基于词向量特征扩展的中文短文本分类研究
2018-08-15刘旭敏徐维祥
雷 朔 刘旭敏 徐维祥
1(首都师范大学信息工程学院 北京 100048)2(北京交通大学交通运输学院 北京 100044)
0 引 言
随着大数据时代的到来以及移动终端的广泛应用,人们可以随时随地通过智能终端来获取和发布信息。与此同时,数据结构也发生了数量上的改变,数据由传统的结构化数据转变成了非结构化数据,文本逐渐成为了互联网信息交流和传播的载体。随着社交平台的发展,例如微博、Twitter等,短文本数据也成为了文本数据的主要表现形式[1-2]。短文本数据通常是指文本长度在160字以内,文本长度较短,特征较为稀疏,未登录词较多,语句随意,是噪声较多的文本数据。由于这些短文本数据代表了大众的观点,对短文本数据的挖掘可以更多的获知用户的态度,行为趋势等信息,也逐渐成为了国内外研究学者的热点。但由于其特征较少,文字长度较短等缺点,不能够将其当成普通的长文本数据进行相关的数据挖掘,所以有必要提出相应的算法来对短文本数据进行分类。
针对短文本特征稀疏的特点,YANG等[3]用引入外部文档来进行特征的扩充,通过外部文档的引入,将更多的特征信息加入到短文本中,达到特征扩展作用。Li等[4]提出了基于领域词扩展,达到了不错的效果。Fan[5]也提出了一种有效的基于外部文档进行特征扩展的方法。范云杰等[6]提出了基于维基百科的中文短文本分类,利用维基百科的信息来扩充短文本,使得其类似于长文本,进而用长文本的分类方法进行分类,达到分类的效果。还有将百度百科作为微博特征扩展的方式,其原理和基于维基百科的原理类似。王东等[7]提出的基于同义词词林的特征扩展,还有基于知网,wordnet来进行文本特征扩展。但由于基于外部语料库的特征扩展并不能很好地发现文档内部语义特征,并且其对特定的语料数据集效果并不是很好,由于外部语料库形式的不确定性,容易加入噪声等信息。
在基于内部语义的短文本特征扩展中,张志飞等[8]提出的基于LDA主题模型,胡勇军等[9]基于LDA高频词扩展的中文短文本分类研究,通过文档词频的统计,概率模型的求解,得出主题词分布,通过设定阈值,将主题词概率大于该阈值的特征加入到短文本中,达到文本特征扩展的目的。Enríquez[10]提出了用词向量进行意见文本方面的分类。江大鹏等[11]提出了加权连续词袋模型,并结合LDA,提出了主题分布的词向量生成算法,并将词向量应用于短文本分类取得了较好的效果。Zhang等[12]将隐含主题和词汇同时作为词向量进行学习。但是基于内部语义的短文本特征扩展算法更多地依赖于数据本身,对于新型数据敏感性较差,容易出现过拟合现象。
