A Distributed Intrusion Detection Model via Nondestructive Partitioning and Balanced Allocation for Big Data
2018-08-15XiaonianWuChuyunZhangRunlianZhangYujueWangandJinhuaCui
Xiaonian Wu , Chuyun Zhang, Runlian Zhang, Yujue Wang and Jinhua Cui
Abstract: There are two key issues in distributed intrusion detection system, that is,maintaining load balance of system and protecting data integrity. To address these issues,this paper proposes a new distributed intrusion detection model for big data based on nondestructive partitioning and balanced allocation. A data allocation strategy based on capacity and workload is introduced to achieve local load balance, and a dynamic load adjustment strategy is adopted to maintain global load balance of cluster. Moreover, data integrity is protected by using session reassemble and session partitioning. The simulation results show that the new model enjoys favorable advantages such as good load balance, higher detection rate and detection efficiency.
Keywords: Distributed intrusion detection, data allocation, load balancing, data integrity,big data.
1 Introduction
Intrusion detection system (IDS) is an important tool in protecting network security[Denning (1987)]. With the fast development of network technology, big data age arrived[Gupta and George (2016)], which brings many challenges to traditional IDS. Due to the huge volume of data and potential attacks in big data, it is rather difficult to provide effective security support for traditional IDS. In fact, traditional IDS has many disadvantages such as delaying response, reducing detection rate, thus it cannot effectively complete the detection work in big data environment. To solve these issues,distributed instruction detection system (DIDS) was introduced [Konstantinos, Ioannis and Spiros (2006); Genge, Haller and Kiss (2016)]. Although many DIDS schemes have proposed with different approaches, they have many shortcomings and need to be improved. For instance, data integrity may be destroyed when data is inappropriately partitioned, and the imbalance of data allocation may affect performance. Therefore, it is an urgent task to improve the efficiency and detection rate of IDS.
The challenge work in current IDS is to improve data processing speed so that it can successfully match the speed of network transmission and processing for massive data. In this case, the key point is to look for some appropriate data partition algorithms to partition data, and efficiently process data. Kruegel et al. [Kruegel, Valeur, Vigna et al.(2002)] used a slicing mechanism to process data in a parallel mode. Later, Charitakis et al. [Charitakis, Anagnostakis and Markatos (2003)] introduced an active traffic splitter based on hash algorithm. In 2005, an algorithm is presented by the idea of priority to partition and distribute the data to the lightest load node [Jiang, Song and Dai (2005)].Also, a hash mechanism is used to distribute network traffic load [Schaelicke, Wheeler and Freeland (2005)]. Recently, a distributed outlier detection algorithm for computing outliers is proposed [Wang, Shen and Mei (2016)]. Notice that data integrity in above methods could be destroyed when the traffic is inappropriately divided into subsets.Moreover, to ensure data integrity, a partition algorithm [Lai, Cai and Huang (2004)] is introduced to divide traffic into small slices by address, port and attack types. Furthermore,Liu et al. [Liu, Xin, Gang et al. (2008)] investigated the issue using the independent neural network. Recently, Cheng introduced an abnormal network flow feature sequence prediction approach to detect DDoS attacks in big data environment. However, the problem is still not well solved.
On the other hand, data partitioning has been widely used in parallel computing and data processing in various fields, to raise throughput and provide load balancing [Soklic(2002); Rosas, Sikora and Jorba (2014); Wang, Chen, Li et al. (2016)]. Although the throughput of system is increased by data partition and load policy, there still exists a bottleneck in IDS system.
In this paper, a new distributed intrusion detection model is proposed based on nondestructive partitioning and balanced allocation for big data (DIDS-NPBA).Specifically, a data allocation approach is introduced based on capacity and load to achieve local load balance, a dynamic load adjustment strategy is adopted to maintain global load balance of cluster and data integrity is protected by reassembling TCP session and session allocation policy.
The rest of this paper is organized as follows. A brief introduction and overview of DIDS-NPBA model are given in Section 2. The process about session assembly and data classification are described in Session 3. Section 4 presents a data allocation approach and a nondestructive data partitioning algorithm. The experimental results of the proposed model are shown in Section 5. Finally, the conclusions and future work are discussed in Section 6.
2 DIDS-NPBA system model
In high-speed network, massive amount of data makes traditional IDS difficult to detect attacks. Hadoop is an open-source framework and is used for large scale data processing.In this paper, our DIDS-NPBA is built on Hadoop to detect big data. As shown in Fig. 1,DIDS-NPBA consists of data acquisition, control center, data storage and data detection,where control center contains system monitoring, task scheduler and alarm response.According to Hadoop framework, control center acts as the master node, whereas other components play as slave nodes and communicate with MapReduce, which will be described in Section 5.1.

