图像集闭包建模的协同表示人脸识别算法
2018-08-20胡正平刘立真
胡正平 刘立真
(燕山大学信息科学与工程学院,河北秦皇岛 066004)
1 引言
图像多重描述能够提高分类精度[1],图像集分类识别已经越来越多应用于人脸识别[2-3]和目标分类[4]领域。因图像集能更好传达类内相关信息,图像集人脸识别比图像的人脸识别有更大优越性。
人脸识别技术中如何获得图像充分且互补的多重描述是一个重要问题[5]。文献[6-7]提出由原始人脸图像产生对称人脸的应用,有效地克服人脸图像多重变化的问题。文献[8]提出原始图像和其镜像图像联合实现人脸识别,镜像图像可展现异于原始图像的可应用细节[9],增添扩展信息,故二者联合应用可提高人脸识别精度。
图像集分类识别存在两个关键问题:首先如何实现图像集建模,其次是如何计算测试集和训练集的距离从而分类判别。针对此问题,研究者提出有参方法和无参方法两种模式。有参方法是将每个图像集建模成带有参数的分布,然后利用交叉熵计算分布距离[10]。但参数估计较难且参数不适用实际情况,从而无参建模方法更具优势。文献[11]提出混合欧氏距离和黎曼几何度量学习图像集分类算法,利用混合度量学习算法合并多异构数据实现鲁棒图像集分类判别,采用协方差矩阵和高斯分布等形成多元数据表示每个集合实现互补集建模。该利用欧氏距离和黎曼几何度量将原始空间嵌入高维的希尔伯特空间进而在满足判别约束条件下联合学习混合度量,从而实现融合来自异构空间的数据达到图像集分类判别效果。文献[12]提出格拉斯曼流形最近点图像集识别算法,利用能够将子空间从格拉斯曼流型空间投影到适用欧氏距离的再生核希尔伯特空间的投影核完成图像集表示,将再生核希尔伯特空间中由扩展的k-means子空间构造的点建模为放射核,最后利用相异放射核间的欧氏距离实现分类判别。文献[13]中提出成对线性回归图像集分类算法,定义不相关子空间且提出两种构建不相关子空间的方法,利用两种基于不相关子空间构造方法的分类器的联合度量,增加测试集和训练集的最大化不同信息从而实现分类判别。文献[14]提出感知流形学习图像集分类算法,该算法基于格拉斯曼流形独立成分分析。格拉斯曼流形是线性子空间的集合,它使每个子空间被映射到流形空间的一个点,利用可获得空间局部信息的独立成分分析构建格拉斯曼子空间,在该空间利用线性判别分析或者稀疏表示分类获得鲁棒性分类性能。文献[15]提出迭代深度学习图像集人脸识别算法,它可以自动分层从原始图像中学习有鉴别力的表示特征。首先由池化卷积层学习得到低层不变特征,然后利用以分层次方式迭代的人工神经网络学习输入图像集的有鉴别力非线性特征表示。该方法减轻将图像集表示为线性子空间或者黎曼几何流形等因预先假设所属类别所带来的对分类鉴别信息丢失的限制。文献[16]提出联合原型和度量学习算法,利用可数样本表示每个训练样本集从而学习到原型度量进而张成正则化仿射闭包表示样本集,测量样本集间的距离学习到马氏距离度量,通过交替更新原型度量和马氏距离度量获得集到集的距离完成分类判别。
无论是有参建模还是无参建模,分类判别都利用测试集与每个训练集分别比较距离。类似于最近邻分类器和最近子空间分类器,这种分类方法并没有考虑训练集间的相关性。基于分类的稀疏表示算法(SRC)[17]和基于分类的协同表示算法(CRC)[18]强调利用所有类的训练样本线性表示测试样本。研究者将SRC和CRC运用到图像集识别,利用所有训练集表示测试集中的每一个样本图像,但是此做法并未利用测试集样本间的相关性和区别性。
