基于近红外光谱技术对多年际建三江、五常大米产地溯源
2018-08-31钱丽丽宋雪健张东杰张丽媛阮长青鹿保鑫
钱丽丽,宋雪健,张东杰,*,张丽媛,阮长青,鹿保鑫
地理标志作为一项知识产权已经得到国际认可并受到保护[1-2]。素有“贡米”之称的五常大米及“中国绿色米都”建三江种植建三江大米因其籽粒饱满晶莹剔透,营养丰富,清香适口等特点被评为地理标志大米[3],备受消费者青睐,具有广阔的市场前景。一些不法商贩以此为“良机”开始制售假大米,以谋取利益,严重损坏了地理标志大米的品牌效益,并扰乱了市场秩序。因此,为实现对地理标志大米的产地保护研究,开发一种快速鉴别地理标志大米技术是亟待解决的问题之一。目前,对大米产地溯源的研究技术主要有电子鼻技术[4]、电子舌技术[5]、矿物元素指纹分析技术[6]、DNA指纹分析技术[7]、电感耦合等离子技术[8]、拉曼光谱技术[9]、近红外光谱技术[10]等。与其他技术相比较近红外光谱具有快速、高效、无损、适用范围广等特点。
近红外光谱分析技术是利用近红外谱区包含的丰富的物质信息,同时吸收带的吸收强度与分子组成或化学基团的含量有关可用于测定化学物质的成分和分析物理性质[11],对于多组分的复杂样品,其近红外光谱也不是各组分单独光谱的简单叠加,因此,近红外光谱技术需要结合“化学计量法”对光谱信号进行处理,从而提取食品中的有效信息[12],其研究结果较为理想。近红外光谱的采集方式主要有透射式、漫反射式、透漫射式3 种,在对固体样品光谱采集时多以漫反射为主,而其他两种方式多用于液体样品的光谱采集。范积平等[13]研究发现利用近红外漫反射光谱技术能实现对来自甘肃、青海、陕西的大黄药材进行产地鉴别。Sinelli等[14]通过传统感官评价方法并结合近红外漫反射光谱技术对112 组初榨橄榄油进行了产地溯源研究,发现采用线性判别式分析和簇独立软模式分类法对初榨橄榄油产地的判别正确率分别为71.6%、100%。也有学者将近红外漫反射技术用于小米[15]、小麦[16]、茶叶[17]等产地溯源。目前,应用近红外漫反射光谱技术对大米研究多集中在品质检测及少量单一年份产地判别,鲜见应用该技术对多年际大米进行产地溯源的研究。本研究采用近红外漫反射光谱技术对多年份大米进行产地溯源研究,为地理标志大米产地保护研究提供理论研究基础。
1 材料与方法
1.1 材料与试剂
于2013—2015年采集建三江、五常地区及2015年试验田的样品,均为田间采样,采用3 点随机取样的方式进行采集,每份样本采集2 kg装入尼龙网兜,并记录采样信息,所有水稻品种均为粳米。除试验田样品外,其余均归为随机样品。样本详细信息见表1、2。
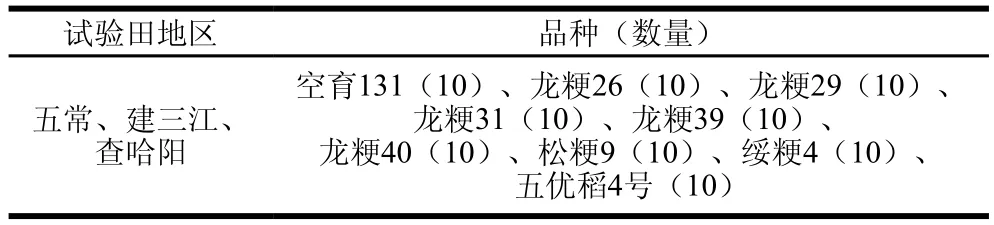
