本的,如果没有复杂的算法来尝试推测准确的会话字节量,那么几乎不可能获得每台主机流量100%的准确值。使用这项技术时,交换机每隔100个数据包(可配置)对每个接口采一次样,然后将它传送给采集器。sFlow的规格也支持1∶1的采样率,即对每一个数据包都进行“采样”。对数据包最大采样频率的限制取决于具体的芯片厂商和sFlow的实现情况。
2.1.3 双流量数据采集
因HTTP会话双向性的特点,需采取网络双向流量分析,主要针对request请求和服务器的response响应进行实时分析,并且自动关联分析磁盘阵列中全流量镜像历史数据,发现更深层次的攻击事件。
如图3所示,系统在用户发出请求和服务器给予响应的过程中,会对两者的HTTP请求包和响应包数据进行分析,判断是否存在漏洞或者攻击事件。如果有漏洞或者攻击事件,则会记录并交由其他模块继续处理。
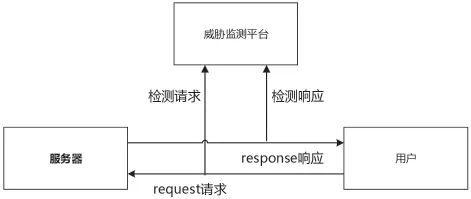
图3 双向流检测流程
通过不同层次的监控(内核级、应用层级主要包括进程操作、文件操作、注册表操作、网络访问、网络数据URL等)发现更全面的监控样本,结合智能关联分析形成有效的安全检测体系,以挖掘更全面的恶意行为。
2.1.4 数据融合
NetFlow和sFlow两种协议都属于网络流协议,但是存在一些差异。sFlow通过采样的形式来获取网络流数据,基本包含了网络中的所有信息,且具有“永远在线”的特点。由于协议本身的设置,使得sFlow在获取网络流数据过程中虽然CPU负载率低,但是获取的数据存在一些误差,尤其在网络流量较小时,难以满足小规模网络的要求。而NetFlow通过连续采集的方式来获取网络流数据,使得数据中不包括网络中的一些部分重要信息(如:MAC地址、接口速率等),导致无法对上述重要信息进行研究分析。此外,由于通过连续采集的方式来获取数据,使得其CPU负载率较高,尤其当网络流量较大时,难以有效满足大规模网络的要求[4]。
将NetFlow和sFlow数据融合,相互弥补各自的不足、性能上的差异,是推动采集数据全面性的必经之路。融合不是简单的结合,而是在两个协议功能、性能优缺点分析的基础上,对两个协议字段进行融合。
2.2 算法研究
算法决定上限,也是说算法决定了智能安全功能展现的上限阈值。本文通过算法集研究实践,分析不同算法特性来应对不同威胁的攻击。具体地,主要对支持向量机算法、Apriori与FP-growth算法、隐式马尔科夫算法和朴素贝叶斯算法等进行分析研究。
2.2.1 支持向量机算法
支持向量机是一种二分类模型,基本模型是定义在特征空间上的间隔最大的线性分类器[5]。间隔最大使它有别于感知机(感知机利用误分类最小的策略,求得分离超平面,解有无穷多个;线性可分支持向量机利用间隔最大化求解最优分离超平面,解是唯一的);支持向量机还包括核技巧(将数据有时是非线性数据,从一个低维空间映射到一个高维空间,可以将一个在低维空间中的非线性问题转换为高维空间下的线性问题来求解),使其成为实质上的非线性分类器。支持向量机的学习策略是间隔最大化,以形式化为一个求解凸二次规划的问题,也等价于正则化的合页函数的最小化问题。
支持向量机学习算法模型分类。
(1)线性可分支持向量机。当训练集线性可分时,通过硬间隔最大化,学习一个线性的分类器,即线性可分支持向量机,又称为硬间隔支持向量机。
(2)线性近似可分支持向量机。当训练集近似线性可分时,通过软间隔最大化,也学习一个线性的分类器,即线性支持向量机,又称为软间隔支持向量机。