考虑到充分利用样本集内部相关性和差异性,本文提出图像集闭包建模的协同表示人脸识别算法。首先,扩展字典,中等强度像素带有鉴别信息;镜像图像可描述异于原始图像的细节且增添视觉分辨效果;将原始图像,镜像图像,中等像素图像联合构成扩展的图像集字典。然后,利用无参模型建模训练集字典闭包;同类异源域的测试图像构成图像集(Image set)且构建这些图像集为测试闭包,扩展字典协同表示测试闭包进而利用字典更新求解闭包系数。最后,采用残差判别函数进行模式分类。
2 图像集闭包建模的协同表示人脸识别算法系统框图
图1是本文算法的整体框图。首先,构建扩展字典,将原始图像和由其产生的镜像图像与中等像素图像,三种源域图像联合构成扩展的图像集字典。然后,建模图像集闭包,以无参模型建模构建训练集闭包,同类异源域的测试图像建模构建测试集闭包。最后,训练集闭包协同表示测试集闭包利用字典更新求解闭包系数,进而采用残差判别函数进行判别分类。
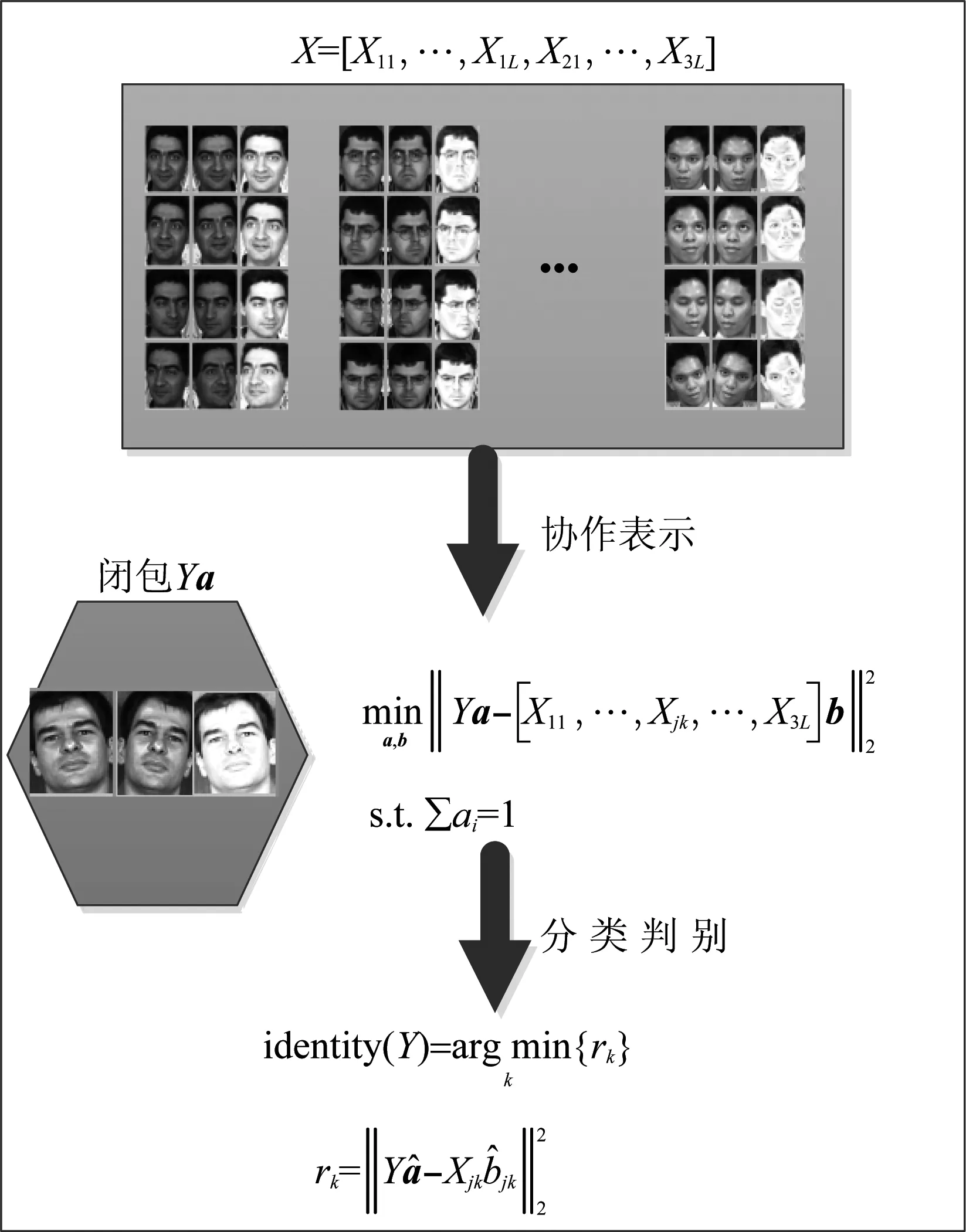
图1 系统组成框图
3 构建扩展字典
图像的多重描述能够提供互补信息,故构建具有多重描述的扩展字典。因图像集能够传达目标类内变化信息,所以图像集人脸识别明显优于单一图像的人脸识别。
3.1 扩展字典
3.1.1镜像图像生成
人脸图像拥有轴对称的结构,但是通常情况下,几乎没有绝对正面的人脸图像,大多数都是不对称图像。由原始图像产生的镜像图像不仅能够克服人脸识别中人脸图像的错位问题,而且可以消除原始图像姿势和光照的边缘影响从而反应原始图像在姿势或者光照中的可能变化因素。


(1)
其中,p=1,…,P,q=1,…,Q。
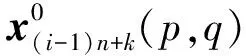

图2 GT库原始图像和镜像图像
虽然镜像图像是由原始图像生成的,但镜像图像也是自然图像且可以正确反映原始图像的姿势和光照的变化。此外,在距离度量方面镜像图像与原始图像完全不同。所以利用镜像图像可以获得人脸更多的可利用信息。
3.1.2中等像素图像生成
从图像中提取显著特征对于图像分类至关重要。同一类人的训练样本和测试样本相同位置有着不同的像素强度,这加大提取显著特征的难度。根据每张图像不同位置像素的作用不同,可用原始样本产生中等强度像素图像,此图像加强了原始图像中等强度像素的区域降低了其他强度像素区域[19]。
I代表一张原始图片,Iij表示图像I的第i行和第j列的像素强度。假设m是所有像素的最大值,对于传统的灰度图像m=255。由原始图片I产生的中等强度像素图像J方法如下:
Jij=Iij·(m-Iij)
(2)
Jij表示中等强度像素图像J的第i行和第j列像素的强度。

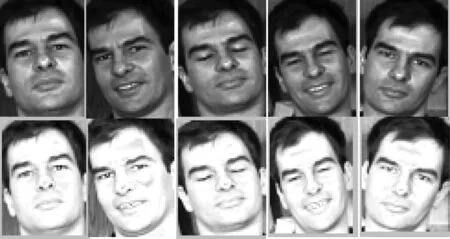
图3 GT库原始图像和中等强度像素图像
研究表明图像分类中不同像素发挥着不同作用。式(2)表明,图像中等像素位置是描述图像的关键部位。对于变化人脸图像,中等强度像素比较稳定。原始图像和像素强度产生图像可提供同一人脸图像的多重特征。
