基于深度学习的运动目标实时识别与定位①
2018-08-17童基均常晓龙赵英杰蒋路茸
童基均,常晓龙,赵英杰,蒋路茸
(浙江理工大学 信息学院,杭州 310018)
1 引言
目标检测与定位是计算机视觉领域中一个重要的研究课题[1].检测出感兴趣目标及其位置是计算机视觉科研工作者关注的重点[2].传统的检测方法通过特征提取、多特征融合进行目标检测.例如通过提取HOG[3]、LBP[4,5]和SIFT[6]特征,将提取到的特征通过SVM[7]或者AdaBoost[8]等分类器进行分类识别.但随着场景的变换、光照的影响以及实时性要求等使得传统方法无法满足人们的需求.
近几年深度学习由于其快速的处理能力和较高的准确率在计算机视觉中得到广泛应用,使得在一些复杂条件下利用视觉对场景进行分析成为可能.2012年Krizhevsky等[9]采用AlexNet网络的卷积神经网络(Convolutional Neural Networks,CNN)在ImageNet图像分类中取得了最好的成绩.最初将深度学习应用到目标检测的是Girshick[10]等提出的R-CNN(Regionbased Convolutional Neural Networks)方法.R-CNN将区域建议(region proposal)[11,12]和卷积神经网络相结合,但是在速度与精度上还无法满足人们的需求.而后,He[9]等人提出SPP-Net、Girshick[13]等人提出Fast RCNN以及Ren[14]等人提出的Faster R-CNN都是在最开始的R-CNN的基础上进一步的改进,且都是基于区域建议框,因此其速度都受到一定限制.针对此问题,有研究者提出了一系列的基于无区域建议的方法:如Redmond[15]等提出的YOLO(You Only Look Once)已经达到了实时检测的效果,但是检测精度确不够理想,随后Liu[16]等人提出SSD(Single Shot multibox Detector)模型,在提高检测精度的同时也兼顾到了实时性的要求,可以说是一个相对而言比较理想的一个算法.本文就是基于此算法构建了人体运动检测模型.
2 系统架构
本系统首先用不同的视觉标记物对运动目标进行一定的标记,并通学习训练相应的模型;接着通过深度学习技术对穿戴标记物的运动人体进行检测和识别,文中标记物为自己设计的不同颜色和纹理的帽子,通过检测人体所佩戴的标记物来唯一识别每一个个体,便于后面做定位,因此只需对标记物进行训练,当人员更换时只需佩戴相应的视觉标记物而不需要重新训练;最后利用立体视觉定位算法对其进行定位,从而实现人体运动目标实时检测与定位.
本视觉定位系统通过2路高清网络摄像机获取视频码流,直接输出数字信号,省去了图像采集卡将模拟信号转化为数字信号的操作.视频实时流首先通过解码服务器将码流转换为能够处理的图像格式,然后在分析管理服务器上进行多路视频同步、检测以及定位等操作,将结果反馈给客户端,分析管理服务器同时也负责接受客户端的控制指令.视频检测流程图如图1所示.
2.1 多线程并行视频流采集
视频采集端采用2个网络摄像头进行采集,利用ffmpeg中的解码库,将相机输出的rtsp实时流通过解协议、解封装最终将视频解码成在RGB颜色空间上的图像格式,同时利用pthread多线程处理库,通过互斥锁和信号量实现多相机并行采集以及同步问题.
2.2 人体运动目标检测
目标检测部分采用深度学习框架Caffe[17],利用SSD物体检测模型进行运动人体的检测.该方法既保证了目标检测的精度,又保证了目标检测的速度.SSD方法的核心是使用小的卷积滤波器来预测特征图上固定的一组默认边界框的类别分数与位置偏移量.从不同尺度的特征图上产生不同尺度的预测,并通过不同的宽高比来正确的进行预测.一个单次检测器SSD用于多类别目标检测,比YOLO速度更块,和使用区域建议、pooling技术的检测方法(faster R-CNN)一样准确.SSD目标检测的原理如图2所示.