表1 试验田样品信息Table 1 Information about rice samples from experimental field
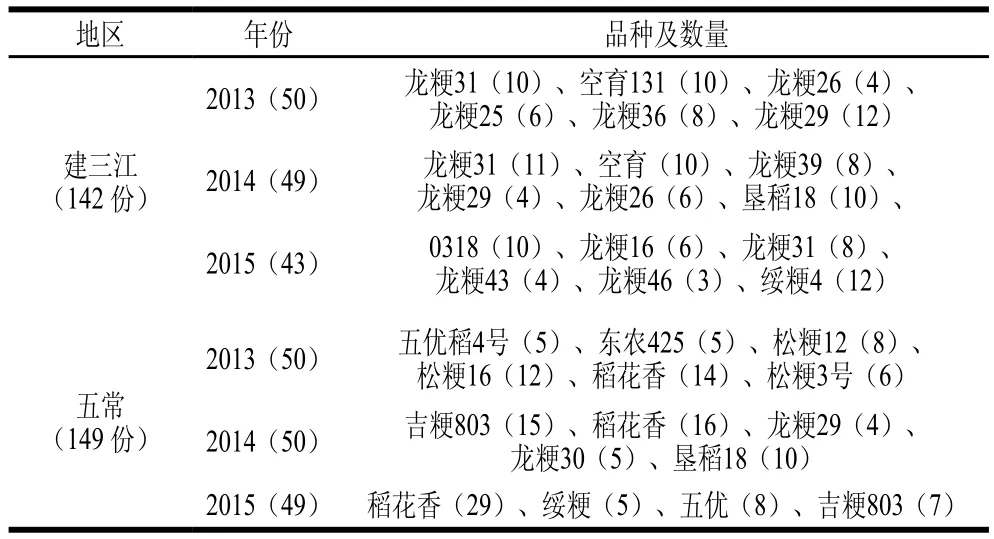
表2 随机采样样品信息Table 2 Information about randomly collected rice samples
1.2 仪器与设备
FC2K砻谷机 日本大竹制作所;VP-32实验碾米机日本山本公司;FW100高速万能粉碎机 天津泰斯特仪器有限公司;TENSORII型傅里叶变换近红外光谱仪(漫反射镀金积分球、InGaAs检测器) 德国布鲁克(北京)科技有限公司。
1.3 方法
1.3.1 水稻试验田的构建
于2015年,以粳稻主产区黑龙江省(五常、建三江、查哈阳)为试验点,建立3 块试验田。每块试验田种植主栽中晚熟品种9 个分别为空育131、龙粳31、龙粳26、龙粳29、龙粳39、龙粳40、松粳9、五优稻4号、绥粳4,各试验田育苗移栽、秧田管理、施肥、灌溉均按当地生产习惯,所有品种同期播种。采用3 次重复随机区组设计,小区面积不少于10 m2。四周设保护行,保护行品种与各对应品种相同。
1.3.2 样品的前处理
采集回来的样品经过晾晒、去石、脱粒等前处理后,在实验室采用统一加工方式对其进行垄谷、碾米、粉碎、过筛(100 目),待测。每个样品砻谷2 次。碾米的进样量为3 次,碾米3 次,白度为3 次。
1.3.3 样品原始光谱的采集
将傅里叶变换近红外光谱仪预热30 min,打开OPUS 7.5软件经由检查信号、保存峰位,扫描背景单通道光谱,每间隔1 h扫描一次背景来消除外界信息干扰保证光谱的稳定性以减少误差。将样品粉末倒入玻璃杯中,用压样器压实,测量样品单通道采集样品光谱。环境温度为室温(25±1)℃,相对湿度为20%~30%,光谱波数范围12 000~4 000 cm-1,分辨率8 cm-1,扫描64 次。
1.3.4 样品选取
试验田样品用于与产地因素有关的特征波段筛选。其余样品则选择各地区样品总量的2/3作为建模样品用于模型的建立,1/3作为预测样品集用于模型的验证。各地区用于建模和预测的样品数见表3。

表3 建模与预测样品Table 3 Modeling and prediction set samples
1.3.5 试验田近红外光谱数据处理
应用OPUS 7.5软件分别对试验田样品的原始光谱进行一阶导数预处理消除噪声、基线漂移、光色散等因素的干扰及防止过拟合现象的出现,应用SPSS 19.0软件对试验田样品进行方差分析筛选出与产地有关的波段,并用于随机样品产地溯源研究。
1.3.6 模型的建立及验证
