基于MR数据与机器学习的LTE用户感知评估方法
2018-09-03王希
王希
(中国移动通信集团福建有限公司,福建 福州 350001)
1 引言
现有网络优化质差分析一般是驱车测试和呼叫质量拨打测试,通过专用的测试系统采集测试区域的信号强度、信号质量等网络相关数据,后期对采集的数据通过人工回放分析,筛选出质差问题或路段。现有技术主要是基于特定范围的测试,并依据测试系统输出的结果数据(包含表格和图形)进行人工筛查。
传统网络优化质差分析中,需要用到大量车辆、测试人员进行数据采集,包括周期性的道路测试等等,同时对于采集回来的数据需要专业人员进行复杂性分析,存在如下问题:
(1)测试设备:一次道路测试或拨打测试需要准备测试车辆、测试设备、定位设备、测试软件一套,设备成本投入大。
(2)人力成本:一次道路测试除了测试准备条件外还需要相应的测试工程师和分析工程师,人力资源浪费。
(3)分析周期:道路测试或拨打测试时,需要长时间进行测试数据搜集,分析周期较长。
(4)样本局限:驱车测试局限于车辆可通行的道路,拨打测试同样受限于人力。
(5)专业技能:基于人工分析时受限于分析人员的专业技能水平和经验,通常简单地对RSRP、SINR等单项指标进行分析。
基于以上不足,本文通过利用大数据和人工智能新型技术,引入了机器学习深度挖掘目前日趋完善的测量报告(Measurement Report)用户级软采数据,能够对全网质差用户进行建模,并自动输出质差用户,克服了传统人工质差分析的缺陷,具有较大的实际应用价值。
2 基于海量MR数据实现方法
2.1 技术特点及概述
通过分析海量用户的测量报告,提取主小区和邻区的网络质量指标数据进行数学建模,利用系统反馈结果,完善分析模型,达到对用户质差进行甄别的效果。同时结合定位技术,获取用户质差发生时的位置信息,从而能够更加全面、高效、准确地对全网质差用户进行评估。
2.2 新技术总体流程
通过对海量用户测量报告基础数据进行处理生成训练数据,并进行训练,生成判别模型,然后对判别结果进行验证,优化并完善训练模型,经过模型输出质差用户后,再进行空间定位以及场景映射,能够形成质差场景,并进行主动告警提示。具体实现的总体流程图如图1所示。