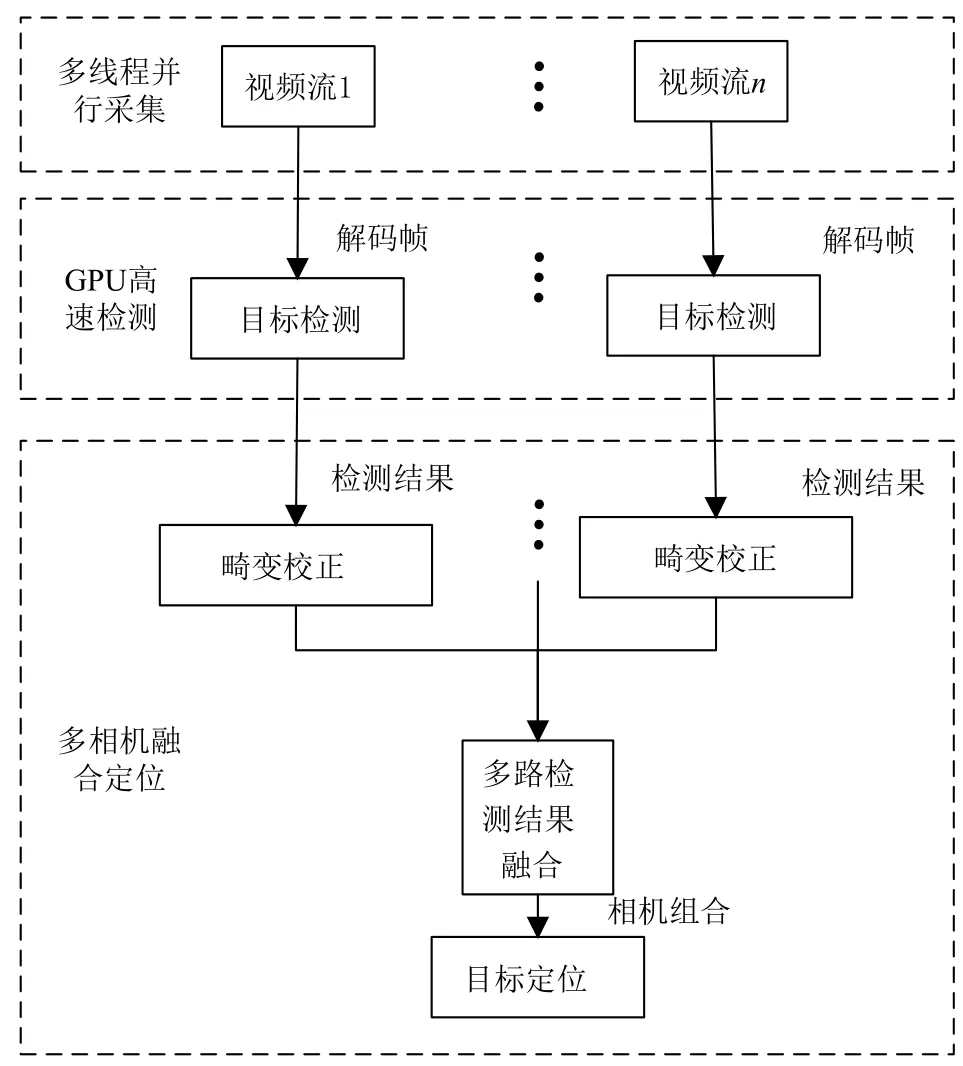
图1 人体运动目标实时检测定位流程图
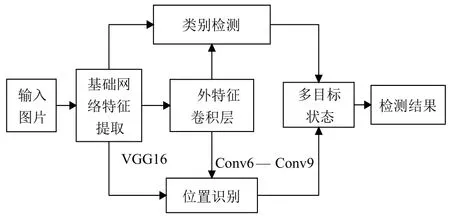
图2 SSD检测原理图
2.2.1 SSD网络模型
SSD是基于前馈卷积神经网络,产生固定大小的边界框集合和边界框中对象类别的分数,然后通过非最大抑制来产生最终检测结果.本文采用VGG16[18]网络作为基础网络,用于特征提取,然后再向基础网络中添加辅助结构,产生特定的特征用于检测[15].如图3所示,这些特征层的尺度逐渐变小,可以得到多个尺度检测的预测值.
