基于卷积神经网络的跨领域语义信息检索研究
2018-08-15谢先章王兆凯李亚星冯旭鹏刘利军黄青松
谢先章 王兆凯 李亚星 冯旭鹏 刘利军 黄青松,2*
1(昆明理工大学信息工程与自动化学院 云南 昆明 650500)2(云南省计算机技术应用重点实验室 云南 昆明 650500)3(昆明理工大学教育技术与网络中心 云南 昆明 650500)
0 引 言
信息检索是自然语言处理研究中用来解决信息合理推送的问题,例如在自动问答中的应用[1]。当用户进行信息搜索时,搜索表述方式决定着其获取信息的质量,现有基于关键词检索方式已被广泛认可和接受,但这是以大量语料信息作为检索基础,而许多场景下,如小规模或中等规模的语料仅用关键词匹配很难达到理想的效果。同时关键词匹配计算方法将词语作为孤立的元素,这种词语相互之间没有联系的假设是不合理的[2]。为了应对此类情况,研究者从语句相似度入手,句子的相似度研究方法可以归结为:(1) 基于词特征的句子相似度计算[3];(2) 基于词义特征的句子相似度计算;(3) 基于句法分析特征的句子相似度计算[4]。词特征的方法进行句相似度计算一般依靠构建向量空间,但这类方法的明显缺陷是特征稀疏,用在稍大点的语料上效果不理想。为了解决特征稀疏问题,Wang等[5]提出了基于词汇分解与组合的句子相似度计算,其将对比的句子进行向量化,对形成的句子特征矩阵进行分解,最后进行近似语句计算,但是此方法对环境的实时计算能力要求较高。词义特征的方法主要依赖外源语义词典,如游彬等[6]提出的基于HowNet的信息量计算语义相似度算法,但是这类方法局限性太强,外源语义词典的完整性直接影响着模型的准确率。句法分析特征计算句子相似度的方法,如李茹等[7]提出的基于框架语义分析的汉语句子相似度计算,其主要利用依存关系提取核心词构建相似矩阵进行相似度计算,这类方法其实还是停留在浅层词义的分析上,进行相似度计算时忽略了句子中词与词之间的关系,在短文本分析中效果较不理想。
目前卷积神经网络多用于图像处理领域,但随着对卷积网络的深入研究,其逐渐被用于自然语言处理[2]。何炎祥等[8]提出了一个情感语义增强的深度学习模型EMCNN进行中文微博的多情感分类,取得了较好的分类效果。Wang[9]进一步提出了用语义簇和卷积神经网络对短文本进行分类,分类效果相比其他短文本分类方式有更高的准确率。
针对当前相似度计算方法存在的问题,本文结合卷积神经网络的特性提出了基于卷积神经网络的语义信息检索模型。此模型首先将语料进行分类,然后根据分类结果选择不同类别的卷积神经网络检索模型,这样使得缩小无效检索域的同时避免不同领域的相同词具有不同语义特征的情况。然后将训练语料转化成向量矩阵特征和聚类特征,通过卷积神经网络模型对两种特征进行映射训练,训练过程是一种无监督的训练方式。本模型用词向量作为特征克服了特征稀疏的问题,同时卷积神经网络的使用能使模型提取词与词之间的潜在语义关系。为了验证本模型的有效性,从问答网站上爬取不同类别的提问语料用于模型训练。实验结果表明,相比传统关键字匹配检索,本文提出的基于卷积神经网络检索模型有更高的查准率和召回率。