2.3 技术实现具体步骤
(1)基础数据准备
基础数据有路测数据和投诉数据两种,测试数据主要包含主小区的小区号(ECI)、频点(EARFCN)、物理小区识别号(PCI)、信号强度(RSRP)、信号质量(RSRQ)、下行信噪比(SINR)、邻区的频点(NEARFCN)、邻区物理小区号(NPCI)、邻区信号强度(NRSRP),邻区数量可能有0条或多条(一般不大于6条)。

图1 新技术总体流程
衡量无线网络质量好坏的关键指标为SINR和呼叫连续性,但是由于目标数据不包含下行信噪比,故在进行数学建模时不参与计算,因此需要找到影响SINR指标的影响因素,将其分解如下:

Signal为小区信号强度RSRP;Noise为网络背景噪声,一般用一个统一的值表示即可。由于TD-LTE网络是同频组网的,因此同频的其他邻区信号强度即为Interference;PCI为小区参考信号的位置,对参考信号的同邻频干扰有较大影响,因此在考虑干扰时必须参与计算。
呼叫期间的切换次数影响呼叫连续性,切换次数越多,造成通话断续或数据感知断续的可能性就更大,因此也需要考虑。
(2)训练数据预处理
通过对用户基础数据进行聚合运算,并根据最终衡量网络质量的指标形成如下属性作为训练数据维度。
◆上报点平均同频邻区数;
◆第一同频邻区出现个数;
◆主小区和同频邻区RSRP平均差值;
◆同频邻区RSRP标准差;
◆主小区平均电平;
◆主小区电平标准差;
◆电平差9 dB内,同频邻区数量;
◆电平差9 dB内,主小区PCI和邻区PCI模3相等邻区数量;
◆电平差9 dB内,主小区PCI和邻区PCI模6相等邻区数量;
◆电平差9 dB内,主小区PCI和邻区PCI模10相等邻区数量;
◆电平差9 dB内,主小区PCI和邻区PCI模30相等邻区数量;
◆电平差9 dB内,主小区PCI和邻区PCI模50相等邻区数量。
(3)训练数据建模
如果把质差分析看作对网络质差和非质差这个问题的判别过程,其基本流程遵循分而治之(divideand-conquer)策略,通过对质差用户训练数据进行学习,能够建立质差分类器模型,具体训练流程如图2所示。