2.2.2 训练
SSD的训练与传统方法的区别在于真实标签需要与固定的检测器输出集合中的某一个特定的输出相对应(端到端训练).训练时,需要建立默认框与真实框之间的一一对应关系[15].可以从不同位置、尺度、宽高比的默认框中选择真实的目标标签框.
2.3 双目定位
双目定位首先需要考虑摄像机的标定与图像的畸变矫正问题.本文采用张正友的基于平面模版的标定方法[19],然后进行去畸变处理,得到合理的相机标定结果.
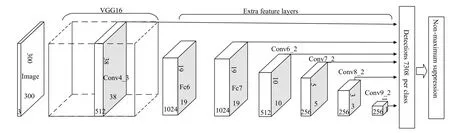
图3 SSD网络结构图
图4 中oc为摄像机的光心,zc为光轴,(u,v)为像素坐标,o(u0,v0)为图像坐标系原点,oco为摄像机的焦距f,图像坐标与像素值的对应关系为:
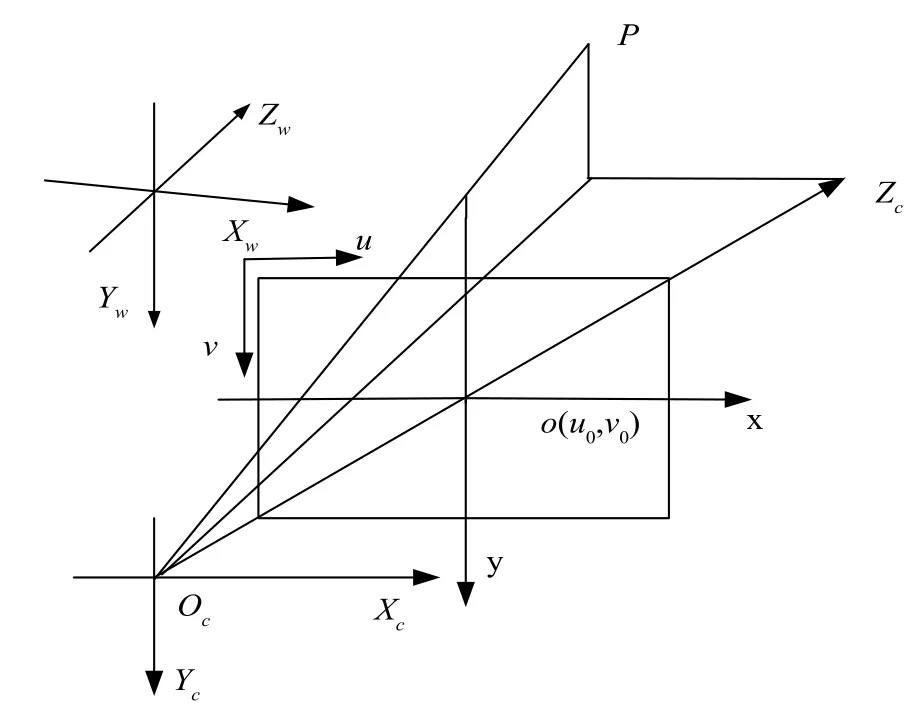
图4 相机成像模型
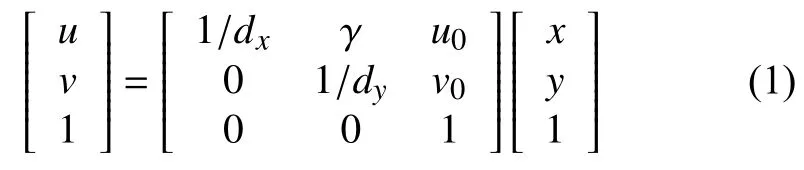
其中,dx,dy为单位像素的物理长度.相机坐标与图像坐标的对应关系为:
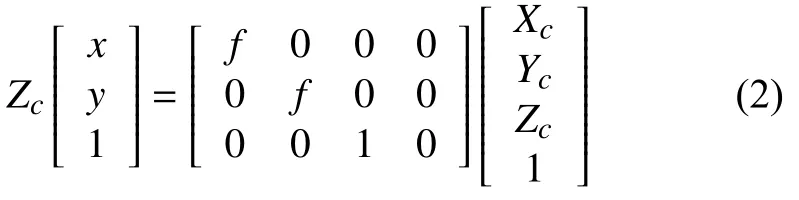
世界坐标系与相机坐标系的对应关系为:
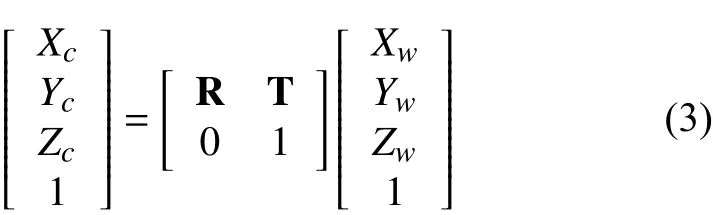
