基于LDA模型的图书馆文献分类系统设计与开发
2018-08-25刘芳
刘芳
(陕西学前师范学院陕西西安710100)
人类在获得知识过程中的方式主要包括两种,第一种为实践,第二种为阅读。虽然实践非常重要,但是能够通过阅读有效掌握先辈们的实践成果及经验,图书馆属于学校及整个社会尤为重要的部分,其使我们站在巨人肩膀中学习[1]。在现代信息大爆炸时代不断来临及专业分类不断细化的过程中,对于图书文献分类具有大量的要求。为了能够有效满足现代图书馆设备管理需求,避免因为人为管理出现的错误,就要实现图书馆文献分类系统的设计和开发[2]。目前,国内外图书馆文献分类系统的主要趋势为网络化、资源化、个性化及小型化,其不仅能够实现分布式资源相互操作的特点,还能够实现并行处理高速查询。大部分的图书馆已经实现编目、采访、阅览、流通及信息咨询等工作自动化统计及管理,提高了图书馆服务质量及工作效率。但是部分图书馆并没有得到完善,其分类系统更新比较缓慢,学科分类比较单一,无法满足现代全新文献分类需求[3]。基于此,文中实现了基于LDA模型的图书馆文献分类系统的设计。
1 系统需求分析
因为传统图书馆文献在手工操作模式中,图书编目及借阅的工作量比较大,并且精准性较低,所以就要创建图书馆多种功能,详见图1,根据需求对主要功能需求进行归纳[4]。

图1 图书馆文献分类系统的功能模块
通过图1可以看出来,用户不需要登录就能够对图书馆图书信息及文献信息进行检索及浏览,如果用户使用借书证号及密码实现系统的登录,可以使用读者论坛、图书馆及资源共享等模块功能[5]。图2为管理员的需求功能结构。

图2 系统管理员的需求功能结构
图书管理人员主要是图书馆文献分类系统的使用人员,参与到图书馆中的所有业务,其比普通用户具有更多的需求。其能够实现图书信息、借阅人员信息、总体借阅情况信息管理及统计,并且还能够对图书基本信息进行浏览、添加及查询等操作[6]。
2 图书馆文献分类系统总体设计
目前,学科分类越来越细化,单一学科逐渐朝着跨学科及学科交叉方向发展,同一个文献能够同时属于多个学科及多个主题。传统图书馆分类系统是利用词和词之间对比对文献相似性进行判断。但是,基于现实语言环境,两个共同语句较少文献有可能表达相同主题,只是使用不同阐述方式。所以,在对比文献的时候,可以通过其对相同主题的描述对其相似度进行描述。本文所研究的基于LDA模型的图书馆文献分类系统全面考虑了标签及频率相关性,提高了系统的性能[7]。图3为基于LDA模型的图书馆文献分类系统的用例图。

图3 基于LDA模型的图书馆文献分类系统的用例图
文中设计的系统主要包括特征抽取、预处理、文献分类及分类训练器模块。其中预处理模块的功能就是实现图书馆现有格式文献资源的格式转换,统一使其转换成为文本文档格式,并且实现格式文档分词处理等;其中分类器训练模块的主要目的为将包括语义信息特征到判别式分类模型中放入实现分类器参数训练,使用训练参数实现分类器的定义;特征抽取模块使用LDA模型实现文本特征的表示,并且实现特征提取,对其进行权值赋予;文献分类模型的功能为用户通过对需要分类的文档进行有效的选择,实现分类结果目录的指定,实现所有文档分类,之后到结果文件中输入[8]。图4为图书馆文献分类系统的主要结构。
3 基于LDA模型的图书馆文献分类系统的设计
3.1 系统硬件设计
文中所设计的基于LDA模型的文献分类系统主要目的为实现移动数字图书馆内容的数字化,也就是实现相关文献资料的数字化。其能够以图书分类系统为基础,根据读者需求实现不同形式的制作,所以制作之后的形式并不同[9]。图5为图书馆文献分类系统的硬件结构。

图4 图书馆文献分类系统的主要结构

图5 图书馆文献分类系统的硬件结构
3.2 系统的详细设计
文中研究系统的开发使用的软件及硬件环境主要为:应用层使用功能VStuido集成化开发环境,在实现文本规范化处理的过程中,主要包括去停用词及中文分词等,利用分词实现文本的为基本词集合。其中特征抽取模块指的是从文本中选择能够有效将文本类别反应出来的词作为特征,之后实现特征提取;文献分类模块使用户利用需要分类的文档选择实现分类结果目录的制定,之后实现所有文档分类;分类器训练模块将包括语义信息特征到分类模型中存放,之后实现分类器参数的训练,使用训练之后的参数进行分类器的定义[10]。图6为图书馆文献分类系统的详细设计结构。

