单极化合成孔径雷达图像颜色特征编码与分类
2018-08-27邓旭,徐新,董浩
邓 旭,徐 新,董 浩
(武汉大学 电子信息学院,武汉 430072)(*通信作者电子邮箱xinxu@whu.edu.cn)
0 引言
随着遥感技术的迅速发展,遥感数据日益增加并广泛应用于环境监测、灾情探测与防治、地物分类等方面[1]。其中合成孔径雷达成像具有全天时、全天候、高分辨率、大幅面的成像特点,被广泛应用于矿场资源探测、灾情探测与防治、土地规划、军事目标识别等[2-3]。传统的单极化合成孔径雷达(Synthetic Aperture Radar, SAR)图像可视化方法直接对强度信息进行压缩,进而形成灰度图像,但是人眼对颜色的分辨能力远远大于灰度,可以分辨多达几千种的颜色色调和亮度,但只能分辨几十种灰度。图像伪彩色增强将灰度图像变换为伪彩色图像,将人眼不能区分的灰度差别显示为颜色差异,从而利于图像的目视解译和信息提取,因此可以通过伪彩色增强实现极化SAR图像的可视化。
国内外学者对此作了很多研究,提出了多种单极化SAR的伪彩图编码方法,将灰度数据转换为颜色信息[4]。伪彩图编码方法大致可以分为以下四种。
第1种直接对单极化SAR进行处理,分为基于空间域和频率两大类[5-13]:基于空间域实现伪彩色编码的包括密度分层法、灰度级彩色变换法、互补色编码法、像素自身变换法和连续颜色编码方法等;基于频率域的方法主要有频率滤波法。如:文献[10]提出了一种基于K均值聚类的红外线算法,该算法通过K均值聚类算法实现灰度图像的聚类,然后根据伪彩色编码的节点对聚类结果进行伪彩色编码;文献[11]提出了基于小波分析和伪彩色的遥感图像增强;文献[12]提出了基于梯度的非线性伪彩色编码方法,计算出图像的梯度场并确定阈值,从而进行编码;文献[13]基于多阈值大津法直方图分割提出了在HIS(Hue,Intensity,Saturation)彩色空间对SAR数据进行空间编码的方法;文献[14]提出了基于Roberts梯度和HIS色彩空间的伪彩色编码算法。
第2种是颜色迁移方法。该方法通过把一幅图像的颜色特征传递给另外一幅图像,使得目标图像具有与参考图像相似的颜色信息。如:文献[15]提出了一种基于直方图映射和分层迁移的灰度图像上色算法,将给定的颜色信息图像和需要迁移的灰度形状图像转换到正交空间,得到两幅图像的灰度直方图;然后利用颜色图像的颜色信息为灰度图像上色得到过渡图像,参照灰度直方图将过渡图像和颜色图像进行分层处理;之后提取出过渡图像的形状信息和颜色图像的颜色信息;最后实现颜色图像到灰度图像的上色过程。文献[16]提出了基于放缩系数和均值的多参数颜色迁移方法。文献[17]提出了一种基于颜色传递和小波降噪、多尺度图像分割的彩色化增强方法。文献[18]提出了一种对单极化SAR图像的彩色增强方法,该方法首先通过伪彩色编码将SAR图像变为过渡图像,然后在颜色迁移过程中运用保持细节的颜色迁移方法保留了SAR图像的细节信息,然后通过改变各通道系数的方式进行色调调整,使得SAR图像与光学图像有着相同的颜色信息。
第3种方法将单极化SAR图像与对应的光学图像融合实现伪彩色编码。如文献[19]提出一种基于单极化SAR图像纹理特征的Contourlet变换融合方法,对SAR图像提取灰度共生矩阵纹理特征,然后通过相关性得到重要特征图,接着通过HSV(Hue, Saturation, Value)变换提取光学图像的强度分量,然后将其与强度分量进行Contourlet变换融合,得到伪彩色图像。文献[20]提出了一种基于Shearlet变换的多源遥感影像融合方法,利用变换,设计了基于改进型的脉冲耦合神经网络的高频系数融合和基于区域能量的低频系数融合规则。
第4种方法将深度神经网络用于伪彩色编码,将单极化SAR图像利用神经网络进而实现颜色编码[21-22]。如文献[22]利用深度神经网络将单极化SAR图像转换为全极化SAR图像,实现伪彩色编码。这些方法各有优缺点,如彩色空间编码方法,会随着研究区域的不同得到差异较大的结果;密度分层方法保持图像原始信息较好且简单,但是由于彩色数目有限,生成的伪彩图对地物区分性不好,即灰度相近的地物类别颜色差异不大;颜色迁移方法需要有一幅参考图像;与光学图像融合的方法需要相关的光学图像;而神经网络的方法比较复杂。
通过分析上述已有的单极化SAR图像编码方法,可以发现存在的主要问题有:1)大部分方法是利用单极化SAR图像的灰度信息,进行直接或者间接转换得到伪彩图,目视效果有所改善,但是丢失了很多细节信息,灰度相似的地物差异不大;2)由于单极化SAR图像目标地物的物理散射特性和噪声问题,所以生成的伪彩图地物区分性不强;3)有的方法实现过程复杂或需要一定的条件。
针对以上问题,提出了单极化SAR图像的颜色特征编码方法。该方法综合考虑了单极化SAR图像噪声问题和物理散射特性,对单极化SAR图像的特征进行编码,将特征转换在RGB(Red,Green,Blue)颜色空间,保留了更多的细节信息,获取更多的颜色信息,更利于目视和解译,并将其用来实现单极化SAR图像的分类。用两组TerraSAR-X单极化SAR数据进行了方法验证。
1 实验数据
实验数据1 佛山地区TerraSAR-X单极化SAR数据,获取时间2008年5月,距离向和方位向为1.25 m,图像大小为2 000×2 000,包括3类地物,分别是水域、耕地、建筑,其中标记为黑色的为不参与精度评价的区域。