综合公式(1)(2)(3)可得图像坐标系(像素表示法)与世界坐标系的关系公式如下:
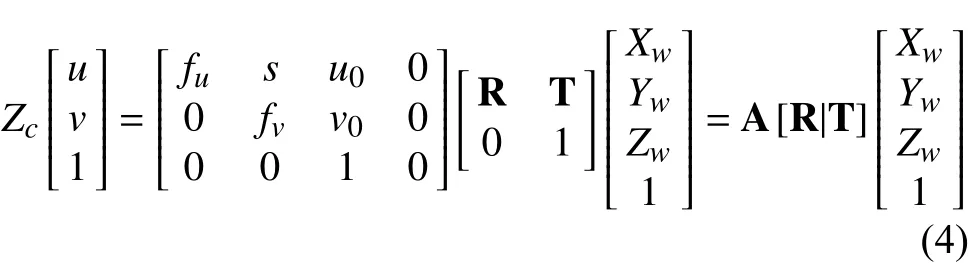
在公式(4)中(Xw,Yw,Zw)为自定义的世界坐标系,(u,v)为图像坐标系.A为相机的内参矩阵,R,T为旋转和平移矩阵,即外参矩阵.
本文自定义世界坐标,用Matlab工具箱中棋盘格标定法来求得两个相机的内参数矩阵A1,A2、以及两个相机的畸变系数k1;k2,由相机的内参矩阵和畸变系数可以得到无畸变的图片,根据求得的无畸变图以及对应自定义的世界坐标中的10组对应点,根据公式(5)可求出世界坐标与相机坐标的单映矩阵H.
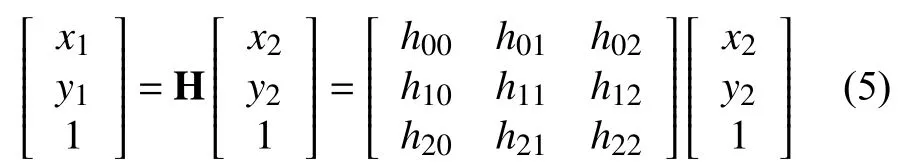
再由地平面与图像平面之间的单应关系可以求得相机坐标系和世界坐标系之间的旋转矩阵R和平移矩阵T.设H=[h1,h2,h3],在已知内参数矩阵的情况下容易通过下面的公式(6)解得两个相机的外参数RT1和RT2.
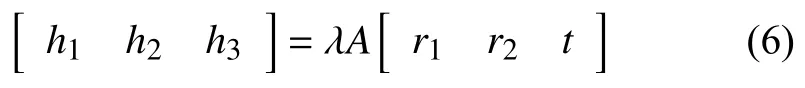
为获取目标在世界坐标中的位置信息,需由两个摄像机对目标进行定位.摄像机参数见表1.