本文算法不仅利用了外部语料库丰富的上下文信息,同时将词向量引入特征扩展,通过内部语义求取关键词信息,很好地解决了上述特征扩展算法的不足。
1 文本表示和词向量
1.1 词袋模型
词袋模型是最先提出的一种文本表示模型,也是能够容易直观理解的文本表示模型。词袋模型将文章中的词汇映射为一个一维向量,词汇向量两两正交,并占据向量中的唯一维度。向量的长度则为语料集中单词的总数。词袋模型的优点是容易理解,使用方便。缺点是缺少语义相关信息,维度较大,尤其是在数据量较大的时候,向量的长度能够达到万维甚至十万维,不易于建模。
1.2 向量空间模型
向量空间模型是基于统计规则的文本表示方法。与词袋模型类似,向量空间模型同样需要对词频信息做相应的统计,并计算每一个term中相应的权值,不同之处在于向量的维度可以根据需要自由设定,减少了相应的运算量。对于文本相似度的求解,向量空间模型表现出了很好的效果,但是对于词汇相似度的求解,向量空间模型却无能为力。
1.3 LDA主题模型
LDA主题模型是将文档集通过训练,表示成文档主题分布和主题词汇分布[13]。LDA主题模型是一种生成模型,首先是以一定的概率选择主题文档分布和主题词汇分布,在生成文档的过程中,从文档主题分布中以一定概率选择主题,得到主题,并根据主题从主题词汇分布中以一定概率选择词汇,加入到文档中,完成文本生成。但对于一个已经生成的文本来说,文档主题分布可以作为一种文本表示形式,可以根据EM算法来推测其隐含主题的概率。LDA主题模型是一种无监督的训练,在训练中可以自定义主题的个数,模型可用于文本生成和文本表示。但是LDA在文本表示方面不能充分表达语义信息,对于文本长度敏感性较大,不适用于短文本文本表示。
1.4 词向量
词向量的概念首先由Hiton在1986年提出,开创了词向量的先河[14]。词向量是通过文本语料的训练,将单词映射为一个高维的向量表示,进而将单词在高维空间中的距离来表示单词之间的相似度。由于词向量的维度可以自由设定,所以相比于词袋模型和向量空间模型来说,能够清晰地表示词汇间的语义信息以及单词之间的相似度信息。对于语句和文档来说,通过在词向量训练时加入句子、段落、文章等信息,可以更进一步地获取词语、句子相关信息。基于句型、段落、文章等向量方法也随之出现,比如代表语句的句向量(sentence2vec)和代表文章的文档向量(doc2vec)。
