面向数据中心网络流量的路由优化设计*
2018-09-03陈松,谢卫
陈 松,谢 卫
(中国电子科技集团公司第三十研究所,四川 成都 600045)
0 引 言
基于软件定义的数据中心网络采用控制平面和数据平面分离的思想。分离出的控制平面为应用程序提供北向编程接口,并通过南向接口控制数据平面的转发行为。集中式运行的网络控制平面具有灵活和细粒度的控制能力,是网络的“大脑”,在软件定义的数据中心网络具有举足轻重的作用。网络控制器可以根据当前网络状态和流的信息,为业务流量优化路由选择,实现全局网络流量分布优化,提高流量传输性能。
1 数据中心网络流量特点
与传统网络相比,数据中心网络业务和拓扑结构有其特殊性。比如,数据中心网络中90%以上的流为小流,只有约10%的流为大流。小流通常需要在尽量短的时间内完成,而大流占用80%以上的网络带宽。再如,由于数据中心网络特有的业务类型(如MapReduce业务),数据中心网络中传输的若干个流通常具有相关性(通常称为Coflow)。为了保证Coflow的性能,网络需要对Coflow进行合理调度和路由。为了保证网络对不同流的传输性能要求,需要重点研究面向海量流的数据中心网络流路由优化方法。同时,为了保证数据中心网络中特有的Coflow的传输性能,还要研究如何对Coflow的调度和路由进行联合优化。
2 面向海量流的数据中心网络路由优化方法
随着数据中心网络规模的不断扩大和应用的不断增加,数据中心网络中传输的流的数目将非常巨大。因此,在大规模数据中心网络中要实现海量流的路由优化必然面临可扩展性的问题,即网络控制可能无法在可接受的时间限制内完成流的路由优化计算。这是一项需要突破的关键技术[1]。
为了解决该问题,一种是发展并行的路由优化方法,通过利用CPU多线程并行计算能力来减少路由优化的计算时间。目前,虽然通用CPU通常都具有多个核心,且每个核心能支持多个线程,但是由于体系架构的限制,一个CPU能支持的线程也只有数十个到上百个,无法为并行路由计算带来满意的并行增益。近年来,GPU的性能和通用计算编程模型有了非常大的改进。与CPU相比,GPU能同时支持数以万计的线程,并行计算能力非常可观。因此,采用基于GPU实现并行路由优化算法比较适合[2]。
GPU虽然能支持海量的并行线程,但是其独特的体系架构决定了它处理复杂逻辑的能力较弱,且在host device编程模型下,算法的数据在每次迭代中都要从主内存拷贝到设备内存,会消耗额外的时间。因此,一个高效的运行于GPU环境上的并行算法应该具有以下两个特征。第一,算法的并行度要非常高,并每个并行线程的计算逻辑要简单;第二,算法的迭代次数要少。因此,拟使用拉格朗日松弛方法来分解路由优化问题,并使用并行化的Bellman-Ford最短算法为每个业务计算路由。
首先,数据中心网络路由优化问题可以建模为如下的混合整数规划模型:
上述模型中使用到的符号定义如表1所示。

表1 路由优化模型中使用的符号
模型中,式(1)为流量守恒约束,该约束限制流的路由,式(2)为链路容量约束。通过使用拉格朗日松弛方法,可以把式(3)松弛到优化目标,进而得到模型:
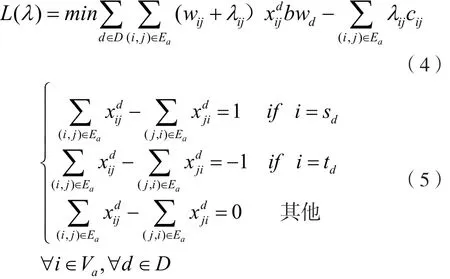
容易得知,上述模型等价于在链路权重(wij+λij)下求解每个流的最短路径。由于松弛掉式(4)后,模型中的流之间没有了相互关系,所以他们的最短路由可以并行计算。但是,如果使用串行算法为每个流计算最短路由,会涉及复杂的逻辑判断而影响算法的并行效率。为了解决这个问题,可以通过使用并行化的Bellman-Ford算法来为每个流计算路由,以提高算法的并行度和降低单个并行线程的逻辑复杂度。在GPU上实现并行路由计算的设计方案,如图1所示。可以看到,Bellman-ford最短路算法中针对每条边的松弛操作都在独立的线程上并行完成,且不同业务的最短路计算也是并行完成,所以该方案的并行程度非常高,每个并行进程处理的逻辑非常简单,有利于GPU并行计算环境[3]。

