基于多元概化理论的英语听说考试信度效度研究
2018-08-14刘燕王华
刘燕,王华
(1.山西大学商务学院 外语系,山西 太原 030031;2.山西大学 外语学院,山西 太原 030006)
一、引言
任何语言测试在本质上都是一个抽样过程,抽样必然带来样本的概化问题[1],即从抽取的样本得出的结论在多大程度上可以推论到全域中(universe domain)。Messick[2]认为概化性是构念效度的一个重要组成部分,可以从两个层面去理解。第一,概化性涉及信度问题(reliability),即对考生能力的推论在多大程度上可以概化到不同的任务、不同的群体、不同的评分员等情况下;第二牵涉迁移问题(transfer),即考生在测量更广阔构念任务上表现的一致性问题。概化理论[3]为分析语言行为测试的概化性提供了很好的分析框架。正如Schoonen[4]和McNamara[1]指出,概化理论不仅可以估算语言行为测试的信度,而且还可以为不同任务提供聚合效度方面的证据。本研究将使用多元概化理论分析听说考试的信度和不同任务聚合效度方面的证据。
二、相关研究
概化理论是在经典测试理论和方差分析的基础上,由Cronbach及其同事在上世纪70年代提出,经Brennan等逐步完善的测量理论。概化理论应用分为概化研究阶段和决策研究阶段。在概化研究阶段,概化理论估算出不同测量侧面(facet)及他们之间的交互作用的方差分量。在决策研究阶段,这些方差分量则可被用于不同的测量情景中,估算不同测量条件下信度指标,如概化系数(generalizability coefficent)、可靠指数(phi index)和侧写差异性(profile variability)指数(g^ 值)。
随着GENOVA,EduG等概化理论测试软件的开发和不断完善,概化理论被广泛地应用到研究测试的信度和效度上。Gebril[5],Lee[6],Lee&Kantor[7],Sawaki[8],Schoonen[9],Xi[10]等利用概化理论对语言行为测试进行研究。他们的研究不仅表明概化理论可以分析信度,分析不同测量侧面组合对信度的影响,也能提供不同任务聚合效度方面的证据。在国内,运用概化理论对语言行为测试进行分析的研究相对比较少,如李航[11],孙海洋[12],赵向民和王占礼[13],而且这些研究基本上都是只用单元概化理论进行信度分析。即使使用了多元概化理论,如罗娟和肖云南[14],汪顺玉和席仲恩[15],他们的分析也是停留在信度分析的层面。
在多元概化理论中,一个测试被看成是由v个测量不同构念的部分组成,这v个部分被当成是固定侧面(fixed facet)。在概化分析中,这v个部分不能发生变化,能发生变化的是每个部分中的测量侧面的数量,如题目、评分员等的数量。不同于单元概化理论,多元概化理论可以同时估算每一部分中测量侧面以及他们之间的交互作用的方差和协方差。其次,多元概化理论可以估算每一部分在域分数上之间相关系数,这为分析不同部分是否测量相似的构念提供数据支持,也为能否合理的合成一个总分提供了基础。在合成总分时,每一部分的权重可能不同,这个权重通常是由考试开发者设定,称之为名义权重。但不同部分的名义权重对考生能力方差的实际贡献是否和考试开发者预期的一样呢?多元概化理论的另一个优势在于,可以估算每一部分的效应权重,即不同部分对考生能力方差的实际贡献率。基于国内现有研究不足和多元概化理论的优势,本研究将回答以下三个问题:
1)听说考试评分的信度如何?如果将评分员从1名增加到4名,评分的信度将如何变化?
2)听说考试三个任务在域分数上的相关度如何,是否支持这三个任务测试的是相似构念?
3)听说考试三个任务对总分方差的实际贡献率是否和考试开发者预期的一样?如果改变名义权重,对考试的信度有何影响?