本质上来说,词向量只是语言模型的产物,是在求取自然语言模型的同时得到的词向量。对于给定的语料和未知的句子来说,希望通过构建判别模型来对未知句子进行‘是否是自然语句’的判别。对于原始语料的数据集,可以得到目标函数为:
(1)
式中:n表示文档的数量,m表示每篇文档单词的数量,p(wij|context_ij)表示在上下文信息为context_ij的情况下wij出现的概率,则对于是否是自然语言模型的判别,需要最大化上述目标函数,进而得到词向量。有两种模型可以获得词向量,一个是C-BOW模型,另一个是Skip-gram模型。如图1和图2所示。
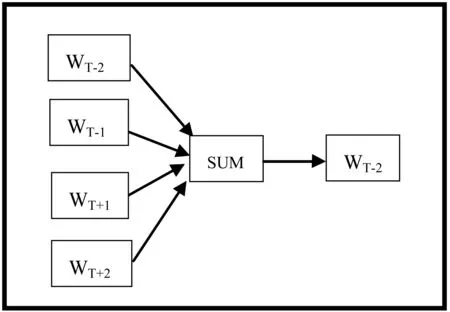
图1 CBOW模型
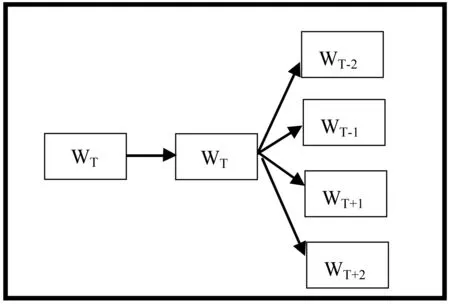
图2 Skip-gram模型
图1表示的是C-BOW模型,对于C-BOW模型来说,其输入节点则是上下文词集中的单词,中间节点是求和节点,输出节点是一棵二叉树,其中叶子节点的个数则是文档中的单词集合个数。通过遍历文档得到优化的词向量。其中,上下文词集的数量可以由一个指定范围的随机数来确定,对于给定的上下文词集,首先进行初始词向量的加和,得到加和向量,进而通过由加和节点到该单词的叶子节点的路径来进行词向量数值的优化。其中用于C-BOW的优化算法为SGD算法。
图2表示的是Skip-gram模型的求解图示,Skip-gram模型同样是由三层网络模型组成,但是Skip-gram的输入节点是当前节点,不同于C-BOW模型,在中间节点中Skip-gram不做任何操作,输出节点同样是由文档词集单词为叶子节点的二叉树。不同于C-BOW的训练,Skip-gram在每次训练中需要优化由输入节点到上下文每个单词的词向量信息,经过若干次迭代后得到词向量。
2 基于词向量的短文本分类过程
由于基于外部语料和内部语义进行特征扩展的算法各有优劣,所以本文结合两者的优点。首先获取维基百科外部语料集,对维基百科语料集进行词向量的训练,得到其词向量表示。同时,通过TF-IDF算法来得到数据集的关键词词集信息。将每篇文档中特征词相似度最高的前k个单词加入原文本,完成特征扩展。
2.1 框架分析
基于维基百科词向量的特征扩展算法第一步是要进行维基百科词向量的获取,通过Word2vec模型对维基百科词向量进行求取,得到维基百科词向量。第二步利用TFIDF算法进行文本关键词的求取。第三步通过算法将相应的特征加入到原短文本中,完成特征扩展。
2.2 维基百科词向量的获取
