移动端非显式用户身份信息的隐私问题研究①
2018-08-17代遵志滕彩峰张路桥
张 颖,代遵志,滕彩峰,张路桥
(成都信息工程大学 网络空间安全学院,成都 610000)
随着社会的发展,人们对隐私保护的重视程度越来越高,大家对隐私问题越来越敏感,移动互联网隐私安全研究逐渐成为一个热点.传统的隐私保护技术主要分为3类:数据扰动技术、数据加密技术和数据匿名化技术[1].通过这些技术,我们能有效保护个人隐私,但是在日常生活中不经意间隐私信息可能会就被泄漏,从用户的角度看,微量隐私[2]的泄露也许并无严重后果,但难以证实的是,通过获取大量用户的数据,利用机器学习分析用户行为习惯可能会得到用户其他隐私信息,用户的身份信息,以及社会关系,现阶段这方面的研究是很少的.
为了更好的保护我们的隐私,我们得知道隐私泄露的途径有哪些,一个应用可以通过哪些信息得到我们的隐私数据.显而易见,隐私数据包括通信录,通话记录,聊天记录,短信[3]等等这些有明显身份信息的显式信息,而另一方面一个应用不仅可以收集上传信息,也可以在不需要额外的权限下收集一些非显式的用户身份信息,这方面是经常被忽略的,而本文的研究目的就是去分析这些非显式的用户身份信息是否对用户的隐私产生威胁,如果产生威胁的程度有多大,这个衡量的标准取决于通过这些信息挖掘出用户身份的准确率[4].准确率越高那么产生的威胁越大,也叫告诉我们在使用手机的过程中,为了保护我们的隐私[5]也要额外警惕不良应用收集这些非显式的身份信息,有需要的话可以利用Android系统权限限制,禁止应用使用某些权限.
本文通过志愿者来采集智能手机使用过程中产生的不包含任何显式用户身份信息的用户行为数据,通过分析数据对用户身份进行识别,推测他们的社会关系,并研究哪些数据会对用户隐私产生威胁,而这些数据造成的隐私泄露不容小觑,应该对非显式用户身份信息加以保护,使用过程中加以限制,帮助普通用户更好的保护隐私.
1 国内外研究现状
对于移动互联网隐私安全的研究很早就开始了,并且对于移动用户信息隐私的泄露和保护的研究也逐渐成为一个热点.文献[6]是利用手机传感器数据加上蜂窝网及Wi-Fi网络信息强度等参数实现对用户连接AP时长的预测.文献[7]利用用户与AP关联数据实现对用户身份预测,并证明了仅仅通过对设备编号的哈希等匿名化处理是不能够有效保护用户隐私的.文献[8]利用手机使用过程中所产生的网络流量对用户网络使用行为进行统计学分析.文献[9]利用了用户在不同类型地点连接网络时体现出来的网络使用方式的差异,实现了用户所在地点类别的识别.现阶段大多是利用Wi-Fi网络信息、AP关联数据、用户手机使用行为等直接对个体或群体层面进行用户行为分析预测,而关于非显式的用户身份信息对用户的隐私保护的研究还不完善,本文就此进行研究.
2 用户行为数据处理流程
人们在智能手机使用的过程中会产生各种各样的数据,绝大部分的数据本身是不包括和携带任何用户身份信息的[10,11],这些原始信息如果没有经过特殊处理是不会对用户隐私产生威胁的.但是通过采集大量用户数据建立用户行为特征库,可以实现对用户身份信息进行识别,甚至推测用户的社会关系.
2.1 移动端非显示身份信息数据采集阶段
数据采集阶段主要根据需求采集相应的非显式身份信息,即这些信息是不直接标识用户身份的.因为这些数据均与用户使用习惯和行为存在着直接或者间接的联系,可以通过分析对用户身份进行识别,并且一个正常的应用收集这些信息也不需要申请其他敏感权限.这些信息详情见基础数据表1.

