基于商空间的不完备形式背景填补方法研究
2018-08-15张其文王培瑾
张其文 王培瑾
(兰州理工大学计算机与通信学院 甘肃 兰州 730050)
0 引 言
实际生活中,因为人为因素、设备故障、隐私保护等原因,常常导致信息缺失。关于不完备决策形式背景,传统处理方法直接删除不完备信息记录或采用扩展属性的方法[1-2]。这虽然有助于更快地解决问题,但也破坏了原信息的完整性,降低了知识获取的准确度。
为解决传统填补算法的不足,提高补齐数据的识别率,相继提出了基于属性重要度与近似关系为主线的填补策略[3-6]。这类方法在特征属性缺失率较大时,填补效果较差。Huang等[7]提出K近邻补全算法;武森等[8]基于不完备数据聚类算法对缺失数据进行填补。这些方法的不足之处是填补效果完全取决于聚类的精度与样本数据的平均值,在填补选择上具有一定的局限性。张孙力等[9]利用数据的偏向特性,根据k个近邻数据与缺失数据之间的距离,对k个近邻赋予不同的权值,使补全的数据更加有效、合理。袁景凌等[10]针对绿色数据中心数据收集不完备和断电等因素造成的数据缺失情况,提出了基于完备相容类的不完备大数据填补算法,其填补算法架构在云平台上通过并行化处理,提高了算法的时间和空间效率。
粒计算GrC(Granular Computing)[11]作为目前的热门研究领域,在解决大量复杂数据时,通过粒的思想把复杂的问题抽象化为简单问题来分析与求解。商空间是张铃等[12]提出来的一种粒计算模型。用三元组(X,f,T)来替代描述问题,X表示问题的对象集,f表示对象对应的属性集,T表示对象集上的结构,代指对象间的相互关系。在不同粒度上对问题进行观察,并在其间相互转换,对不同的问题取不同的粒度来求解,这样的思维方式称之为商空间法。
