一种基于业务词典的精准主题挖掘解决方案
2018-08-29孟庆强郑浩泉
杨 志 林 峰 胡 牧 孟庆强 郑浩泉
(南京南瑞集团公司/国网电力科学研究院 南京 210003)
1 引言
随着数据应用的广度和深度的快速发展,能带来巨大价值的数据分析挖掘得到了越来越多的企业、政府和科研机构的认可和关注[1]。作为数据知识发现的关键步骤[2],数据挖掘[3~5]成为了当前的研究热点之一。文本挖掘[6~7]是数据挖掘的一个重要分支。如今,许多算法已经被提出来解决文本场景中的数据分析。然而,在电力行业故障日志中,存在相关设备多,词典不统一,主题难以固定等问题。现有的通用的文本挖掘算法切词不准确,很难找故障主题相关因素。因此,如何实现精确的主题挖掘成为研究热点之一。
在文本挖掘中,文本数据以半结构化或非结构化的形式存储在数据库或文件中。由于隐含的语义信息难以挖掘其价值。目前,许多科研机构和团队提出了一些有价值的挖掘算法。主要有两种类型。第一类是文本聚类[8~13]。其中聚类分析[8]是实现文本挖掘的重要方法之一。文献[9~10]提出了两种基于加权特征的模糊聚类方法,利用特征权重向量反映内部结构,在监督或无监督学习过程中使用加权特征的距离函数实现数据挖掘。另一种是自动加权特征技术[11~12]。利用k-均值或FCM,特征权重向量对整个数据集显示各个特征的重要性。此外,文献[13]提出了结合特征加权度量为软子空间学习框架的模糊聚类算法。在这些算法中,在特定的场景中效果较好,但由于不同关键词的主题描述能力差异度较大,很难找到通用的特征向量。
另外一类是主题挖掘[14~21]。利用 PLSA(概率语义分析)模型[16~17]进行日志分析,但容易产生其过拟合。最著名的主题模型LDA(Latent Dirichlet Allocation)[17~19]。在该模型中,通过设置适当的参数,可以得到最终的多个主题和主题相关词分布。同时,在LDA的基础上,提出了扩展LDA模型(Twitter-LDA[20],Labeled-LDA[21],MB-LDA[15]等)。在这些算法中,可以实现主题挖掘和分析出主题相关的词。然而,业务专家需要投入很大精力来分析哪些是主题,这些词是否与主题相关。此外,算法的灵活性低,主题相关的词不能随机设定主题。
上述算法虽然可以解决很多文本挖掘问题,但不能满足电力行业的文本挖掘需求。在电力行业文本挖掘场景中,日志数据存储在结构化数据库中,每条日志记录了电网的运行维护信息(例如设备故障、维护过程、故障分析等)。在故障定位时,需要指定主题词集合,以此分析出语义相关词。数据的潜在价值可用于电网规划、辅助决策等。但是,上述算法无法挖掘出准确的结果。
为了解决上述问题,我们提出了一种基于业务词典的精准主题挖掘解决方案。该方案可准确分析出主题词语义相关的词语集。该算法是在主题挖掘理论的基础上,利用自然语言语义切词技术,计算出词语语义相关影响因子。然后,借助于业务词典,将准确的语义相关词返回给业务专家。