(3)非线性支持向量机。当训练集线性不可分时,通过核技巧和软间隔最大化,学习非线性支持向量机。
SVM学习问题可以表示为凸优化问题,因此可以利用已知的有效算法发现目标函数的全局最小值。而其他分类方法(如基于规则的分类器和人工神经网络)都采用一种基于贪心学习的策略来搜索假设空间,一般只能获得局部最优解。
2.2.2 Apriori与FP-gowth算法
Apriori和FP-growth算法是比较有代表性的关联规则算法。它们是无监督算法,可以自动从数据中挖掘出潜在的关联关系。这一算法对挖掘潜在威胁很有帮助,如对图2中自适应算法集及资源管理调整生成未知策略帮助很大。
Apriori算法是一种同时满足最小支持度阈值和最小置信度阈值的关联规则挖掘算法。使用频繁项集的先验知识,通过逐层搜索迭代的方式探索项度集。
FP-growth算法基于Apriori算法构建,但采用了高级的数据结构减少扫描次数,加快了算法速度。FP-growth算法只需要对数据库进行两次扫描,而Apr-iori算法对每个潜在的频繁项集都会扫描数据集判定给定模式是否频繁,因此FP-growth算法比Apr-iori算法快。
在自适应算法集,采用Apriori和FP-growth算法对NetFlow和sFlow两个协议的融合数据进行关联分析。
2.2.3 隐式链马尔科夫算法
隐马尔可夫模型(Hidden Markov Model,HMM)是统计模型,用来描述一个含有隐含未知参数的马尔可夫过程。难点是从可观察的参数中确定该过程的隐含参数,然后利用参数做进一步分析,如模式识别。被建模的系统被认为是一个马尔可夫过程与未观测到的(隐藏的)的状态的统计,即马尔可夫模型。
和HMM相关的算法主要分为三类,分别解决三种问题:
(1)已知隐含状态数量、转换率,根据可见状态链得出隐含状态链;
(2)已知隐含状态数量、转换率,根据可见状态链得出结果概率;
(3)已知隐含状态数量,通过多次观测可见状态链,反推出转换率。
2.2.4 朴素贝叶斯算法
在所有的机器学习分类算法中,朴素贝叶斯和其他绝大多数的分类算法不同。对于大多数的分类算法,如决策树、KNN、逻辑回归、支持向量机等,都是判别方法,也就是直接学习特征输出Y和特征X之间的关系,要么是决策函数Y=f(X),要么是条件分布P(Y |X )。但是,朴素贝叶斯却是生成方法,直接找出特征输出Y和特征X的联合分布P(X , Y ),然后利用:
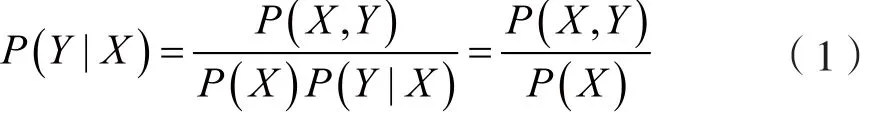
得出:

贝叶斯学派的思想可以概括为先验概率+数据=后验概率。也就是说,实际问题中需要得到的后验概率,可以通过先验概率和数据综合得到。一般来说,先验概率是对数据所在领域的历史经验,但是这个经验常常难以量化或者模型化。于是,贝叶斯学派大胆假设先验分布的模型,如正态分布、beta分布等。这个假设一般没有特定的依据,虽然难以从严密的数学逻辑中推出贝叶斯学派的逻辑,但是在很多实际应用中,贝叶斯理论应用效果良好,如垃圾邮件分类和文本分类。
2.3 未知规则生成研究
在整个“以未知对未知”防御思路中,未知数据、算法集、未知规则是其核心。这个思路是改变传统以特征库匹配防御的思路,推出了新的动态防御思路。
未知数据是网络空间中网络设备、安全设备二次加工数据以及NetFlow和sFlow两个协议融合的网络流量数据,需对这些数据进行处理提炼。