本文在粒度思想的指导下,通过粒计算商空间模型,定义了不完备决策形式背景上的近似关系,构造了模糊近似评估矩阵。通过传递闭包算法得到最小传递关系的模糊等价评估矩阵,实现了对对象集的粒化,得到了不同粒度大小的商集,探讨了商属性取值分布情况,给出了完整的缺失数据填补方法。实验结果分析表明,选择适宜的粒度划分,能够得到较高准确率的填补结果。
1 基本概念与相关定理
1.1 基本概念
形式概念分析FCA(Formal Concept Analysis)[13]自1982年作为一种数据处理的理想工具被德国数学家Wille.R提出后,一直广泛应用于数据挖掘、信息检索、故障诊断等众多领域。
定义1形式背景由三元组(U,A,I)构成,U为对象集,A为属性集,I表示U和A之间的二元关系,有u∈U,a∈A,用(u,a)∈I(或‘uIa’)表示对象u具有属性a,相反的,若对象u不具有属性a,记作(u,a)∉I(或‘uI-a’)。
定义2决策形式背景(U,A∪D,W,I),U={u1,u2,…,un}表示对象集,A∪D表示属性集,其中A={a1,a2,…,ak}表示条件属性,D={d}表示决策属性,且满足A∩D=φ,W=∪(A∪D)表示属性值集合,I满足映射:I:I(U,A∪D)∈W。
在不完备决策形式背景中,条件属性的缺失,会加大决策难度,甚至有时决策属性也会缺失。在四元组表示的决策形式背景中,用W=*(包含空值)表示对象与属性之间的缺失情况或未知情况,即有∀u∈U,∀a∈A,d∈D,I(u,a)=*orI(u,d)=*,‘*’代表的信息是存在的,也是不确定的,其在属性上的取值也是多形态分布的。如表1所示。

表1 不完备决策形式背景
定义3[12]问题(X,f,T),有X上模糊近似关系R,令[X]={[x]|x∈X},则(X,f,T)对应R的商空间为([X],[f],[T]),称[X]是X关于R的商集,[f]为商属性,[T]为商拓扑。