训练维基百科词向量,一般获取方式有两种。一种可以通过下载维基百科数据集进而通过对语料库进行训练进而获取其词向量,另一种可以直接通过已有的程序库来直接获取维基百科词向量,本文通过后一种方法来直接获取其词向量[15]。
本文维基百科词向量的获取是通过C-BOW模型来获得维基百科词向量集。对于维基百科数据集的每一篇文档的每一句话来说,首先进行分词,对于分好词的文档来说,可以将文档中每一个单词以及其上下文单词输入到模型中进行求解。
由式(1)中的目标函数可以进行如下变换:
l(θ)= -log(L(θ))=
(2)
式中:
p(wij|context_ij)=p(wij|cij)=
dkijlog(1-σ(qkij×Cij))]
(3)
即通过变换将目标函数转换为损失函数,其中,dkij表示到当前词路径的顺序,可以假定向左即为0,向右即为1。qkij代表当前内部节点的词向量。Cij表示该词上下文词向量之和。对于损失函数L(θ),可以利用随机梯度下降的优化方法来对每个词向量求得最优解。
如图3所示,例如在维基百科中对于‘中国’词的解释为‘中国是个爱好和平的国家’,通过分词以及去除停用词后可以得到‘中国 爱好 和平 国家’,根据维基百科词频统计可以得到原始的哈夫曼树,图3为简化的哈夫曼树,在实际应用中,哈夫曼树要比图3的树大很多。首先,初始化词向量,文本采用随机初始化的方式将单词集中所有词映射成维度为300,数值为[0,1]的随机初始化数值。其次,对于分词后的句子来说,依次选择句子中的单词和其上下文进行求解,假设当前词为wij=‘爱好’,其上下文单词为Cij=‘和平 中国 国家’词向量之和,从根节点到‘爱好’节点对应唯一的路径。如式(3)所示,dkij表示该路径向左还是向右,可以假定向左为0,向右为1。qkij与Cij的乘积表示上下文词向量之和与中间节点的向量积,从而得到最后的目标函数。
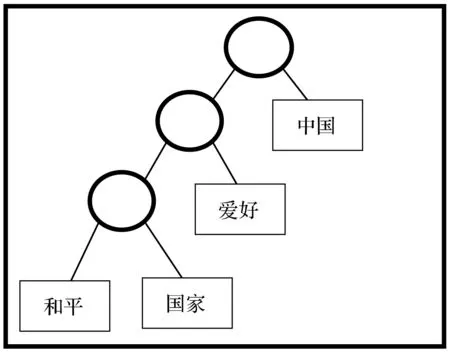
图3 词向量求解示例图
通过变化得到新的损失函数L(θ),可以用传统的随机梯度下降算法进行求解,由于未知变量为qkij与Cij,所以分别对其进行求导,通过迭代的方法得到最优解。
至此,可以得到维基百科数据集的词向量集合,对于任意一个单词来说,可以表示成[0.12,0.31,1.23,…]的形式,词向量的另一个解释为高维空间中的点,对于相同维数的词向量来说,可以利用欧式距离的计算方法求得单词之间的相似度。
2.3 文本预处理