1.3.6.1 定性分析模型建立
采用OPUS 7.5软件在特征波段下利用因子化法和欧式距离法对随机样品进行定性分析模型建立研究,预处理方式分为矢量归一化(standard normal variate,SNV)、一阶导数+平滑(5、9、13、17、21、25 点,下同)、一阶导数+SNV+平滑、二阶导数+平滑、二阶导数+SNV+平滑等,消除无关信息的干扰,提高模型的精度。通过比较选择性S值最终确定定性分析模型的建立方法,其中S值表征样品之间的距离,当S值小于1时,表示两类样品“相交”,样品未被均一鉴别;当S值为1时,表示两类样品“相切”;当S值大于1时,表示两类样品“相离”,样品被均一鉴别,故S值越大于1,模型的效果越好。同时利用因子化法和欧式距离法对随机样品进行聚类分析模型建立研究,预处理方式与上述相同。并通过比较样品之间的“距离”大小确定建模方法,其中样品之间的“距离”越大越好。
1.3.6.2 定量分析模型建立
采用留1交叉检验的检验方法以偏最小二乘(partial least squares,PLS)法在特征波段进行定量分析模型的建立,分别将建三江大米的组分值赋值为-1、五常大米的组分值赋值为1,以0为衡量标准,预测值小于0为建三江大米、预测值大于0为五常大米[18]。原始光谱的预处理方式有消除常数偏移量、减去一条直线、SNV、最小-最大归一化、多元散射矫正(multiplicative scatter correction,MSC)、内部标准、一阶导数+平滑、二阶导数+平滑、一阶导数+减去一条直线+平滑、一阶导数+SNV+平滑、一阶导数+多元散射校正+平滑,通过交互验证均方根误差(root mean square error of cross validation,RMSECV)及定向系数(R2)来衡量模型的好坏,其中R2数值越接近100%则预测含量值越接近真值;RMSECV数值越小越好;同时RMSECV先随维数的增大快速下降后略微逐渐增大,模型效果较好,进而确定定量分析模型。
1.3.6.3 模型验证
利用OPUS 7.5软件分别选择定性分析、聚类分析、定量分析工具栏,调入模型,调入预测样品光谱图,测定得出结果。
2 结果与分析
2.1 大米近红外原始光谱分析结果

图1 试验田样品(A)和随机样品(B)近红外原始光谱图Fig. 1 NIR Spectra of experimental field samples (A) and random samples (B)