假设训练数据集的样本集为D={(x1, y1), (x2, y2),…, (xm, ym)},其中每一个实例xi表示属性向量{ai1, ai2,…, aid},yi∈C{非质差,质差},则训练数据有属性集A={a1, a2, …, ad}。
本次训练数据建模中共搜集到训练数据集样本记录为3 652 210条,即ym中m的值为3 652 210,而属性向量为预处理中给出的维度,共12个维度,即ad中d的值为12,然后把训练数据集样本按类型判别模块和节点划分模块进行迭代递归处理,生成质差分类器模型并保存。
1)类型判别模块
模型形成过程中,算法会针对每一个当前节点即当前样本记录进行判断,检查其是否满足递归返回条件。当满足条件时,则标记当前节点为叶节点,并把该规则条件和叶节点进行保存;否则对当前节点继续进行划分。在基本算法中,有三种情形会导致递归返回:
◆如果D中样本属于同一类型C,则将当前节点标记为C类叶节点;
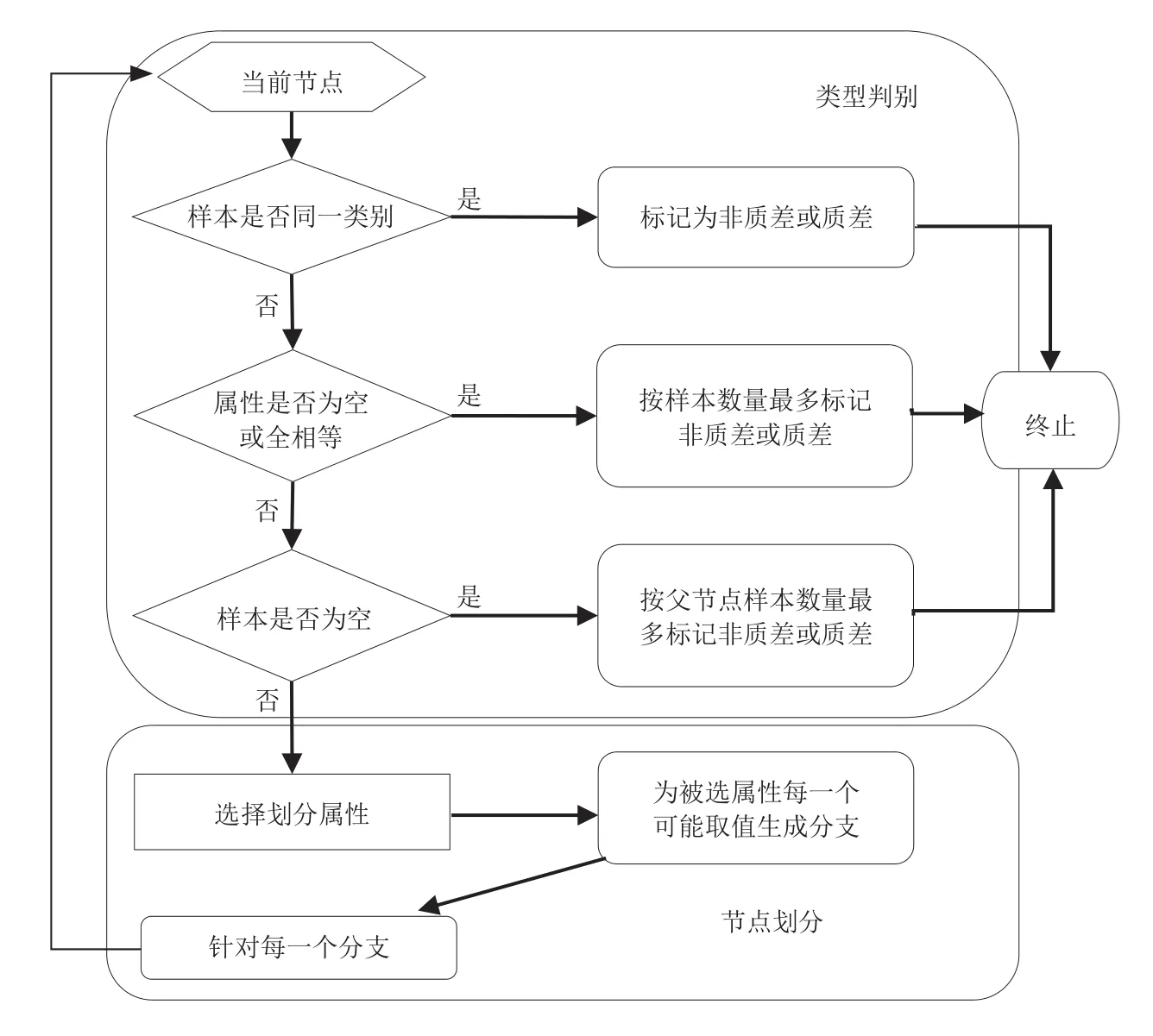
图2 训练模型流程图
◆如果A=φ OR D中样本在A上取值相同,即当前属性集为空,或是所有样本的所有属性向量相等,则将当前节点标记为叶节点,其类别标记为D中样本数量最多的类。
◆如果Dv=φ,即当前节点包含的样本集为空,则将分支节点标记为叶节点,其类别标记为D,即父节点中的样本,最多的类。
2)节点划分模块
分类器形成算法的关键是选择划分属性,即如何选择最优划分属性。一般而言,随着划分过程不断进行,希望分类器的分支节点所包含的样本尽可能属于同一类别,即节点的纯度(Purity)越来越高。
信息熵(Information Entropy)是度量样本集合纯度最常用的一种指标。假定当前样本集合D中第k类样本所占的比例为pk(k=1, 2, …, |y|),则D的信息熵为:
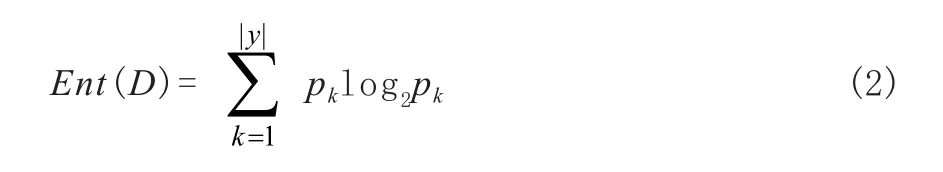
Ent(D)越小,则D的纯度越高。
因此通过计算样本集D的分支节点的信息熵,能够对样本集进行不断分支,而节点划分过程不断重复后,有时会造成决策树分支太多,导致某一个样本自身的一些特征被当作共性特征而导致过拟合,需要进行剪枝操作。