该方案的优点主要有
1)利用语义技术搜索主题相关词。对于给定的主题,使用语义理论,条件概率和业务词典,准确地找出语义相关的词。
2)用业务词典准确地挖掘单词。在这种情况下,避免了大量无关词的干扰,降低了从所有的文档集合中分析语义相关词的时间和精力。
3)减少与主题有关的文档/记录数目。使用主题词集合,排除不相关的文档/记录,减少分析范围,提高效率。
2 主题挖掘理论和评价标准
2.1 主题挖掘理论
在场景中给定的主题,主题挖掘目的是分析挖掘出最佳的语义相关词。由于在实际环境中语义相关词分布在主题词所在的语句中,因此可用相关词和主题的概率进行分析。在文档/记录中,不同的主题有不同的语义相关词。通常,相关词属于一个或多个主题如图1所示。本文将重点讨论相同的词可属于在不同的主题。在一个语句中,词A和词B同时出现,分析其相关度。
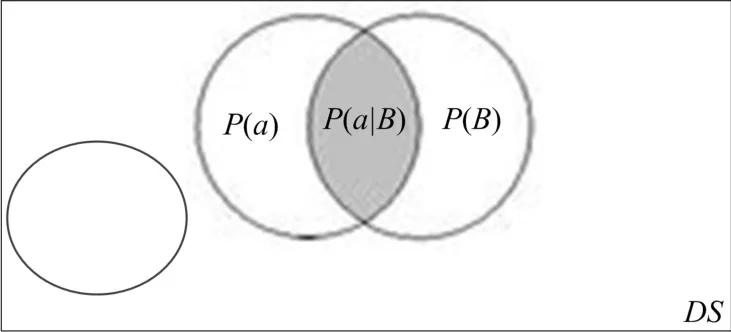
图1 语义相关概率
在文档集合DS中,存在多个语句S,这些语句描述了一个或多个主题。每个语句均包含多个词语W。从上图中可以看出,主题B有多个词语可以描述。P(a)由多个P(ai)构成。对于主题B,可以用公式P(a|B)来表示语义相关词和主题的相关程度。
语义相关度的集合为
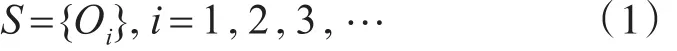
上述公式中,Oi表示每个词语和主题词的相关度,其数据计算公式为
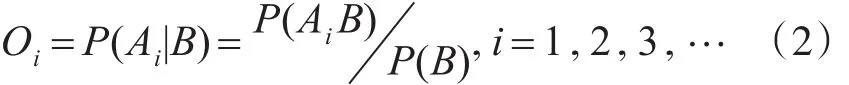
上述公式中,P(AiB)表示B和Ai同时在文档集中出现的概率。P(B)表示主题B出现的概率。P(AiB)表示在主题B出现的前提下,Ai出现的概率。
语义相关度越高,则Oi就越大。如果词语和主题词不相关,则Oi为零。
2.2 评价标准
对于指定的主题词,可以从上面的算法获得许多单词。每个词都有不同的贡献度。所有单词的贡献度之和为100%。并不是所有的词语都对日志分析有价值,因此可以设定一个阈值,这样仅分析较少的相关度高的词语,同时也不会损失数据隐藏的价值。本文中采用比例指数来描述。
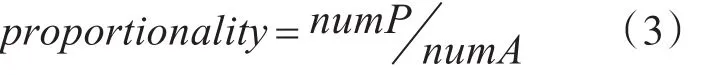
上述公式中,numP表示满足设定阈值的相关度词的数量,numA表示所有相关词的数量。该公式表示从所有相关词中选取词和总数的比例。
比例是定性分析指标。指标不能表明最终结果好坏程度。需要结合实际业务情况,对其进行评估。
3 基于业务词典的精准主题挖掘解决方案
该方案基本原则是不改变原始数据,尽量减少人为因素干扰,最大限度地挖掘数据的潜在价值。按照逐步递进策略,方案共分三步:预处理、热词分析、主题词分析。在预处理环节中一方面对文档/记录集进行异常数据的处理,另外一方面针对业务场景创建业务词典。在热词分析环节中借助于业务词典,利用自然语言切词技术将文本数据拆分成词语,同时对拆分结果进行无效词处理,利用热词分析技术展现词语热度,并选取热度最高的词语作为主题词集。在主题词分析环节,在热词展现中选取关注热词作为主题词集,然后利用语义相关度分析得到每个词的影响因子指标,最后利用网络图显示词和主题词的关联程度。