大米近红外原始光谱如图1所示,在波段为7 500~9 000 cm-1处(I区)是C—H第3组合频区,其中8 321 cm-1附近的吸收峰是由脂肪烃中甲基(—CH)基团引起的;5 500~7 500 cm-1处(II区)是C—H第2组合频区,在6 846 cm-1附近的吸收峰是因—CH2二级振动所引起的,因与样品中氨基酸种类及含量有关,所以较I区信息稍微强些;4 000~5 500cm-1处(III区)是C—H第1组合频谱区,是表征蛋白质及淀粉物质中的N—H、C—H、O—H及C=O键振动的要区间,其中5 173 cm-1处的吸收峰与其有关[19]。不同产地及不同品种之间的近红外光谱相似,采用一阶导数对试验田原始光谱预处理后进行方差分析,结果表明,不同地区来源的样品在波段5 136~5 501 cm-1处均有显著差异,说明不同地区间样品的近红外光谱存在显著性差异。在特征波段对大米进行产地溯源研究具有较强的代表性[20]。
2.2 不同预处理方式对定性分析建模效果的影响
近红外光谱虽然包含了丰富的物质信息,但谱峰重叠、信号较弱、谱带较宽,难以像中红外光谱那样进行结构剖析,因此近红外光谱的定性分析主要用于物质的种属判别,即通过比较未知样品与已知样本或标准样本的光谱确定未知样品的归属[21]。在特征波段5 136~5 501 cm-1范围内分别采用因子化法和欧式距离法对随机样品的原始光谱进行定性建模分析,如表4所示。结果表明,采用因子化法结合二阶导数+SNV+5 点平滑的预处理方式建立的模型效果较好,两地区的样品被均一鉴别,其中模型的S值为1.324 005,故选此方法建立定性分析模型,如图2所示。王梦东等[22]利用近红外漫反射光谱技术结合因子化法在特征波段7 400~9 900 cm-1范围内采用二阶导数+矢量归一化+21 点平滑对白茶、红茶及乌龙茶进行判别研究,研究发现采用近红外漫反射光谱技术结合因子化法在3类茶叶的判别中具有可行性。张敏等[23]研究发现,利用近红外漫反射光谱技术结合因子化法在特征波段4 482~5 238、5 369.1~6 950.5 cm-1范围内采用一阶导数+矢量归一化+13 点平滑的预处理方式能实现对来自6 个地区的鸡血藤的产地溯源判别研究。

表4 不同预处理方式对定性分析模型效果影响Table 4 Effects of different pretreatment methods on qualitative analysis model
通过对原始光谱进行主成分分解,选取特征值较大的几个主成分得分特征变量参与模式识别,在进来保留有用信息的前提下,不仅压缩了原始光谱,而且这些变量是沿最大方差方向得到的,还起到特征信息提取的作用。而标准算法采用的是欧式距离,直接使用吸光度计算光谱距离,不能体现特征变量的变化情况。因此,采用因子化法建立的模型精度要优于欧式距离法。

图2 因子化法2D得分图Fig. 2 2D score plot by factorization method