表1 基础数据表
① 网络流量信息、Wi-Fi网络信息以及移动蜂窝网信息:这些信息反映了用户网络使用习惯,网络连接的偏好,智能手机安装应用产生的网络流量,推测用户选择的通信运营商等等.另外,Wi-Fi网络的SSID信息和蜂窝网基站信息都间接隐藏着用户的地理位置信息,这种对应关系可以经过推测能得到用户访问的历史位置信息,可以通过构建每位用户连接过的Wi-Fi网络集合,对用户社会关系进行推测.
② 屏幕状态信息:通过每一次屏幕的点亮熄灭的时间间隔、一段时间的点亮次数,知道用户各个时段手机使用时长等习惯,推测用户使用手机强度和频率.
③ 电池电量信息:用户使用手机的充电方式,充电时间规律等行为习惯的体现.
④ 手机陀螺仪、光敏传感器:是对用户使用手机时的环境、拿握手机的姿势(睡姿或者坐姿),手机携带方式(随身携带或者放置在桌面上等)行为的体现.
除此之外,还会采集设备的国际移动设备标识(International Mobile Equipment Identity,IMEI)[12]为用户身份标定,以便进行实验结果的准确率的验证.
本次采集的数据未包含任何显式的用户身份信息,与数据相对应的时间戳也同步记录.为此我们开发了一个数据采集系统安装在志愿者的手机上去采集这些数据,此系统包括Android手机客户端,Python自动化脚本,用户行为特征数据库.
2.2 移动端非显示身份信息数据预处理和特征选取阶段
数据预处理阶段主要是从采集到的数据中提取与用户行为有关的数据,通过脚本导入数据库,剔除无效数据,再根据采集数据类型进行分类,以便于后期进一步处理[13].
对于数据包大小、数据量等数值数据,将根据其采集时间进行分箱,数据分箱后可以进一步得到其最大值,最小值、均值等统计学特征.网络连接状态,充电状态等布尔型的数据可以通过计算转化为网络连接时长,充电时长等数据,再计算其统计学特征.最后,去除部分相关性较高的数据,例如:电池电量消耗速度与屏幕点亮熄灭的频率等,以降低后续数据处理的复杂度.
2.3 移动端非显示身份信息数据分析阶段
数据分析阶段结合预处理后的数据和数据分析模型实现用户行为的分析和身份的识别,推测出其存在的社会关系.为降低难度和提高识别率,前期可通过数据可视化技术得到一些统计学特征和趋势图,使用Weka分类算法中的J48(决策树C4.5)将数据预处理后充电时长,充电间隔,屏幕点亮时长,屏幕点亮间隔,网络流量大小,并以天为单位进行分箱,得到输入的样本数据,构建决策树从而对用户分类识别[14],再根据这些信息选取适当的数据使用皮尔森相关系数等方式描述用户行为,推测其社会关系.
3 数据分析
3.1 用户识别
目前小规模收集的有效数据有八万多条,包括5名用户对象,采集的数据的用户社会关系包括了情侣关系,同年级不同寝室同实验室的同学关系,不同年级不同寝室同实验室的同学关系以不同年级不同寝室不同实验室的同学关系.
以手机的IMEI号为唯一标识确定他们的对应关系如表2所示,为保护采集数据的用户隐私,本文用户名字使用字母代替.

表2 用户关系图
我们对目前收集的数据进行分析,发现用户的行为不论是网络行为,还是手机的使用习惯都存在着明显的差异.如表3所示,用户每天屏幕点亮的次数就存在这明显的差异
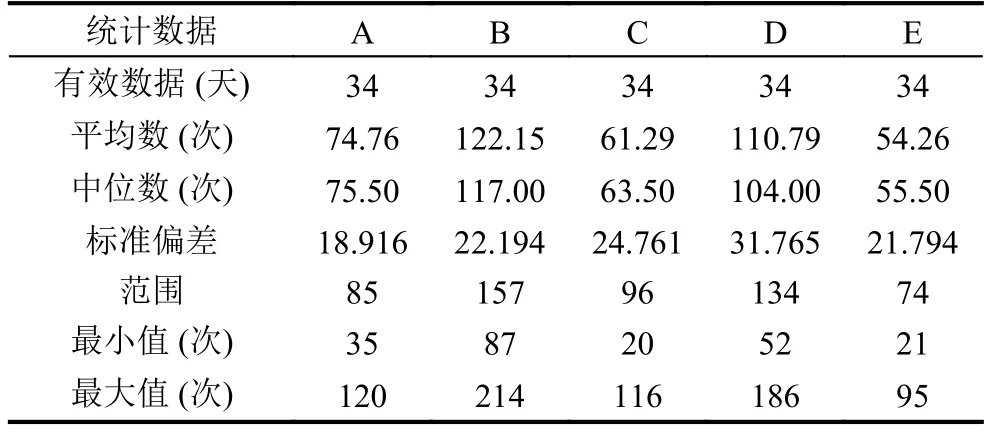
表3 用户每天屏幕点亮数据统计表
分析表中的数据可以发现,用户BD相对而言每天使用手机的频率要远高于其他三人,与事实相吻合,用户BD经常使用手机刷微博微信等社交软件.用户AC使用手机的频率相对较少,原因是A为研究生一年级的同学,课时任务比较多,C同学在上班,使用手机的频率自然要少一些.这说明屏幕点亮信息与个人使用手机的习惯是正相关的.同时也对手机充电次数也做了类似的分析,其充电次数统计信息如表4所示

