兼顾重要性与可靠性的科学基金项目绩效评价方法*
2018-08-31杜元伟王素素
杜元伟 杨 宁 陈 群 王素素
(1.中国海洋大学 管理学院,山东 青岛 266100;2.中国海洋大学 海洋发展研究院,山东 青岛 266100)
一、引言
《科技评价工作规定(试行)办法》指出,政府管理部门及相关方面要委托评价机构或组织专家评价组,运用合理、规范的程序和方法,对科技活动及其相关责任主体所进行的专业化评价与咨询活动,旨在优化科技管理决策,加强科技监督问责,提高科技活动实施效果和财政支出绩效。国家863计划、国家973计划、国家自然科学基金、国家社科基金、教育部人文社科基金等科学基金项目是科技活动的重要组成部分,它们对提升科技水平、促进经济增长、提高社会福利、增强国家竞争力起到了重要的支撑作用。目前已有专家学者从影响因素分析、指标权重确定、评价方法构建等方面对科学基金项目的绩效评价问题进行了研究。其一,在影响因素分析方面,现有成果主要是通过定量或者定性分析找出影响科学基金项目绩效评价的因素,为科学构建科学基金项目指标体系提供依据。[1-3]例如:王长峰利用灰色模型及柯布道格拉斯生产函数就互联网的发展对科学基金项目的绩效影响进行定量分析。[4]其二,在指标权重确定方面,现有成果主要是应用主观赋权、客观赋权、主客观交叉赋权等方法确定科学基金项目绩效评价指标的权重,进而依据该权重对各项指标上的绩效表现信息进行综合集成计算项目取得的绩效。如:Jung采用网络分析法(Analytic Network Process, ANP)、[5]Nilashi采用决策试验和评价实验室(Decision Making Trial and Evaluation Laboratory, DEMATEL)和ANP相结合的主观赋权方法确定各项指标的权重;[6]Charttirot采用逼近理想解排序法(Technique for Order Preference by Similarity to Ideal Solution, TOPSIS)等客观赋权方法确定指标权重;[7]关于主客观交叉赋权法,Mohaghar采用将模糊集与ANP相结合的方法确定指标权重,[8]Sangaiah等采用将模糊集、DEMATEL、TOPSIS等进行结合的主客观交叉赋权方法确定指标权重。[9-10]其三,在评价方法构建方面,现有成果或者侧重于从项目产出视角构建能够确定项目绩效效果的评价方法,或者侧重于从项目投入与产出双重视角构建能够确定项目绩效效率的评价方法。如:在项目绩效产出评价方面,肖人毅、Feng、Liu、Gülçin分别采用统动力学仿真、专家系统整合法、智能决策支持法、多准则妥协解排序法(VIKOR)进行项目产出绩效评价;[11-14]在项目绩效投入产出评价方面,吴建南、杨方娟、宋志红基于循证设计和倾向得分分层等方法得出科学基金资助确实提高科研产出的结论;[15-17]李志兰、Chun、Karasaka采用数据包络分析(Data Envelopment Analysis,DEA)对科学基金的整体投入产出效率进行分析,得出加大科学基金的投入力度有助于提高产出效率的结论;[18-20]段庆锋、杨雨昆采用DEA两阶段模型分析了科学基金项目投入产出效率问题并指出效率瓶颈在于知识生产阶段。[21-22]
上述研究成果对丰富科学基金项目的绩效评价理论和方法起到了重要作用,也为启发本文研究思路、构建理论方法起到了借鉴作用。上述成果中的决策信息主要来源于专家对科学基金项目在各项评价指标上绩效表现的主观判断,最终绩效评价结果是对专家主观判断信息的综合集成。一些成果认识到知识经验、认知能力等诸多方面的差异可能会导致源于不同专家的决策信息的可利用程度并不相同,为此借鉴在多属性决策中利用指标权重对决策信息进行线性加权的融合思路,提出了利用专家权重对主观判断信息进行综合集成的应对策略。然而,多属性决策中的指标权重与群体决策中的专家可靠性是两个截然不同的概念。前者用于反映一个指标相对于另一个指标的重要程度,取决于决策者偏好,具有主观性和相对性,而后者常用于反映一个信源在一段时间内和一定条件下无故障地执行特定功能的能力或可能性,具有客观性和绝对性。