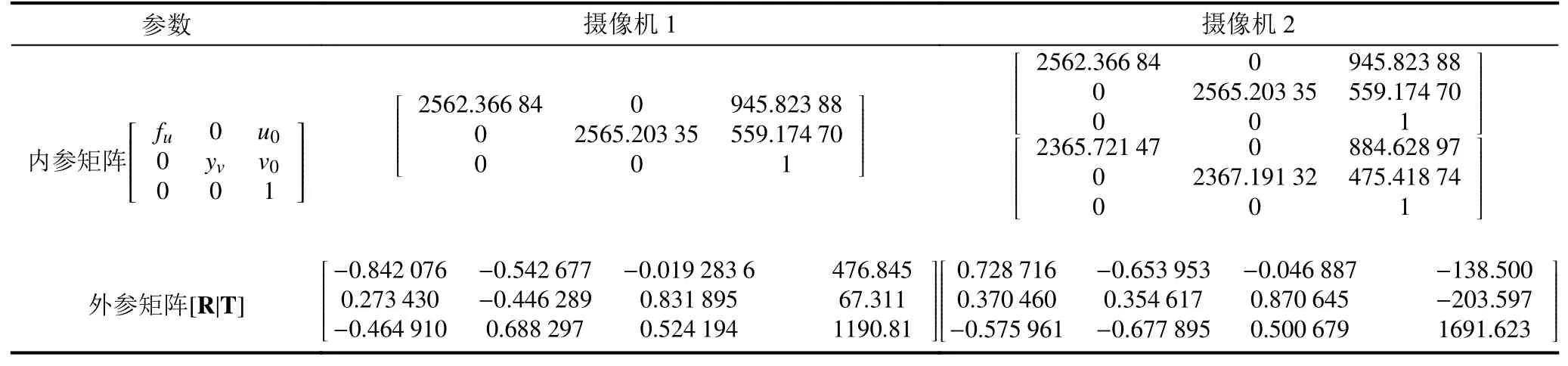
表1 相机参数表
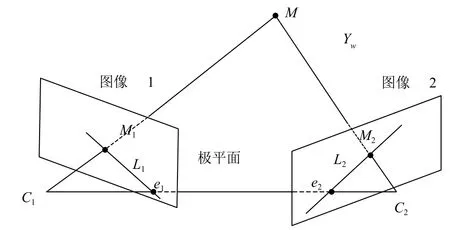
图5 双目相机极线几何约束模型图
根据如图5所示的约束模型,设两个摄像机的投影矩阵为P1,P2:
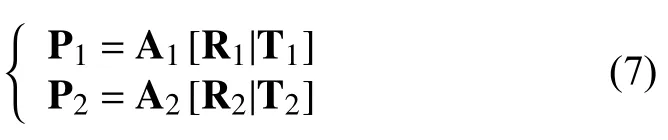
点m为 自定义坐标下的点,点m1和点m2为点m在两个相机中的投{影点,两个投影线和基线C1C2形成了一个三角形,则s1m1=p1m,因此利用三角形定位原理s2m2=p2m计算空间坐标点m.
3 实验
本文采集相机为Dahua DH-IPC-HF8431E,图像分辨率为1920×1080,训练和检测的电脑硬件配置为:CPU:Intel Core i7-6850K CPU @ 3.60 GHz;GPU:NVIDIA GeForce GTX 1080 Ti,11 G×2.
3.1 数据集制作
本文是针对特定场景设计的一套运动目标检测与定位系统.以一个10 m×10 m的室内场景中运动的人体为检测目标,每一个运动目标佩戴一顶不同的帽子作为视觉标定物,通过4路相机采集不同视角的图片数据作为样本集,然后通过人工对采集的数据进行标注.本文对于10个目标的场景的数据集包括:Images:752 张/JPG,Labels:752 个/XML,BoundingBoxes:7520个/Rectangles.训练集有632张图片,测试集有120张图片,比例大概为5:1.验证集分为两个场景,每个场景中都有10个运动目标,共956张图片.
