基于门控循环单元神经网络的广告点击率预估
2018-08-24,,,
, , ,
(浙江理工大学信息学院,杭州 310018)
0 引 言
计算广告学是一门新兴的综合性学科,涉及统计学、信息科学、计算机科学和微观经济等相关领域。点击率(Click through rate, CTR)预估是计算广告技术的核心之一[1]。广告点击率预估通常根据历史广告点击数据,通过机器学习模型,预测特定用户在特定广告位对特定广告的点击概率。常见的互联网广告商业计费模式[2]有四种:按展现付费 (Cost per mille, CPM)、按点击付费 (Cost per click, CPC)、按转化付费 (Cost per action, CPA)和按投资收益率付费(Return on investment, ROI)。市场上的付费模式大多采用CPC,即广告被用户每点击一次,广告主应给媒体付的价格,媒体网站的收入是点击价格和点击总数的乘积。在点击价格不变的情况下,提高点击次数,即提高点击广告的概率是提高广告收益的关键因素。
广告点击率预估主要分为四个步骤:数据清洗、特征工程、模型选择和训练、模型评估。Dave等[3]提出了基于梯度提升决策树(Gradient boosting decision tree, GBDT)的预估方法,主要思想是通过弱决策器迭代生成强决策器,并自动选择和生成特征。但是该方法在大规模稀疏的数据集情况下,准确率难以得到保证且训练时间成本过高。Oentaryo等[4]提出了利用因式分解机(Factorization machine, FM)模型挖掘非线性特征的方法。该方法通过对二项式矩阵做矩阵分解,将高维稀疏的特征向量映射到低维连续向量空间,能够有效地解决大规模数据稀疏型的问题,然而该方法由于需要特征矩阵作分解和特征高低维映射的原因,导致处理特征的工作量巨大。Zhu等[5]提出了一种基于模型融合最大化的方法,该方法只考虑对点击率有关键作用的特征进行哈希变换,一定程度上忽视了特征的整体性和多样性。Chapelle等[6]提出一种基于贝叶斯网络(Naive bayes networks,NB)模型的方法,通过模拟登陆页面的相关性以及搜索结果页面可感知的相关性进行广告点击率预估,但是贝叶斯网络模型必须先验概率且属性之间必须是相互独立的。Zhang等[7]提出了利用循环神经网络(Recurrent neural networks, RNN)模型进行点击率预估的方法,利用按时间反向传播(Back propagation through time, BPTT)算法来训练RNN,其实验结果表明,相比于GBDT、FM以及传统的神经网络模型,RNN在准确率上有一定的提升。然而RNN在使用梯度下降优化算法时,造成梯度爆炸问题[8],影响模型的准确度。
为了解决循环神经网络梯度爆炸的问题,本文采用基于门控单元(Gated recurrent unit, GRU)改进的循环神经网络,即门控循环单元神经网络(Gated recurrent unit neural networks, GRUs)。该方法利用GRUs特殊的门控单元结构,通过对当前隐藏层状态的影响因子不同作加权处理,同时对模型训练产生的误差进行更新,避免在学习轮数增加的情况下发生梯度爆炸的问题,进而提高模型的准确性。本文进一步对该模型的训练算法进行改进,提出一种步长改进算法,通过步长改进算法可使得训练迭代次数更少,预估结果更加精确,以提高广告点击率的预估能力。
1 门控循环单元神经网络模型和算法改进
1.1 门控循环单元神经网络模型


图1 GRUs原理
1.2 模型训练和算法改进
基于GRUs模型预估广告点击率,目的是准确地对广告特征输入序列进行分类,依靠误差反向传播和梯度下降来实现[12]。GRUs训练比较困难,主要是因为隐藏层参数W,无论在前向传播过程还是在反向传播过程中都会乘上多次,这样就会导致前向传播某个小于1的值乘上多次,对输出影响变小,使得反向传播时出现梯度爆炸的问题。在传统的神经网络中,大都采用反向传播 (Back propagation, BP) 算法来训练,RNN以及改进网络中使用按时间反向传播BPTT算法[13]。按时间传播表示一系列完全定义的有序计算,根据时间依次连接,其参数在所有的层之间共享,因此当前层的梯度值除了要基于当前的这一步计算,还有依赖于之前的时间步。BPTT采用链式法则求解参数梯度。
图2描述了BPTT算法在一个t时间的存储和处理操作。历史缓存每经过一个t时间,就会增加一层的数据(包括该t时间所有的输入和输出值)。