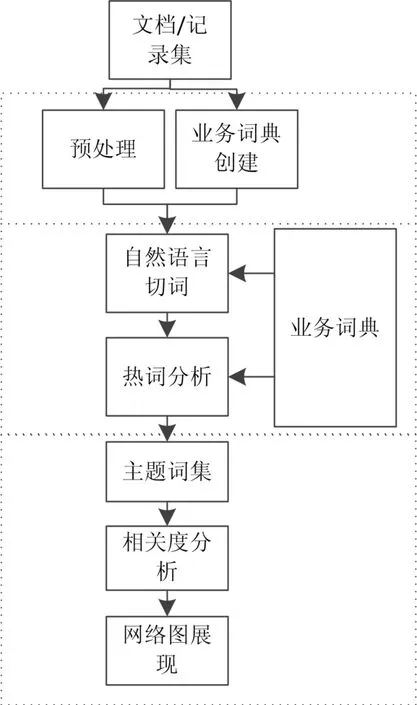
图2 方案过程
方案详细过程如下:
3.1 预处理
预处理环节首先对文档/记录集进行无效词处理,在保证不改变有效数据的前提下,对错、漏、空、重复等异常数据进行处理。在处理的过程中,处理策略要结合业务场景,不能均使用删除方法来处理。如果实际情况就是空值或者重复值,则该值是正常值,不能对其进行异常值处理。
其次,针对业务场景特点创建业务词典。该业务词典主要用于保证专业术语作为完整词语被识别,没有被拆分成多个词语,这样才能分析出数据潜在的最大数据价值。创建过程是由业务专家根据行业、场景,将特殊行业术语、场景术语以及一些约定俗成的术语创建成业务词典。包含关系如图3所示。
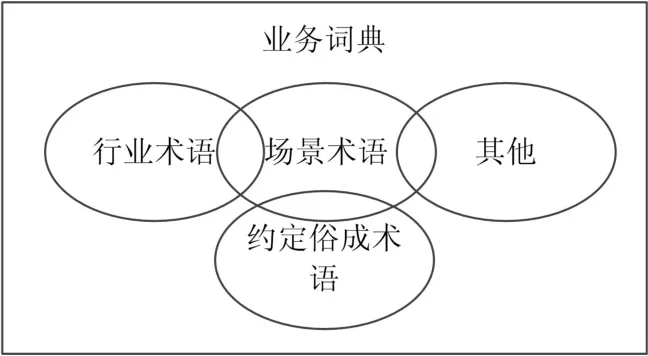
图3 业务词典构成
上图表示业务词典和行业术语、约定俗成术语和其他之间的关系。行业术语指行业内通用的设备、操作、事件等内容的一些名称。场景术语指某类场景专用的一些设备、事件等的一些名词。约定俗成术语指某地区对于某些设备名称、操作过程等内容的简称。其他指行业外与场景相关设备或物体的一些名称。
3.2 热词分析
首先基于业务词典,采用自然语言切词技术对文档/记录集进行切词,然后对切词结果集进行热词分析,分析出热度最高的词语作为主题词。
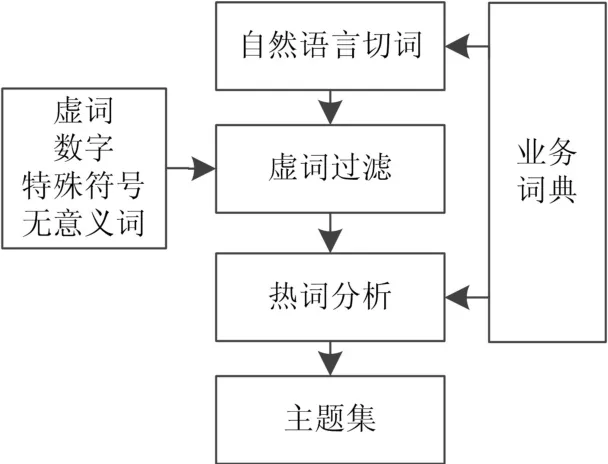
图4 热词分析过程
在利用自然语言切词技术进行切词时,由于不同行业有不同的技术术语。在同一行业中,一些具体的场景在不同的情况下也有不同的术语。这些术语由于不包含在通用字典中,无法识别,隐藏在文档中的有效信息将丢失,无法找到一些数据值。所以,为了避免有用信息的丢失,缺陷可以弥补的阶段。本方案借助于业务词典,在切词过程中尽可能保留业务词语。分词环节是将文档/记录集切分词语集,然后过滤出虚词、无效数字、特殊符号等无意义词语。保留与业务场景有关的词语集。该词语集是精准挖掘数据潜在价值的基础。整体过程如下:
热词分析可分析出文档/记录集中出现频率最高的词语,这些词语表明受关注程度最高,从中选取某些热词作为主题集。
3.3 主题词分析
因为词语和主题词出现在同一文档/记录中,所以词语从不同的方面或角度描述主题词。由于描述的角度和程度有差异,不同词语和主题的关联程度不同。相关性越高,词和主题越紧密。在这种情况下,可以得到准确的关联度。相关词语在一定程度上反映了用户的关注点。在本文中,影响因子是用来描述的关系。用词频和主题频率的比值说明相关指标。
影响因子计算公式如下:
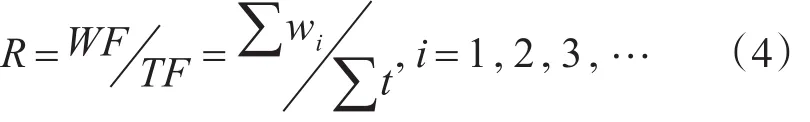
