基于Markov模型及A*算法的平台航路规划*
2018-08-22张富才周新志
张富才 ,宁 芊 *,周新志
(1.四川大学电子信息学院,成都 610065;2.中国电子科技集团公司第二十九研究所电子信息控制重点实验室,成都 610036)
0 引言
航路规划目的在于根据地形与威胁信息,并考虑到平台性能的情况下,为完成飞行任务到达目标点规划出最优飞行路径。一般平台在出发前按照已知航路上的地形及威胁进行到达目的地的航路规划,在途中若有突发事件则根据当前状况进行重新规划航路。
目前,搜索最优路径的算法很多,其中A*作为启发式算法的代表,对其本身的优化及改进的方法也很多。然而很多改进都只是针对点搜索空间、航迹平滑、搜索速度等方面进行优化[1-2,11-14]。例如,通过剪裁搜索区域,设计新的搜索策略以及优化算法计算速度进行改进[1];通过优化节点扩展方式以及路径的平滑进行改进[2]等。然而实际中由于突发事件,可能存在地图信息不明确以及多种威胁条件,从而无法及时查询平台状态,导致无法完成任务并到达目标点。因此,针对以上问题,采用生存代价优化适应度函数,可在当前突发事件情况下由于地图信息不明确、或者存在威胁情况下搜索路径,并通过过程中每个状态的转移概率获取在威胁区域中平台实时状态。
1 基本A*算法
A*算法作为启发式搜索算法,通过对状态空间中每个搜索点的位置进行评估,选取最优点,然后再以当前位置进行搜索,最终到达目标点。代价函数如下:
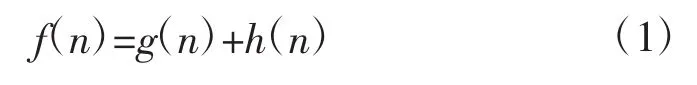
式中:f(n)为当前节点的代价值;g(n)为从起点到节点n的实际代价;h(n)为启发函数,表示从节点n到目标点的估计代价值,算法步骤如下:
1)将起点放入Open表并估计从出发点到目标点的代价;
2)判断Open表是否为空,是则结束循环,否则继续;
3)从Open表中取出f(n)值最小的节点作为当前节点,将其添加进Close表并从Open表中删除;
4)判断当前节点是否为目标节点,是则规划成功,否则继续;
5)对当前节点的相邻节点进行扩展,判断相邻节点是否在Close中,若是则放弃该节点,否则作为当前节点的扩展子节点;
6)对每一个扩展子节点,判断其是否在Open表中,如果不在,计算该节点 g(n)和 h(n),并添加进Open表,并把当前节点作为该节点的父节点,跳转到第2)步;若在Open表中,检查新路径的g(n)是否更小,是则将该节点的父节点改为当前节点,并重新计算 g(n)和 h(n),跳转到第 2)步,否则直接跳转到第2)步。