需要注意的是,目前对于指标权重的内涵及其确定方法已经在业界达成共识,而专家可靠性确是一个近几年刚刚被关注的新概念。在群体决策领域,有关专家可靠性的研究成果并不多见,个别成果提出了专家可靠性的计算方法,如熵值法、偏离目标测算法等,[23-25]其他成果则是直接根据统计信息给出专家可靠性的具体数值。[26-27]本文中的专家可靠性将遵循第二种思路予以确定。由信息融合理论可知,基于指标权重的融合策略和基于可靠性的融合策略并不相同,前者应采用补偿性策略、后者应采用非补偿性策略(原因详见后文)。现有成果因融合策略选择不当而造成对科学基金项目绩效评价结果的科学有效性是有待商榷的。有鉴于此,本文在考虑指标权重与专家可靠系数之间性质差异的基础上,提出了兼顾重要性与可靠性的科学基金项目绩效评价方法。
二、科学基金项目绩效评价机理
科学基金项目绩效评价问题一般是基于专家对待评项目在各项评价指标上绩效表现判断来确定项目综合绩效表现的等级。下面从专家评价信息表达、个体补偿性融合、群体非补偿性融合三个层面构建科学基金项目的绩效评价机理。
基于基本信任函数的信息表达机理。在进行项目绩效评价时,专家需要对待评价项目在各项评价指标上的绩效表现情况进行判断,但是工作经验、专业背景等方面的差异使得各类专家都有自己擅长的领域,他们能对与自己领域相关性高的指标做出完备性评价,对相关性一般的指标做出相对完备的评价,对相关性低指标可能做不出任何的评价。因为专家在各项指标上给出评价信息的完备程度可能并不相同,所以为了有效地提取专家对科学基金项目在各个指标上绩效表现的不完备性评价信息,合理地描述专家的真实推断情况,本文利用证据理论中的基本信任分配函数(Basic Belief function,BBA)构建提取专家判断信息的表达机理。BBA函数是证据理论中的一种证据信息表达方式,能够利用局部不确定和全局不确定描述相对完备和不完备的推断信息。
基于指标权重的个体信息补偿性融合机理。个体信息融合是指为了得到某一专家对科学基金项目的综合性评价信息而对其在所有指标上给出的绩效评价信息进行融合的过程。当项目在某一指标上表现优秀,在另一项指标(如人才培养)表现中等,利用指标权重对两方面信息进行融合后得到的综合评价等级为良好是可能的。上述过程体现了专家评价在信息在不同指标之间是可以相互补偿的,故基于指标权重的个体信息融合要遵循补偿性融合策略。考虑到证据推理(Evidential Reasoning, ER)规则常被用于解决指标之间具有补偿性的多属性决策问题,[28]故本文采用ER规则对专家在各项指标上的评价信息进行融合。
基于专家可靠系数的群体信息非补偿性融合机理。群体信息融合是指为了从专家群体视角得到他们对科学基金项目的综合性评价信息而对所有专家个体融合结果进行再融合的过程。如果某位专家认为科学基金项目整体绩效表现(经过个体融合得到的结果)一定不是优秀,而他又是绝对可靠的(给出无误信息的可能性是100%),那么显然该项目最终评价等级一定不应该是优秀(否则会与该专家具有绝对可靠性相冲突)。这体现了专家之间非补偿性的特点,故基于专家可靠系数的群体信息融合应遵循非补偿性融合策略。考虑到证据理论(Dempster-Shafer Theory of Evidence, DS)中的Dempster规则具有“一票否决”的性质,能够反映证据融合的非补偿性特征,故本文采用该规则对群体信息进行融合。[29]
兼顾重要性与可靠性的科学基金项目绩效评价机理可以描述为:先基于基本信任分配函数信息表达机理提取专家对科学基金项目在各项指标上的不完备性评价信息,再以专家个体为单位、利用ER规则对各项指标上的评价信息进行补偿性融合,最后利用Dempster规则对所有专家的个体评价结果进行非补偿性融合。上述绩效评价机理可描述为下图形式。
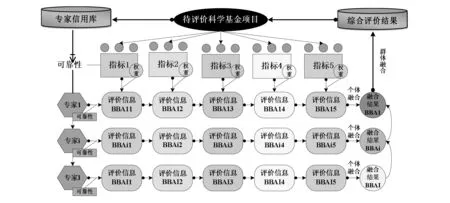
图1 科学基金项目绩效评价机理
三、科学基金项目绩效评价方法
(一)评价信息提取