三、研究方法
(一)被试
本研究的被试包括455名学生和6名评分员。这455名学生中,男生171名,女生284名,他们的年龄介于17至20岁之间。六名评分员中,男女各3名,他们均多次参加过口语考试阅卷。
(二)实验材料
本研究采用的听说考试共有三个任务组成:第一个任务是模仿朗读;第二个任务是角色扮演;第三个任务是故事复述。
(三)评分
这六名评分员被分成三组(每组男女各一名),每组负责一个任务的评分。在评分之前,每一组都详细分析讨论了各自任务的评分标准,在对评分标准达成共识后,每一组都试评了15份(这15份不包括在最后分析的455份考生录音)各个分数档的考生录音。对于评分不一致的样本,评分员都进行分析和讨论,最终他们对评分标准的把握达成了基本共识和一致。
(四)数据分析
数据分析使用的是多元概化理论分析软件mGENOVA2.1[3]。英语听说考试由3个部分组成,但每个部分只有一个任务,理论上这样的组合不适合使用多元概化理论分析,如果使用的是整体评分法。由于听说考试每一部分使用的都是分项评分法,这使得可以使用多元概化理论进行分析,但只能将不同的评分维度看成固定侧面。这样的研究设计存在其不足之处,即在决策研究阶段,无法估算任务数量的增加是否会影响信度。多元概化理论分析最理想的分析模式是考生(p)、评分维度(d)和评分员(r)的完全交叉模式(p x d x r)。本研究使用了6名评分员,每名评分员都嵌套在某个任务中,实际上本研究的设计模式是p x(r:d)。但这样的模式在mGENOVA2.1无法运行,因此本研究将6名评分员对三个任务的评分看成是两个评分员对三个任务的双评,这样本研究就成了考生(p)、评分维度(d)和评分(r’)的完全交叉模式(p x d x r’)。这种做法在很多概化研究中都被采用(如Lee[6];Sawaki[8])。
四、结果和讨论
(一)听说考试的信度
1.方差估算
多元概化理论在概化研究阶段分别估算了模仿朗读、角色扮演和故事复述三任务中考生、评分维度、评分、考生和评分维度交互、考生和评分交互、评分维度和评分交互以及考生、评分维度、评分三者交互和随机误差这七个方面的方差以及它们占各自方差总量的百分比。如表1所示,在听说考试三个任务中,占方差比重最大的都是考生,分别解释了各自方差总量的44.5%、49.1%和51.1%。这说明听说考试中,考生分数之间的差异主要是由考生的能力造成,即听说考试能很好地将考生能力区分开来,这也是听说考试期望的结果。除了故事复述任务外,考生和评分维度之间的交互是第二大方差来源,分别占模仿朗读和角色扮演方差总量的24.0%和35.7%,这说明不同评分维度对考生排序存在较大差异。本研究将角色扮演任务总分分成问题分和答题分两部分,这两部分分相当于模仿朗读和故事复述任务中的分项分。考生和评分维度之间的交互方差较大说明考生在问题和答题部分的排序不同。在故事复述部分,考生和评分维度之间的交互虽然不是第二大方差来源,但它也占方差总量的12.5%,这表明考生在信息点得分和综合得分上的排序也存在着一定的差异。需要注意的是,在故事复述部分,方差的第二大来源是评分维度,占方差总量的23.9%,这意味着故事复述两个评分维度在难度上存在着较大差异,也就是说,考生在这两个评分维度上得分的容易程度不同。在模仿朗读和角色扮演中,第三大方差来源是考生、评分维度、评分的交互和随机误差,分别占方差总量的15.2%和10.3%,这说明有相当一部分考生在评分维度和评分交互上排序出现不一致,或者这说明在模仿朗读和角色扮演中有相当一部分无法解释的随机误差。相对而言,在故事复述中,考生、评分维度、评分的交互和随机误差占方差总量比重较少,只占6.9%。