表4 每天充电次数
从表中可以看出用户BDE每天充电的次数要高于其他两者,与表3每天屏幕状态统计信息的数据基本相符,一般而言,手机使用频繁度与充电次数是正相关的.其中不同的地方在于用户E,因为E从事Android开发,常常会在真机上测试程序,但平时使用手机并不频繁,这也是用户E充电次数会偏高的原因.
这些数据表明不同的用户的手机行为或者习惯是不一样的,正是因为每个人都有自己的行为特点,所以我们可以利用屏幕状态信息和充电次数信息对用户进行识别.本文使用Weka分类算法中的J48(决策树C4.5)对用户进行识别,J48是对ID3算法的扩展,其主要区别在于可以容忍缺失数据,这一点也是本文选择这个算法的主要原因.由于手机上收集数据的特殊性,数据会存在一部分的缺失,通过J48这一特性可以很好的弥补数据上的缺陷.J48的主要思想是以信息熵的增益为依据,从原始样本中提取最有利于区分类别的属性,逐渐的由根节点到叶子节点构建决策树,其流程如图1所示.
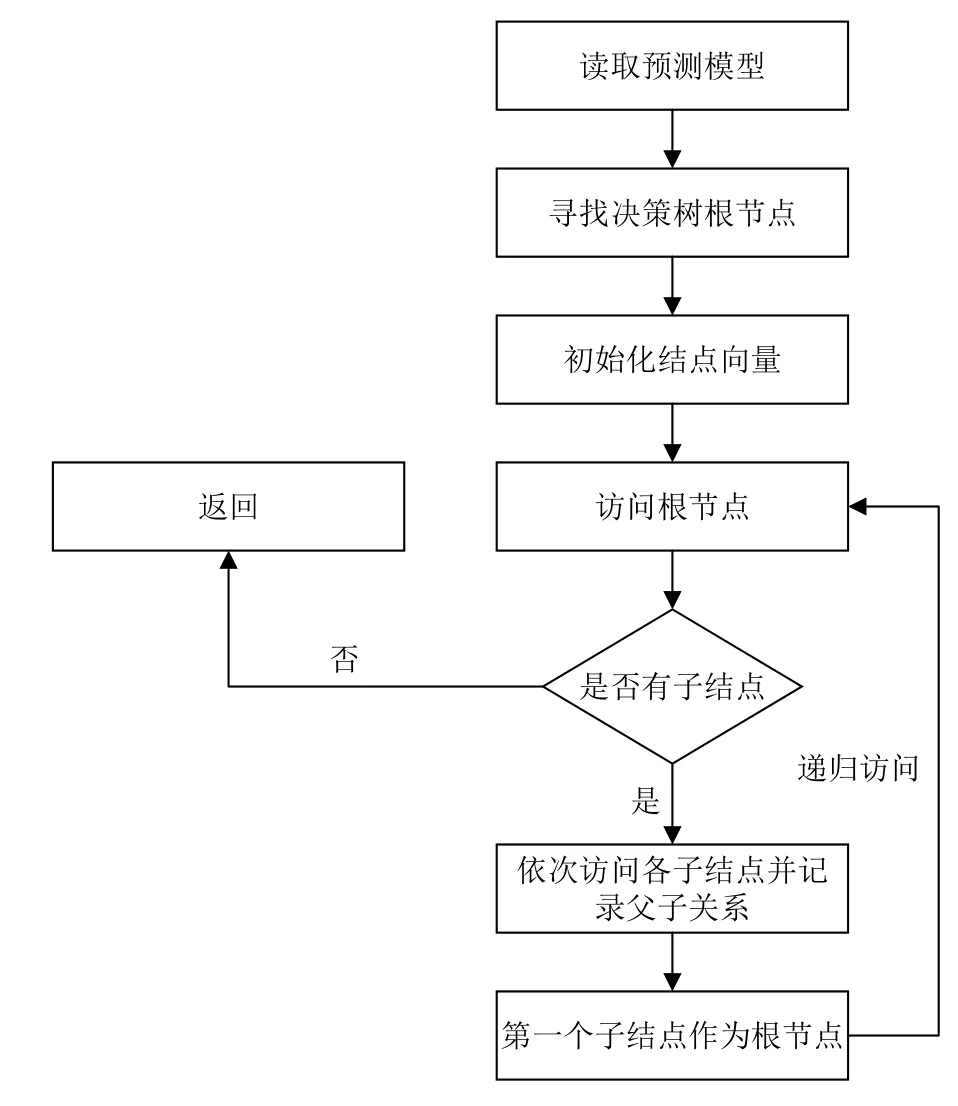
图1 决策树算法流程图
我们通过对数据预处理后,得到充电时长,充电间隔,屏幕点亮时长,屏幕点亮间隔,网络流量大小,并以天为单位进行分箱,这样得到输入的样本数据,而构建决策树的过程中以上文计算得到的各种统计值作为分支条件,算法性能数据详见表5.