(1)

(二)个体信息的补偿性融合
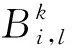
(2)

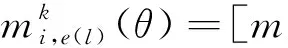
(3)
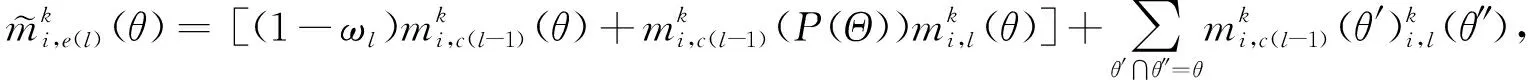
(4)
(5)
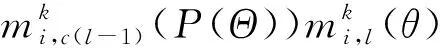

(6)
(三)群体信息的非补偿性融合
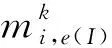
(7)
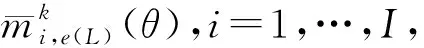
(8)
由式(8)的性质可知,若只要有一位绝对可靠的专家反对科学基金项目的绩效评价结果隶属于某个或某几个等级,则无论其他专家的意见如何,该项目的绩效评价结果一定不会隶属于这些评价等级。这体现了Dempster规则能够反映群体信息融合具有非补偿性的特点。
(四)评价等级确定方法
由式(8)可知,mk(θ)为所有专家对项目ak最终绩效隶属评价等级的评价结果。因为mk(θ)依然是一种BBA函数形式,其中可能存在着局部确定和全局不确定,所以为了确定项目ak的最终隶属评价等级,需要对该结果进行转换处理。这里采用被业界学者广泛接受的且能兼顾信度函数和似然函数双重优势的Pignistic概率进行转换。[30]依据Pignistic概率计算规则,确定项目ak最终绩效隶属评价等级θn的计算公式如下:
(9)
其中,Belk(θn)=∑θ⊆θnmk(θ),Plk(θn)=∑θn∩θ≠∅mk(θ),εk=[1-∑θn⊆ΘBelk(θn)]∑θn⊆ΘPlk(θn)。

(五)专家可靠系数计算方法
关于可靠性的描述,多出现在电气工程领域,常用可靠性系数来刻画可靠性,以此为鉴,专家的可靠性由专家的可靠性系数来表示。[33-38]在科学基金项目绩效评价中,每位专家都可以视为一个信源,则专家的可靠系数是专家对科学基金项目绩效评价问题给出无误信息的可能性,其值的确定可根据专家历史评价信息予以确定。由实际情况可知,大部分的科学基金项目都是可以顺利结题,只有极个别项目会存在不能结题或者延迟结题的情况。如果采用准确率,即专家认为可以结题的项目数和已经结题的项目数进行比较,则可能会导致这样一个现象,一位评审专家总是给出建议结题的评价结果,不考虑项目完成的质量,这位专家仍然具有较高的可靠性系数,这并不能很好地区分专家之间的可靠程度,故采用该种方法处理刻画专家可靠性系数存在问题。考虑到上述情况,本文建议构建混淆矩阵方法确定专家可靠系数。[39]混淆矩阵也称误差矩阵,是表示精度评价的一种标准格式,不仅具有很好地描述误差的能力,且计算方法简单,易于理解和实际应用。
设Y、N分别表示专家建议结题、不建议结题的项目数,T、F分别表示该项目实际结题、实际未结题的项目数,则YT表示建议结题并实际已结题的项目数,YF为专家建议结题而实际没有结题的项目数,NT为不建议结题但实际已结题的项目数,NF为不建议结题且实际结果并没有结题的项目数。为计算专家可靠性,构造如下表所示的混淆矩阵。[28]
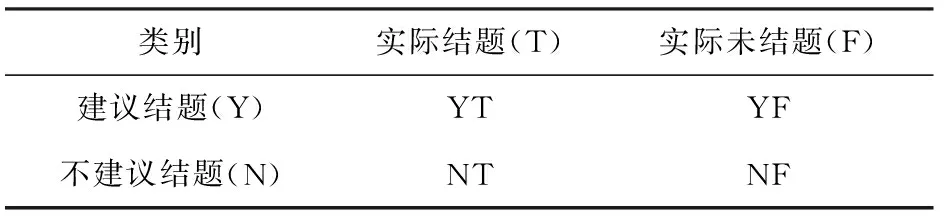
表1 混淆矩阵
专家的可靠性系数可由式(10)予以计算。
(10)
例如:若专家共评价项目20项,给出评价结果中,“建议结题”16个,“不建议结题”4个,其中“建议结题”且“实际已结题”项目数为13,“不建议结题”且“实际未结题”项目数为2。根据式(10)计算可得到专家评价的可靠性r=0.75。不难发现,专家的可靠性并非一成不变,而是会根据专家评审结果的准确率予以动态调整。
(六)方法步骤
遵循前文提出的科学基金项目绩效评价机理,基于评价信息提取、个体信息的补偿性融合、群体信息的非补偿性融合、评价等级确定方法等构建兼顾重要性和可靠性的科学基金项目绩效评价方法步骤。具体如下:
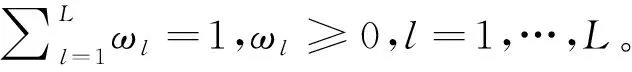
步骤2:设定初始评价项目。令k=1,设定当前评价项目为ak=a1。
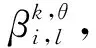