由于质差用户样本属性取值通常为连续型,因此需要对样本属性取值进行离散化,目前最常用的方法是二分法(Bi-Partition)。比如主小区平均电平≤54.495 7为一类,而主小区平均电平>54.495 7为另一类,这样就能对连续属性进行离散化处理,而每一次节点进行分支过程中,都能对样本集Ent(D)进行计算,比如按主小区平均电平分支后,Ent(D)的值为0.710 2,通过对样本集D不断分支和计算,可以得到如图3所示的样本数据分类树。
(4)数据建模优化
通过质差分类器模型进行质差判别生成质差用户结果后,需要抽样进行验证以得到分类模型的判别准确率。同时,将验证通过的数据补充进训练数据中,对分类器模型进行修正和调整,能够提升判别准确率。
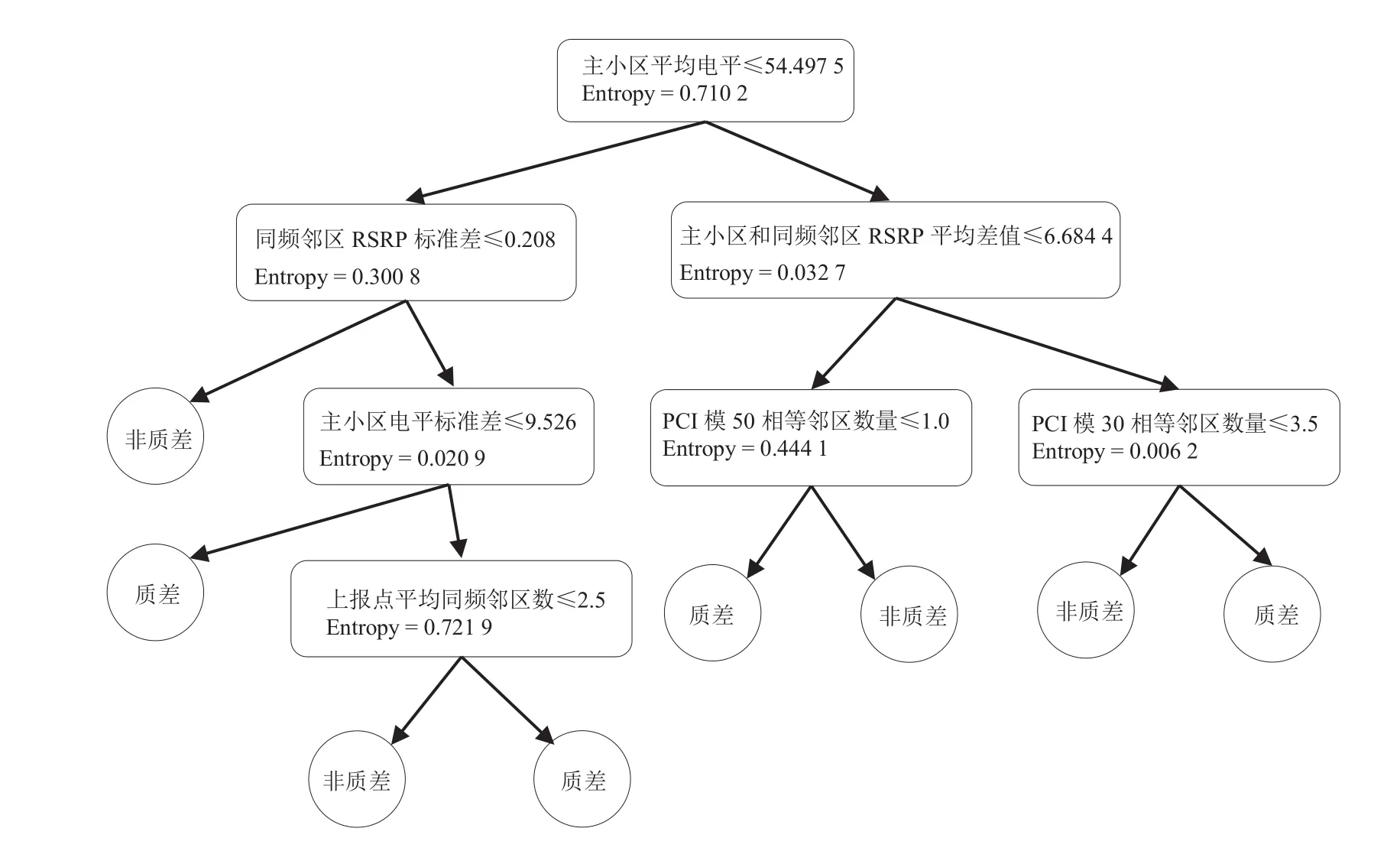
图3 样本数据分类树
3 应用案例
3.1 数据源情况说明
传统的质差分析是通过福建移动网优集中分析平台进行工单派发,然后由各地市网优分析人员通过测试分析软件进行人工筛选并标记质差问题路段,并保存到数据库中。
通过福建移动网优集中分析平台获取目前的历史质差路段作为训练样本,截止2017年11月全省质差问题路段共有831个。针对全省质差问题路段进行海量测量报告数据加工处理,以及网络质量指标预处理,共能生成测量报告质差用户训练数据3 652 210条,通过对训练数据进行质差用户判别建模,能够生成质差用户判别模型。
3.2 质差分类器评估
目前测量报告数据时间粒度为小时级别,通过将2017年12月01日24小时数据作为测试数据,分别对24小时数据进行质差判别模型处理后,生成质差标签,并把质差数据分别下发相应的地市,由分地市人员对质差结果进行确认,最终评估结果如表1所示。
省公司根据各地市反馈情况,随机抽取10%的反馈数据并按质差问题进行投票判决,超过半数认定为质差则判定该问题为质差。由于莆田、厦门、漳州三个地市反馈质量较差,所以投票区分了未剔除和剔除莆田、厦门、漳州的情况,最终获得质差判别模型平均准确率为75.13%,具体如表2所示。
3.3 质差分析效果对比