图1 佛山实验数据
实验数据2 武汉地区TerraSAR-X单极化SAR数据,获取时间2008年9月,距离向和方位向的分辨率均为3.0 m,图像大小为2 000×1 800,包括4类地物,分别为建筑、水田、河流、耕地,其中标记为黑色的为不参与精度评价的区域。

图2 武汉实验数据
2 颜色特征编码算法
本文提出的颜色特征编码方法对单极化SAR图像的特征进行颜色编码。该颜色特征编码方法首先对单极化SAR图像提取纹理特征,包括灰度共生矩阵和直方图统计特征;然后用随机森林对特征进行重要性排序并将特征颜色编码成颜色特征图;最后按重要性排序从高到低,每3组颜色特征图组合成伪彩图。
2.1 特征提取
纹理特征是单极化SAR图像分类的重要特征,实验算法所用到的纹理特征包括灰度共生矩阵和直方图统计特征。
灰度共生矩阵是一种常用的纹理提取方法[23]。灰度共生矩阵通过计算图像邻近像元灰度级之间的二阶联合条件概率密度P(i,j,d,q)来表示纹理,该概率密度函数表示在给定的空间距离和方向上,以灰度级i为起点出现灰度级j的概率。
用数学公式表示则为:
P(i,j)={[(x,y),(x+Dx,y+Dy)];
f(x,y)=i;
f(x+Dx,y+Dy)=j;
x=0,1,2,…,Nx-1;
y=0,1,2,…,Ny-1}
(1)
其中:i,j=0,1,2,…,L-1;x,y是影像中的像素坐标;L为影像的灰度级数;Nx,Ny分别为影像的行列数。
算法用到了灰度共生矩阵中的6个特征,包括均值、均一性、对比度、熵、不相似度和同质性[24]。
灰度直方图反映的是图像灰度的统计特性,表达了图像中取不同灰度值的像素点个数在图像中所占的比例,是图像中最基本的信息[25]。图像直方图的定义可以用式(2)来表示:
H(i)=ni/N;i=0,1,…,L-1
(2)
其中:i表示灰度级,L表示灰度级的级数,ni表示灰度级为i的像素的个数,N表示的是图像的总像素点。直方图的横坐标是灰度级,纵坐标表示区域内出现该灰度级所占的概率。
一般不直接将直方图作为特征,而是对直方图进行统计得到统计特征。算法所用到的直方图特征有均值、均方差、标准差系数、中值、中方差、斜度、能量、熵、峰度、欧氏距离均值10个。
2.2 特征优选
实验采用的特征是灰度纹理特征和直方图特征,用滑动窗口提取,该窗口以每个像素点为中心,其中计算灰度共生矩阵时采用的参数如下:0°、45°、90°和135°四个方向,灰度级为8级,所以特征为4个方向的灰度共生矩阵特征共24维,直方图统计特征10维,原始幅度图像特征1维,总35维,其中灰度共生矩阵8个特征是常用的几个特征,10个直方图特征也是常用的。
在佛山地区数据和武汉地区数据中对每一类地物随机采样14 000个样本点,利用随机森林进行训练,得到特征重要性,对35维特征进行特征重要性排序。图3(a)和3(b)分别表示的是佛山地区数据和武汉地区数据的特征重要性,横坐标是35维特征对应的标号,纵坐标是特征的重要性。