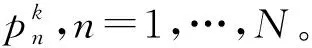
步骤7:判断是否完成评价。令k=k+1。若k≤K,则说明还有项目ak需要进行绩效评价,转到步骤3;若k>K,则说明已完成对所有项目的绩效评价,结束。
四、案例模拟分析——以某国家自然科学基金项目为例
为验证提出方法的科学有效性,本文以某国家自然科学基金项目为例进行案例分析。该科学基金项目于2012年立项,预期目标是通过借鉴吸收知识管理、行为科学、管理决策、信息融合等理论的基本观点和技术方法,针对知识网络中知识数量庞大、知识类型多样、知识主体复杂等特点,对知识网络中决策信息的提取问题开展研究,以期能够明确知识网络中关键知识主体的识别方法、揭示多元决策信息智能提取机理、建立多元决策信息智能提取模型。
参照《国家自然科学基金资助项目研究成果管理办法》和《国家自然科学基金资助项目结题/成果报告》,这里选用项目执行情况(c1)、项目取得成果的总体情况(c2)、成果转化应用(c3)、人才培养情况(c4)、应用前景情况(c5)作为项目的绩效评价指标。设指标权重为(ω1,…,ω5)=(1.00,1.00,0.64,0.92,0.52)。为给专家开展绩效评价提供依据信息,在此给出项目原计划目标以及实际完成情况,具体如表2所示。

