基于人工智能算法的功率域NOMA系统功率分配方法研究*
2018-09-03张少敏李立欣
张少敏,李立欣**
(西北工业大学电子信息学院,陕西 西安 710129)
1 引言
随着智能终端的广泛普及和移动新业务的持续增长,无线传输速率的需求呈指数增加。为了满足移动通信不断发展的需求,非正交多址(Non-Orthogonal Multiple Access,NOMA)技术已经成为通信发展中一个重要的技术支撑。NOMA具有高可靠性、高吞吐量以及广域覆盖的特点,而功率域NOMA因其可以为用户分配不同的功率值从而实现多址接入而成为5G发展中的潜在候选者[1]。本文重点研究功率域NOMA中的功率分配问题。
由于功率分配与整个系统的能量效率密切相关,因此在功率域NOMA的下行链路系统中,基站分配给用户的功率是影响系统性能的因素之一。因此,本文主要通过优化功率分配策略以提高系统的能量效率。
在已有的研究中,已经提出了多种不同的方法来解决功率分配问题。通过建立可支持每个用户数据速率要求的可行的发射功率范围,文献[2]提出了一种功率分配策略,以解决在使能量效率最大限度地满足每个用户所需的最低数据速率的过程中导致的非凸问题。在文献[3]中,通过引入松弛变量提出了一种基于约束凸优化的迭代算法,以将非凸优化问题转化为等价的两个凸函数的差值问题。这些方法的基本思路是将非凸问题转化为凸优化问题以解决功率分配问题,但是计算复杂度仍然不容忽视。因此,找到一种低复杂度的方法解决功率分配问题是很有必要的。
随着人工智能浪潮的到来,越来越多的问题可以通过机器学习来解决。作为机器学习的一个分支,强化学习算法因其可以通过一系列连续的决策实现特定的目标而在很多领域都展现出了其巨大的优势。文献[4]提出了在命名数据网络(Named Data Networking)中使用强化学习算法的可行性。通过修改Q-learning算法解决固有问题,设计和实施了IQ-learning(Interest Q-learning)和DQ-learning(Data Q-learning)策略,从过去的经验中学习并做出最佳的转发选择。文献[5]针对混合能量异构网络中的用户调度和资源分配研究了最优策略,并且通过采用Actor-Critic强化学习算法来最大化整个网络的能量效率。
由于强化学习算法在决策优化和动态分配方面的优势,针对功率域NOMA中的功率分配问题,本文采用无模型强化学习算法,即采用强化学习算法预测基站分配给用户的功率值,通过不断的迭代来提高系统的能量效率。
2 关键技术及基本算法
2.1 非正交多址(NOMA)
NOMA是一种新型的多址接入方式,在存在远近效应和广覆盖多节点接入的场景特别是上行密集场景中,采用功率复用的非正交多址方式和传统的正交多址方式相比,前者有明显的性能优势,更适合未来系统的部署。
功率域NOMA是NOMA中的一个分支,在发送端采用叠加编码(Superposition Coding,SC)的方式发送信息,主动引入干扰;在接收端采用串行干扰消除(Successive Interference Cancellation,SIC)技术以实现多路检测。与正交多址方式相比,虽然接收机复杂度有所提升,但可以获得更高的频谱效率。
2.2 深度Q网络(DQN)
深度Q网络(Deep Q Network,DQN)是一种融合了卷积神经网络(Convolutional Neural Network,CNN)和Q-learning的算法。其中,CNN的输入是原始数据(状态),输出则是每个动作对应的价值评估值函数(Q值);Q-learning是一种离线学习,所以每次DQN更新的时候,可以随机抽取一些之前的经历进行学习。随机抽取这种方法打乱了经历之间的相关性,使得神经网络的更新更有效率。DQN是第一个将深度学习与强化学习模型结合在一起从而成功地直接从高维的输入中学习控制策略的算法。在DQN中,用一个价值网络来表示评判模块,价值网络输出Q(s,a),即状态s下选择动作a的Q值。基于价值网络,可以遍历某个状态s下每个动作的价值,然后选择价值最大的一个动作输出。在此过程中,使用随机梯度下降方法来更新价值网络。
2.3 Actor-Critic
Actor-Critic结合了以值为基础(比如Q-learning)和以动作为基础(比如策略梯度)的两类算法,将两类算法的优点融合在一起,既可以学习值函数,也可以学习策略函数。Actor网络用来学习策略函数,产生选择某一动作的概率,Critic学习值函数,然后给Actor反馈方差比较小的值函数,之后Actor再根据Critic的反馈进行更新。
在Actor-Critic算法中,Agent根据Actor网络的策略进行动作的选择,之后将选择的动作作用于环境,而Critic网络由环境得到的即时奖赏更新值函数,并得到时间差分误差(Time Difference Error,TD Error),然后将TD Error反馈给Actor网络以便更好地更新策略函数。
3 系统模型
在本文中,基于单小区无线蜂窝网络的下行链路来建立模型,假设有单个基站和K个用户,并且所有终端都配备单个天线,基站在总功率的约束下向所有用户发送数据。假设信道服从瑞利衰落且其噪声为加性高斯白噪声(AWGN)。假定所有用户的瞬时信道状态信息(Channel Status Information,CSI)在基站处是已知的。为了不失一般性,把信道分类为0<|h1|2<|h2|2<…<|hk|2,其中hi(1<i<K)是第i个用户的信道增益,并且始终保持第i个用户的瞬时信道是最弱的。系统模型如图1所示。NOMA方案允许在基站处的SC和用户处的SIC技术的帮助下使用整个系统带宽传输数据来同时为所有用户提供服务。在功率域中执行用户复用,在接收机处采用SIC的方法消除多用户干扰。具体而言,当i<k时,第k个用户首先解码第i个用户的信息,然后按照i=1, 2, ...的顺序从它的接收信号中减去这个信息,再对第i个用户的信号进行解码;当i>k时,第i个用户的消息被视为噪声。第k个用户的可实现速率表示为:

B是系统的带宽,基站处的总功率为P,αk表示基站分配给第k个用户的功率与总功率的比值,且σ2是AWGN的功率,总的可实现速率可表示为:

其中Rk是用户k的速率,则整个系统的能量效率可以定义为系统的可实现总速率与总功率之比[6],即η=R/P。
本文研究功率域NOMA中的功率分配策略,通过优化基站分配给用户的功率分配系数来提高系统的能量效率。基站分配给用户的功率必须受限于系统的总功率P,同时,为了能成功实现SIC解码,用户的功率必然受到用户的功率的限制。因此,优化能量效率的问题可以表述如下:

其中,pk=αkP,Pmax是系统的最大功率。

图1 功率域NOMA下行链路通信场景
4 问题形成
强化学习的目标是通过试错学习经验将环境状态映射到最佳行动以最大化累积奖赏。功率分配问题可以表示为具有连续状态和动作空间的离散时间马尔可夫决策过程(Markov Decision Process,MDP)[7]。由于移动环境中状态转移概率和所有状态的期望奖励往往都是未知的,因此采用无模型强化学习算法在NOMA中制定功率分配问题。
一般情况下,M D P由一个四元数组表示,即M=<S, A, P, R>。
S表示状态空间,在功率域NOMA的功率分配问题中将任意用户的信噪比看作状态空间,它由信道增益hi、功率分配系数αi以及AWGN的功率σi2决定,因此,第t步的状态st(st∈S)可以定义为:
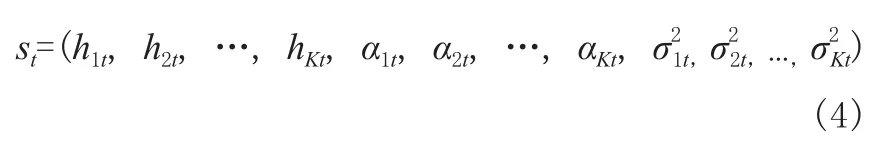
A表示动作空间,在功率域NOMA系统的功率分配问题中,将增加或减少基站分配给用户的功率看作动作空间,因此,第t步的动作at(at∈A)可以表示为:
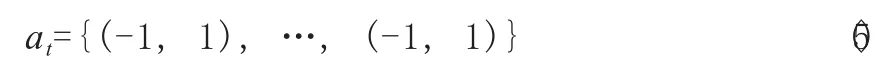
其中,-1表示减小基站给用户分配的功率,反之则用1表示。
P表示从某一状态转移到下一状态的概率,在连续MDP中,使用状态转移概率密度函数f来描述概率P,即:
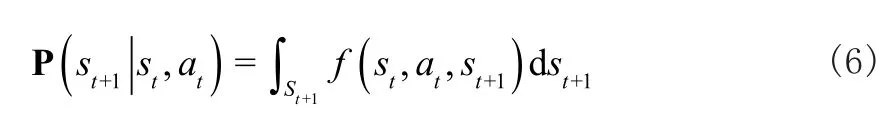
其中,st+1表示在(t+1)步的状态且st+1∈St+1⊆S。
R表示奖赏,即在状态s下选择动作a得到的即时奖赏。在功率域NOMA的功率分配问题中,将即时奖赏表示为:

强化学习算法的基本框架如图2所示。当选定某一状态s时,Agent会采取一动作a,将状态s以概率P转移到下一个状态s´,此时环境将把即时奖赏R反馈给Agent,不断迭代直到结束。Agent的目标就是在不断的学习下使总奖赏Rsum最大化,Rsum定义如下:

其中γ是折扣因子,有γ∈(0, 1),Rt表示第t步的即时奖赏。

图2 强化学习算法的基本框架
4.1 DQN
由图2可知,环境反馈给Agent的奖赏R和状态s以及动作a有关,在DQN算法[8]中采用状态动作值函数Q(s, a)来描述奖赏R与状态s和动作a的关系,定义如下:
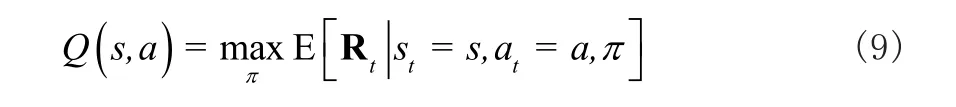
其中,π表示Agent学习到的策略。
当使用D Q N算法优化功率分配策略时,和Q-learning相比,DQN的状态增多,所以采用值函数近似[9]的方法对状态的维度进行压缩。在DQN算法中,用来近似状态动作值函数采用的方法通常是由神经网络构造的函数逼近器,即Q值神经网络定义如下:

其中,ω是神经网络的网络参数。
通过使损失函数最小化来训练ω,以得到最优的ω。所以,在Q网络中,使用均方差来定义的损失函数如下:

其中,s´、a´表示下一步的状态和动作。
然后计算L(ω)关于参数ω的梯度:

因此采用随机梯度下降的方法来训练神经网络以更新参数,最终获得最优的参数ω。
4.2 Actor-Critic
对于一个给定的MDP,强化学习算法的最终目的是找到一个使长期的奖赏总和最大的策略π*:

其中,E[.]表示期望值。
当使用Actor-Critic算法优化功率分配策略时,值函数和Q策略函数是分开进行更新的[10]。动作状态值函数表示从当前状态采取动作的累积奖赏的期望值,然后用给定的策略来选择应采取的动作。Critic部分采用状态动作值函数来计算累积回报,它可以表示为:

很显然,对于一个最优的策略π*,最优状态动作值函数为:

其中,Rt表示第t步的奖赏即系统的能量效率。
状态动作值函数用于了解在状态s下选取动作a时的效果好坏,它可以分为两部分:即时奖赏和后续状态的折扣值函数:

上述递归关系称为贝尔曼方程[11],它可以用来计算Q(s, a)的真实值。
TD Error可以通过在先前的状态下产生的状态动作值函数Q(st, at)以及在Critic部分产生的状态动作值函数Rt+1+Q(st+1, at+1)计算,即:

因此Critic部分更新状态动作值函数如下:

其中,αc表示Critic部分的学习速率。
之后通过将TD Error反馈给Actor指导其对策略进行更好地更新,其策略更新如下:

其中,αa表示Critic部分的学习速率。
如果每个动作在每种状态下执行无限次,并且算法遵循贪婪的探索,则值函数Q(s)和策略函数π(s, a)最终将以1的概率分别收敛至最优值函数Q*(s)和最优策略π*,此时系统的能量效率也达到最优。
5 仿真结果及分析
本节通过仿真来验证所提出的强化学习算法的有效性。在本文中,将基站分配给用户的总功率归一化为1 W,所有用户共享的带宽设置为1 Hz,功率分配系数αk∈[0, 1],折扣因子γ设置为0.9。
图3对比了所提出的强化学习算法的收敛性。DQN算法是基于值函数的强化学习算法,它不会产生振荡,但容易陷入局部最优,且收敛速度较慢。而Actor-Critic结合了以值为基础的和以策略为基础的强化学习算法,收敛速度变快,但是要谨慎选择学习速率以避免振荡情况的发生。在Actor-Critic算法中,为了避免振荡,学习速率一般都比较小,但是如果太小的话达到收敛需要很长时间,因此学习速率的选择必须很谨慎。

图3 不同算法的收敛性分析
图4对比了不同的算法随着用户数的增加能量效率的变化。由于Actor-Critic和DQN相比增加了以策略为基础的强化学习算法,因此不仅更新值函数而且更新策略函数,最终得到一个更优的功率分配策略。所以基于Actor-Critic算法的功率分配策略的能量效率比基于DQN算法功率分配策略的能量效率更好。但是随着用户数的增加,两种算法都呈下降的趋势,用户数到达一定值后,能量效率的值趋于平稳。
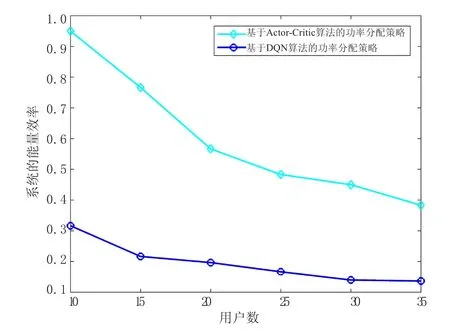
图4 不同算法的能量效率
6 结束语
本文利用人工智能中的无模型强化学习算法对功率域NOMA中的功率分配问题进行建模。将功率分配过程看作一个MDP,采用DQN和Actor-Critic两种强化学习算法对基站给用户分配的功率进行预测,以找到较优的功率分配策略,从而优化系统的能量效率。仿真结果表明所采用的两种算法都可以收敛,但相比之下Actor-Critic算法的收敛性优于DQN且Actor-Critic算法具有较好的优化效果。