定义4给定X上的模糊近似关系R,设Rλ为截等关系,有:
Rλ={(x1,x2)|R(x1,x2)≥λ}
式中:λ∈[0,1],截等关系Rλ对应的商空间为([X],[f],[T])λ,X(λ)为X上的分层递阶结构。
定义5X上的两个模糊近似关系R1、R2,若存在∀(x1,x2)∈X×X,有R1(x1,x2)≻R2(x1,x2),称R1的粒度比R2的粒度粗,记作R1≻R2。
由定义5,得到商空间([X],[f],[T])λ上的近似关系序列为:R1≻R2≻…≻Ri-1≻Ri,R1为最粗粒度,Ri为最细粒度。模糊近似关系R下,得到分层递阶结构,不同的截等关系对应不同的商空间结构。随着λ的减小,约束条件逐渐减弱,粒度加粗,每一个粒子的形态结构也越大,包含的对象个数越多,其反应的信息精细程度与相应的求解也就越模糊。
1.2 近似精度
定义6设K=(U,A∪D,W,I)为不完备决策形式背景,对于∀ui,uj∈U,ak∈A,满足映射:uj→tui(uj)∈[0,1],(i,j=1,2,…,n),t为近似函数,对象之间的近似度表示如下:
tui(uj)=
(1)
可以看出,对象ui、uj越近似,tui(uj)的值越大,反之,其值越小。其中,|I(ui,ak)∩I(uj,ak)|表示取对象ui与uj在条件属性取值相同时的基数。
由定义6,得到如下推论:
推论任一对象u∈U相对于对象ui∈U-u,(i=1,2,…,n)的平均近似度为:
(2)
由于属性是取多值的,在计算带有缺失数据的对象近似度时,不能直接认定|*∩*|=1,于是提出近似度上界、下界描述对象之间的近似关系,具体定义如下:
定义7对象ui、uj若在条件属性取值上存在如下一种或同时缺失的情况:
I(ui,ak)=*∧I(uj,ak)=*∧I(ui,ak)=
I(uj,ak)=*