2.3 不同预处理方式对聚类分析建模效果的影响

表5 不同预处理方式对聚类分析模型效果影响Table 5 Effects of different pretreatment methods on clustering analysis model

图3 不同地区大米样品的聚类分析结果Fig. 3 Cluster analysis of different geographical rice samples
聚类分析用于判定一系列近红外谱图的相似性,是根据样本自身的属性,用数学方法按照某种相似性或差异性指标确定样本之间的亲疏关系,并按这种亲疏关系程度对样本进行聚类。与定性分析不同,它不需要输入任何信息,聚类分析只将相似光谱按组分类[24]。在特征波段5 136~5 501 cm-1范围内分别采用因子化法和欧式距离法对随机样品的原始光谱进行聚类建模分析,如表5所示。结果表明,采用因子化法结合二阶导数+SNV+5 点平滑的预处理方式建立的模型效果较好,两地区样品被正确分类,且“距离”为0.918 00,如图3所示。故选此方法建立聚类分析模型。庞艳苹等[25]利用近红外漫反射光谱技术因子化法在4 000~8 003.8 cm-1范围内采用二阶导数+5 点平滑的预处理方式对255 份草莓进行产地溯源研究,结果表明,其模型的预测正确率高达96.70%。也有学者发现在特征波段4 000~7 500 cm-1范围内采用因子化法结合一阶导数+矢量归一化+17 点平滑的预处理方法建立的模型能够实现对久保桃的产地鉴别[26]。
2.4 不同预处理方式对定量分析建模效果的影响
建立定量分析模型的目的是对多组分样品的相关组分进行定量分析。首先需要选择能够代表待测体系的已知组分的建模样品,然后用这些样品的近红外光谱和组分值来拟合模型,经过检验其预测的可靠性之后,这个模型就可用来分析未知样品的组分值[27]。PLS法将用来寻找光谱与浓度数据矩阵之间的最佳相关函数关系,具有更易于辨识系统信息与噪声的优点,使其拟合的模型精度更高[28]。在特征波段5 136~5 501 cm-1范围内采用PLS法结合交叉检验法对原始光谱进行处理,如表6所示。结果表明,采用一阶导数+MSC+13 点平滑的预处理方式建立的模型效果较好,其RMSECV为0.105,R2为98.97%,维数为4,故选此方法来建立定量分析模型。如图4、5所示。汪静静等[29]研究发现利用近红外漫反射光谱技术在特征波段7 559~8 531 cm-1范围内采用二阶导数+MSC+5 点平滑建立的定量分析模对来自3 个地区的74 份人参样品进行产地判别,其正确率高达90%。赵艳丽等[30]在波段4 007.35~7 135.33 cm-1,采用近红外漫反射光谱技术结合PLS判别分析法对3 个不同产区的70 份野生药用植物重楼建立判别模型,其预测正确率为100%。