3.2 模型训练
训练时采用VGG16作为本次实验的基础网络,并将最后的fc8层和所有dropout[20]层去掉,将fc6和fc7转化为卷积层[13],将pool5的2x2-s2改为3x3-s1,并使用atrous算法填洞.使用GSD对网络进行微调,设置初始学习率为0.000 25,采用 multistep的方法对学习率进行改变,gamma设置为0.1,即当迭代到30 000,40 000,50 000次时,学习率改为原来的0.1倍.Momentum为0.9,weight_decay为0.0005,batch_size为32,总共训练60 000次,总共训练时间约为60个小时,最后两次训练得出的精度分别达到96.2%和92.4%.利用训练好的模型(.caffemodel文件)就可以对图片视频进行检测.使用网络中的conv4_3,fc7,conv6_2,conv7_2,conv8_2 和 conv9_2总共 6 个不同尺度的特征图上进行预测置信度和位置.
通过2.3节方法求得相机的内参A和参矩阵H,并利用两路网络摄像机的目标检测结果进行定位.
4 结果与分析
从图6中的网络训练精度与损失函数中可以看到当训练迭代到3万次的时候,损失函数基本保持不变,检测精度也在3万次以后趋于稳定,在95%左右.利用训练好的模型对视频的每一帧进行检测.实验统计检测识别结果如表2.
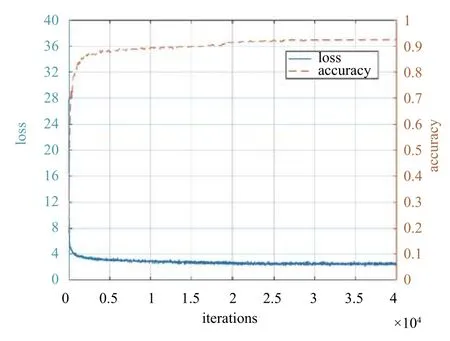
图6 网络训练精度与损失函数图

表2 目标识别结果(σ=0.2)
表中的σ为置信度,表示每个目标在检测网络中默认框与真实目标框的IOU大于0.45时默认框数量的多少.当σ=0.6时,每个目标的漏检率相对较高,当σ=0.2时,误检率都有明显的下降.如表3,为两个场景视频中随机抽取一帧的检测情况,场景1中,σ=0.6时,检测到3个目标,σ=0.2时,检测到9个目标;在场景2中σ=0.6时,检测到5个目标,当σ=0.2时,检测到所有目标.