融合原始图像、镜像图像、中等像素图像构成本文的扩展字典,实现多重描述人脸图像,更好地完成人脸识别。
3.2 单集到单集闭包建模
相比图像集有参建模模型,无参建模方法不用估计参数分布故有许多有利性能。一种简洁的无参建模方法是闭包建模方法,即将一个图像集建模成其样本的线性组合。
假设图像集Y={y1,…,yi,…,yna},yi∈Rd,图像集Y的凸闭包被定义为:H(Y)={∑aiyi}。通常,要求∑ai=1且系数ai是有界的:
H(Y)={∑aiyi|∑ai=1,0≤ai≤τ}
(3)
假设Y={y1,…,yi,…,yna}是一个图像集,Z={z1,…,zj,…,znz}是另一个图像集,那么将图像集建模成凸闭包,图像集Y到图像集Z的距离被定义如下:
s.t. ∑ai=1,0≤ai≤τ
∑bi=1,0≤bi≤τ
(4)
若两个图像集没有交集,式(4)的单一集到单一集的距离就是两个凸闭包最近两点距离,如图4所示。如果将每一类看做一个图像集,两类间最大边界就是集到集的距离。
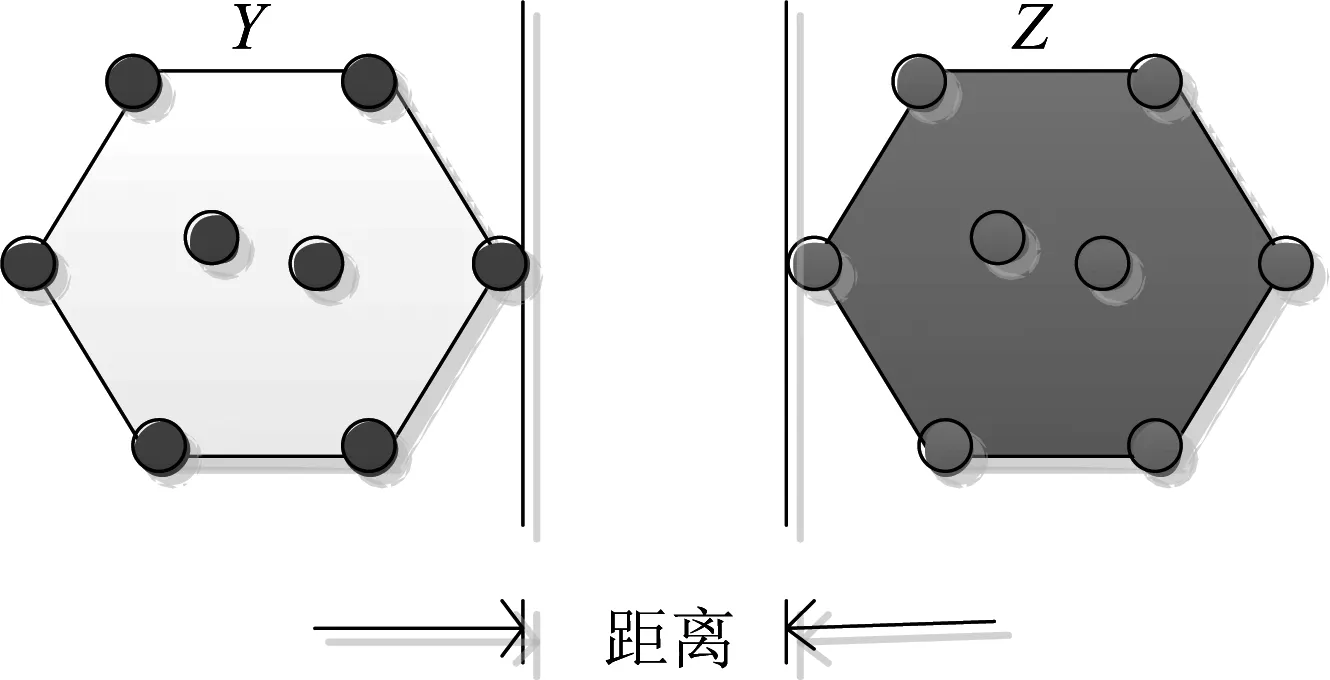
图4 单集到单集距离的凸闭包
4 闭包建模图像集协同表示人脸识别算法
4.1 单集到多集协同表示分类
本文扩展字典图像集由原始图像、镜像图像和中等像素图像构成,三种源域图像种类数量相一致。假设每种源域图像有L类,第i类有n个训练样本。图像集人脸识别中,Y表示同类同姿态相异源域的图像构成的测试集,Xjk(j=1,2,3;k=1,…,L)表示训练字典集。研究表明,人脸识别中异类人脸图像存在相似之处。若用2.2节求解单集到单集距离的方法,那么训练样本类间的协作表示能力就被忽略。将SRC和CRC中训练样本线性表示测试样本的理论知识运用于图像集,提出本文的闭包建模图像集协同表示人脸识别算法。
X=[X11,X12,…,X1L,X21,…,X2L,X31,…,X3L]表示所有训练样本即扩展字典。建模字典X为闭包字典,同类同姿态相异源域图像构成测试集,建模为测试闭包,分别用Xb和Ya表示,其中a和b是系数向量。定义单集Y到多集X的距离如下式:
mina,b‖Ya-Xb‖2s.t.∑ai=1
(5)
其中,ai是a的第i个的系数。式(5)的求解将在4.2节详解。
(6)

求解式(5)闭包系数,本文采取正则化优化方法,即4.2节的正则化闭包协同表示方法。
4.2 单集到多集正则化闭包协同表示
本节将详细给出式(5)的求解方法,L1范数和L2范数都能正则化系数向量a和b,但是L1范数求解的稀疏解更稀疏,所以本文应用L1范数正则化闭包解决问题。
4.2.1主要模型
根据3.2节,测试集Y的L1范数正则化闭包定义如下:
H(Y)={∑aiyi|‖a‖l1<δ}s.t.∑ai=1
(7)
扩展字典的L1范数正则化闭包定义如下:
H(X)={∑bixi|‖b‖l1<δ}
(8)
闭包Y和闭包X的距离定义如下:
s.t.‖a‖l1<δ1,‖b‖l1<δ2,∑ai=1
(9)
为求解式(9)最小化问题,将式(9)重新改写为它的拉格朗日表达式:
s.t.∑ai=1
(10)
其中,λ1和λ2是平衡残差和正则化矩阵的正常数。在式(10)中若测试集Y仅一个样本那么a=1,则本文方法就简化成SRC过程。
4.2.2正则化过程
交替最小化方法能非常有效解决多个变量优化问题,故本文采用此方法优化式(10)。该式增广的拉格朗日函数如下:
(11)
其中,λ是拉格朗日乘数,<·,·>表示内积,γ>0表示惩罚因子,e是一个所有元素为1的行向量。
求解a和b时,固定一个量优化另一个量。最小化a的过程如下:
a(t+1)=arg minaL(a,b(t),λ(t))=arg minaf(a)+
(12)

当a(t+1)被更新完毕,b(t+1)继续L1正则化优化。
b(t+1)=arg minbL(a(t+1),b,λt)=
(13)
求解a(t+1)和b(t+1)后,λ可据以下式进行求解:
λ(t+1)=λ(t)+γ(ea(t+1)-1)
(14)
上式参数设置如下:λ1=0.001,λ2=0.001,λ=2.5/na(na是每个测试集闭包的样本数量),γ=λ/ 2。
单集到多集正则化闭包协同表示算法的具体步骤如下:
1)输入:测试集Y;λ1和λ2;扩展字典集X=[X11,X12,…,X1L,X21,…,X2L,X31,…,X3L]。
2)初始化:β(0),λ(0)和0←t。
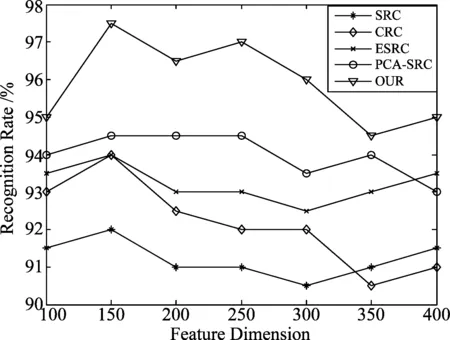
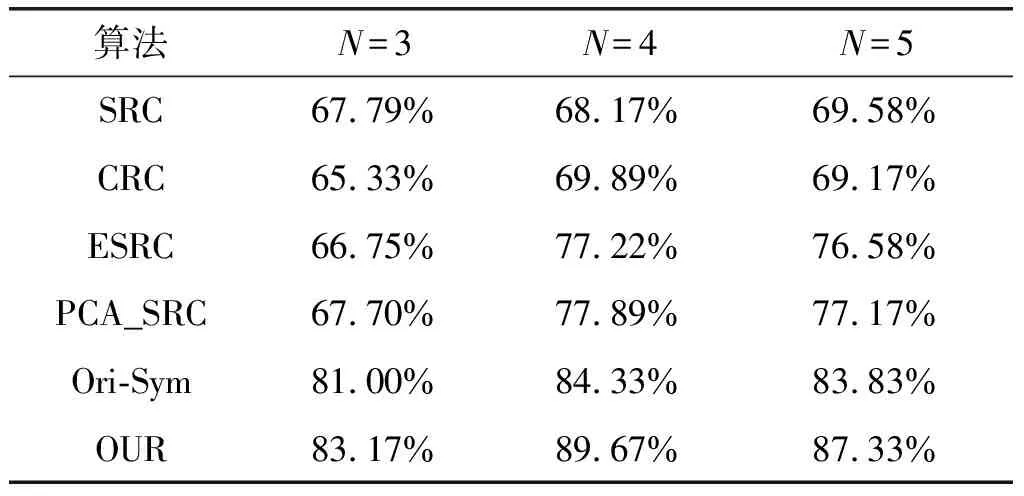
3)当t 第1步:用式子(12)更新a; 第2步:用式子(13)更新b; 第3步:用式子(14)更新λ; 第4步:t←t+1。 输出:测试集Y的标签: 本文方法在ORL、CMU PIE和GT(Georgia Tech Face Database)、FERET人脸数据库中进行一系列实验。并且与基于分类的稀疏表示算法(SRC)、基于分类的协同表示算法(CRC)、类内变化联合扩展字典的稀疏表示算法(ESRC)、原始图像和特征脸联合的扩展字典稀疏表示算法(PCA-SRC)、原始图像及其镜像图像联合的扩展字典表示算法(Ori-Sym)进行对比实验。 ORL数据库共有40人,每人有10幅人脸图像。将原始图像用3.1节知识产生镜像图像和中等像素图像,从而形成扩展的图像集。图5是ORL数据库集部分图像,第一行是原始图像,第二行是镜像图像,第三行是中等像素图像。 图5 ORL三种源域图像部分图像 在实验中,每种源域图像每类选取N(=4,5,6)幅图像构成扩展字典,同类同姿态异源域的图像构成测试集,这样测试样本就构成了图像集。原始图像尺寸为56×46,采用下采样对图像进行降维处理,从而给出维度变化时的识别率。 三种源域训练图像联合构建扩展字典闭包,同类同姿态相异源域的图像建模测试闭包。表1对比了基于分类的稀疏表示算法(SRC)、基于分类的协同表示算法(CRC)、类内变化联合扩展字典的稀疏表示算法(ESRC)、原始图像和特征脸联合的扩展字典稀疏表示算法(PCA-SRC)、原始图像及其镜像图像联合的扩展字典表示算法(Ori-Sym)和本文方法在不同训练样本个数下的正确识别率。 表1 ORL数据库不同算法的正确率对比 在图像不同维度下进行实验,将基于分类的稀疏表示算法(SRC)、基于分类的协同表示算法(CRC)、类内变化联合扩展字典稀疏表示算法(ESRC)、原始图像和特征脸联合的扩展字典稀疏表示算法(PCA-SRC)与本文方法在维度变化下进行对比,图6是各种算法在图像不同维度下的识别率曲线。通过图6可以看出本文方法的识别率高于其他算法。 