上述公式中,R表示相关度。WF表示词语出现频率。TF表示主题词出现的频率。
所有词语计算影响因子后,形成一个数据矩阵,它描述了每个单词和主题的相关性。
在数据矩阵的基础上,利用网络图等方式显示数据矩阵,将结果直观地呈现给用户。
方案分析:
1)通过对指定词进行主题词分析,用户可以获得与主题相关的词。在这种情况下,主题和相关词语之间的关系被准确地显示出来。由于分析指定主题词集合的相关词,避免了无关主题词相关词的干扰。
2)方案中,通过热词分析指定主题词集。因此,可以避免人为指定一些不具有代表性的主题词,节省工作量,提高效率。
3)利用业务字典,保留了具体业务术语。可准确体现业务场景,分析主题词和相关词。在这种情况下,可重点分析与主题词相关的词语集。
4)利用影响因子公式,分析得到主题词关联度,可定量分析主题词和相关词之间的关联程度,结果能有效支撑辅助决策。
4 验证与分析
上述解决方案已应用到电力生产管理系统(PMS)中。
作为SG186工程的重要应用之一的PMS是一个庞大而复杂的应用程序,是当今最先进的电力生产管理系统。系统数据量大,包括高中低压在内的数据总量超过1500亿条。在这些数据中,日志数据占其中较大比例,日志数据包括如电网操作、故障信息等数据。日志数据潜在的价值有待于进一步发掘。因此,选取PMS系统日志数据来验证上述解决方案。
在PMS系统中选取某个省市的故障日志数据。这些数据描述了主变压器、线路、电压互感器、母线等设备资产的故障和缺陷。同时日志也描述了某一类故障的相关设备、现象、过程、后果和故障分析。从数据中,我们可以分析的主要因素和次要因素或者直接或间接原因。
基于上述数据,在R语言环境中,验证上述解决方案。主要分析过程如下。
4.1 预处理
故障日志存储在结构化数据库中。由于许多字段与本方案无关,因此,选择三个字段来分析算法。这三个字段如下:

表1 分析字段
在选定的日志数据中,异常值数据有空值和重复值两类,处置策略如下:
1)对于空值,因为空值对分析结果没有影响。所以,删除掉所有的空值记录。
2)对于重复值,由于重复值是真实反映现场故障情况的,故不能删除,需要保留。
在故障分析场景中,将电力行业术语、故障场景术语、约定俗称的术语和其他一些术语有业务专家创建成业务词典。部分词典数据如下:
{“接地”,“被淹”,“爆熔”,“跳闸”,“单刀涨碎”,“车辆”,“令克”,“线夹断裂”,“雷击”,“电缆”,“植物”,“风”,“树枝”,“绝缘瓷瓶损坏”,“设备老化”,“松鼠”,“雨水”,…}。
4.2 热词分析
利用自然语言切词技术对记录集进行切词,在分词结果中,存在许多无效词,比如形式词、单个字母和数字等,如下列所示。
{一,从,零,避,国,查,苍,串,A,C,B,Q,30,23,64,5,7,17,…}。
处置策略是删除这些无效词,保留有效词语,这样便于提高分析效率。
