基于时序数据库的电力运维系统关键技术研究*
2018-08-14荣雪琴刘勇刘昊卜树坡
荣雪琴,刘勇,刘昊,卜树坡
(苏州工业职业技术学院 电子与通信工程系,江苏 苏州 215104)
0 引 言
随着“大物移云”,即大数据、物联网、移动互联网、云计算的蓬勃发展,新技术使电力系统在数据量和应用模式上发生了巨大转变[1],传统的电力运维系统已无法满足信息化电力系统的需求[2],存在电网企业难以实时监控运维作业过程,无法掌握运维进度[3]、运维管理存在检修安装人员数量不足和检修工程量过大的问题[4]。这些问题不仅会给安全运行带来极大的隐患,而且会造成不良的社会和经济影响。因此,从“大物移云”发展趋势出发,构建新的数据密集型电力运维系统是非常必要和迫切的。
1 电力系统运维管理
电力系统运维管理包括对电力设备软件系统、硬件设备的运维管理,对电力设施及设备台账、软硬件版本、参数/定值信息进行设置,同时包含对客户托管设备的运行状态监测,实现多种能源接入终端基础信息的标准化、一体化,为系统各类应用提供统一的基础数据[5]。
2 系统架构与实现
文中系统主要包括四个子系统:系统界面子系统、应用支撑平台、数据服务子系统、平台服务子系统,分别实现在线运行的配电设备、用户侧用电设备以及其他类型能源设施、设备运行状态监控、维护以及检修管理等功能。
其中,系统界面子系统包括:Web瘦客户端、现场作业移动App客户端、电力图形化组态工具、WebGIS系统、一次/二次告警事件处理等。应用支撑平台包括:设备全寿命周期状态监测、故障诊断与处理、运维管理、检修管理、运检流程管理、资产管理,数据服务子系统包括:电能量数据建模、业务数据、数据预处理、数据统计、数据评估。平台服务子系统包括:关系数据管理、Key-value数据存储、分布式存储管理、消息管理、分布式文件管理、集群管理、权限管理、安全管理。
系统以分布式构架设计,实时库数据来源为配电终端数据、充电桩数据、微电网数据等高速实时数据,并以Restful API方式提供电量时序数据库和前端Web应用服务访问接口,后端服务器将应用数据模型和业务模型映射到数据中心,采用分布式内存存储、计算用户用电信息,极大提升系统的处理容量、性能及可靠性。系统架构如图1所示。