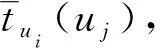
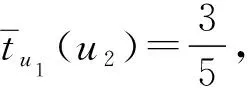
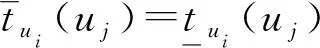
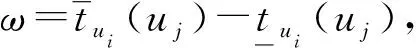
1.3 模糊近似评估矩阵
在不完备决策形式背景上,由于存在缺失数据。传统的模糊近似矩阵不能真实的反应对象间的近似关系,故重新定义为模糊近似评估矩阵为:
定义9模糊近似评估矩阵M=(mij)n×n中的元素mij=[α,ω]定义为:
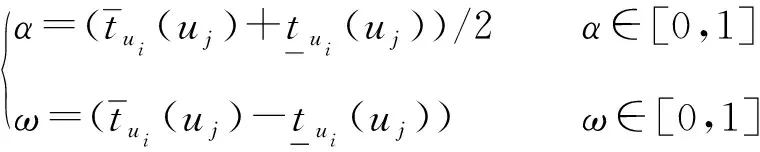
(3)
式中:i,j=1,2,…,n,n=|U|。在矩阵中每一个元素包含两个值,α表示对象ui、uj的模糊近似度。
由表1得到模糊近似评估矩阵如表2所示。

表2 模糊近似评估矩阵
对模糊近似评估矩阵用平方法作传递闭包运算,得到包含模糊近似关系R上的最小传递关系的模糊等价评估矩阵M*。然后对对象集U进行粒化,按照不同的约束条件Ci(i=1,2,…,n)取不同的粒度划分,得到树形的分层递阶结构。根据实际需求,确定阈值,由定义5,求解出模糊关系R下的Rλ截矩阵。形成商集[X]λ={[X1],[X2],[X3],…}。可以看出,每一个截等关系对应一分层递阶结构,本质说来,商集即是对象粒,表示为:
[X]={u|u∈U∨Rλ(u)∈C}
由分层递阶结构可以知道,随着λ的减小,商集所描述的对象粒的粒度也就越粗。
(X,f,T)对应的商空间为([X],[f],[T]),由于原始对象中的属性在粒化后直接影响商属性的取值,商集对应的商属性取值也就不止一种情况,不同近似度阈值也会有不同的填补结果。为准确描述不同的填补值权值分布,引入支持度和置信度:
定义10商属性[f]中,包含属性值w(w∈W)的支持度、置信度分别为support(w)、confidence(w)。
定义11商属性[f]中,属性a(a∈A)的值域为W,那么商集[X]在a的取值w的置信度为:
(4)
式中:support(W)表示商集[X]中属性值的个数。
定义12商属性[f]中,属性值w权重计算公式为:
Weight(w)=confidence(w)×η
(5)
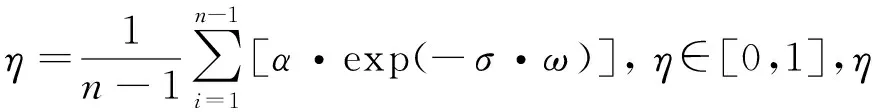
2 基于商空间的填补算法
2.1 算法描述
不完备决策形式背景K=(U,A∪D,W,I)中,基于粒计算商空间模型的填补算法:
输入:不完备决策形式背景K=(U,A∪D,W,I);
Step1初始化,A≠φ,D≠φ。
Step3计算α、ω,导出模糊近似评估矩阵M。
Step4借助传递闭包算法,得到模糊等价评估矩阵M*。
Step5从M*上得到商空间分层递阶结构序列,根据实际需求,确定阈值α、ω,得到截等关系Rλ,划分商集[X]α。
Step6填补缺失数据
1) 商集[X]中对象属性值w无缺失。
(1) 各对象属性值w相同时,商属性值[f]=w。
(2) 各对象属性值w不同时,商属性值[f]=w→max{confidence(w)}。
2) 商集[X]中对象属性值w缺失。
(1) 缺失条件属性A(∀a∈A),即I(u,a)=*时,[f](A)=w→max{Weight(w)}。
(2) 缺失决策属性D(∀d∈D),即I(u,d)=*时,[f](D)=w→max{Weight(w)}。
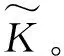