这说明考生在评分维度和评分交互上排序基本一致,或者可能是故事复述任务随机误差较小。在模仿朗读和角色扮演中,第四大方差来源都是评分维度,分别占8.4%和2.7%,不过它们占各自方差总量的比重差距较大。评分维度占模仿朗读方差总量的8.4%说明在模仿朗读中,考生在语音语调和语速两个分项分上得分的容易程度不同。但在语音语调和语速上得分的容易程度跟在故事复述中信息点得分和综合得分的难易度比起来,这种容易度要小很多。评分维度占角色扮演方差总量的2.7%说明在问题和答题在难度上存在差异,但这种差异非常的小。在听说考试的三部分中,评分所占的方差都比较小,分别占5.2%、1.6%和0.6%,这说明每一组评分员之间的严厉度基本接近。但需要指出的是,在模仿朗读中,评分所占方差稍高,这说明在这个部分评分时,评分员之间还是存在一定的差异。考生和评分之间的交互在模仿朗读和角色扮演任务中所占的方差几乎可以忽略,分别占0%和0.5%,这说明在这两个任务中,评分员对考生的排序基本完全一致。但考生和评分之间的交互在故事复述任务中,占方差总量的4.4%,这表明评分员在故事复述任务中对考生能力的排序存在着一定的差异,但这种差异不是很大。
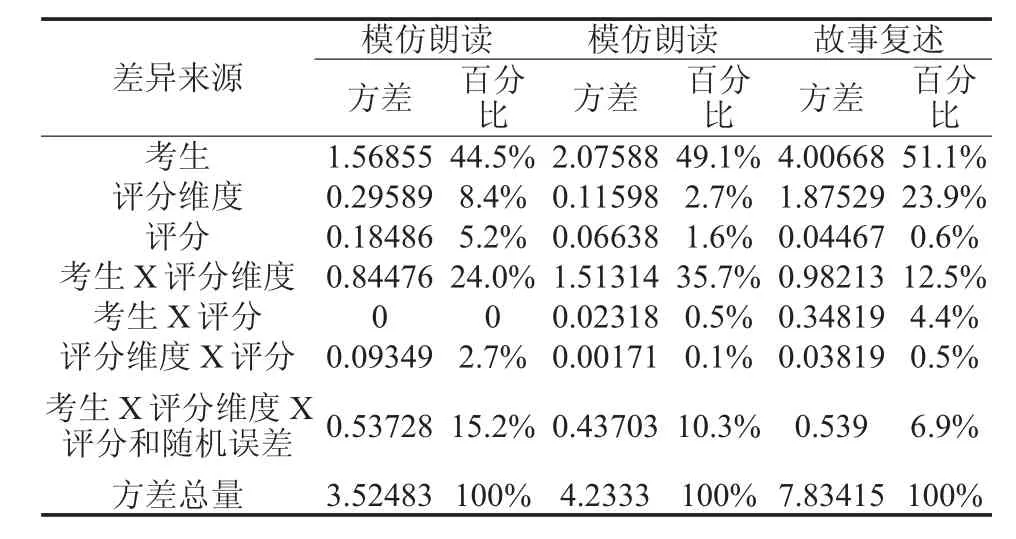
表1 概化研究方差估算
2.信度指标
在多元概化理论的决策研究阶段,我们分别估算信度指标在模仿朗读、角色扮演、故事复述三个任务以及总分上的变化跟评分员数量与之间的关系。Brennan[3]以及Xi[10]指出,在多元概化理论中,概化系数、可靠指数以及表示考生侧写差异性的g^值是表示信度的重要指标。概化系数是对考生相对排序的信度指标,一般用作制定相对决策的常模参照测验,而可靠指数是对考生绝对排序的信度指标,多用于制定绝对决策的尺度参照测验。在计算概化系数时,使用测量对象的方差和测量对象和其他测量侧面的交互作用所产生的误差作为分母,而在计算可靠指数时,使用测量对象的方差和其他所有的误差作为分母,因此,概化系数总是大于可靠指数。g^值是对考生在侧写上相对平整度(the relative flatness)的估算,它的值越大,说明考生域分数方差占考生观察到的分数方差的比重越大。也就是说,g^值越大,越说明在考生的分数中考生能力占的比重越大,分数的误差越小。这三个指标的取值都在0和1之间。
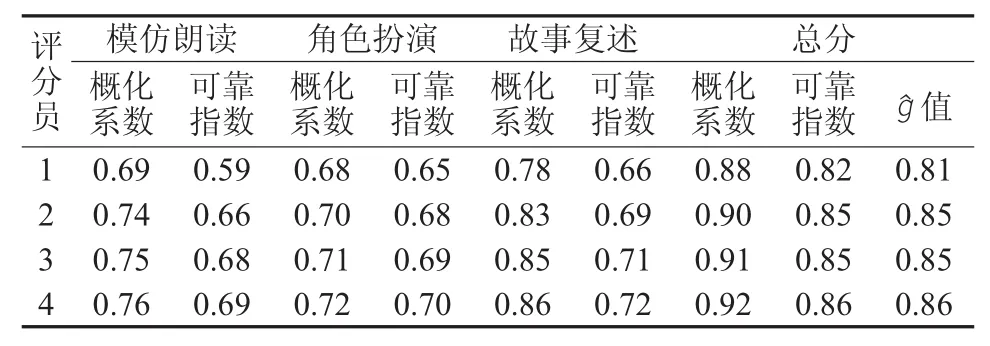
表2 信度指标估算
从表2可以看出,当只有一个评分员时,在模仿朗读、角色扮演和故事复述三个任务中,概化系数分别为0.69、0.68和0.78,虽然在模仿朗读、角色扮演概化系数未达到0.7,但都非常接近0.7(在语言测试界,通常信度指标达到0.7才被认为是可以接受的,见Green[17],2013)。这三个任务的可靠指数分别为0.59、0.65和0.66,均未达到0.7。虽然三个任务各自的概化系数和可靠指数相对比较低,但总分的概化系数、可靠指数和值却相对比较高,分别为0.88、0.82和0.81。这说明从总分上看,英语听说考试的信度非常好。同等情况下,总分这样的信度指标甚至比新托福口语考试的指标都高,托福总分的概化系数和可靠指数分别为0.78和0.78[6]。即使从单个任务来看,每个任务的信度还是相当不错的,因为英语听说考试是常模参照性考试,我们只需要参考概化系数。