图2 按时间反向传播操作
图2中x表示当前时间的特征输入,O表示当前时间的特征输出,S表示激活函数。图2中的实线箭头表示当前隐藏层节点的输出值是由上一刻的输入输出值确定,虚线表示反向传播,计算t+1到t-1时间的误差。每一个时间都产生一个输出,节点输出每经过一个时间t,就会增加之前所有时间的信息状态值。GRUs的结构在时间t的隐藏层输入可以用公式表示为:


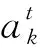
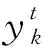
其中:whk为隐藏层与输出层之间的权重,gk为输出层的激励函数。


t时间的隐藏状态的梯度函数用公式表示为:

至此,由梯度下降法求出权重的更新函数用公式表示为:
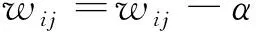
对GRUs采用梯度下降法来训练时,需要提前设置步长和迭代轮次。本文提出一种改进步长的梯度下降方法来训练GRUs,改进步长算法的流程为:先设置一个大的步长快速寻找全局近似最优点,再利用较小的步长通过指数迭代衰减,进而找到局部最优。
本文模型算法改进具体计算用公式表示为:
其中:l表示每一轮优化时使用的步长,m表示最小步长,n表示最大步长,p表示迭代轮次,q表示在给定的步数下达到n。步长参数设置过大,会导致参数在极优值点的两侧来回移动,很难收敛到一个极值点;相反,如果步长参数过小,虽然可以保证收敛到一个近似极值点,但会大大降低优化速度,需要更多的迭代次数才能达到一个理想的优化效果。具体参数设置见表1。

表1 模型算法改进前后参数
1.3 评价函数
由于本文的广告点击率预估问题是一个典型的二分类问题,所以采用ROC(Receiver operating characteristic)曲线和AUC值来评价模型的标准以及预测的准确率[14]。ROC和AUC常被用来评价一个二值分类器(binary classifier)的优劣,在广告投放中,被点击的候选广告根据广告点击率值的大小,按概率由高到低排序,生成ROC曲线,AUC代表ROC曲线下的面积,值越大,表示被点击的广告排序越靠前,即广告投放的效果越好,也就是广告点击率预测越准确。ROC曲线横轴为假正率(False positive rate,FPR),表示划分实例中所有负例占所有负例的比例;纵轴为真正率(True positive rate,TPR),表示正类覆盖率。AUC的值vAUC用公式表示为:

其中:M表示正类样本的数目,即点击广告数据的数目;N表示负类样本的数目,即广告数据未点击的数目。AUC计算思想是统计总的正负样本对中,正样本的score大于负样本的score。在广告点击率预估场景下,通常属于不平衡问题,AUC对样本的数据比例有着良好的容忍性,在测试集的正负样本分布变化时,ROC曲线能够保持不变,所以实验采用AUC值评价模型指标。
2 实验过程和结果分析
2.1 数据准备
本文实验中使用的数据集是Kaggle平台上的10天日志,该日志由移动广告dsp公司Avazu提供。由于涉及到用户隐私等问题,数据字段全部采用加密的形式给出。训练数据共四千多万条,24个字段特征,其中14个为分类特征,10个为数量特征。实验数据字段见表2。
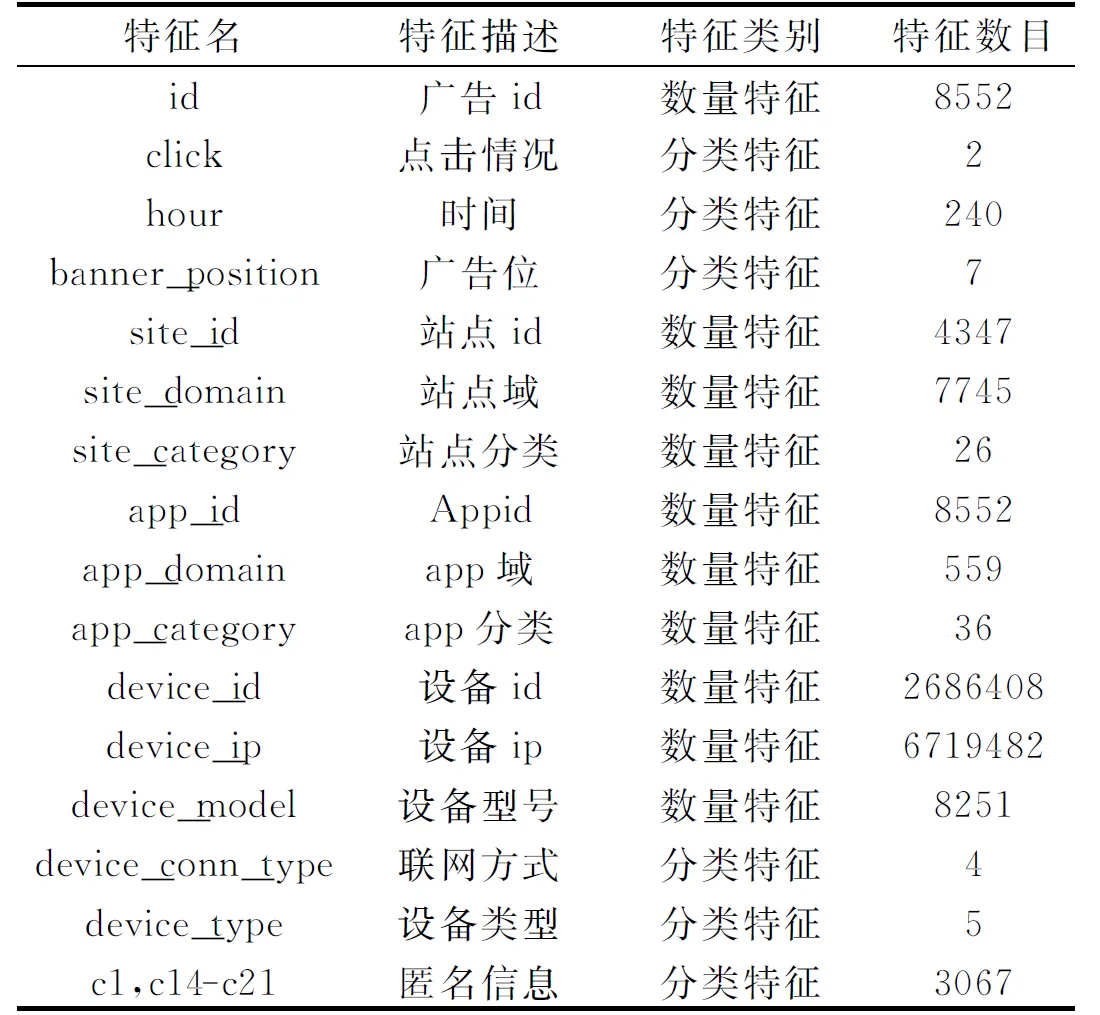
表2 实验数据字段介绍
2.2 特征工程
首先划分训练集和测试集。由于作为原始数据中测试集的后两天数据没有类别标签,所以本实验只采用8天的训练集作为实验数据。把前7天的数据作为训练集,第8天的数据作为测试集。数据的日点击率情况见表3。

表3 数据的日点击率情况
从表3可以看出,各天的点击率基本维持在0.17上下,正负样本均衡,不需要进行采样处理。
针对时间“hour”特征,抽取增加出“day”和“hour”两个新特征。对特征缺失值进行处理。对不同类型特征的缺失值进行补全处理,其中缺失值为连续型的特征用该类别特征的均值代替,缺失值为离散型的特征用该类别特征的众数代替。进行频次转化,去除“id”、“day”和“hour”,其余特征强制转成“int”型整数格式作频次转化。进行频次转化的原因在于一条广告展示的次数过多会降低相同广告出现的概率,其次则为了数据类型的统一性。几个重要特征的转化情况见表4。