图6 维度变化的各种算法识别率Fig.6 The recognition rate of different methods about various dimensions GT(GeorgiaTechFaceDatabase)数据库共有50人,每个人有15幅人脸图像。将原始图像用3.1节知识产生镜像图像和中等像素图像,从而形成扩展的数据集。图7是GT数据库部分图像,第一行是原始图像,第二行是镜像图像,第三行是中等强度像素图像。 图7 GT三种源域图像部分图像Fig.7 Three domains image of GT face database 每种源域图像每类选取N(=7,8,9)幅图像构成扩展字典,同类同姿态相异源域的图像构成测试集,这样测试样本就构成了图像集。灰度处理全部图像,并对图像进行降维处理,从而给出维度变化时的识别率。 三种源域训练图像联合构建扩展字典闭包,同类同姿态相异源域的图像建模测试闭包。表2分别比较SRC、CRC、ESRC、PCA-SRC、Ori-Sym和本文方法在不同训练样本个数下的正确识别率。 表2 GT数据库不同算法的正确率对比 针对维度变化对算法的影响进行实验,将SRC、CRC、ESRC、PCA-SRC和本文方法在维度变化下进行对比。图8是维度变化时各种算法的识别率曲线。 图8 维度变化的各种算法识别率 CMU PIE数据库有五个图像子集,每类人脸包含姿态变化、光照变化及表情变化。本实验选取C09图像子集,C09子集含有68人,每类人包含24张包含表情及光照变化图像,所有图像进行裁剪尺寸为64×64。采用下采样对图像进行降维处理,从而给出维度变化时的识别率。每种源域图像每类选取N(=10,12,14)幅图像构成扩展字典,同类同姿态相异源域的图像构成测试集。 将原始图像用3.1节知识产生镜像图像和中等像素图像,从而形成数据集。图9是CMU PIE数据库集的部分图像,第一行是原始图像,第二行是镜像图像,第三行是中等像素图像。 图9 CMU PIE数据库集部分图像 表3分别比较SRC、CRC、ESRC、PCA-SRC、Ori-Sym和本文方法在不同训练样本个数下的正确识别率。 表3 CMU PIE数据库不同算法的正确率对比 为充分说明本文提出方法的有效性,在图像维度变化的情况下将SRC、CRC、ESRC、PCA-SRC和本文方法进行对比实验。图10是不同算法在图像维度变化下的识别率曲线,由图可看出本文方法优于其他算法。 图10 维度变化的各种算法识别率 FERET人脸数据库包含200个人,每个人7张人脸图像。每种源域图像每类选取N(=3,4,5)幅图像构成扩展字典,同类同姿态相异源域的图像构成测试图像集。数据库原始图像尺寸是80×80,采用下采样对图像进行降维处理,且给出维度变化时的识别率。 将原始图像用3.1节知识产生镜像图像和中等像素图像,从而形成数据集。图11是FERET数据库集的部分图像,第一行是原始图像,第二行是镜像图像,第三行是中等强度像素图像。 图11 FERET数据库集部分图像 表4分别比较SRC、CRC、ESRC、PCA-SRC、Ori-Sym和本文方法在不同训练样本个数下的正确识别率。 表4 FERET人脸数据库几种方法的识别率 为进一步验证本文算法的性能,将SRC、CRC、ESRC、PCA-SRC和本文方法在维度变化下进行对比。