2 Markov模型
当执行的任务区位于敌方武器攻击范围外,此时平台生存状态最好;而当平台执行位于敌方武器攻击范围内的任务时,将会暴露在敌方防空系统中。一般后者情况居多,并且在执行任务时也会存在以下因素:1)敌方保护贵重物资,会有敌机阻止平台到达目标,此时为了保证平台安全,需要平衡完成任务、与敌机对战等方面的状态;2)敌人的伪装,定位的敌方雷达、武器等信息存在不准确的情况,即使根据最佳情报信息已经规划出路径,当平台实际执行任务时情况可能会再次变化。因此,在执行任务过程中出现新的情报时,平台需要根据当前信息采用生存代价对任务路径进行新的评价,重新选取威胁最小的路径。
由上可知平台的威胁主要来自敌方雷达与武器,并且敌方发现与击落的几率主要取决于平台的位置。
2.1 生存模型
生存模型是描述平台与敌方之间状态的连续时间马尔科夫模型,主要用来描述随机的多领域过程[3-4]。
2.1.1 马尔科夫过程
连续时间 Markov过程{X(t)|t≥0}是一个连续、离散值的随机过程,如式(2):
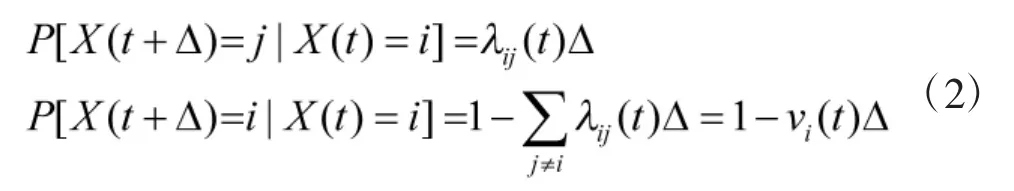
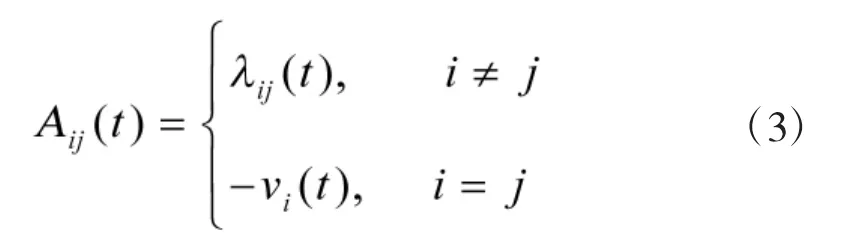
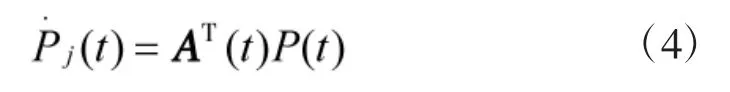
其中,AT为矩阵A的转置。
2.1.2 状态与状态概率
生存模型设置为5个状态:未发现(Undetected)、发现(Detected)、跟踪(Tracked)、对战(Engaged)与击中(Hit)。由式(4),设置向量为路径中某时间点状态概率,该模型转移强度矩阵A(t)与平台经过的雷达武器区域及经过的时间点相关。在时间点tn:
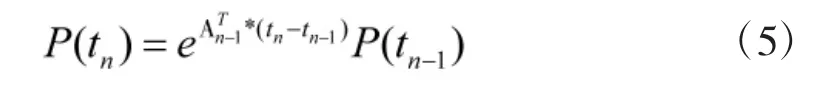
其中,eA定义为:。
2.1.3 区域与转移强度关系
2.1.3.1 单个雷达、武器区域
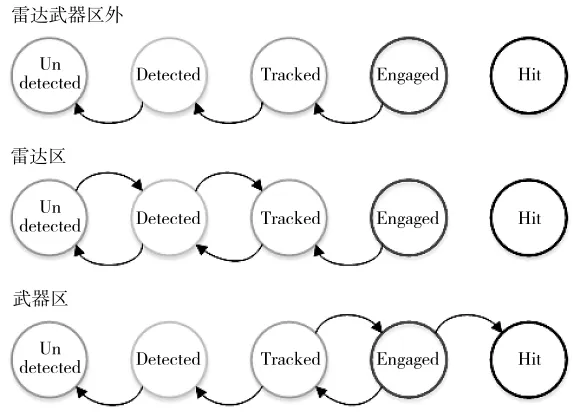
图1 状态转移方向
1)雷达、武器区域外。在该区域,飞行过程在Undetected状态结束,可通过DU>0,TD>0 及ET>0对模型进行描述。然而考虑到敌方对平台运动轨迹的预测,因此,并不会立刻从较高状态转移,此时可以设置ET为最大。该过程转移强度见表1。
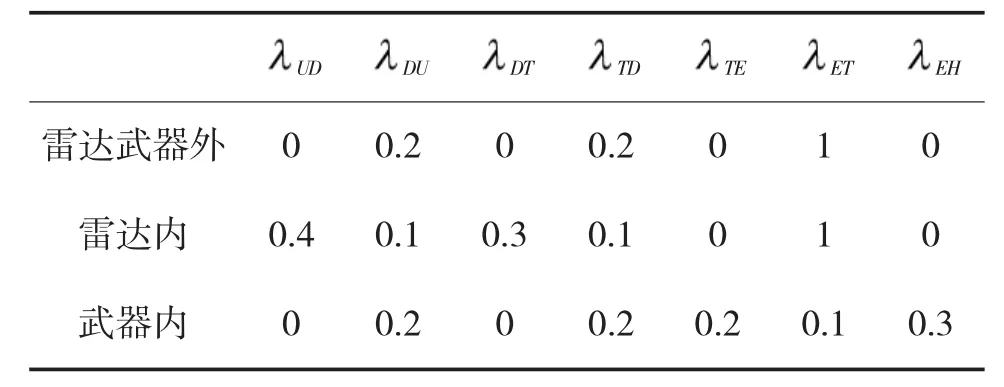
表1 不同区域初始化转移强度值