表4 几个重要特征的转化情况
分类处理某一个或某几个特征如“banner_position”特征,此特征共有7个特征类别值,分别为0、1、2、3、4、5、7,在广告点击率预估中代表一条广告所处不同广告banner位置。此特征单个类别值的广告点击率大小如图 3所示。

图3 单特征类别点击率
对特征进行One-Hot Encoding编码。虽然基于决策树的随机森林不需要进行One-Hot Encoding,但是本文实验中采用相同的特征,以此保证对比实验的客观性。One-Hot Encoding编码方式调用sklearn里面的接口One-Hot Encoder。对于取值数目较多的分类特征如“device_ip”和“device_id”等进行特征降维,之后作One-Hot Encoding编码。对出现频率很少的特征值都归为同一类特征,避免产生巨大的矩阵向量维度,降低计算复杂度,提高资源利用率。
特征工程的工作均是通过以上步骤完成。本文对比实验中所用到的数据完全一致,只有特征工程相同,才能更好地比较模型自身的优势。
2.3 实验结果及分析
本文实验中分别使用逻辑回归 (Logistic regression,LR) 模型、NB模型、随机森林 (Random forest ,RF) 模型等浅层模型以及 RNN作为GRUs及其本文算法改进模型对比实验。以上所有模型均采用相同输入特征,其中3种神经网络模型在层数以及每层的节点数保持一致,优化算法全都采用梯度下降算法,激励函数为tanh。
在广告点击率预估实验中,不同模型有着不同的预估效果,取所有模型各自最好的AUC值作为实验对比,AUC值大小如图4所示。