Figure 1: The DIDS-NPBA model
The mechanism of DIDS-NPBA is as follows. In Fig. 1, data acquisition is to collect network packets using many independent sensors. Packets are reassembled and classified in sensors. The data storage nodes receive and store data from sensors and submit summarizing information to control center.
System monitoring module monitors the state of detection nodes, including utilization ratio of node CPU/RAM/hard disk, and network bandwidth. Then the information is sent to task scheduler. According to the information and a data allocation strategy based on capacity and load (DAS-CL), task scheduler partitions and allocates data to detection nodes. Alarm response module receives and displays alarms coming from detection nodes.Data detection module is used to detect and analyze data, which consists of many distributed data detection nodes in parallel. Each detection node reads the allocated data files from the corresponding data storage node, analyses and detects data, and sends alarms to control center.
3 The work of data assembly and classification detection
The TCP session assembly is to assemble and restore session from the interrelated network packets. A TCP link is determined uniquely by a tuple
4 Data allocation strategy and data partition algorithm
4.1 Capacity evaluation for detection nodes
The capacity of nodes is determined by many performance indexes, which can be collected by the system monitoring module. Assume the evaluation indexes for node capacity mainly include node CPU, memory and network bandwidth, since the work focuses on computation and data transmission. We only evaluate the detection nodes which are used to detect data. Let CAP(i) represent the capacity of node i, which is defined as follows:

where CPUiis the product of CPU number and CPU frequency of node i, Miis the memory capacity, Niis network bandwidth, and a1, a2, a3are the weighting factors on node capacity with a1+a2+a3=1.
To evaluate the diversity of memory among heterogeneous nodes, Miis computed by memory size, frequency and CAS latency (CL) of memory, where these parameters are normalized by using Min-max linear function conversion method. The computation of Miavoids the influence from the discrete value of different indexes. Similarly, CPUi, Niin formula (1) are normalized with the same linear method.
The heterogeneity of detection node capacity makes it difficult to control the data granularity allocated to each node when big data is split. If all nodes are assigned datasets with the same size, the nodes with weak capacity would be bottleneck. Here, we introduce a concept about node capacity factor (CF) to measure the capacity relationship of nodes as follows.
Definition 1. CF is mainly used to measure or weigh capacity ratio of a node in cluster.Assume there are n nodes in a cluster, CAP(i) is the capacity of node i, and node j (1≤j≤n)has the lowest capacity CAP(j) in all nodes. The CF of node i can be computed as follows:
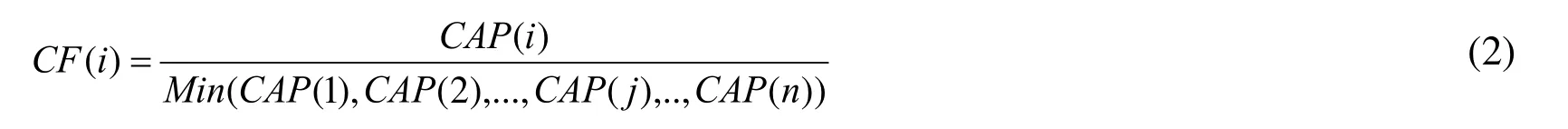
The node with the lowest capacity is used as a benchmark to measure or weigh other node in cluster. Moreover, CF reflects the ratio among nodes in cluster, which can be helped to calculate the weight for data allocation.
4.2 Load evaluation for detection nodes
The load of nodes is another important factor affecting the data processing efficiency. The heavier load of a node, the more time is needed for data detection. In order to evaluate node load, the utilization of CPU, memory and network bandwidth of nodes are collected by the system monitoring module in real time. Suppose L(i) is the load of node i at a certain moment, we define:

where U(CPUi), U(Mi), U(Ni) are the CPU, memory and network bandwidth utilization of node i, and b1, b2, b3are the weight factors satisfying b1+b2+b3=1.
If the load of some node is changed, then the data granularity allocated to this node should be changed accordingly. For instance, the overload nodes will no longer be assigned data. Here, we give another definition about the load factor (LF) to estimate the load degree of heterogeneous nodes.
Definition 2. LF is mainly used to measure the degree of node load. Suppose the lightload threshold of a node is α and its overload threshold is β. The LF of node i can be computed as follows:

where LF is a piecewise function such that its value changes along with the node load.Thus, LF is the other key factor to evaluate data allocation.
4.3 Data allocation strategy in a node group
In the proposed DAS-CL, the contribution of each node is quantified in a node group.Assuming there are m nodes in node group k, and the total GDBkdata are submitted to node group k. The weight factor R(i) of node i in group k can be computed as follows:

From Eq. (5), the stronger capacity and the lighter load of node i, it has the greater weight or contribution in node group k.