传统的人工质差分析,一般是在用户投诉网络质量后,根据投诉工单下发到对应地市,由地市路测和拨测人员对投诉用户的所属路段搜集网络质量指标,然后地市网络优化分析人员对指标进行分析,得到质差原因并给出修改建议。

表1 质差分类器准确率评估

表2 专家判别法评估
传统质差分析流程需要耗时5天左右,各地市需要配备1名网络优化分析人员和2名路测拨测人员进行配合处理,非常耗时耗力。而且由于路测和拨测的方式搜集到的网络质量指标有限,各地市网络优化分析人员水平参差不齐,导致目前的传统人工质差分析准确率平均在68.78%左右。
通过对质差分类器的反复评估以及对福州、厦门地市的抽样试点,福建移动全省落地了质差分类器来进行质差分析,除了提高质差分析的准确率,还大大提高了质差分析的效率,节约了大量的人力物力成本,详细质差分析对比效果如表3所示:

表3 质差分析效果对比
从表3可以看出,通过质差分类器建模方式,分析准确率提高了6.35%左右,全省可节省路测拨测人员共9个,质差分析流程的时长可以缩短一倍左右,而且传统质差方式处理都是先有投诉工单后处理,质差分类器建模方式可以预先对全网用户进行质差识别,并进行主动告警下发,属于预处理方式。
4 结束语
本文结合目前新兴的大数据和人工智能技术,引入了机器学习来深度挖掘日趋完善的测量报告数据。通过对基础数据进行预处理以及制定衡量网络质量相关指标后,针对现有质差问题路段,抽取质差用户特征,进而生成质差用户训练样本数据,然后通过分类器反复训练,形成质差分类器。利用质差分类器能够对全网质差用户进行判别,输出最终的质差用户,再通过对质差用户进行空间定位以及场景映射,能够形成质差场景,并进行主动告警提示。
总的来说,海量测量报告质差分类器建模方式在业内属于领先水平,具有极大的创新性和实用性,通过这种质差分析方式,不仅能够提高质差分析的准确率,节约大量人力物力成本,缩短质差分析周期,而且能够提前对质差用户进行预警处理,提高移动LTE用户的网络体验。
本方法的不足之处是由于目前质差用户训练样本有限,导致质差分类器的准确率只有75.13%左右。相信后期通过不断积累和学习质差判别反馈结果,能够继续完善质差分类器模型,提高质差分析的准确率。