图4 不同模型下的最高AUC值
从图4可以看出,在3种使用浅层模型预估广告点击率实验中,基于RF的广告点击率预估效果最好,AUC值为0.696,主要在于RF采用bootstrap方法有放回地随机抽取新的广告样本集作为训练样本,通过构建多棵分类回归树,达到较好的预估效果。同时,基于RF模型的AUC值明显要低于基于RNN模型的实验结果。这是因为浅层模型中没有充分挖掘广告特征间的非线性关系,随着样本量的增加,模型的泛化能力也相对减弱。而在基于循环神经模型的点击率预估实验中,基于门控循环单元的神经网络模型以及步长改进的模型效果最好,AUC值分别为0.785和0.789。
3种基于循环神经网络模型在不同迭代次数下的AUC变化如图5所示。
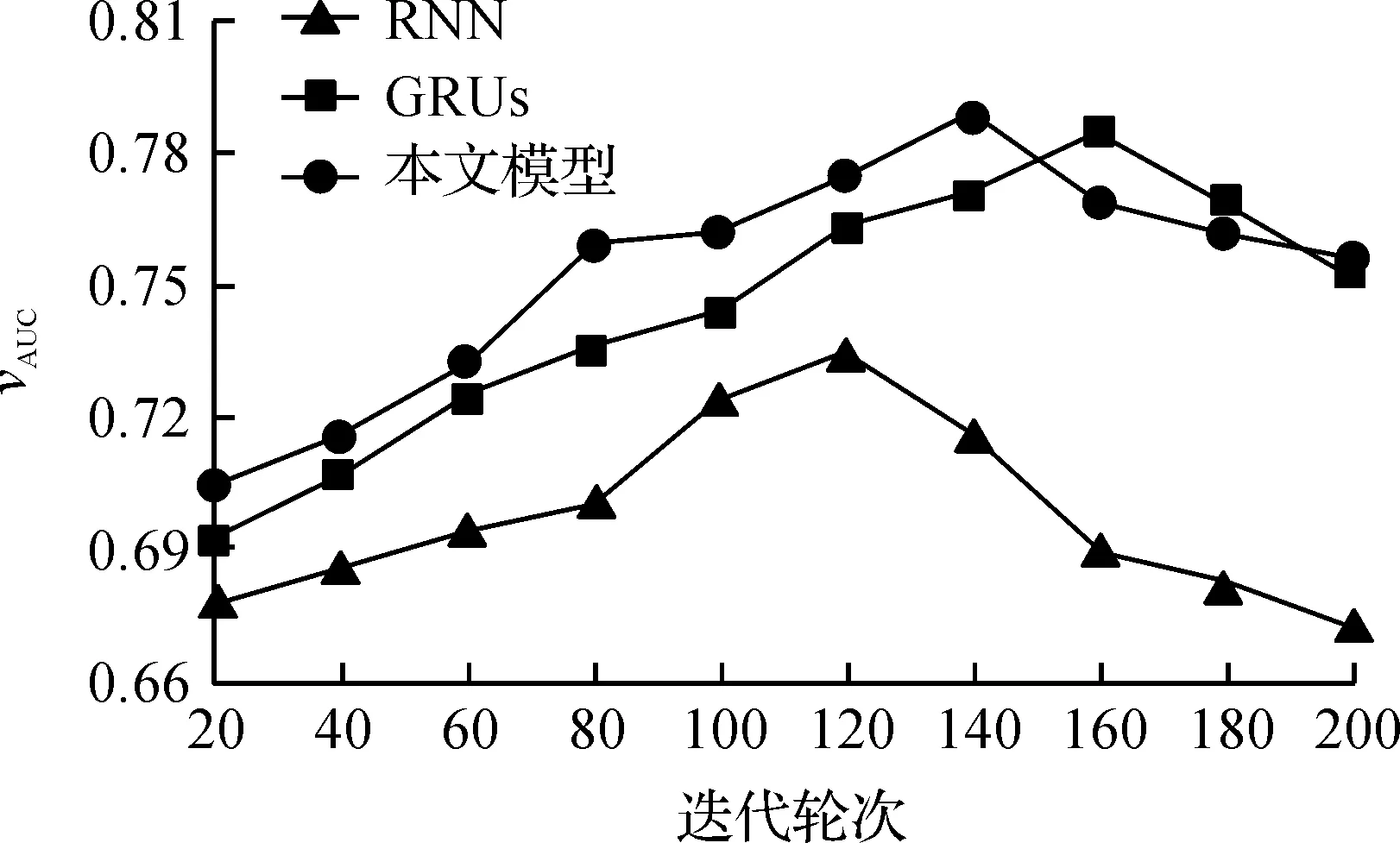
图5 不同神经网络模型在迭代次数下的AUC变化
RNN和GRUs用相同固定的步长0.001,隐藏层为3层,节点个数为256。从图5中可以看出,在相同的激励函数tanh下,随着迭代轮次的增加,RNN的AUC值提升相比GRUs和本文模型都更加缓慢,而且最佳的AUC值比本文模型降低了将近0.05。这是因为RNN在随着样本量和迭代轮次增加,使得当前的模型输出与前面很长的一段广告序列信息产生遗漏,造成梯度消失或爆炸的原因。而GRUs和本文模型在迭代轮次的增加下,AUC值上升趋势快,这是因为相对于RNN,GRUs在隐藏层的计算方法上引入了门单元结构,利用门单元特殊的门控机制来控制梯度传播,在广告特征计算的历史信息中将重要特征保留,从而避免了梯度消失或爆炸,提高了模型预估效果。但是本文模型在迭代140次左右的时候达到了最大AUC值,而GRUs要在160次左右到达最大的AUC值。本文模型要比GRUs在更少的迭代次数下达到最优点,最佳AUC值比GRUs下大0.005左右。这是因为本文模型在GRUs的基础之上改变了步长优化算法,使得步长在每次迭代都更新幅度大小,使得训练时间更少,模型更加精确。本实验说明,基于步长改进算法的本文模型在广告点击率预估中效果要更好,证明了步长改进算法的可行性和有效性。
3 结 论
本文采用基于GRUs模型的方法预估广告点击率问题,利用GRUs中特有的门控机制来加强广告特征在时间上的联系,进而增强广告特征之间的非线性关系。基于GRUs模型,在优化方法上提出一种步长改进算法,使得梯度下降在训练优化模型时,每轮迭代的步长发生更新。实验结果表明,利用步长改进算法后的梯度下降法优化的模型对比其他模型,在广告点击率预估上使用的训练时间更短,预估效果更好,为媒体网站和广告主在投放广告的类别筛选、位置排版等提供参考价值,提高广告收益。
本文实验只选取了梯度下降这一种优化算法,在后续工作中,可以在步长控制算法的基础之上寻找更有效的优化算法,尝试对GRUs的隐藏层节点进行改变。