表5 使用Fast decision tree进行用户识别的准确率
从上表中ROC Area的值均在0.9左右,其准确率已远高于随机猜测,说明我们的分类算法能有效的对用户身份进行识别.
3.2 社会关系推测
社会关系推测采用的方法如下:
首先,因Wi-Fi网络的SSID不一样,而每个SSID代表一个地理位置,若两人连接的SSID相同说明两人在同一区域出现过,越经常在同一区域出现,两人认识的机率越大,故可通过用户访问过的Wi-Fi网络重合度、相似度进行社会关系紧密程度推测.其SSID统计数据如表6所示,横轴代表用户,纵轴代表连接Wi-Fi的SSID,数字代表本文收集数据期间用户与该SSID的Wi-Fi连接次数.由于每个用户连接过的SSID数据较大,但常连接的一般只有三四个,因此只保留了用户连接次数最多的前四个SSID,具体统计数据如下.

表6 SSID连接次数
其中连接bigWIN(SSID名称)的人最多,说明用户ABDE经常出现在同一个地点.还可以明显看出用户C E社会关系紧密程度很高,其共同连接FiveMeters的次数均在7200左右,而其他人均为了0,用户CE除去FiveMeters外,并没有相同连接的SSID,可以明确推测出CE用户的关系十分紧密,实际上,CE为情侣关系,一人上班,一人在学校,所以其相同的FiveMeters只有一个.其中连接bigWIN的次数也可以明显分析出他们的社会关系.用户ABDE在经常出现在同一地点,而用户C除了与E关系亲近,与其他人并不熟悉,与实际相符合.
在判断数据的相关性,将采用皮尔森相关系数去计算两两用户间访问过S S I D集合的相似度.Pearson相关系数也称为皮尔森积矩相关系数,其计算公式如下:

Pearson相关系数的取值在–1到1,值越接近于正负1,相关度越大,值为0代表两个数据完全不相关.双尾显著性检测就是双侧检验,举例说明若双尾显著性为0.05,则说明有95%的把握确认相关性的存在.
我们使用表6的样本计算Pearson相关系数,其结果如表7所示:

表7 SSID的Pearson相关系数表
综上所述,我们的小规模实验结果表明,用户CE的关系十分紧密,与实际情况相一致,其中CE的皮尔森相关系数为0.977,双尾显著性为0.000029.
4 结语
通过我们的研究发现即便是非显式用户身份信息,通过大规模数据分析,对用户身份进行识别,并推测出部分用户间的社会关系等结论也会对用户隐私造成威胁,为了保护我们的隐私要额外警惕不良应用收集这些非显式的身份信息,有需要的话可以利用Android系统权限限制,禁止应用使用某些权限来加以保护.随着个人的隐私越来越受到人们的重视,隐私保护逐渐成了当前迫在眉睫的研究课题.