1 预处理
1.1 词向量
词向量概念是Hinton[10]于1986年提出来的一种词表示方式。其通过训练将语言中每个词映射成一个固定短向量。相比于传统稀疏的词表示方式,利用低维固定长度的词向量更有利于数据分析。本文利用gensim的word2vec模块进行词向量训练。由于词的向量是由词的邻近词所计算出来的,所以向量里会隐含语义信息,适合用于语义的信息提取[11]。
1.2 基于语义的快速聚类
在卷积神经网络映射训练时需要用到句子的聚类特征,而生成句子的聚类特征需要对语料中的词进行聚类,得到由不同词所形成的词簇。这里用词向量作为词聚类的近似依据。
搜索密度峰的快速聚类是Alex等[12]于2014年所提出来的快速聚类方法,其利用局部密度和高密度最小距离作为聚类标准。对较大数据进行聚类分析时,相比传统聚类其速度更快且效果较好,此方法不像k-mean聚类那样需要提前定义好聚类数目,只要定义好局部密度和高密度最小距离的阈值就能自动提取聚类中心,划分出类别来。局部密度计算方式如下:
(1)
式中:ρi表示点i的局部密度值;dc表示截断距离;dij表示点i到点j的距离,实际运用中用向量之间的余弦值表示。χ函数的计算公式如下:
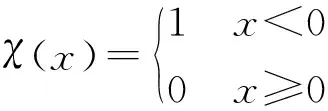
(2)
高密度最小距离计算方式如下:
(3)
计算出局部密度和高密度最小距离后,便可提取聚类中心点,在词聚类中称为词类别中心。最后进行一次遍历就可计算出其他点的最近聚类中心,最终生成所有点的类别。利用上述聚类方式对词进行聚类,为句子构建词聚类特征建立基础。聚类特征的生成和运用会在3.2中详细阐述。
1.3 改进SVM短文本分类
由于不同领域的相同词,特征倾向有很大的不同,所以对句子进行近似计算前进行文本分类,这种处理方式会减少无效检索域,有助于提高模型检索的查准率。SVM是一种适用于高维空间的分类方法,传统利用SVM对文本进行分类的方式是将文本有代表性的词标记为一个id,即一个独立的维度,同时设定对应词的权重,进行SVM训练[13]。对信息进行检索时检索语料一般为短文本,这就导致将词作为独立维度,如果选用的特征词过少,难以表达特征少且特征空间高的短文本特征,会使分类性能降低;如果选用的特征词过多,会造成整体维度较高,使得特征极其稀疏,最终导致短文本分类效果不尽如人意[14]。所以本文用词向量作为SVM的训练特征数据,特征表示如下:
(4)
式中:W为句子去掉停用词后所包含的词,函数V为获取W的词向量。分类效果在实验部分进行对比。
通过以上方法获得检索语料的类别后,再将检索语料放入对应类别的卷积神经网络检索模型中进行信息检索。
2 基于卷积神经网络的检索模型
本文的语义检索模型由句卷积层、池化层、隐藏层和转换层组成,整体结构如图1所示。
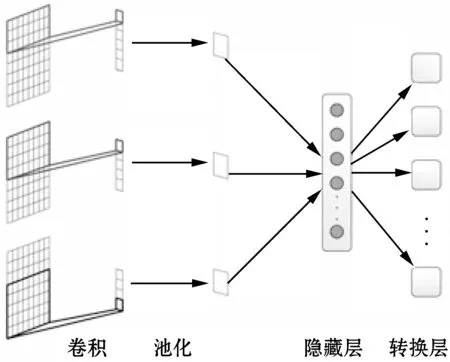
图1 语义信息检索模型
此模型的建立基于两个假设:
(1) 与每句句子相似度最大的句子是句子本身。
(2) 两句子语义相似则其句子片段必定有多处语义接近。
基于以上假设,本文提出了将相同句子的不同表达特征使用卷积神经网络模型进行映射训练,从而达到近似句计算的目的。
2.1 句卷积层
句卷积层将预处理后的词向量矩阵进行卷积,为了使向量矩阵中的不同特征被尽可能地被提取,利用不同的卷积窗口卷积出不同的卷积向量。图1中有三个卷积窗口,由于每个卷积窗口是按行卷积,所以每个窗口卷积出的特征个数为:
K=H-h+1
(5)
式中:H为特征矩阵高度,h为卷积窗口高度。每次进行卷积的卷积值为:
(6)
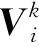
2.2 池化层
从卷积层获得的卷积向量表示的是不同卷积窗口中的特征,为了表示向量矩阵在卷积窗口中的特征强弱,需要使用池化层来过滤,一般选用最大值的过滤方式。最终n个卷积窗口生成一个n维特征向量。对文本特征进行池化的好处在于最终特征的输出个数不会随输入句子的长度变化而变化。同时池化处理在不损失显著特征的前提下减少输出结果的维度,减少模型计算量。
2.3 转换层
作为模型的最后一层,也是卷积神经网络最重要的一层。其目的是把经过池化层和隐藏层生成的句子特征进行映射,映射到新的特征空间上。转换层的每个节点表示词库经过语义聚类后的类别,即转换层神经元个数为词聚类的类别个数。隐藏层输出的系数作为句子中词所在类别的修正系数,利用句子级别的特征弥补词级别特征的不足。近似值计算方式如下:
(7)
式中:Cj表示检索句子和被检索句子j的近似值,Wi表示隐藏层第i个输出系数,且0≤Wi≤1,mij表示句子j在聚类特征上的第i个系数。
生成聚类特征m的方式如下:
(8)
式中:mj表示聚类特征的第j个值,Wi表示句子中第i个词,tj表示第j个词类别中心的词向量,V为词向量函数,将词转换为向量。图2为聚类特征生成示例图,对句子进行全模式分词。
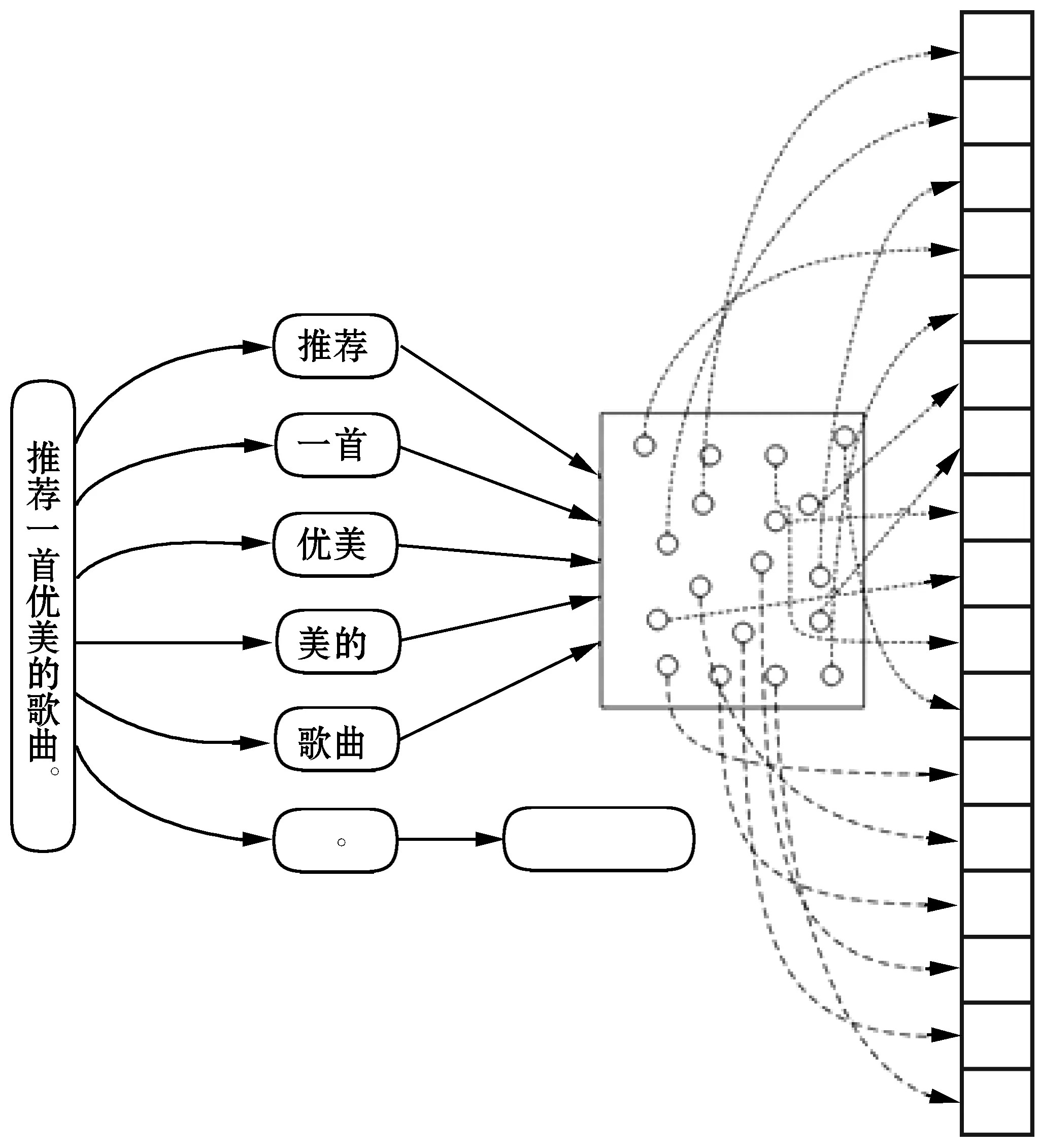
图2 生成聚类特征
由上面的句卷积层、池化层和转换层构成了图1中语义信息检索模型,通过此模型可以将卷积特征和聚类特征形成映射,最终达到信息检索的目的。每次检索会将检索信息的卷积特征和所有被检索信息的聚类特征在模型中进行计算,计算所得的数值就是最终句子的近似度。
3 结果和训练优化
3.1 评价方法
实验过程中,以成功率作为评价模型近似句计算的标准,以召回率和查准率作为信息检索的评价标准。
成功率计算公式如下:
(9)
式中:PSC表示模型的成功率,sucTopN表示在sum次测试中TopN上包含最为近似的数据次数,sum表示测试集上的数据总数。
查准率计算公式如下:
(10)
召回率计算公式如下:
(11)
式中:Ppr和Pr分别表示查准率和召回率;A表示检索到的相关数据数量;B表示检索到的不相关数据数量;C表示未检索到的相关数据数量。
3.2 语料片段训练
为了解决句子对句子片段匹配不敏感的问题,即防止句子在模型训练中过拟合,这里加入语料片段用于训练。将句子切分成片段:
Pi={wi,wi+1,wi+2,…,wi+n-1}
则长度为L的句子可以切分出L-n+1个片段。为了使训练片段中包含句子的关键信息,利用以下公式对片段进行筛选:
(12)
式中:tfd为将词转化为TF-IDF值的函数,如果Pdi<α则过滤掉第i个片段,反之则将其用于语料训练。
3.3 近似计算结果优化
利用上述方法对1 000条问答句子进行100次近似计算测试,成功率如表1所示。

表1 未经模型优化TopN成功率表
从表1可知模型已发现89%测试数据的近似语句,但Top1的成功率相对较低。为了优化结果,可以从模型的两个方面入手:
(1) 考虑向量的近似性,对前10条记录进行重排,重排的计算依据是:
(13)
式中:S1表示用于检索的句子,Sj表示被检索的句子。
(2) 在相似计算阶段考虑向量近似性,对结果权值进行适当调整,即式(7)改为:
(14)
式中:tj为式(10)计算结果,β为调整系数,实验中取0.01。
优化(1)和优化(2)的区别在于优化(2)在排序时同时考虑网络计算结果和向量相似性,而优化(1)在筛选出前10条近似句后,仅考虑向量的近似性进行重排。即优化(1)注重候选句的内部调整,优化(2)注重提高候选句的整体质量。
将优化(1)和优化(2)同时考虑后,成功率如表2所示。

表2 模型优化后的TopN成功率表
4 实 验
本文一共进行了5个实验,目的分别为:
(1) 分类处理对模型近似计算成功率的影响。
(2) 词向量SVM分类和其他分类方式效果进行对比。
(3) 测试隐藏层层数和每层神经元个数对模型成功率的影响。
(4) 对基于卷积神经网络的近似计算与其他近似计算方法进行对比。
(5) 测试本模型用于信息检索的检索效果。
实验一
为了对比分类对模型近似计算的影响,拿未分类和经过四分类处理模型进行测试,测试类别为:财经、体育、娱乐和科技。将四类分别取200、500、800和1 000条作为分类后模型的训练数据,每个类别构建独立的CNNs模型。从四类中随机抽取200、500、800和1 000条作为未分类处理模型的训练数据,构建一个混合类别的CNNs模型,实验结果如图3所示。
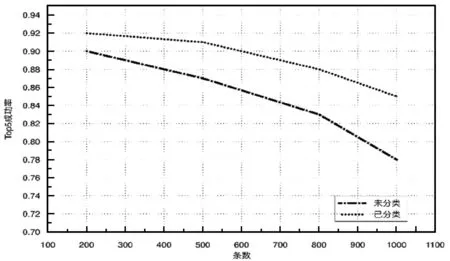
图3 未分类-已分类模型对比
从图3可以看出两种模型Top5成功率都会随着数据量的增加而下降,但经过分类处理的模型的下降速率相对更小。原因在于:(1) 对同一类别的词进行词向量训练,生成的词向量质量更好,从而使模型对语义的泛化能力更强;(2) 在未分类模型中,随着数据量的增加,同形不同意词造成的干扰会越来越强。
实验二
分类的质量直接影响着模型的结果,为了对比不同模型的短文本分类效果,用财经、体育、娱乐和科技四类语料各10 000条短文本用于训练,取100条短文本用于测试。实验结果如图4所示。
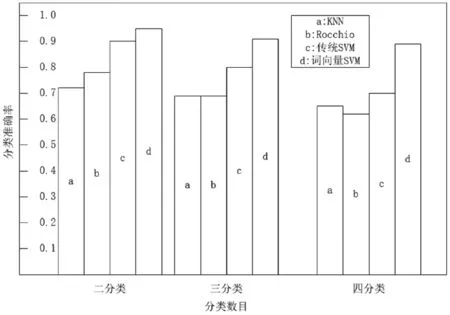
图4 分类准确率