基于商空间的填补算法,具有“高内聚、低耦合”的特性,在不同的实际复杂问题中选取不同的粒度,并在其中相互转换对比,得到不同的填补结果。将低近似度或完全独立的不完备对象,划分到一个粒中完成填补。在算法的应用环境上更具有普适性,对不同的结构化数据填补能起到良好的效果。
2.2 实例分析
按照2.1节算法的描述,由表2得到表3的模糊等价评估矩阵。

表3 模糊等价评估矩阵
该模糊近似关系下,取近似精度ω≤0.6,其对应的分层递阶商空间序列为:
X(α1≥0)={{u1,u2,u3,u4,u5,u6,u7,u8,u9,u10}}
X(α2≥0.4)={{u1,u2,u3,u4,u5,u6,u7,u8,u9,u10}}
X(α3≥0.6)={{u1,u2,u4,u5,u6,u8,u9,u10},{u3,u7}}
X(α4≥0.7)={{u1,u4,u5,u8,u9},{u2,u6,u10},{u3,u7}}
X(α5≥0.8)={{u1,u4,u5,u9},{u2,u6},{u3,u7},{u8},{u10}}
X(α6≥1)={{u1},{u2},{u3},{u4},{u5},{u6},{u7},{u8},{u9},{u10}}
选取上述分层递阶结构中α=0.7,得到商集[X]0.7={[X1],[X2],[X3]},其中:
[X1]={{1},{4},{5},{8},{9}};
[X2]={{2},{6},{10}};
[X3]={{3},{7}};
在该阈值下,得到商属性填补值权重分布情况如表4所示。
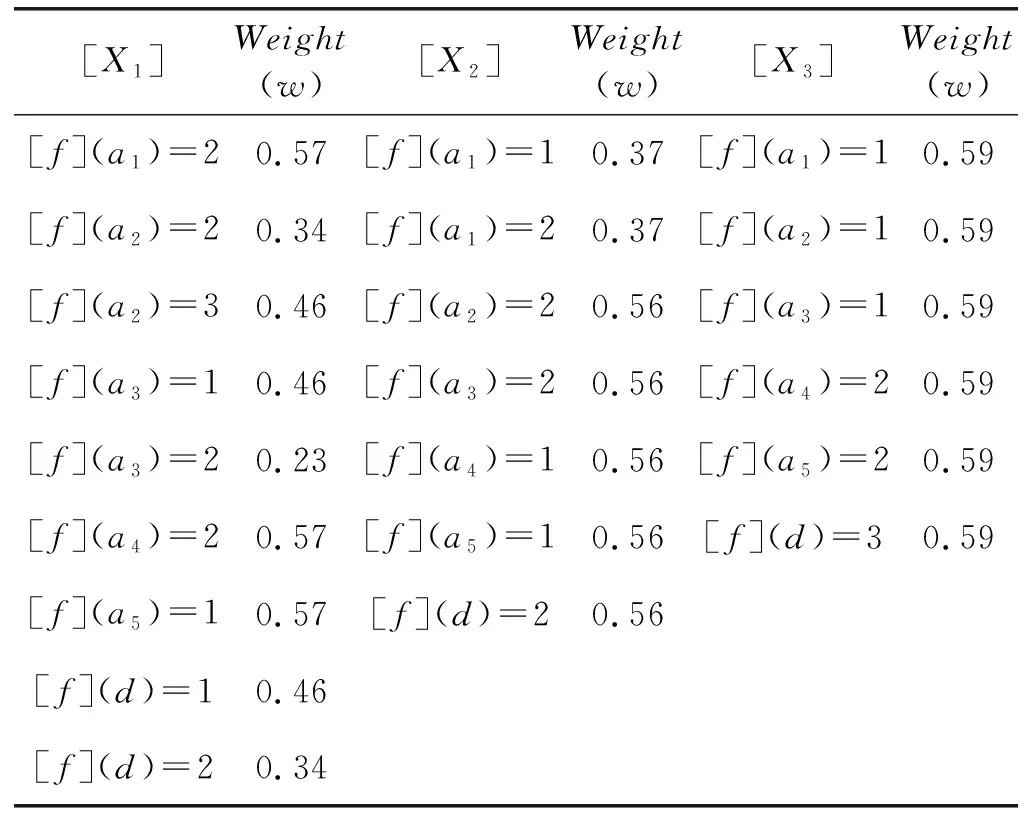
表4 [X1]、[X2]、[X3]商属性填补值权值分布
上述商属性填补值分布表中可以看出,在实际问题分析中,属性取值的多样性,更有利于解决复杂问题,避免了遗漏关键小概率属性值而导致获取的知识不全。填补过程中,根据实际需要选择不同的填补标准。完备决策形式背景取最大权值填补属性后如表5所示(注:填补值权值相同时,同时填补到商属性中)。