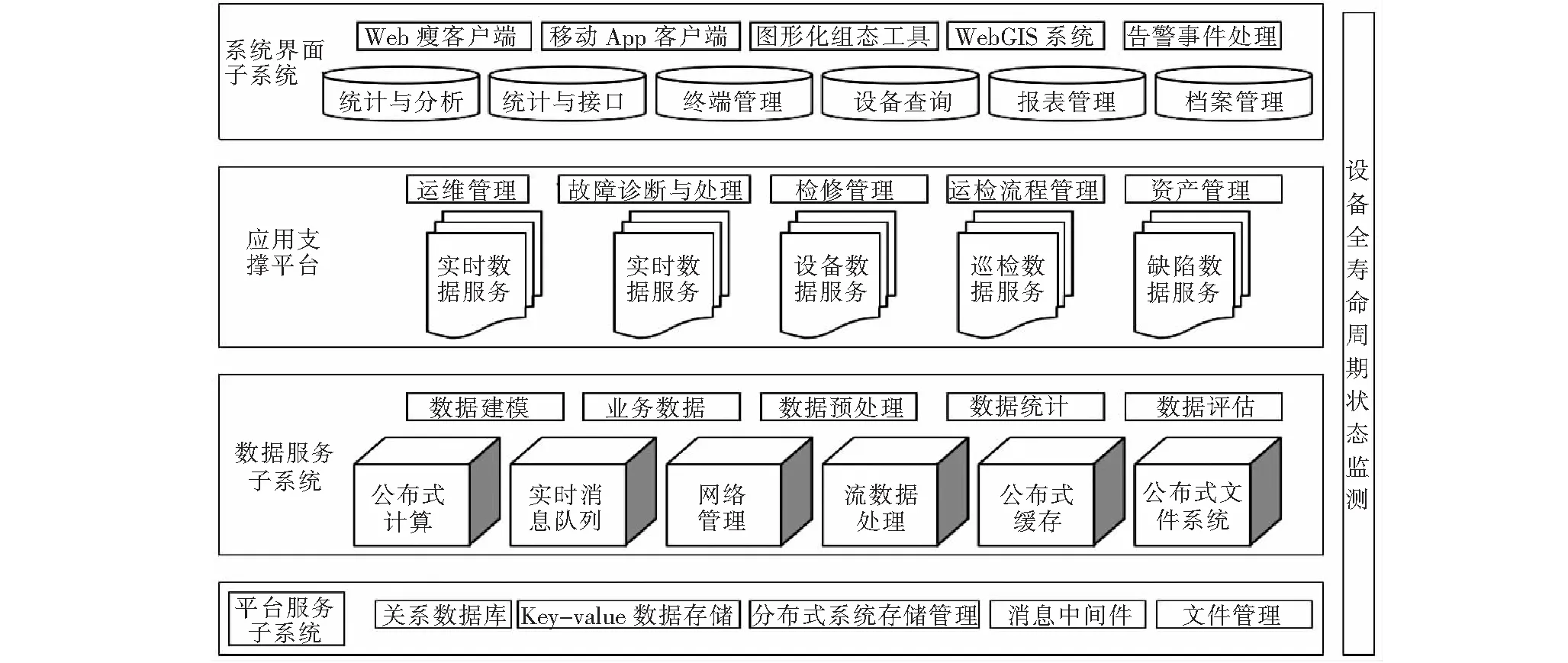
图1 系统架构图Fig.1 System architecture diagram
3 Node.JS简介
采用Node.JS作为后端服务器开发环境,Node.JS是一个基于Chrome V8引擎的JavaScript运行平台,文献[6]从事件驱动,异步非阻塞I/O等方面阐述了Node.JS快速构建网络服务及相关应用。文献[7]提出了前后端分离开发模式,可根据前后端要求提供相应的访问方式。文献[8]提出了非阻塞特性及异步事件驱动模型在高并发网络服务应用,减少了运行资源,提高系统性能。
4 时序数据库(TSDB)
为解决智能电网建设和生产过程中大规模时序数据的快速存储和访问处理难题,以分布式为主要特征的时序数据库系统受到高度关注[9]。文献[10]将时序数据库与当前主流关系数据库技术特点进行比较,总结了时序数据库拥有超大规模数据处理能力和高比例压缩能力的技术创新性。文献[11]进行了加载测试、查询测试实例验证,证明时序数据库在超大规模数据集、高实时性方面能够满足智能电网大数据应用需求。文献[12]从构建服务器集群的角度,提出策略驱动技术实现时序数据的灵活存储与处理,进一步验证了时序数据库的高效性。表1为日冻结电量表,图2为存储正向有功总电能的时序数据库JSON结构体。
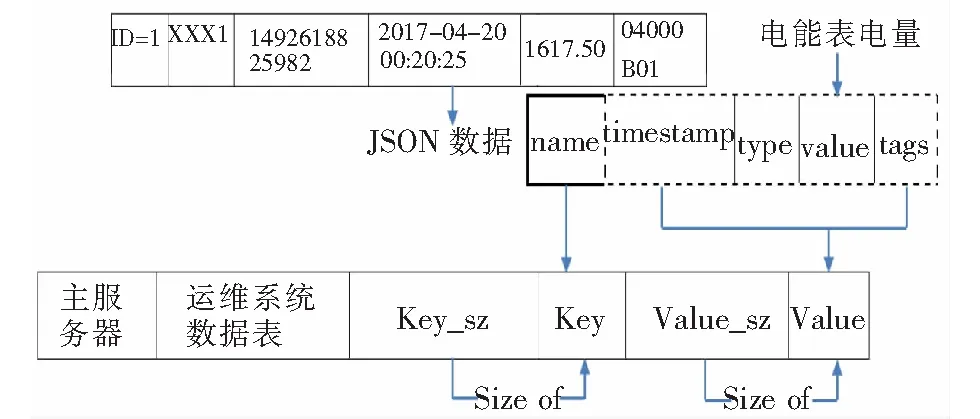
图2 电量时序存储结构体Fig.2 Power sequencing storage structure
文章设计电力运维时序数据库着重考虑电力系统庞大的数据总量,借助时序数据库的Key-value数据存储模式实现电能表定时冻结、瞬时冻结、日冻结、整点冻结数据的高速存储与查询,方便对年度、季度、月度的电量进行分布式查询计算。

表1 电能表冻结电量列表Tab.1 Freezing electricity consumption of electric energy meter
5 电力运维系统存储结构