图3 特征重要性
从图3(a)中可以看出佛山地区数据的35维特征重要性差别较小,没有特别突出的特征,因此生成的伪彩图区分性差别较弱;从图3(b)可以看出武汉地区数据的35维特征重要性差异较大,因此生成的伪彩图的区分性较强。
2.3 颜色特征
将上述35维特征每一维量化到0到255,然后对每一个灰度级赋予一个RGB颜色,形成RGB颜色特征图,对该颜色特征图通过目视判断对地物的区分性。
图4和图5分别是佛山地区数据、武汉地区数据中方向为0的灰度共生矩阵的4个特征的颜色特征图:图4(a)和图5(a)是方向为0的不相似性特征对应的颜色特征图;图4(b)和图5(b)是方向为0的对比度特征对应的颜色特征图;图4(c)和图5(c)是方向为0的熵对应的颜色特征;图4(d)和图5(d)是方向为0的同质性对应的颜色特征图。
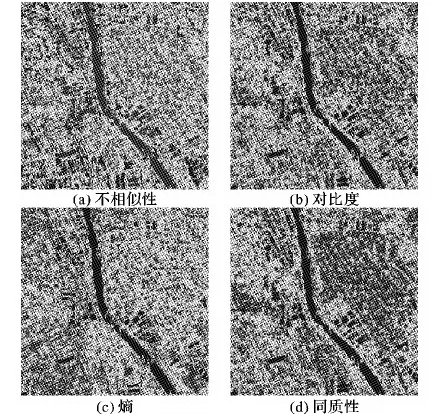
图4 佛山数据的颜色特征图
从图4中可以看出佛山地区数据的4个纹理特征的颜色特征图目视效果非常好,可以区分对应的3类地物。
从图5中可以看出武汉地区数据4个纹理特征的颜色特征图不能区分出建筑,其他3类地物可以区分出来,因此用这些特征单独进行分类是不能区分出全部地物的。
总的来说,从图4和图5中可以看出特征变成颜色特征图后地物之间差异明显,颜色信息丰富,目视效果很好,有助于判断该特征是否可以区分相关的地物。
2.4 伪彩图的生成
对特征的重要性进行排序,然后按重要性排序先后每3维特征分别为R、G、B通道生成伪彩图,第34维和第35维只有2张所以不能生成伪彩图并且特征重要性太低,将其舍弃,所以用前33维特征生成11张伪彩图。
图6和图7分别是佛山地区数据、武汉地区数据生成的伪彩图。