表5 完备决策形式背景
填补结果分析:
在粒度X(0.7)ω=0.6下,实现了对象集的粒化,完成了对商属性的数据填补。其中,对象u8的决策属性为2,但在该粒度下属于[X1],决策属性Weight(1)=0.46、Weight(2)=0.34,表明对象u8与决策属性为1的对象在条件属性取值上差异很小。
3 仿真实验
3.1 实验分析
为了进一步验证本文提出的算法有效性,选用完备数据集Car Evaluation Data Set(数据库来自:http://archive.ics.uci.edu/ml/datasets/Car+Evaluation),数据库总数1 728条,每条数据包含6个属性,每个属性包含至少3种不同的值,数据具体描述见表6。实验选用500条数据,选取数据总数按照类别分布等比例选取,见表7。按照属性相对重要度Safety>Persons>Buying>Lug_boot>Doors>Maint,人工对条件属性与决策属性添加缺失。实验环境为:操作系统Windows7 64位,CPU Intel CORE i5 2.6 GHz,内存6 GB。

表6 汽车评估数据集

表7 汽车评估数据集类别分布
基于商空间的数据填补算法中,对决策形式背景来讲,完成数据填补工作的同时,得到其准确的决策属性也是至关重要的。抑或是在缺失率较大的情况下,通过较大粒度的商集,来判定对象的决策属性。为客观的分析算法的实际效果,实验操作从填补后的决策属性准确率进行分析说明,针对不同的粒化阈值,得到不同的填补结果。填补准确率公式为:
(6)
式中:c∈[0,1],n表示决策属性填补准确的个数,N表示数据总数。
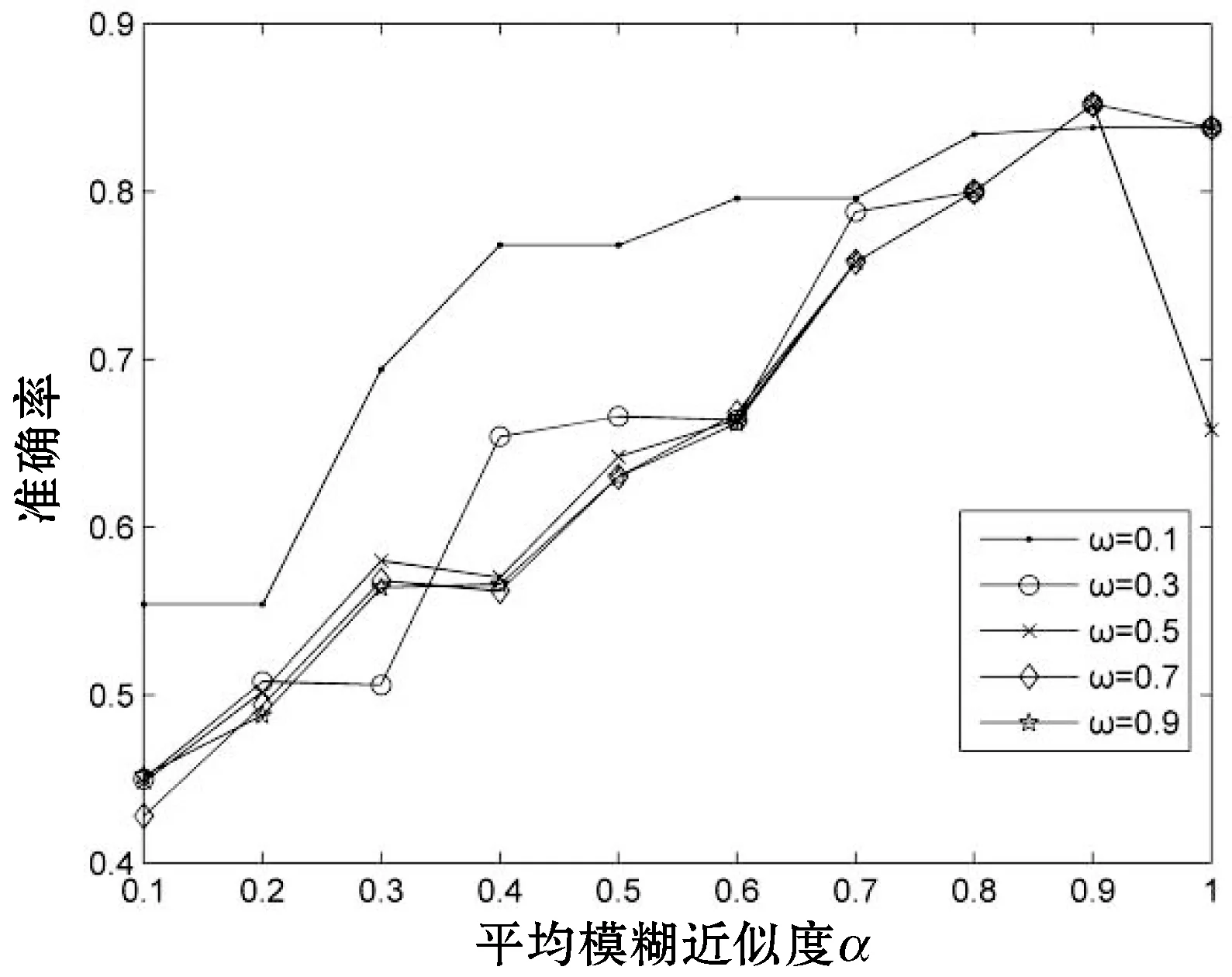