电力运维信息涉及电力设备的(准)实时运行信息,及其关联设备和所处站所的当前状况,要求数据存储具备高吞吐量、批量更新数据及极高的内存利用率。对于Key-value模式实现电能表数据存储,运维系统存储结构采用日志结构存储(Log-Structured Storage)。图3为电力运维系统存储结构。
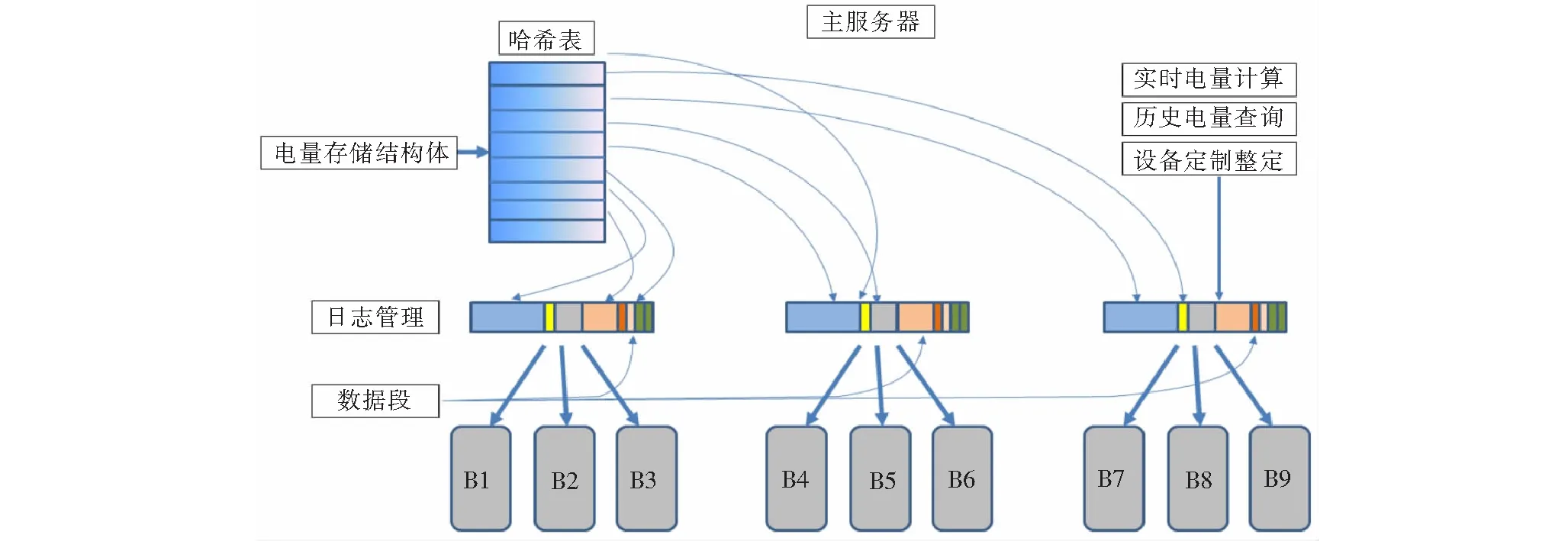
图3 系统存储结构Fig.3 System storage structure
6 Node.JS实现运维系统新增业务功能
6.1 Rest API动词映射
Node.JS建立时序数据库服务有两种方式,分别为Rest API和Rest client。Rest client是第三方提供的客户端程序,具有开发快速、资源众多等优点,缺点是扩展性不好,因此本文案采用Rest API方式建立时序数据库服务,消息交互采用轻量级的数据交换JSON格式封装[13-16],表2为时序数据库增加(C)、查询(S)、修改(U)及删除(D)操作与Rest API动词对照关系,Node.JS通过这种映射关系建立时序数据库服务。
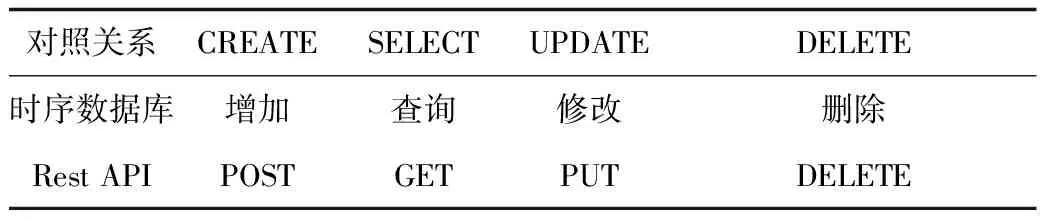
表2 CRUD操作与Rest API动词对照表Tab.2 CRUD operation and Rest API verbs
6.2 新增业务请求流程
新增业务是运维系统所有数据的来源,是系统核心功能之一,如图4所示,当用户发起业务请求后,先对请求进行负载均衡处理,将请求转发至不同的服务器上进行反向代理请求头的处理,处理完的数据会发送给Node.JS实现时序数据新增业务,然后将数据返回Web瘦客户端。
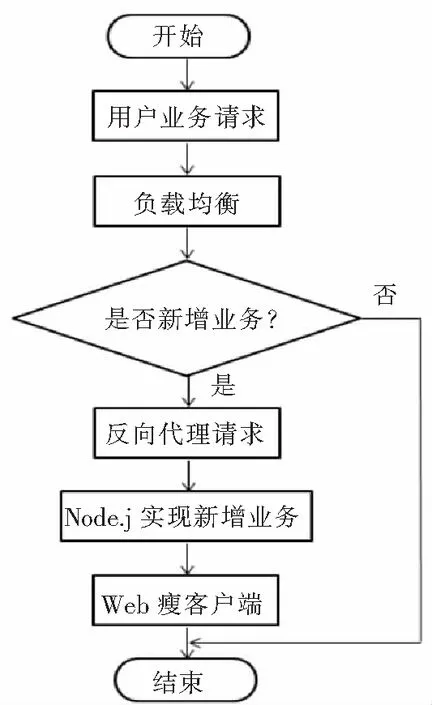
图4 请求业务流程Fig.4 Request-business processes
6.3 Node.js实现新增数据业务
当Web瘦客户端向后端发送增加数据业务指令后,Node.js将新增的数据存储在电量时序存储结构体data_create中,按照表2的映射关系请求连接时序数据库,在建立服务连接后,将data_create数据以Rest API方式新增至时序数据库。