图6 佛山数据生成的伪彩图
图6(a)到图6(k)表示的是佛山数据对应生成的11张伪彩图,其中图6(a)的图片名称1-3表示的是排序前三的特征组合而成的第一张伪彩图,图6(b)到图6(k)的图片名称都是类似的含义。图7(a)到图7(k)表示的是武汉地区数据对应生成的11张伪彩图,其中图7(a)的图片名称1-3表示的是排序前三的特征组合而成的第一张伪彩图,图7(b)到图7(k)的图片名称都是类似的含义。附上原始幅度图作为对比。
首先对佛山地区数据生成的伪彩图进行分析。通过与原始幅度图的对比,人工判读所有伪彩图均能解译出三类地物。特征的重要性基本一样,生成的伪彩图对地物的区分能力差别不大。对于武汉地区的数据,通过与原始幅度图的对比发现:第1张伪彩图7(a)可以区分4类地物来,即河流、水田、耕地、建筑;第2张伪彩图不能区分建筑和耕地;第3张伪彩图只能区分2类地物,不能区分水田和河流,也不能区分建筑和耕地;从第4张到最后第11张伪彩图都不能区分河流和水田。
从两组数据的伪彩图对地物的区分性来说,特征重要性前3的颜色特征图组合成的伪彩图明显区分开了所有的地物,而且是所有伪彩图中地物区分性最好的,因此两组数据均采用第一张伪彩图进行分割,颜色特征编码方法对单极化SAR地物分类是有明显的效果的。
2.5 伪彩图实验结果与分析
2.5.1 伪彩图质量评价标准
接下来从图像的统计特性、清晰度、信息量三个方面对图像质量进行客观评价[26]。
1)图像统计特性的评价指标。
均值和标准差是图像的两个最基本的统计特性。均值是图像像素值的灰度平均,反映的是图像的平均亮度。公式如下:
(3)
标准差反映了灰度的离散程度。公式如下:
(4)
其中:M、N是图像的行数和列数,F(x,y)是点(x,y)处的灰度值。
2)基于彩色空间的平均梯度是图像纹理变化的特征,具有对微小细节的反应能力,用来评价图像的清晰程度。伪彩色图像的平均梯度值越大,表达能力就越强,如式(5)所示:
(5)
3)信息熵是度量图像信息量的一个重要指标,公式如下:
(6)

图7 武汉数据生成的伪彩图
2.5.2 伪彩图结果分析
表1和图8是佛山地区的伪彩图的质量评价指标和图像结果。表2和图9是武汉地区的伪彩图的质量评价各项指标和图像结果。其中基于HIS的伪彩色编码[5]是提出算法的对比算法。将各项指标和原图的对比,对结果进行评价。

表1 佛山的伪彩色编码方法评价
从表1和图8中可以看出基于HIS的编码生成的伪彩图与原灰度图的均值很接近,而提出的颜色特征编码生成的伪彩图均值低很多,亮度适中,在细节保持度即梯度上不如对比的方法,信息熵比原图和对比方法都好,且不同的地物之间颜色差别明显,每类地物可分性更好。

图8 两种算法的佛山数据伪彩色图
结合表2和图9,可以看出基于HIS的编码生成的伪彩图与原灰度图的均值接近,而提出的颜色特征编码生成的伪彩图均值低很多,亮度适中,在细节保持度上不如对比的方法,但提出的信息熵比原图和对比方法都好,提出方法的目视效果优于对比方法,表现在:1)将水田和河流完全区分开;2)不同地物间颜色差别明显,有助于各类地物。

图9 两种算法的武汉数据伪彩色图

Tab. 2 Evaluation of Wuhan pseudo-color encoding method
结合2组数据的结果,可以说明提出的颜色特征编码算法是有效的,有助于提高单极化SAR图像的可视化效果。
3 基于颜色特征编码方法的分类算法
基于颜色特征编码方法的分类算法流程如图10所示,在提取特征后,对颜色特征编码方法产生的伪彩图进行目视判断,选出地物区分性最好的进行统计区域合并(Statistical Region Merging, SRM)分割,另一方面对所有的伪彩图用随机森林进行分类,最后在SRM分割得到的超像素区域内,对随机森林得到的结果进行相对多数投票,得到最后的分类结果。SRM算法是一种图像统计模型,主要用在RGB彩色图像上[27],分类器是随机森林[28]。
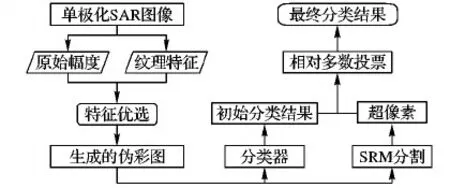
图10 本文算法流程
4 实验结果与分析
表3和图11是佛山地区数据的分类精度评价和分类结果图,表4和图12是武汉地区数据的分类精度评价和分类结果图。其中:对比方法1的特征为纹理特征,分类器为随机森林;对比方法2是基于HIS的伪彩色编码方法生成的伪彩图提出的分类流程。所用的评价方法中每一类地物的分类精度是生产精度,即对生产者分类精度的一个度量,平均精度表示的是总体精度,表示所有涉及到的所有像元分类的正确性。