Suppose D(i) is the assigned data size to node i from GDBk, which can be computed as follows:According to formula (6), each node will be allocated a data set conforming to its capacity and load. Thus, the resource utilization is raised and the bottleneck can be avoided, which means that a better local load balance can be achieved in node group.
4.4 Data partition
In the process of data partition, files allocated to node i may be roughly D(i), but does not equal to D(i), since the size of each file is uncertain. If a file is split out to meet D(i), the data integrity would be undermined. Thus, each file would not be permitted to be split out,as discussed in Section 3.
An approximate allocation way is used to partition data. A fluctuation range closed to D(i)is set to 5 MB, it has little influence on node load when compared with the massive data.Then a file or many files from GDBkwith size closed to D(i) will be allocated to node i,and the file information including the address of data storage node (i.e. the real location of storing data file), file directory and file name, etc. will be sent to node i by the task scheduler. Node i will read the assigned data files from the data storage node, detect the data, and send alarms to the alarm node.
4.5 Dynamic adjustment for load balancing among node groups
The data produced by the Internet applications is varying with time. For instance, during some period, an application may be used frequently, thus the produced data would be increased, whereas other data may be reduced. This changing could be able to affect the load of node groups, even cause load imbalance among node groups. Therefore, we present a dynamic load adjustment method among node groups to maintain global balance in the cluster.
We need to evaluate the load of different node groups. In each node group, each node may have different capacity and load. We introduce a new concept regarding the load of node group (GL) to smooth the differences.
Definition 3. GL is used to measure the average load of all nodes in a node group, which can be computed by the load and capacity of nodes. Suppose there are m nodes in node group k, the load GL(k) of node group k is defined as follows:

The load dynamic adjustment method among node groups is as follows:
Step 1. Compute GL of each node group. The light-load threshold of node group is α' and its overload threshold is β’. All the overload node groups are lined in an overload queue,and all the light-load node groups are lined in a light-load queue.
Step 2. The task scheduler counts up the classified data coming from data storage nodes,and assigns each dataset to a node group by protocols.
Step 3. Set a light dataset threshold δ, which is considered to have less impact on the load of node group even if the node group is overload. Assuming a node group is assigned data of size GDB, if GDB≤δ, then it will be removed from the overload queue.
Step 4. Suppose two queues are all not empty. From the first node group A in the lightload queue, node i is searched, who has completed detection tasks and has lighter load,and its CAP(i) is not the largest in the group. Node i is migrated to the first node group B in the overload queue, and the feature rules of IDS in the migrated node i are changed conforming to the new node group. Then, node groups A and B are removed from two queues, respectively.
Step 5. If the light-load queue is empty and the overload queue is not empty, then the assigned data of all node groups in the overload queue are split out such that half data will be processed in the current round and the remaining will be processed in the next round. Then all node groups are removed from the overload queue.
5 Experimental result analysis
5.1 Experiment environment
Based on Hadoop, a prototype of DIDS-NPBA model is implemented with Java. Nodes running above function are deployed in campus network. For instance, sensors are distributed in different subnet and near switches. The system monitor unit uses open source tool Sigar to collect run-time information of each detection node. DAS-CL strategy and data partitioning are implemented and embedded in task scheduler in control center. The alarm response unit is used to count alarm results. In order to ensure the consistency and validity of data detection, all detection nodes equip with Snort system after detection nodes are grouped, feature rules in each detection node are configured to conform to protocols of its node group. In Hadoop cluster, control center plays as a Master node, which communicates with the slave nodes including data storage nodes and detection nodes using MapReduce.
In this section, we test the DIDS-NPBA model in the above environment in terms of load balancing, detection time and detection rate, and compare with two data allocation methods, that is, consistency hash algorithm [Karger, Lehman, Leighton et al. (1997)]and Rosas algorithm [Rosas, Sikora and Jorba (2014)].
The parameters in DIDS-NPBA model are set as follows:
(1) In formula (1) and (3), the computing power plays a major role in data detection, thus a1, b1are set to 0.6, a2, b2are set to 0.3, and a3, b3are 0.1.
(2) In formula (4), according to the empirical data, the rated output of nodes is about 0.7~0.8, and referring to the experimental data of node load, α and β are set to 0.23 and 0.77, respectively.
(3) In Section 4.4, α' and β' are set to 0.3 and 0.7, respectively, which are different from α and β, since the average load of a node group can be impacted by more factors. And δ is set to 200 MB.
(4) The detection nodes count up to 20 heterogeneous nodes, whose capacities are computed as in Tab. 1.
5.2 Data preprocessing and grouping for detection nodes
We use DARPA2000 data set to conduct testing in this paper. Since the DARPA2000 data set is small, the data in inside, outside and DMZ environments from different dates are extended to 3 GB to simulate data acquisition in high-speed network. The extended 3 GB data set is reassembled and processed in sensors, and each session is stored in a file named after its hash value.
Through analyzing the above 3 GB data set, the total number of attacks is 15659.Moreover, the data components are as follows: The http protocol data is 1782 MB, the ftp data is 233 MB, and the telnet data is 522 MB. The rest 463 MB data are classified as
mixed data. Thus, the total data set is divided into four categories, that is, HTTP, FTP,TELNET, and mixed data.
Accordingly, detection nodes are also divided into four node groups. The feature rules of Snort in each node are configured according to its group, except the mixed node group is with all original feature rules of Snort.
Initially, detection nodes are grouped as follows. HTTP node group is assigned 10 nodes(S1~S10), FTP node group has 2 nodes (S11~S12), TELNET node group has 4 nodes(S13~S16), and the mixed node group contains the resting 4 nodes (S17~S20). The capacity of nodes is shown in Tab. 1.
5.3 Validity test and analysis for the DIDS-NPBA model
In this section, the load balancing, detection time and detection rate of DIDS-NPBA model are investigated. The results are compared with that of consistency hash [Karger,Lehman, Leighton et al. (1997)] and Rosas et al. [Rosas, Sikora and Jorba (2014)]algorithm, which are listed in Tab. 1.

Table 1: The results of data allocation and detection with different methods
In Tab. 1, nodes are listed by grouping in turn, and each group has different background color. CAP represents node capacity, L is node load, CF is the node capacity factor, Data size is the partitioned and assigned data to each node, Detection time is the time spent by each node to detect the assigned data, and Alarm number is the attack number detected by each node.
(1) Result analysis for load balancing experiments
In parallel computing, the data assigned to each node in cluster should be proportionate to node performance [Soklic (2002)] to maximize resource utilization.
In Tab. 1, it can be seen that the difference of capacity (CAP) among nodes is great,whereas the load (L) among nodes are close. This can be evaluated by the standard deviation (SD). SD of CAP and L of 20 nodes are 335 and 0.076, respectively. In Tab. 1,SD of the data assigned to each node group by DIDS-NPBA, hash and Rosas, are computed. For HTTP, FTP, TELNET and mixed node group, there are 29.2, 30.4, 31,23.4 in DIDS-NPBA, 6.3, 9.2, 9.9, 8.4 in hash, and 31.6, 20.5, 27.9, 24.9 in Rosas.
The above results show that, the capacity difference of nodes is great, whereas the difference of the data assigned to each node is small in consistency hash, which means that a node with weak capacity has to deal with the same data set like a strong node. In fact, the consistency hash partitions data without considering node capacity and load.Rosas algorithm adjusts the allocated data amount dynamically by the computing time that the node dealt with the allocated data, which matches the performance of nodes. For DIDS-NPBA, it can be seen that the data assigned to each node is proportionate to its capacity and load, which improves resource utilization and throughput of system, and the load balance of cluster system can also be maintained well.
(2) Analysis of experimental results for detection time
In Tab. 1, SD of detection time for DIDS-NPBA, Hash and Rosas, are 0.72, 1.19, 0.75,respectively. The results show that the difference of detection time spent by each node in DIDS-NPBA is smallest and its parallelism is the best. Consistency hash requires the longest detection time (12.3 s) for a single detection node due to imbalance data allocation, thus the parallelism is worst. Due to the balanced data allocation, the parallelism of Rosas is roughly the same to DIDS-NPBA. Note that the sum of detection time spent in DIDS-NPBA is the least, which shows that the system performance is improved.
(3) Analysis of experimental results for detection rate
DR is defined as the ratio between number D of the detected intrusion behaviors and number T of all intrusion behaviors, that is, DR=D/T.
It is shown in Tab. 1, DR of the hash is the lowest, i.e. 89%, which mainly lies in that the data integrity is damaged heavily when data is partitioned by mapping relationship between packets and virtual nodes. DR of the Rosas and DIDS-NPBA are near to 99%,because the data integrity is protected by TCP session assembly and balanced data allocation. Moreover, the original data that have not to be assembled based on TCP session, DR of the Rosas and DIDS-NPBA are near to 93%.
5.4 Experimental test for the dynamic load balancing adjustment among node groups
To evaluate the efficiency of our proposed algorithms, we construct experiments on five datasets, where each date set is about 3 GB as in Section 5.2. The components of five data sets are as follows: The first data set is same as that used in Section 5.2, and other four data sets are http data of 1382 MB, ftp data of 633 MB, telnet data of 522 MB, and the mixed data of 522 MB, respectively, with the total alarm 15590.
In the experiments, the 3 GB data set is allocated and detected by 20 nodes in parallel based on the DIDS-NPBA model, and the average detection time is about 10 seconds.Thus, the processing of a data set including partition, allocation and detect data is 10 seconds. Note that 20 detection nodes are still used, and the initial group and experimental results for the first data set are shown in Tab. 1. The experimental results for the other four data sets are summarized in Tab. 2, where the titles, L, Data, Time and Alarm, have same meaning as in Tab. 1.Compared the second data set with the first one, it is easy to see that http data are decreased, whereas ftp data are increased. After the second data set has been split and allocated, the nodes in ftp node group were assigned with more data than the first time.As shown in Tab. 2, node S12 is overloaded at 0.87, and ftp node group is also overloaded at 0.79. However, the load of nodes in http node group is decreased, and the http node group has light load at 0.26. According to the dynamic load adjustment strategy,node S2 in http node group is migrated to ftp node group. Then, in ftp node group, node