2)雷达区域内。雷达内,平台可能会处于Undetected、Detected与 Tracked状态,在 Detected与Tracked状态,可用DU>0,TD>0 描述;由于在Undetected状态的几率较小,因此,可设置DU、TD为平台在雷达范围外时该值的最小值,如果敌方雷达侦查精度极高,则TD=DU=0。
3)武器区域内。该区域不存在Detected与Tracked状态,可设置DU=TD=0。在确定平台位置的情况下攻击有效,因此,武器一般位于雷达区域内,此时为重叠区域,分别用TE、EH描述对战与击中两种状态,具体分析见下文。
2.1.3.2 雷达、武器重叠区域
假设路径上要经过的某区域是由K个雷达与武器组成的重叠区域,并且每个独立的区域可用转移强度矩阵Ak进行描述,则最终重叠区的转移强度矩阵AComb可通过计算该区域中每个独立区域的转移强度矩阵得到。
1)Undetected→Detected→Tracked
相对于单个雷达,平台在多雷达系统中更易处于Detected与Tracked状态。假设每个雷达之间的探测是相互独立的,则平台在重叠区从Undetected状态到Detected状态的转移强度为K个转移强度之和。
2)Tracked→Detected→Undetected
多雷达系统中平台更易被追踪。由于系统中每个雷达的寿命为指数分布形式。则该系统的转移强度Comb为系统寿命 的倒数。
3)Tracked↔Engaged→Hit
判断平台是否进入对战状态取决于敌方,并且与位于重叠区的路径长度有关。实验中假设敌人采用一台高精度武器攻击,其转移强度为:
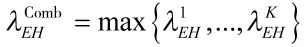
2.1.4 生存代价
生存代价用来描述模型中每个状态信息,主要分为以下两个方面。
1)状态内代价。假设单位时间为bi,则在状态i内,代价为所有单位时间代价和;
2)状态转移代价cij。当状态i与状态j发生转换时,计算 cij。
设置u(t)为飞行过程中t时刻的代价,即在区间[0,t]内的代价。u(t)取决于过程最终输出,是一个随机变量,因此,选择期望值v(t)进行计算。假设模型在微小时间间隔Δ内只有一次转换,过程中t时刻处于状态i的概率为p(it),则在Δ内保持在状态i的概率为1-v(it)Δ,此时代价为biΔ;在该过程中从状态i转移到状态j的概率为ijΔ,此时代价为:,其中相当于,则:
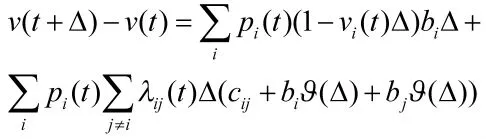
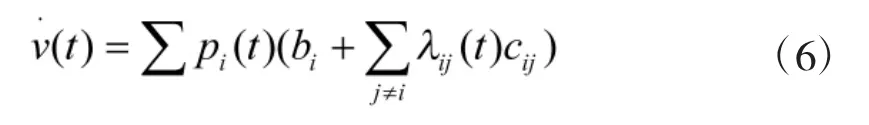
由式(4)与式(6),定义