文本预处理主要包括文本的分词处理,去停用词处理,以及无效的字符处理等[16]。分词处理是文本处理的基础,也是将文本由非结构化的数据转化为结构化数据的第一步,分词的优劣将直接影响到文本后续的处理。由于英文文本可直接通过空格符来直接将文本进行分词,以至于在分词处理的阶段中文分词也要比英文分词更加困难,这也是中文文本语义丰富性要多于英文文本的有效例证之一。正由于中文文本丰富的语义信息,例如未登录词、多义词、同义词等,分词的处理也一直成为了众多学者研究的重点之一。
去停用词是指去除分词后无效的特征信息,这些停用词不具有任何语义的信息,只起到连接,加强语气的作用,由于其存在的普遍性,并不能作为该文本的有效特征,所以将其去除并不会影响后续分类的处理。
2.4 关键词集的获取
传统的特征词获取算法有基于词频的关键词获取算法、基于TF-IDF的关键词获取算法。由于词频仅仅根据单词出现的频率来作为文本的关键词,并不能有效地代表类别信息,而TF-IDF则考虑了文本关键词的普遍特性,对于所有类别都出现较多的特征进行相应的惩罚,所以本文用TF-IDF来作为关键词的提取算法。
(4)
TFij称为文档频率,表示单词在文件中出现的频数与单词总数的比值,代表了这个单词在文本中出现的重要程度,值越大,则相应的重要性越大。
IDFij=|D|/|{I(ti∈dj)}|
(5)
IDFij称为逆文档频率,表示文档总数与包含该单词的文件数的比值,其与文档频率起到了约束的作用。
TFIDFij=TFij×IDFi
(6)
TFIDFij为TFij与IDFij的乘积,值越大表明单词的重要程度越高,代表性越好。
2.5 短文本特征扩展算法
首先通过TF-IDF算法来获取语料集的特征词集,并遍历语料集,对于存在于文档中的特征词,将特征词相似度最高的k个特征词加入到文档中,作为新的文档集合,具体算法步骤如下:
(1) 根据维基百科语料数据集获取维基百科单词的词向量集合。并根据欧式距离的计算方法得到每个单词相似性最大的前20个单词。
(2) 对原始短文本通过TFIDF算法求解关键词的集合keywords。
(3) 依次遍历每一篇文档,对文档中的单词进行如下判断:如果单词在keywords集合中,则将(1)中该单词相似性最大的前20个单词加入短文本,否则,跳过该单词。
(4) 得到特征扩展后的文本。
基于词向量的短文本特征扩展算法如图4所示。
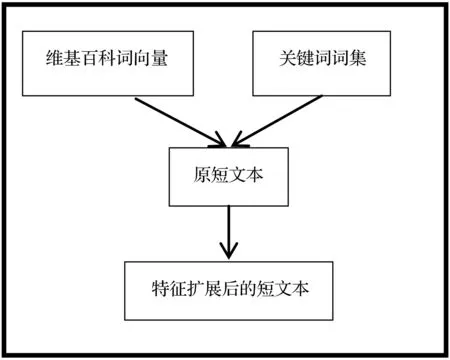
图4 算法流程图