通过图4可知基于词向量的SVM方式较其他分类方式有更高的准确率,由此可以说明将词向量作为训练特征相比传统以字为特征单位有更强的特征表达能力,同时克服了SVM用于文本分类时特征稀疏的问题。
实验三
神经网络中隐藏层的层数和每层神经元的多少直接影响着网络的功能效果。网络每层的神经元越多,即维度越高,其逼近能力越强,但是神经元过多会降低网络的泛化能力,造成过拟合。同时网络维度应逐层降维,降维幅度不宜过大,否则会使降维过程降低噪声信息的同时损失重要的信息,导致结果剧烈震荡[15]。
由于神经元的确定目前还没有统一的标准,所以这里通过实验进行测试,确定一个效果较好的近似语义模型。拿1 000条短文本进行模型训练,用100条近似句用于测试。测试模型为:一层隐藏层,节点数1 600;二层隐藏层,节点数1 600~1 200;二层隐藏层,节点数1 600~800。实验结果如表3所示。

表3 不同模型结构Top10成功率
由表3可见二层隐藏层模型比一层隐藏层模型有更高的成功率,原因在于二层隐藏层模型泛化能力相对更强。通过对表3的1 600~1 200和1 600~800隐藏层对比,可以推测1 600~800隐藏层之所以成功率下降,主要在于第二层隐藏层的节点降幅过大,造成一定的信息损失。
实验四
为了比较此模型与其他常用近似计算方法,这里从Top1、Top5、Top10的成功率进行对比,用1 000条短文本作为匹配目标语句,进行100次测试计算,结果如表4所示。

表4 近似计算方法的成功率
由表4可以明显看出,Self-CNNs比n-gram overlap,同义词扩展和编辑距离有更高的成功率,这是由于n-gram overlap和编辑距离过度依赖字面匹配,同义词扩展则忽略了邻近词之间的关系,而Self-CNNs模型利用词向量和CNNs特性弥补了这两方面的不足。
实验五
为了测试模型用于信息检索的实用性,这里拿传统关键字匹配检索与本模型进行对比,分别从查准率和召回率两方面进行比较。在1 000条被检索信息中进行100次检索测试。结果如表5所示。

表5 检索模型性能对比
从表5可以发现基于卷积神经网络的信息检索方法比关键字检索方法以及BGRU-CNN方法[16]有更高的查准率和召回率。其中基于卷积神经网络的信息检索方法召回率远高于关键字检索方法,这是由于中短长度文本的表达用词呈现多样化,基于卷积神经网络的信息检索方法不会受限于信息的字面匹配,从而相比关键字检索有更高的召回率;而BGRU-CNN由于使用了遗忘门和更新门,丢失了句子中一些有用的信息,造成了准确率和召回率不如CNN语义信息检索的问题。
5 结 语
本文提出一种基于卷积神经网络的语义信息检索模型。利用词向量SVM进行短文本分类,降低无效检索域从而提高近似句的成功率,再将分类后的文本拼接成向量矩阵放入卷积神经网络,将卷积神经网络的最后一层用转换层进行近似句的检索计算。实验表明基于卷积神经网络的近似计算模型用于信息检索相比关键字检索有更高的查准率和查全率。可是此模型面对海量数据进行句子相似度检索还略有不足,这也是接下来要进行的工作。