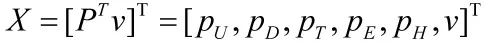
则:
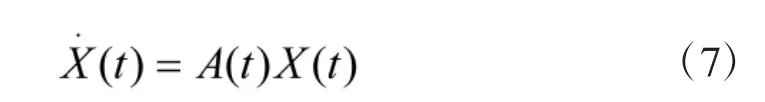
由式(5):
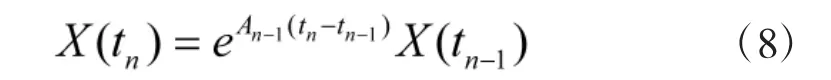
X(tn)为tn时刻当前生存状态概率分布。
3 改进算法
3.1 约束限制及搜索空间
平台由于自身条件限制,为了避免在航路规划后可能无法实际执行。实验中为了防止该问题,约束条件[5]主要考虑如下。
1)角度限制。分为偏转角与俯仰角。偏转角表示在平台当前飞行方向上,限定平台左、右转弯最大角度,俯仰角表示在当前飞行方向上平台上升、下降的最大角度;
2)最短飞行距离。当平台以一定飞行速度飞行时,两次调整飞行状态期间平台所需飞行的最短直线距离。它由不同的飞行速度以及平台的自身性能决定,无论对于飞行速度的控制还是对航迹的评估,都希望尽可能地直飞以使航迹平滑;
3)最低、高飞行高度。保证平台安全飞行的高度限制,当平台在最低飞行高度下飞行时会由于威胁源过近而被击落,同时,过低飞行时对规划空间的划分更加精确,当航迹间节点距离较远时,平台与地面撞击的概率大大增加,当平台在最高飞行高度上飞行时易被雷达探测到,不能有效地利用地面遮挡进行隐蔽,所以在此高度范围内飞行安全系数较高;
4)速度、油耗。平台飞行时,限定最大速度Vmax,最小飞行速度Vmin,并且在飞行时,考虑到雷达与武器区域,为了提高平台生存率,在该区域内的速度要大于在该区域外的速度,因此,在雷达区域速度设置为Vrd=1.5,武器区域为Vwp=2,雷达武器区域外为Vout=1;平台油耗通过求和不同速度在单位时间内的耗油量获得,在一定情况下,油耗低则较优;
5)任务约束。平台在保持生存条件的前提下务必执行。
搜索空间[7]设计如图2所示,其中R1为路径上当前点,R0为上一个点,点O为R0R1直线上距离R1为R1O的点,R1O为搜索步长,α为最大偏转角,β为最大俯仰角。搜索点时,首先在圆O边上以夹角θ选择固定数量点,设置为点集A,然后以同样方法,在图中虚线圆边上选取固定数量点,设置为点集B,该圆半径为1/2圆O半径,最终搜索点集为A、B及点 O 的并集[14-15]。
3.2 适应度函数
由式(1),修改A*算法的适应度函数[6]为:
f(n)为当前节点代价,v(tn)为生存代价,g(n)表示从起点到节点n的实际代价,h(n)为启发函数,表示从节点n到目标点的估计代价值,其中wt为生存代价权值,wl为实际航程代价权值,wh为距离目标点代价权值,相当于任务权值。