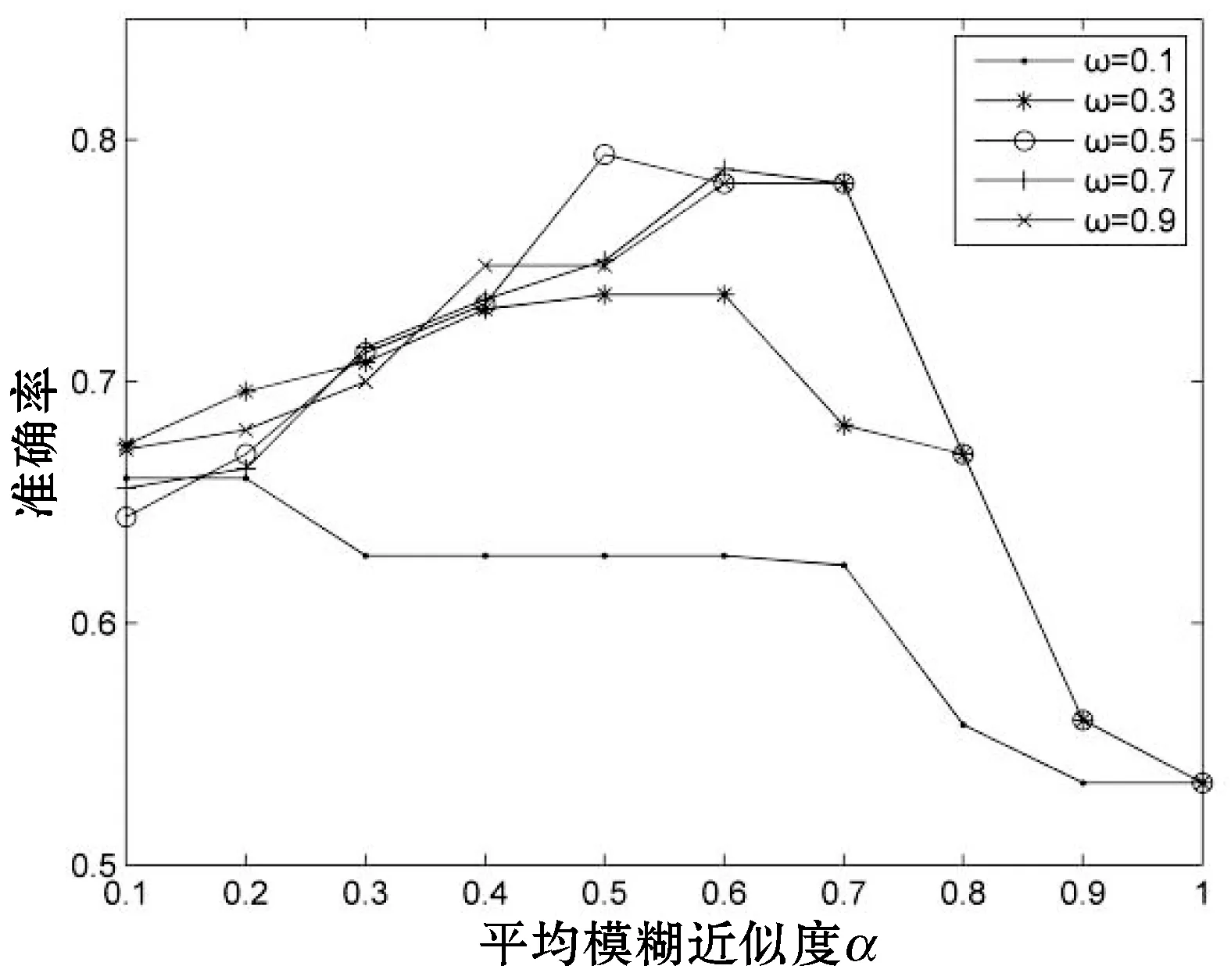
图1给出在缺失率为5%、15%、25%与35%情况下,随着α与ω不同取值下准确率的变化情况。
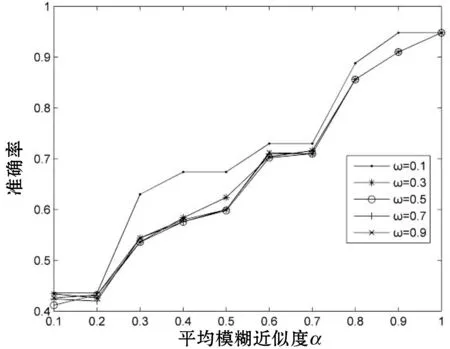
(a) 缺失率为5%
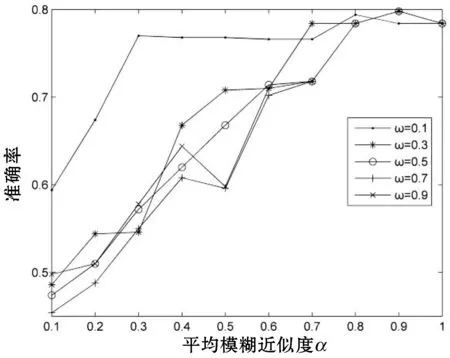
(b) 缺失率为15%
(c) 缺失率为25%
(d) 缺失率为35%图1 不同缺失率下的准确率变化
整体上,在粒度阈值取α偏大,ω偏小时,得到的准确率最高。图1中,随着α的增大,准确率出现下降的情况,因为此时的约束条件越来越严格,粒化程度越来越高。当α=1时,商集则表示独立的对象个体,对象中属性包含缺失数据,故准确率降低。在四种缺失率中,随着缺失率的增大,α对应准确率到达峰值的取值逐渐减小,故在实际生活运用中,可以根据实际的需要去粒化对象,获取最优解。
3.2 对比分析
为进一步验证本文提出的基于商空间填补算法的有效性,选择文献[5]中IATS算法进行对比分析,利用文献中两种数据缺失类型:常规缺失(MIN)和异常缺失(MIA),生成同样的缺失数据集比例进行填补研究,分析结果如图2所示。
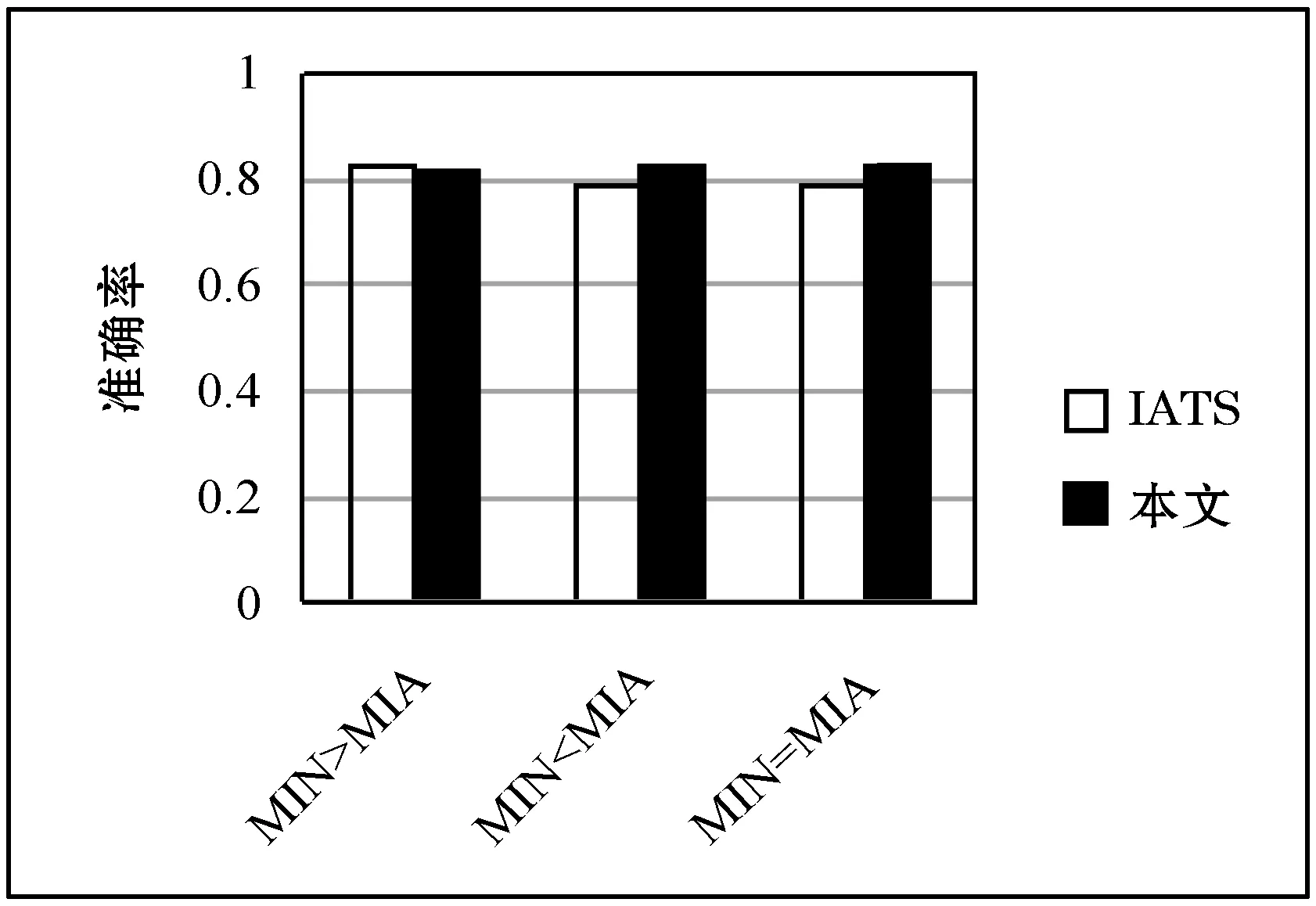
图2 准确率对比分析
由图2可知,在缺失率较低时,IATS的准确率略微高于本文填补算法,但随着缺失率的增大,本文提出的填补算法准确率逐渐高于IATS,体现出本文算法在缺失率较高时的优势。
4 结 语
本文提出的基于商空间的缺失数据填补方法,在处理缺失率较大的数据集时,能有效地提高填补效率。实验结果表明,合理粒度下,在推估、填补不完备信息时能保持较高准确度。在下一步的工作中,将研究如何选取更合理的阈值。