如图4所示,首先需要构建维基百科词向量集,用C-BOW算法对维基百科语料库中的语料进行词向量的获取,同时得到每个单词相似性最大的前k个词。通过TF-IDF算法来获取文本中的关键词,将TF-IDF值较大的词汇作为关键词集的求取标准,通过设定相应的阈值,将大于某一阈值的特征词加入到关键词集。对于每一个文本,将文本中存在于关键词集的关键词特征扩展词集加入到原文本中,得到新得特征扩展的语料集。在本文中,可以直接利用单词词向量之和的结果作为文本表示。最后通过分类器来训练新的语料集并对未知短文本语料进行分类预测。
3 实验结果与分析
3.1 实验评估指标
常用的文本分类评估指标有3种,分别是精确度、召回率、F1值,分别表示如下:
精确度P:
(7)
召回率R:
(8)
F1值F1:
(9)
式中:a表示被正确分到正类的文档数,b表示错分到正类的文档数,c表示属于该类但被错分的文档数。
3.2 实验结果分析
本文实验处理器是Inter core i5-2450m,CPU为2.5 GHz,操作系统是Windows7 64位,编程语言为Python2.7。本实验所用到的短文本实验语料集为搜狗实验室数据集的标题短文本,搜狗实验室数据集是公开、免费的文本实验数据集,主要有标题、URL、类别标签、正文内容组成,数据内容和类别多样,既可以提取其中的长文本,用于语义分析等,也可以用于本文的短文本分类。由于实验语料数据类别数据样本不均衡,存在数据不完整的类别数据,所以从原始11大类别中抽取8大类别,并在这8类中随机抽取数量相当的文档数,对数据进行简单的预处理,每类文档数量如图5所示。
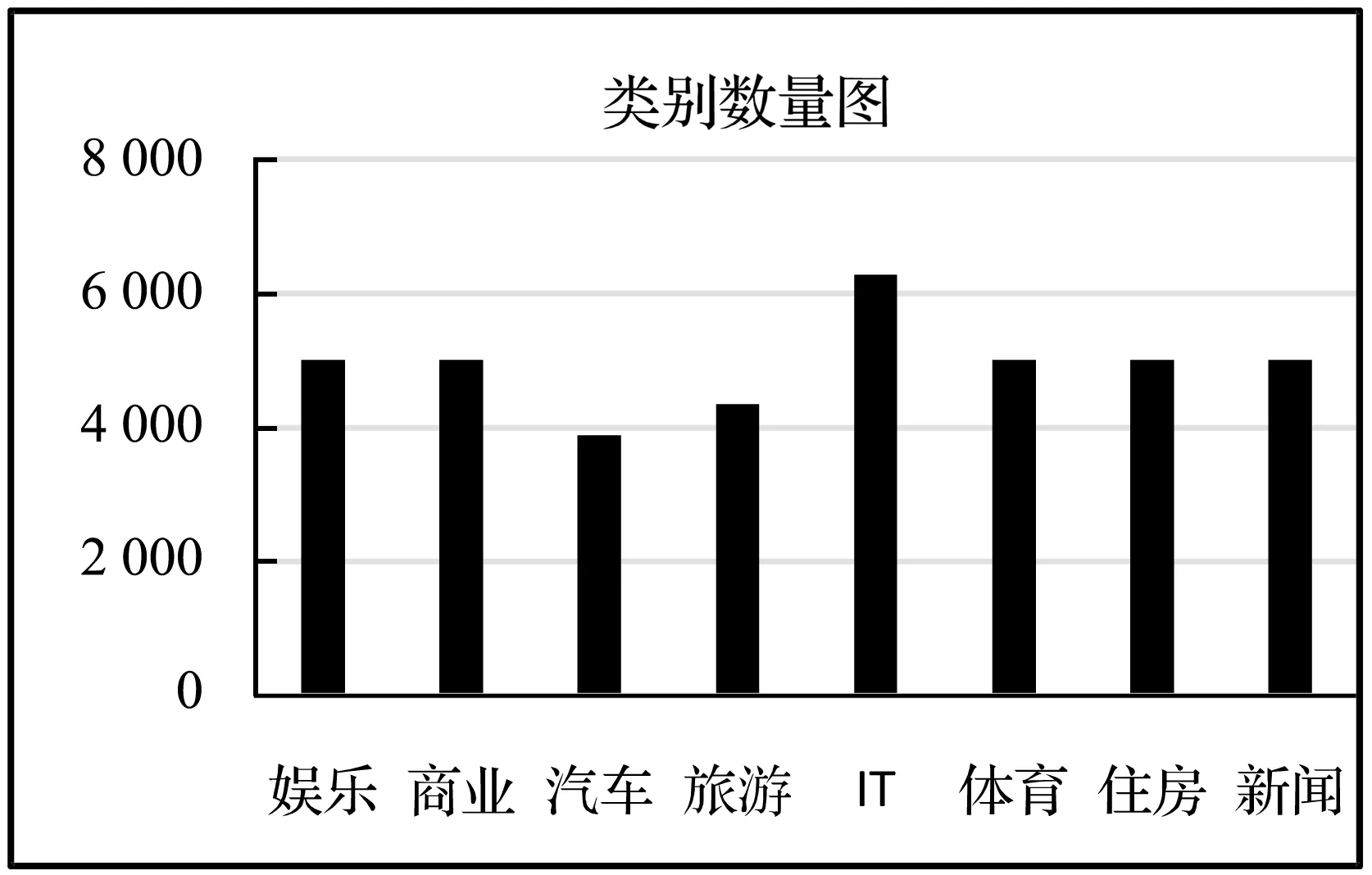
图5 各类别文档数量
将每个类别的数据用词向量的特征扩展算法进行特征扩展后得到新的文本表示数据,其中,每一篇文档均由相同维度的向量进行表示,从而使数据规范化。
本文进行实验的比较对象是基于Word2vec特征扩展以及LDA主题模型进行特征扩展。
基于Word2vec特征扩展是首先对原始语料集利用Word2vec模型进行词向量的求解,对于文章中每一个特征词,将该特征词相似度最高的前20个单词加入到原文本中进行特征扩展,进而用分类器进行分类。
胡勇军等[9]利用LDA高频词进行扩展,并利用搜狗实验室数据集进行测试。基于LDA主题模型特征扩展是先对文档求得文档主题分布、主题词分布,将每一篇文章的最相关的前5类主题以及每类主题最相关的前10个词加入到原文本中,总共50个特征词汇,起到特征扩展的作用。