表2 项目计划情况以及完成情况信息表

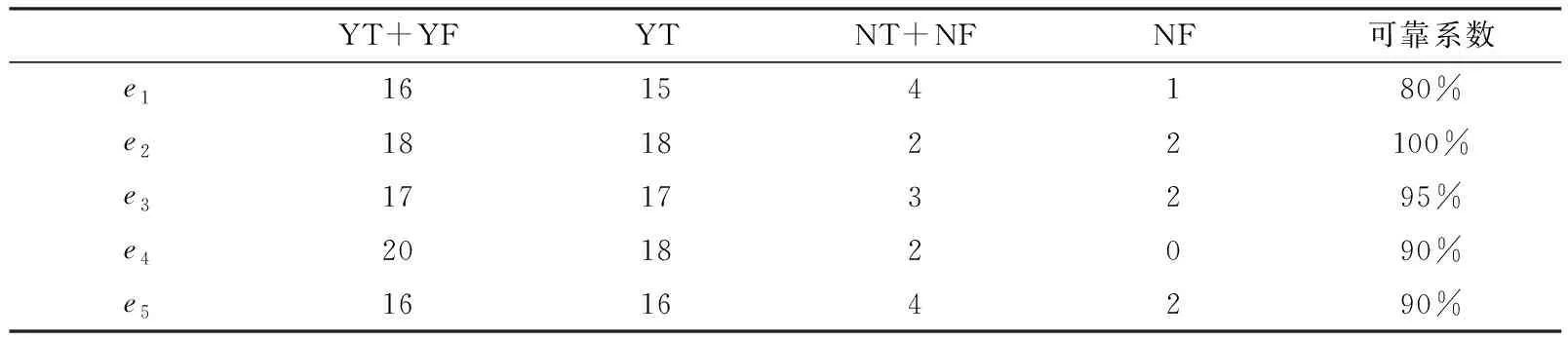
表3 专家历史评价结果

表4 专家评价信息

表5 个体/群体融合结果

表6 评价等级的概率分布
因为本文核心思想是基于指标权重的个体融合采用补偿性融合策略、基于可靠性的群体融合采用非补偿性策略,所以这里分别从个体融合结果和群体融合结果两个方面对上述融合策略进行科学性分析。
从个体融合结果看可以得到以下结论:(1)专家e1认为该项目绩效表现等级有46.49%的可能性为优秀,53.51%可能性为良好,该评价信息是否科学呢?由表5可知,专家e1在c1、c2、c4三项指标上的评价信息与其他专家略有差距,专家e1认为该项目在这些指标上的绩效表现为良好的可能性很大、其次为优秀,而其他专家则认为绩效表现为优秀可能性较大。由表3可知,该项目在上述三项指标上的绩效表现均达到并超额完成了原计划目标,这说明专家e1的评价信息可能是存在偏差的。本文方法通过可靠系数80%对存在偏差的信息进行了折扣处理,并未对项目最终绩效评价结果(优秀)产生不利影响,这体现了本文方法对评价信息进行折扣处理具有科学性。(2)专家e4的个体融合结果是该项目100%属于优秀。由表5可知,虽然专家e4并没有认为该项目在指标c3、c4、c5上100%为优秀,但是由于指标c1、c2的权重都为1(即这两项指标是绝对重要的),而专家e4又认为该项目在这两项指标上绝对优秀,所以其个体融合结果为绝对优秀,符合直觉判断。(3)专家e5对项目在c1、c2的绩效表现均给出完全不知道的评价信息,这并未对其个体评价结果造成影响,体现了本文信息表达机理在允许专家结合自己的知识经验给出评价信息方面具有独特优势。
从群体融合结果看可以得到以下结论:(1)由表6可知,专家e2、e3认为该项目有属于优秀的等级的可能性约为95%,二者可靠系数分别为100%、95%,可靠性强,项目的最终评价结果与二者的个体判断相一致,符合直觉逻辑。(2)专家e4认为该项目100%一定属于优秀,即认为该项目一定不会是其他等级(如良好),而最终评价结果并非100%优秀,在其他等级(良好)上也赋予了信度。由前文可知,当专家绝对可靠且他/她认为该项目一定不会是良好时,则该项目最终评价结果一定不会是良好。但专家e4的可靠系数是90%而非100%,这与非补偿性融合中的“一票否定”规则并不冲突。(3)由表5可知,该项目的每一项指标每位专家都没有给出较差、很差的评价信息,专家个体融合结果、群体融合结果在较差、很差等级上也均未赋予信度,符合直觉逻辑,这体现了本文采用ER规则和Dempster规则进行信息融合具有科学性。
五、结束语
现有科学基金项目绩效评价并未区分指标权重与专家可靠性之间的性质差异,从而容易导致评价结果可能存在科学有效性差的问题。为了解决上述问题,本文首先基于基本信任分配函数给出了能够反映指标权重与专家可靠性两种参数性质特征和专家认知能力的科学基金项目绩效评价机理。然后,基于ER折扣和ER规则构建了能够对专家在不同指标上评价信息进行补偿性融合的个体融合方法,基于Shafer折扣和Dempster规则构建了能够对所有专家个体融合结果进行再融合的群体融合方法。在此基础上,结合Pignistic概率和结果有效性阈值提出了科学基金项目隶属评价等级的确定方法,并基于专家历史评价信息构建了专家可靠系数的计算方法。最后,遵循本文提出的科学基金项目绩效评价机理,结合评价信息提取、个体融合方法、群体融合方法等给出了科学基金项目绩效评价的方法步骤。本文还以某国家自然科学基金项目为案例背景模拟了提出方法的具体操作过程、分析了方法在解决实际问题过程中的科学性。需要说明的是,本文方法侧重于从静态决策视角基于专家给出的评价信息予以综合集成,实现对科学基金项目绩效表现的最终评价,而对于需要专家之间通过彼此交互对科学基金项目绩效进行评价的动态决策问题并未涉及,这也是下一步要研究的重点问题。