关键程序代码:
exports.resource =function(req,res){
var data_create=[{"name":"指标名","timestamp":"时间戳","value":"存储值","tags":"查询条件"}}
var opt={
method:"POST",host:"IP",port:”port”,path:"/api/ver/resource",
varreq=http.request(opt,function(serverFeedback){
if(serverFeedback.statusCode==request_type){var body="";
serverFeedback.on('data',function(data){body+= data;})
.on('end',function(){console.log("success:",serverFeedback.statusCode);});}
else {console.log("wrong:",serverFeedback.statusCode);}});
req.end();
7 运行结果测试
结果测试包括服务器和服务器集群模式,主要针对Key-value类型的智能电能表数据测试。图5给出了采用服务器和服务器集群对智能电能表“日冻结”数据进行计算时,服务器集群与计算规模的关系曲线。从图中可知,随着集群数量的增加,计算规模呈上升趋势,但当集群数量较大时,网络瓶颈成为系统性能的主要制约因素。
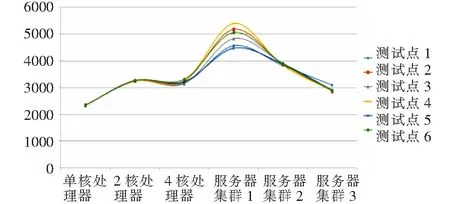
图5 服务器集群与计算规模关系曲线Fig.5 Relationship curve between server cluster and computational scale
8 结束语
结合电网企业对设备的管理需求,采用Node.js、JSON、Rest API框架,建立了基于时序数据库的电力运维系统架构,可扩展性强,更易使用大数据技术进行数据挖掘和二次开发,能够快速、准确地完成对电力设备运维作业的科学、高效优化。