图6 图书馆文献分类系统的详细设计结构
3.2.1 预处理模块
图书馆文献资源格式各不相同,首先要实现多种格式数据的转化,使其能够成为计算机便于处理的格式,在此过程中要删除文本标点符号及空格。出国文档处理之后,要使用正向最大匹配及CRF方法相互结合实现分词处理,之后对文本中的词进行逐一的扫描,将词实现相互匹配,实现停用词的过滤处理,最后得出文档分解的词列表,在本次磁盘中存储[11]。图7为图书馆文献资源转换格式的流程。

图7 图书馆文献资源转换格式的流程
3.2.2 特征抽取模块
在文本分类中,要想能够提高计算机对真实文本的处理效果,就要寻找理想形式化表示方法,此种表示方法要能够将文档内容充分的反映出来。传统图书馆文献分类系统是利用词之前对比实现文献相似性判断,但是现实语境中的共同词语较少文献在表达相同主题的时候使用参数方式不同,所以还要全面了解其对主题的判断。LDA属于实现文本数据主题信息建模的方式,其能够简单描述文档,保存本质统计信息,从而有效提高文档集大规模处理的高效性。所以本系统使用LDA主题模型表示文本特征,从而实现文本特征抽取模块的创建[12-13]。图8为特征抽取模块处理的过程。
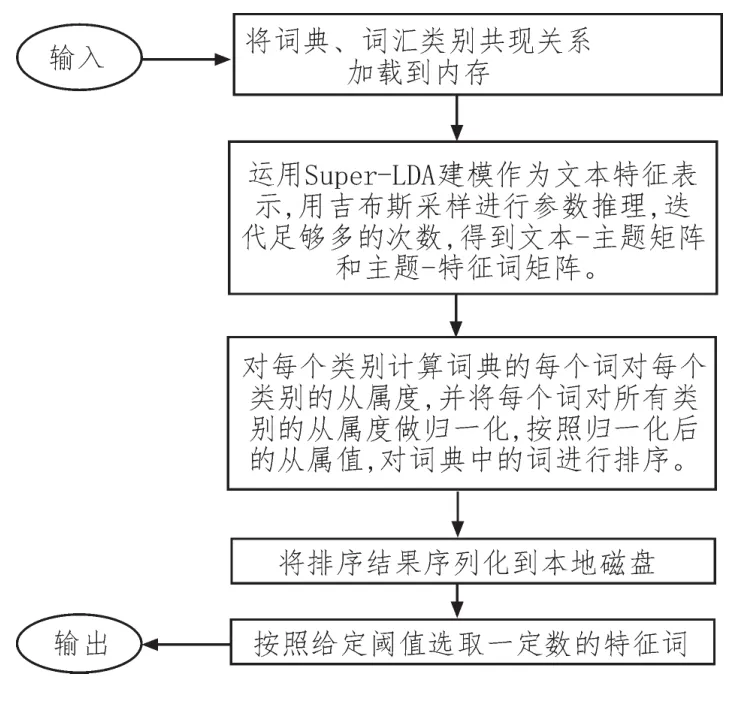
图8 特征抽取模块处理的过程
3.2.3 分类器训练模块
图9为分类器训练模块的算法流程,首先实现模型的加载,之后得到加载的类别,最后将模型进行销毁。

图9 分类器训练模块的算法流程
3.2.4 文献分类模块
以文本主题条件为基础,使系统对此矩阵矩阵模块进行读取,对于需要分类的文本使用此矩阵实现文本分类,将分类的结果到本地硬盘中实现序列化[14-16]。图10为文献分类模块的流程。

图10 文献分类模块的流程
3.3 数据库的设计
表1为图书馆文献分类系统中相应的信息表。

表1 用户基本信息表

表2 图书文献信息表
4 结束语
现在多标签的文本分类还并没有满足理想分类性能需求,并且也无法满足图书馆学术文献分类实际使用需求,其具有一定的提高空间。对本文所研究系统进行全面的分析,表示其能够有效满足用户需求,确定主题模型的数量,实现大规模主体模型的训练,实现大量数据的处理。