当两个评分员评分时,每一个信度指标,不管是每一个任务的概化系数和可靠指数,还是总分的概化系数、可靠指数和值都有了相对较大的提高,提高的幅度分布在0.02和0.07之间,提高幅度的均值为0.04。但当把评分员人数从2个增加到3个,从3个增加到4个的时候,信度指标提高的幅度明显降低,尤其是把评分员人数从3个增加到4个的时候,提高幅度的均值只有0.01。这样的研究结果得到很多使用概化理论分析信度研究的支持(Lee[7];罗娟和肖云南[15];李航[11])。随着评分员人数的增加,信度指标提高的幅度会逐渐降低,提高幅度最大的是当把评分员人数从1个增加到2个的时候。
(二)域分数上三个任务的相关性
任何测量都是有误差的,如果使用有误差的分数进行相关分析,无形中会增大或者减小事物间相关系数,导致无法准确地估计事物之间的相关性。多元概化理论可以剔除由测量带来的误差,估算考生的真分数,概化理论称之为域分数。如表3所示,在听说考试中,模仿朗读和角色扮演、模仿朗读和故事复述、角色扮演和故事复述在域分数上的相关系数分别为0.87、0.76和0.99。角色扮演和故事复述在域分数上近乎完美的相关(0.99)说明这两个任务实际测量的构念非常接近,尽管两个任务考察的形式不同。虽然模仿朗读和角色扮演在理论上测量的构念不同,但它们之间较高的相关系数(0.87)说明两部分可能实际上测量的构念比较接近,另一个可能的原因是语音语调好的考生在听力理解和口语表达能力方面也比较高。模仿朗读和故事复述在域分数上相关系数(0.76)相对较低,这可能是由于模仿朗读所测的构念只是故事复述任务所测构念的一部分。

表3 域分数相关性
(三)效应权重
Brennan[3]指出合成总分效应权重受三个因素的影响:名义权重,域分数方差以及域分数协方差(covariance)。表4列出了听说考试三个任务的名义权重和效应权重,从表4中可以看出,故事复述任务占合成总分域分数方差的50.88%,大于其名义权重。角色扮演任务占合成总分域分数方差的比重为24.03%,比较接近其名义权重,而模仿朗读占25.09%,低于其名义权重。这说明,故事任务最能区分考生的能力,而且占总分域分数方差的一半还多。在现有名义权重下,模仿朗读和角色扮演两个任务的对总分域分数方差的贡献率基本一致。如果考试开发者期望强调某一任务,可以改变其名义权重,但改变名义权重会改变总分的信度。Kane&Case[18]在研究不同名义权重对测试信度和效度影响时指出,如果给与信度较高部分较大的名义权重,总分的信度将会提高,到达某个点前,也会提高效度。但如果给与信度较高部分过大的名义权重,将会降低总分的效度。从表2可以看出,信度最高的是故事复述任务,如果改变故事复述任务的名义权重,总分的概化系数是否跟Kane&Case预测的一样呢?表5列出了三种名义权重下总分的概化系数,从表中可以看出,现有名义权重下,总分的概化系数是最高的。从总分的信度来看,这说明现有名义权重是最优组合。这从一个侧面说明听说考试设计的科学性。

表4 听说考试名义权重和效应权重
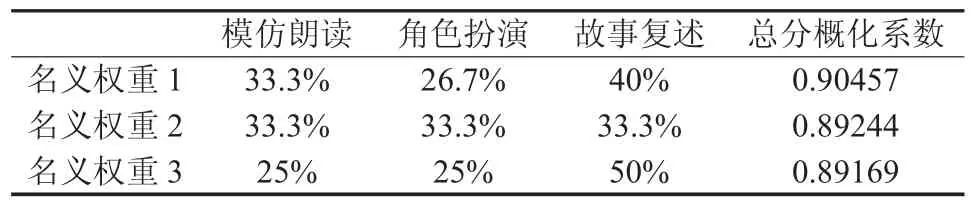
表5 不同名义权重下总分的概化系数变化
五、结束语
本研究运用多元概化理论分析了6名评分员对455名学生在听说考试上表现的评分结果。总体来说,本研究发现英语听说考试具有较高的信度,三个任务在域分数上相关度较高说明这三个任务测试的构念比较接近,支持将三部分合成总分报告给考生,现有名义权重的组合研究也说明听说考试能最大限度地提高信度和效度。本研究也发现了一些值得今后深入分析的地方。在故事复述任务中,方差的第二大来源是评分维度,这说明考生在这两个评分维度上得分的容易程度不同。这可能需要对这两个评分维度进行进一步的分析,发现存在差异的原因。在模仿朗读中,评分所占方差稍高,这说明在这个部分评分时,评分员之间还是存在一定的差异,需要进一步分析,这种差异是评分员自身的原因还是评分标准的问题。