表3 佛山数据的分类精度对比 %

图11 佛山数据的分类结果对比
在表3中对比方法2在SRM分割Q值为64时分类精度最高,所以只列出了该分类精度。结合表3和图11可以看出当SRM的Q值从1到256变化时,提出的算法整体分类精度变化不大,在89.0%左右波动,综合考虑Q取64时提出的分类算法分类结果最好。与对比方法1的结果相比,提出的算法整体提高了10个百分点,河流的分类精度提高了5个百分点,建筑提高了12个百分点,耕地提高了10个百分点。其中建筑物分类效果非常好,只有小部分被错分为耕地;耕地分类精度也不错,有小部分被错分为建筑物;河流有很小一部分被分为建筑。建筑物与耕地互相错分的原因可能是建筑物区域也是有绿地的,不全是建筑。河流被错分为建筑的原因应该是河流内有轮船等在单极化SAR成像上与建筑物同样呈现高亮的物理特性。与对比方法2结果对比,对比方法1在武汉地区的分类精度低一些,但提出的算法整体分类精度高了8.2个百分点,在每个类别的分类精度上除了耕地之外其他两类精度明显较高,效果更佳。

图12 武汉数据的分类结果对比

%
在表4中对比方法2在SRM分割Q值为256时分类精度最高,所以只列出了该分类精度。结合表4和图12,可以看出当SRM的Q值从1到256变化时,提出的分类算法整体分类精度直线上升,从81%增加到88.8%,在Q=256的时候整体分类效果和各个类别分类效果最好。与对比方法1的结果相比,提出的分类算法整体提高了6个百分点,河流的分类精度提高了3.7个百分点,建筑提高了2.8个百分点,耕地提高了8.7个百分点,水田提高了10.8个百分点。其中:将一部分建筑错分为耕地,导致建筑的分类精度不高;水田有一部分被分为耕地,有一部分被分为河流,原因是水田构成复杂,有水也有地,在单极化SAR成像上会呈现复杂的特性,一部分与耕地的纹理特性相似,一部分与河流的物理特性相似,导致区分水田困难,因此分类精度不高;河流也有一部分被错分为水田,原因相同。与对比方法2的结果相比,对比方法1在佛山地区的分类精度低一些,但提出的算法整体分类精度高了1个百分点,在每个类别的分类精度上除了建筑之外其他3类精度基本一致,但是在建筑上提出的算法效果明显优于对比方法2,因此两组数据的结果说明了提出的颜色特征编码方法比基于HIS的颜色编码对分类更有效,更有益于单极化SAR的目视和解译。
5 结语
本文对单极化SAR图像提出了一种颜色特征编码方法,并对生成的伪彩图进行分类实验,结果表明了可以增加颜色细节信息,更有利于目视解译和分类。不足之处如下:采用的特征不够广泛,只采用了纹理特征和幅度特征,不确定其他类型特征是否适合该编码方法;SRM分割参数的选择是由分类实验结果实现的,没有具体的优选方法,在数据非常大的情况下实现难度大;特征优化选择采用的是随机森林方法,可以采用特征选择方法。
针对提出的算法存在的问题,下一步可以:扩大特征的类别范围,进行大量实验,验证提出的编码方法的可扩展性;采用具体的分割指标进行分割尺度优选;尝试其他方法进行特征优化;改进产生颜色特征图的方法。