Table 2: The experimental results of the dynamic load balancing adjustment strategy
S2 and S11 are assigned data for the third and fourth data sets, but node S12 is ignored since it has been overloaded. When the fifth data set is processed, node S12 is monitored.It is assigned data according to its capacity and load, in this way to return to normal. And the load of all nodes is also monitored after the fifth data set has been processed as shown at the most right column in Tab. 2.
With network data sharply changes, some problems would inevitably occur for IDS, such as the imbalance of system load, and the system performance and detection rate are degraded. The global load imbalance due to the sharp change of data component can be overcome in time following the dynamic load adjustment strategy, and the data processing efficiency, load balance and detection rate of the system are relatively stable during the process of continuous operation.
6 Conclusion
In view of the issue that data processing speed of existing IDS cannot match the speed of network transmission and processing for massive data, a novel distributed intrusion detection model DIDS-NPBA is proposed. More precisely, feature rules are decreased by classification detection method. The data integrity can be protected by session reassembly and nondestructive partitioning based on session files. Furthermore, the load balance of system is achieved by the dynamic load adjustment strategy and DAS-CL strategy. The simulation results demonstrate that our model has favorable advantages in providing better load balance, reducing detection time, and raising detection rate and throughput.
Acknowledgement:This article is supported in part by Guangxi Key Laboratory of Trusted Software of China (No. kx201622), Guangxi Key Laboratory of Cryptography and Information Security of China (No. GCIS201623, GCIS201705), Guangxi Key Lab of Wireless Wideband Communication and Signal Processing of China (No.GXKL061510, GXKL0614110), Guangxi Colleges and Universities Key Laboratory of cloud computing and complex systems of China (No. YF16205), and Innovation Project of Guangxi Graduate Education (No. YCSW2018138, 2017YJCX26).
杂志排行

Computers Materials&Continua的其它文章
- Efficient Secure Data Provenance Scheme in Multimedia Outsourcing and Sharing
- An Advanced Quantum-Resistant Signature Scheme for Cloud Based on Eisenstein Ring
- acSB: Anti-Collision Selective-Based Broadcast Protocol in CRAdHocs
- A Novel Quantum Stegonagraphy Based on Brown States
- A Distributed LRTCO Algorithm in Large-Scale DVE Multimedia Systems
- Weighted Sparse Image Classification Based on Low Rank Representation