图12为不同维度下各算法识别率变化曲线。 图12 维度变化的各种算法识别率 本文充分利用样本集内部相关性和差异性,提出图像集闭包建模的协同表示人脸识别算法。首先,从扩展字典的角度出发,据镜像图像可以克服人脸图像不总是轴对称图像的不足;据图像分类中不同像素起着不同作用的原理产生中等强度像素图像,从而整个数据集扩展成由原始图像、镜像图像和中等像素图像汇集的数据集。然后,利用无参模型建模训练集扩展字典闭包,同类同姿态异源域的图像构成测试图像集,字典闭包协同表示测试图像集进而利用字典更新求解闭包系数。最后,利用残差进行分类判别。通过实验验证,本文方法效果优于其他方法的效果。 [1] Zeng Shaoning, Yang Xiong, Gou Jianping. Multiplication fusion of sparse and collaborative representation for robust face recognition[J]. Multimedia Tools and Applications, 2017,76(20): 20889-20907. [2] Faraki M, Harandi M T, Porikli F. Image set classification by symmetric positive semi-definite matrices[C]∥2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA: WACV, 2016: 1- 8. [3] Li Fang, Zhang Sanyuan. Laplacian sparse coding dictionary for image set based collaborative representation[C]∥2016 2nd IEEE International Conference on Computer and Communications (ICCC),Chengdu, China: ICCC, 2016: 245-249. [4] Hayat M, Khan S H, Bennamoun M. Empowering simple binary classifiers for image set based face recognition[J]. International Journal of Computer Vision, 2017,123(3):479- 498. [5] 胡正平, 白帆, 王蒙, 等. 原子-分子字典结合的联合扩展加权稀疏表示人脸识别算法[J]. 信号处理, 2016, 32(7): 801- 809. Hu Zhengping, Bai Fan, Wang Meng, et al. Atom-molecule dictionary joint extended weighted sparse representation face recognition algorithm[J]. Journal of Signal Processing, 2016, 32(7): 801- 809.