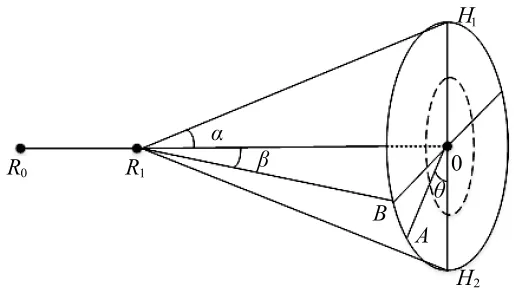
图2 搜索空间
4 实验结果
实验场景通过Matlab2014a采用差值法生成,结果如图3,图4所示。
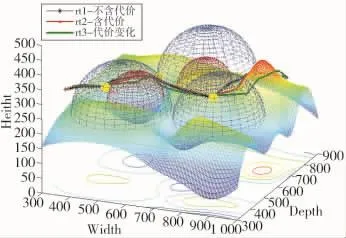
图3 结果侧视图
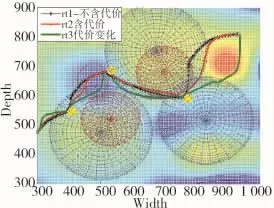
图4 结果俯视图
实验中把雷达与武器区域视为空间球体,图中半径较大的蓝色区域表示雷达范围,较小的红色区域表示武器范围,黄色区域为实验所设置的任务点,表2为不同路径结果数据。
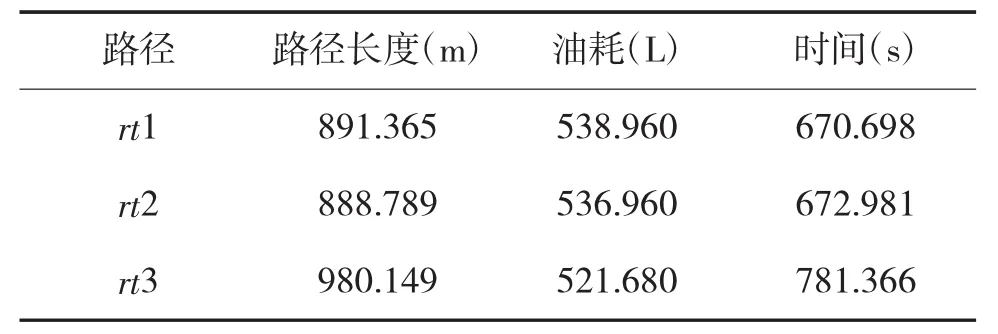
表2 不同路径油耗、时间、距离结果
图3中路径满足高度约束,且图中路径rt1为标准算法结果,权值为:wt=0,wl=0.6,wh=1,rt1 只设置了地形与雷达武器的距离约束;路径rt2与rt3为加入生存代价后结果,rt2权值为:wt=0.15,wl=0.5,wh=1,路径中添加了生存代价;rt3在rt2的基础上增大了生存代价wt,降低了任务代价wh,权值为:wt=0.28,wl=0.22,wh=0.75。从图4与表2可知,rt1相对于rt2路径长,油耗高,且处于雷达武器范围内的路径较长,因此,加入Markov模型后更优;rt3增加生存权值,减小任务权值,因此,相对于rt2路径及时间较长,然而由于处于雷达武器范围内的路径点较少,油耗相对较低。
图5为rt2与rt3路径状态曲线,由于rt3生存代价权值较高,在Undetected状态rt3比rt2概率更大,而在Detected与Tracking状态,比rt2概率更小,并且不在武器区域,因此,Engaged与Hit状态概率为0。
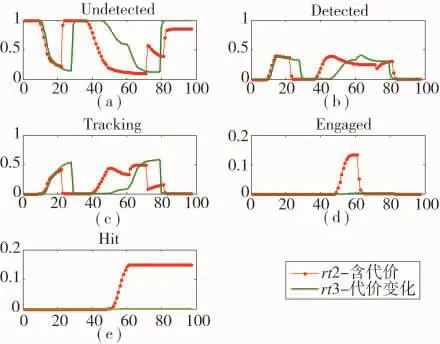
图5 rt2、rt3状态概率
因此,通过设置不同权值可以获得不同路径,并且加入生存代价改进后的搜索算法更优。
5 结论
本文采用实验地形进行测试,根据当前约束情况,添加生存代价后,可以获取平台在路径中每个时刻的状态变化,从而及时判断平台状态进行分析,结果较好,然而考虑到实际情况的复杂,本文存在其他一些不足,例如:
1)平台飞行过程中比较重要的速度及油耗等问题建模较为简单;
2)实际中任务点分布情况较多,本实验只采用当前一种任务布置方式;
3)实际地理环境中的地形因素;
4)任务执行状况。
因此,期望在后续实验中可以加入更多的复杂情况进一步实验研究,使之可以最大化地靠近真实环境,得到更加准确、有效的结果。