本文利用深度学习中的多层感知机作为实验算法的分类器,由于深度学习可以学习深层次的语义特征,所以深层分类模型往往优于浅层模型。本实验选择每个类别IFIDF最高的前200个关键词来作为关键词词集。通过分别调整分类器的层数、学习率以及迭代次数,来对不进行处理的短文本进行对比,其中,选择不进行任何处理的短文本数据集,用Word2vec进行特征扩展的数据集来做对比实验,实验结果如图6所示。
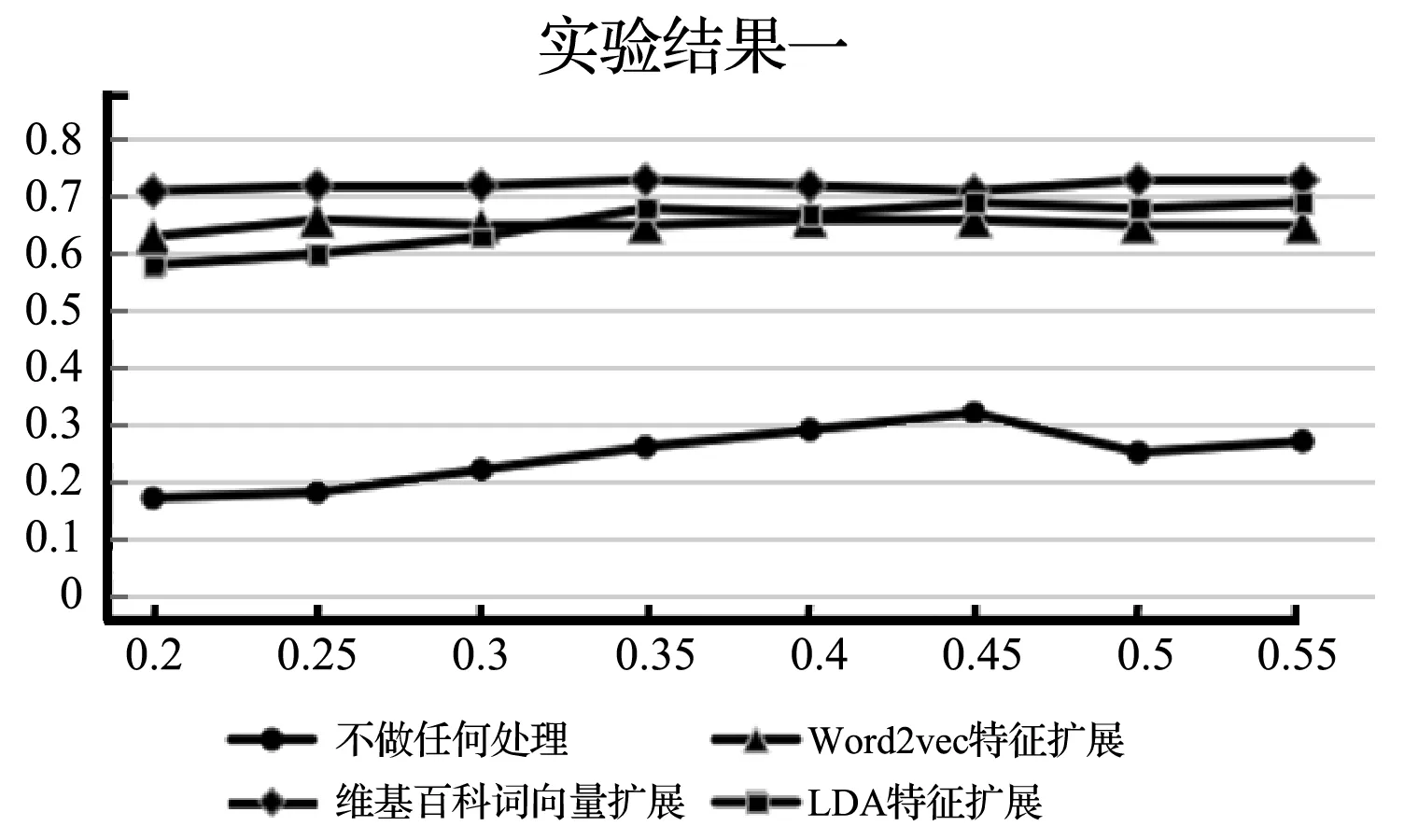
图6 调整学习速率实验结果
实验一中选用层数为3 000-500-500-8的多层感知机分类器,迭代次数为10进行实验,通过调整学习速率来对本文分类算法进行比较。由图6中可以看出,在没有特征扩展的情况下,由于文本数据特征缺失较为严重,分类器得到的精确度较差,由于迭代次数的影响,不进行任何处理的短文本分类数据集效果不好,基于Word2vec特征扩展精确度达到了65%左右,基于LDA主题词特征扩展精确度达到了67%左右,略优于Word2vec特征扩展。本文用基于维基百科词向量的特征扩展算法实验结果精确度达到了72%左右。
图7实验中选用层数3 000-500-500-8的多层感知机分类器,学习速率为0.35,通过调整迭代次数进行文本分类的实验。

图7 调整迭代次数实验结果
由实验结果可知,基于Word2vec特征扩展算法的精确度对迭代次数敏感性不高,精确度在65%左右;基于LDA主题特征扩展的特征扩展方式对迭代次数敏感性不高,精确度达到了63%左右;不进行任何处理的数据实验结果对迭代次数的敏感性较高,随着迭代次数的增加其预测精确度起初增长较快,随后趋于平稳;本文算法受迭代次数影响不大,对迭代次数不敏感,但精确度却高于上述两者,达到75%左右。
表1是在每个类别下Word2vec特征扩展,LDA高频词特征扩展以及本文的精确度、召回率和F1值的结果比较。表1结果是将每个类别的在不同速率下得到的精确度,召回率取平均值后所得,可以看出,本文基于维基百科词向量特征扩展的算法在以上三个评价指标中多数类别取得了不错的结果。
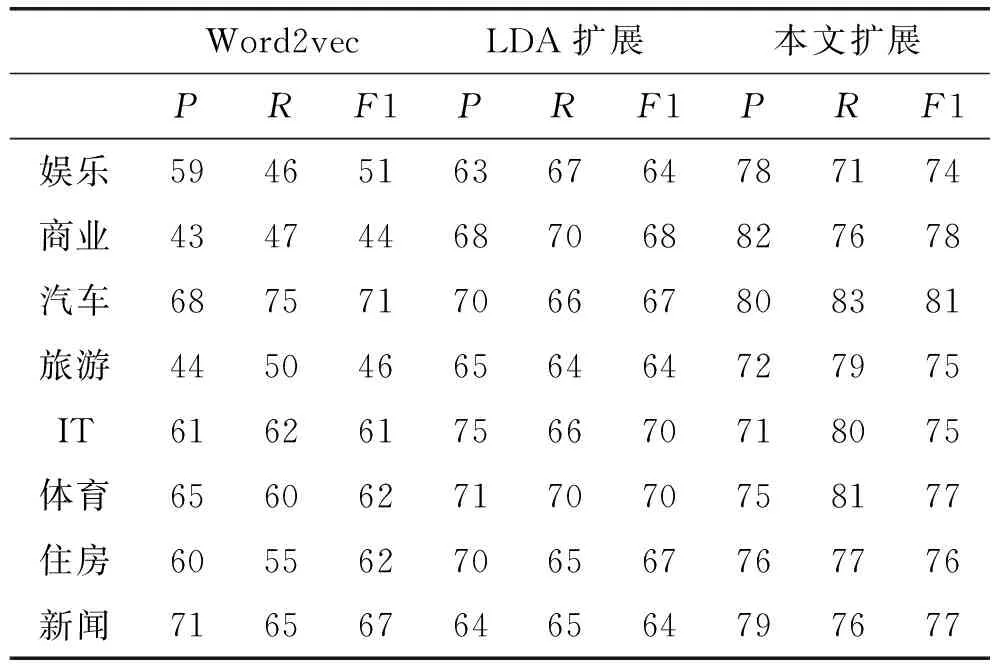
表1 实验结果比较 %
4 结 语
本文提出了基于词向量特征扩展算法,通过训练外部语料数据集来获取外部语料词向量,通过TF-IDF算法来获得文档的关键词集,并将文章中相似度较高的词集加入到原文本当中,达到特征扩展的效果,使得扩充更多的信息到短文本当中,利用分类器来对文本进行分类,得到实验结果。由于本文只用了单词的信息来做文本表示,信息扩展相对来说还是较少,今后可以通过利用句信息,段落信息和文章信息来对短文本特征进行更多的扩展,进而提高文本分类的精确度。