(in Chinese) [6] Xu Yong, Zhu Xingjie, Li Zhengming, et al. Using the original and ‘symmetrical face’training samples to perform representation based two-step face recognition[J]. Pattern Recognition, 2014, 46(4): 1151-1158. [7] Wu Shuai, Cao Jian. ‘Symmetrical face’based improved LPP method for face recognition[J]. Optik-International Journal for Light and Electron Optics, 2014, 125(14): 3530-3533. [8] Xu Yong, Li Xuelong, Yang Jian, et al. Integrate the original face image and its mirror image for face recognition[J]. Neurocomputing, 2014, 131: 191-199. [9] Xu Yong, Li Xuelong, Yang Jian, et al. Integrating conventional and inverse representation for face recognition[J]. IEEE Transactions on Cybernetics, 2014, 44(10): 1738-1746. [10] Chen Jingwei, Feng Yong, Liu Yang, et al. Sparse non-negative matrix factorization with generalized Kullback-Leibler divergence[C]∥International Conference on Intelligent Data Engineering and Automated Learning. Springer International Publishing(IDEAL), Wroclaw, Poland:IDEAI, 2016: 353-360. [11] Huang Zhiwu, Wang Ruiping, Shan Shiguang, et al. Hybrid Euclidean-and-Riemannian metric learning for image set classification[C]∥Asian Conference on Computer Vision. Springer International Publishing(ACCV), Singapore, Singapore:ACCV, 2014: 562-577. [12] Tan Hengliang, Ma Zhengming, Zhang Sumin, et al. Grassmann manifold for nearest points image set classification[J]. Pattern Recognition