图1 基于GPU的并行路由算法设计方案
上述方法还会涉及如何选择拉格朗日乘子的步长、如何减少迭代的次数等提高算法效率的关键问题。
3 数据中心Coflow的调度和路由联合优化算法
相较于传统Internet中的流量,数据中心网络中的流量有一个明显的特征:执行前一个任务的前一个阶段的主机,会把中间数据发送给执行后一个阶段任务的主机作为后一个阶段任务的输入数据。这些数据往往来自于多个不同的主机,即由多个流共同完成中间数据的传输。在这样的一组流中,只要有一个流的传输没有完成,下一阶段的计算就无法开始。比如,在MapReduce中,一个Reduce只有在接收完所有Map产生的数据后才会开始进行计算。于是,有人提出了Coflow的概念,来定义这样一组有语意相关性的流[4]。为了优化网络中应用的性能,需要优化这样的Coflow完成时间,而不是与传统网络一样,对单个流的完成时间进行优化。
在给定每一个Coflow中所有单个流的信息(如流的大小,源目节点)的情况下,网络控制器需要实时决定每个流的路径、何时启动以及传输速率等,即Coflow的调度和路由问题。例如,在数据中心网络中对Coflow平均完成时间进行优化时,需要对流量路由和调度进行联合优化,如图2所示。
图2中,有2个Coflow,分别为Coflow a和Coflow b。其中,Coflow a有两个流,分别是fa1和fa2,两个流的大小分别为40 Mb和100 Mb。同样,Coflow b也有两个流,分别是fb1和fb2,大小分别为60 Mb和100 Mb。四个流都需要从网络中的S节点发送到D节点。每个流都有两条路可以选择,分别是S→Mu→D和S→Md→D。同时,例子中的所有链路带宽都是100 Mb/s。通过枚举可以知道,这个例子里,最小的Coflow平均完成时间是1.3 s。
图2(a)给出了利用等价多路径协议(Equal Cost Multi-Path,ECMP)进行路由所得到的一种情况。如果在该路由策略下,采用公平共享链路带宽的调度策略(即单纯的TCP竞争所得到的结果),那么对于两个Coflow来说,路径S→Md→D会是它们的瓶颈。因为在这条路径上承载了两个流,所以每个流可以分到50 Mb/s的带宽,从而两个流都会在2 s时完成。所以,两个Coflow的完成时间都是2 s,Coflow平均完成时间也是2 s。如果按照如图2(d)所示的调度方案,两个Coflow的完成时间分别为1 s和2 s,则Coflow平均完成时间为1.5 s。可以看出,对于网络流量优化,即减小网络中Coflow的平均完成时间,调度可以起到很大作用。但是,在图2(a)所示的路由下,仅靠调整调度策略能得到的最小Coflow平均完成时间也是1.5 s,离1.3 s的最好性能还有一定距离。这是因为在图2(a)的路由条件下,两条路径上所承载的流量严重不平衡,S→Md→D上的流量是S→Mu→D上流量的2倍。因此,仅靠调度并不能得到最优的Coflow平均完成时间。
图2(b)给出了一种负载均衡的路由方式:Coflow a的两个流都经过路径S→Mu→D,而Coflow b的两个流都经过路径S→Md→D。在这一路由策略下,使用图2(e)所示的调度策略,两个Coflow的完成时间分别为1.4 s和1.6 s。此时,Coflow平均完成时间为1.5 s,依旧不是最优。原因是同一个Coflow的所有流都被路由到同一条路径上,使得调度策略很难对平均完成时间的优化起到作用。事实上,该例子中,如果采用图2(b)所示的路由方案,无论采用何种调度策略,只要充分利用网络带宽,Coflow平均完成时间都不会改变。因此,独立考虑路由和调度并不能得到一个好的解[5]。


图2 数据中心网络流量优化需要路由和调度的联合
由此可以看出,对数据中心网络中的Coflow平均完成时间进行优化时,需要对路由和调度进行统一优化。本例中,采用图2(c)中的路由方案和图2(f)中的调度策略,才能得到最优的Coflow平均完成时间。此时,两个Coflow的完成时间分别为1 s和1.6 s,平时完成时间为1.3 s。
4 结 语
在数据中心网络业务路由方面,本文针对数据中心网络中存在的几种特殊业务模式,提出面向海量流采用GPU并行计算的路由优化算法,提高了路由控制的实时性。另外,针对数据中心常见的Coflow流设计了调度和路由联合的优化算法,进一步提高了业务传输的服务质量。