如果没有业务词典,业务词语被打散,其隐藏的信息被破坏了,不能发现其潜在价值。但由于分词后有大量的单词,其中大部分词语出现频率较低,对热词分析结果没有影响,且词语数据量过大直接影响热词分析效率。因此,选择一些频率较高的词来表示词频图。在此场景中选取了排名前150的单词(150名之后的词语影响很小)。为了体现业务词典的价值,将在切词阶段是否使用业务的热词分析效果展现出来,对比图如图5所示。
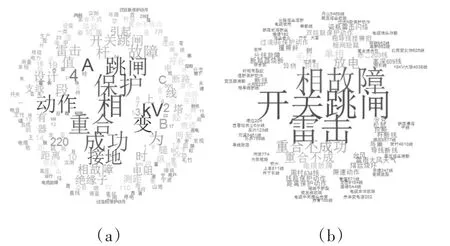
图5 热词对比图
图5 (a)表示没有业务词典的情况的切词结果的热词分析,图5(b)是基于业务词典的切词结果的热词分析。图5(a)无法直观展现故障相关词语,不能判断哪些情况出现的概率高低。从图5(b)中可以直观看出与场景相关的词频率情况。词语显示越大表示该词出现的频率越高,收到的关注度越高,从中可以得出主要因素为{开关跳闸,相故障,雷击}。
4.3 主题词分析
用上述式(4),逐一对所涉及的词进行分析。可以计算出每个词的影响因子。设定的阈值为90%。借助评价准则公式,我们发现前10名的比例大于90%。因此,前10名选择分析。例如,本课题开关跳闸结果如下。
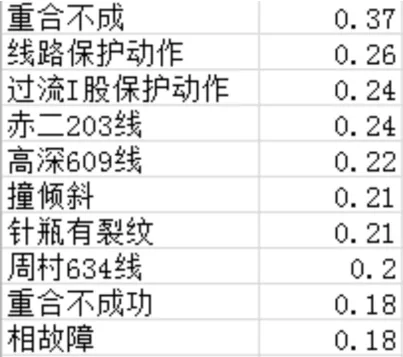
图6 开关跳闸主题相关词关联度
从图中,我们可以看到,“重合不成”词语频率最接近的话题开关跳闸。基于分析结果,用igraph包算法显示结果。其结果如下。
在图中,较大的圆圈是主题,较小的圆圈是相关词。大圈与小圆之间的连接线表示相关词和主题的关系。连线的宽度表示关联程度。
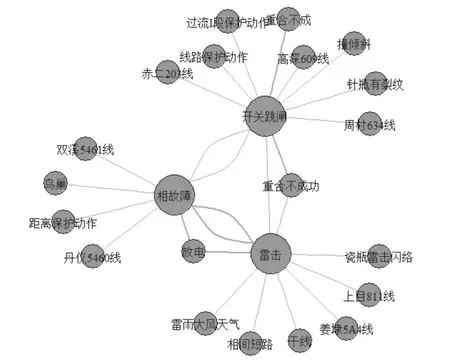
图7 主题词和相关词的网络图
业务专业人员可以从中分析真正的影响因素。例如,通过分析与开关跳闸主题相关的几个词,可以得到几条线路的故障均是由开关跳闸引发的。
验证分析:
1)利用主题词分析可以得到与主题词和相关词之间的关联关系。借助于这种关系,业务人员可以准确分析主要因素和次要因素。
2)热词分析过程中选取出现频率较高的前N项进行分析。可在保证分析结果准确的基础上提高分析效率。
3)基于业务词典的切词。利用业务词典,可以在切词结果中保留更多的业务术语和潜在信息。专业人士可以基于此准确地分析相关词。
4)利用影响因子指标,将定性分析转化为定量分析。借助于这些词语的影响因子,可以准确地描述相关度。
5 结语
由于通用分析算法从日志数据中很难准确地分析出主题相关词,本文提出了基于业务字典的精确主题挖掘解决方案。在该方案中,首先,预处理原始记录集,保留有效的记录集。借助于业务词典,文档被切词成多个词语,然后,删除无效的单词。最后,利用影响因子,可以计算出每个单词的相关性。定性分析转化为定量分析。该方案已应用到PMS。验证结果表明,可以准确地分析主题的主要相关因素。
虽然该算法能够很好地解决日志数据的分析问题,但在创建业务字典时,需要业务专家。业务词典的质量受制于业务专家的能力。此外,如何在分布式环境中提高算法的效率是今后的研究方向之一。