自适应算法集是在对机器学习智能算法理解的基础上进行建模识别,并检测网络威胁。检测流程:(1)智能算法集依据客户网络环境数据及相关信息生成威胁识别模型;(2)威胁识别模型适配运行;(3)识别威胁分类;(4)识别威胁验证(真实性、可触发性验证)优化算法模型;(5)结合已有策略进行调整。
3 理论验证
本文通过加密流量检测和DGA域名检测两个实验,验证“以未知对未知”理论的实践效果。
3.1 加密流量检测
数据加密通保证了网络交易和聊天的私密性,防止了攻击者(中间人攻击)窥探或篡改用户的网络通信数据。但是,也被攻击者利用普通的TLS或SSL流量来试图掩盖他们的恶意命令、远程控制行为以及数据窃取活动。
为了防止恶意软件通过加密流量窃取用户的隐私,传统做法是通过设置代理并解密通信数据来检查所有的SSL和TLS流量。
如果是在恶意活动中,那么上述这种“可行方法”就是常说的中间人(MitM)攻击。但是,即便是出于安全防御端的角度来看,这种方法仍然会被视为一种侵犯用户隐私的行为。因为当用户需要向银行或加密邮件服务发送加密通信信息时,这种方法就会破坏加密信任链,导致用户隐私受到侵害。此外,这种方法的计算量非常高,高到足以造成网络性能的大幅下降,更不用说管理额外的SSL证书(流量被检查之后需要重新签名)所带来的性能负担。以牺牲隐私权和网络性能为代价来换取安全性的方法是不值得的。
为此,从侧面来寻找答案。通过分析NetFlow和sFlow发现,流量中包含大量的有价值信息,可以表示网络上的两台设备正在交互,以及通信时长和发送的字节数等,但受语境限制,有些数据出现不完整现象。分析加密隧道协议发现,TLS数据流中未加密的元数据包含攻击者无法隐藏的数据指纹,而且即使数据经过加密也无法隐藏这种指纹。在不进行任何解密的情况下,对海量数据进行筛选和归类,通过“最具描述性的特征”来识别可以恶意流量和正常流量。
通过未知算法检测加密流量,发现了隐藏恶意文件和指纹,基于NetFlow,检测准确率为67%。配合SPL、DNS、TLS元数据以及HTTP等信息,检测的准确率将高达99%。而传统边界类防护设备无法检测加密流量。
3.2 检测DGA域名
DGA(域名生成算法)是一种利用随机字符生成C&C域名,从而逃避域名黑名单检测的技术手段。例如,一个由Cryptolocker创建的DGA生成域xeogrhxquuubt.com,如果进程尝试其他建立连接,那么机器就可能感染Cryptolocker勒索病毒。域名黑名单通常用于检测和阻断这些域的连接,但对不断更新的DGA算法并不奏效。
检测DGA域名的流程:(1)从DGA文件中提起域名数据;(2)特征提取:①元音字母个数统计;②去重后的字母数字个数与域名长度的比例;③平均jarccard系数;④HMM系数;(3)模型验证。
根据DGA的特性,采取不同算法对其进行验证。
为了更准确地评估不同算法检测的准确率,采用准确率、召回率、F值评测进行评估。正确率是提取的正确数据条数/提取出的数据条数;召回率是提取的正确信息条数/样本中的信息条数;F值是正确率*召回率*2/(正确率+召回率)。基于处理好的样本,对传统检测技术和大数据关联分析技术进行对比,实验结果如表1所示。

表1 DGA检测的正确率、召回率及F值预测结果/(%)
4 结 语
将“以未知对未知”的实践尝试应用到网络空间中,将为动态化、自主化识别恶意软件和攻击行为提供保障。