表3 不同σ检测结果图
通过上面的两次测试结果可知当σ=0.2时,检测效果最好,因此将σ设0.2,利用训练好的模型对视频中的目标场景进行检测和定位,随机选取12帧定位结果进行分析,定位结果如表4.
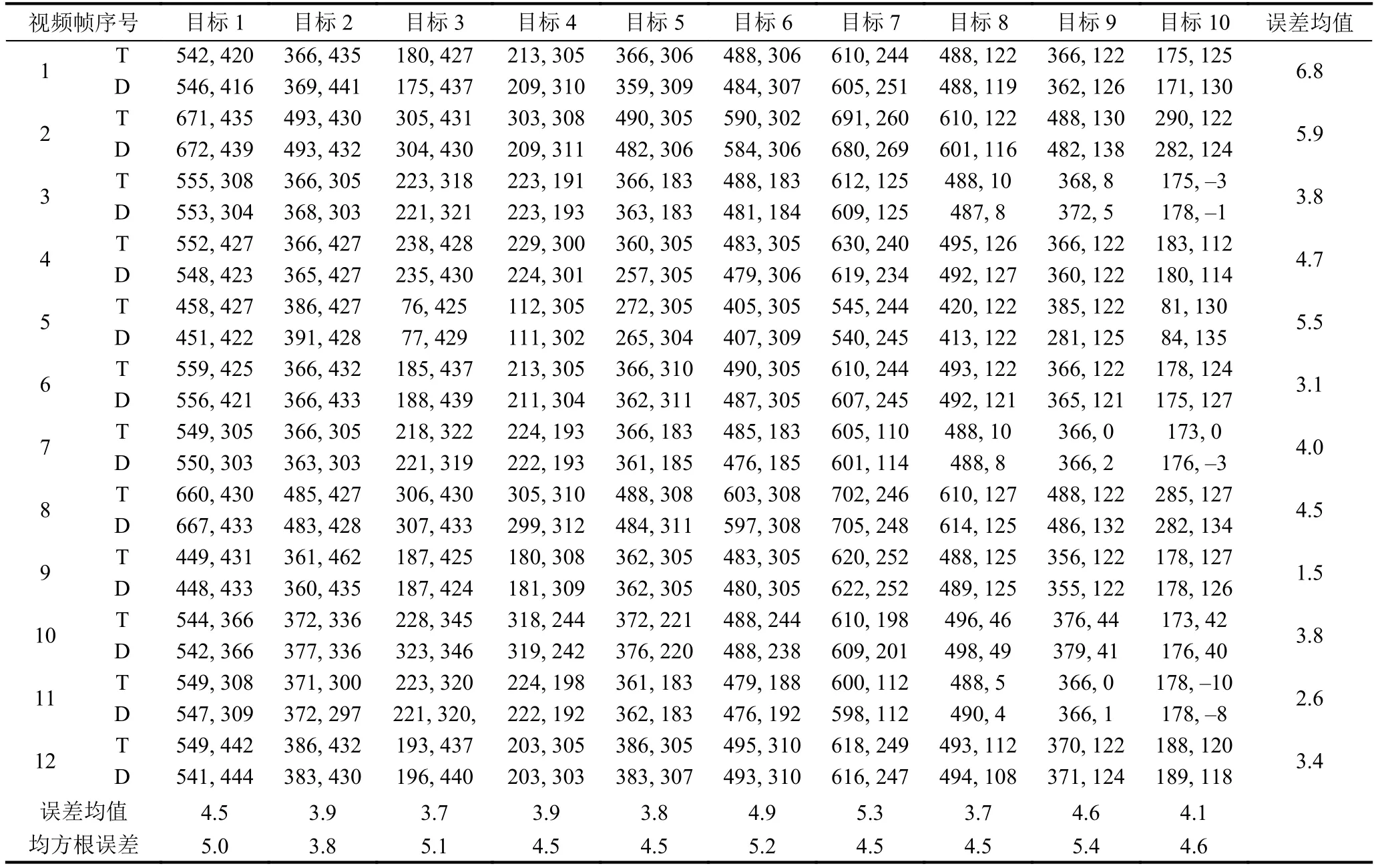
表4 目标定位误差(单位:cm)
表4中T表示真实目标的坐标,D标表示检测定位的坐标.从检测定位结果表中可以观察得出给个每个定位目标的平均定位误差在6 cm以内,每帧检测的所有目标的平均定位误差也在6 cm以内,12帧图片的所有检测目标的平均定位误差为4.17 cm,均方跟误差在4.5左右,检测速度可以达到40 fps以上,完全可以实现实时检测的效果.需要说明一点,本文处理的图片大小为1920×1080像素,处理图片的分辨率一般较大,因此分辨率较大的图片进行处理实现40 fps左右是一个相当有参考价值的方法.

图7 目标检测定位图
5 总结
本文利用深度学习框架,采用SSD目标检测方法和双目视觉定位,实现人体运动目标实时检测和定位.文中采用的SSD模型检测方法与其他的利用神经网络的检测方法相比,省去了区域预测和特征重采样的过程,因此检测速度大大增加.本文提供的定位方法平均误差在6 cm以内,具有较高的精度,且检测速度可以达到40 fps以上.
本文的运动目标检测与定位方法对于固定场景检测定位效果较为理想,而针对小目标的场景,以及运动目标遮挡比较严重的情况下,会出现某个相机漏检和误检的情况,可以通过以下两种方法进一步研究:
1)通过增加多路摄像机,两两配对,增加融合机制,提高检测结果;
2)目前使用的是VGG16作为基础网络,随着计算机性能的提升,可以使用更深层次的网络,例如ResNet、GoogleNet等作为基础网络或者从新设计网络结构来提高检测效果.