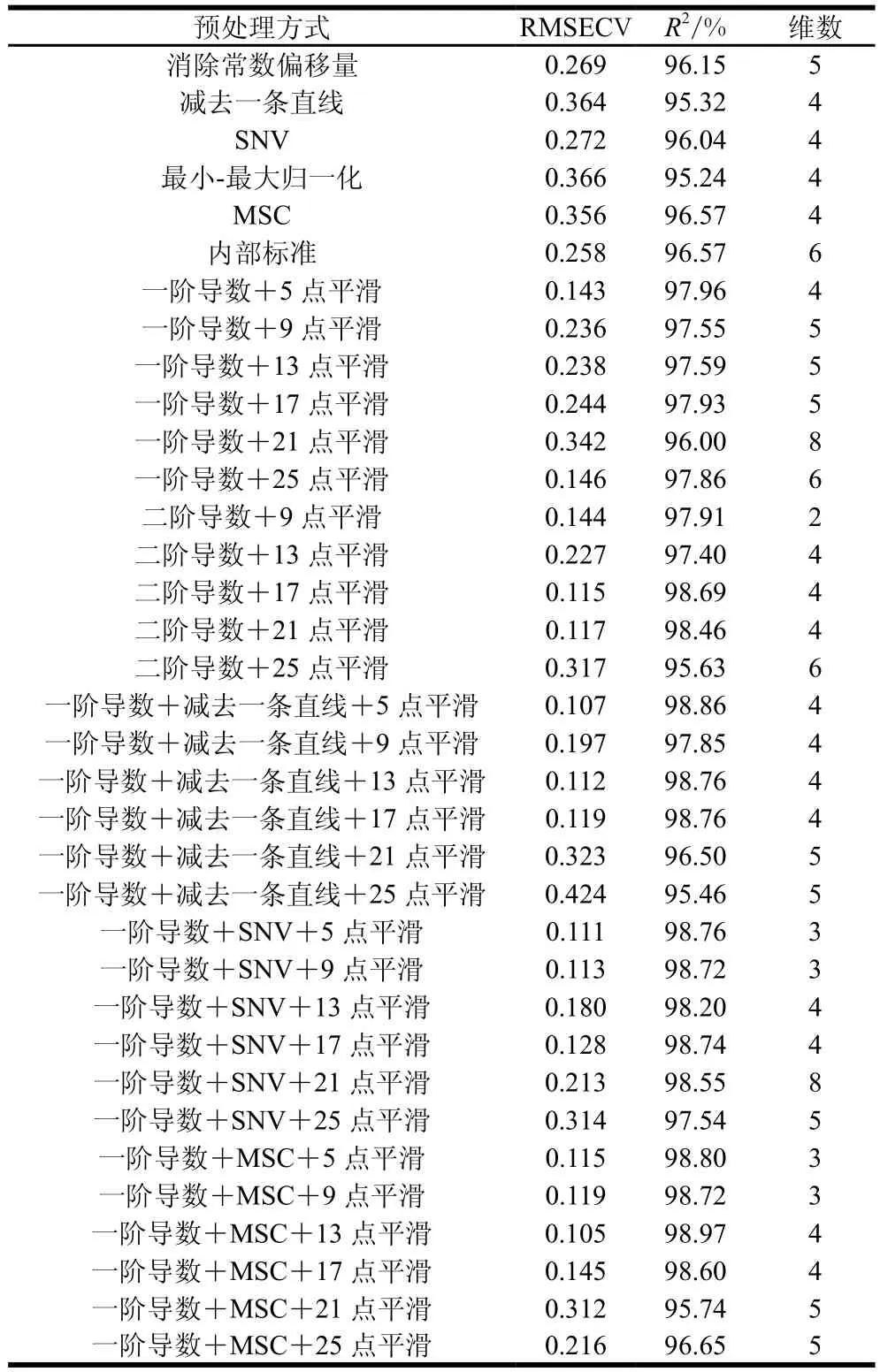
表6 不同预处理方式对定量分析模型效果影响Table 6 Effect of different pretreatment methods on quantitative analysis model
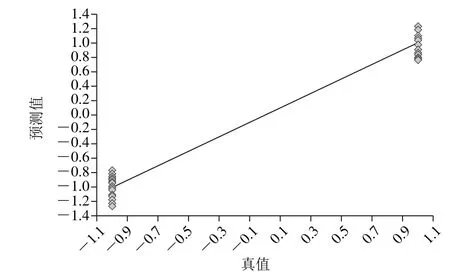
图4 地区预测值与参考值相关图Fig. 4 Predicted value versus reference value
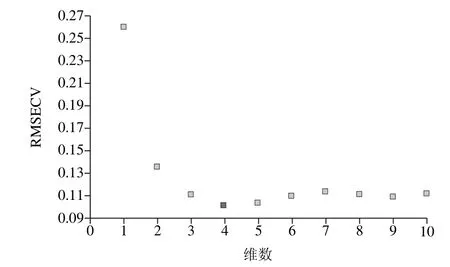
图5 RMSECV与维数的关系图Fig. 5 RMSECV against dimensionality
2.5 大米产地溯源模型验证
将建立好的定性分析模型、聚类分析模型及定量分析模型分别带入OPUS 7.5软件中,对预测样品进行验证,结果表明,定性分析模型对建三江大米及五常大米的正确判别率分别为100%、98%。聚类分析模型对建三江大米及五常大米的正确判别率分别为97.92%、98.00%。定量分析模型对建三江大米及五常大米的正确判别率分别为95.83%、94.00%,如表7所示。
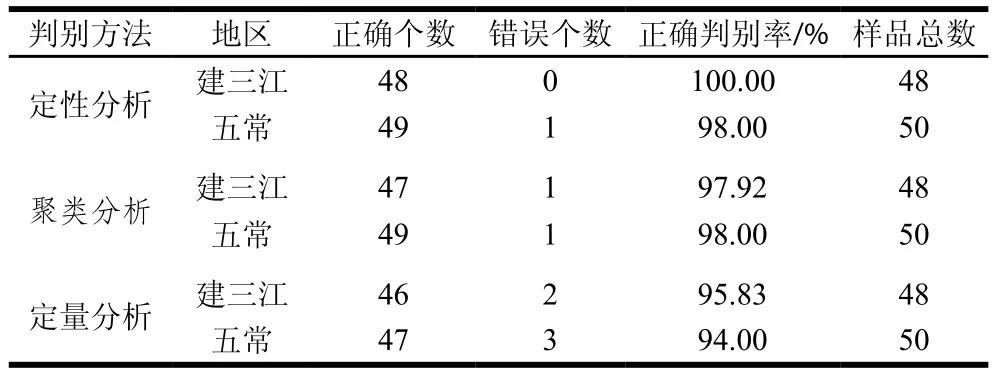
表7 模型鉴别结果Table 7 Results of model validation
3 结 论
对大米进行产地溯源判别研究易受到产地、品种、施肥量等因素的影响,故为筛选与产地有关的因素实验于2015年在黑龙江五常、佳木斯、齐齐哈尔三地建立试验田,进行特殊波段的筛选,通过对试验田样品进行一阶导数处理得出特征波数范围为5 136~5 501 cm-1。在特征波段范围内对2013年至2015年来自建三江地区及五常地区的291 份大米进行产地溯源研究,结果发现,采用因子化法结合二阶导数+SNV+5 点平滑的预处理方式建立的定性分析模型对建三江大米及五常大米的正确判别率分别为100%、98%。采用因子化法结合二阶导数+矢量归一化+5 点平滑的预处理方式建立的聚类分析模型对建三江大米及五常大米的正确判别率分别为97.92%、98.00%。采用PLS法结合一阶导数+MSC+13 点平滑的预处理方式建立的定量分析模型对建三江大米及五常大米的正确判别率分别为95.83%、94.00%。其中定性分析与聚类分析的最优处理方法相一致。故应用近红外漫反射光谱技术可以实现对多个年份大米的产地鉴别。大米产地溯源受多种因素影响,今后可以从土壤、基因型、施肥量等多种因素进行研究。