Letters, 2015, 68: 190-196. [13] Feng Qingxiang, Zhou Yicong, Lan Rushi. Pairwise Linear Regression Classification for Image Set Retrieval[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR),Las Vegas, Nevada:CVPR, 2016: 4865- 4872. [14] Kumar S, Savakis A. Learning a perceptual manifold for image set classification[C]∥2016 IEEE International Conference on Image Processing (ICIP),Phoenix, USA:ICIP, 2016: 4433- 4437. [15] Shah S A A, Bennamoun M, Boussaid F. Iterative deep learning for image set based face and object recognition[J]. Neurocomputing, 2016, 174: 866- 874. [16] Leng M, Moutafis P, Kakadiaris I A. Joint prototype and metric learning for image set classification: Application to video face identification[J]. Image and Vision Computing, 2017, 58: 204-213. [17] Wright J, Yang A Y, Ganesh A, et al. Robust face recognition via sparse representation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(2): 210-227. [18] Zhang Lei, Yang Meng, Feng Xiangchu. Sparse representation or collaborative representation: Which helps face recognition?[C]∥2011 IEEE International Conference on Computer Vision (ICCV),Barcelona, Spain:ICCV, 2011: 471- 478. [19] Xu Yong, Zhang Bob, Zhong Zuofeng. Multiple representations and sparse representation for image classification[J]. Pattern Recognition Letters, 2015, 68: 9-14.
5 实验仿真
5.1 ORL数据库


5.2 GT数据库



5.3 CMU PIE数据库



5.4 FERET人脸数据库


6 结论
