全球高性能计算发展态势分析
2018-08-12郑晓欢陈明奇房俊民
郑晓欢 陈明奇 唐 川 张 娟 房俊民*,
(1.中国科学院办公厅,北京100864;2.中国科学院成都文献情报中心,成都610041)
1 引言
高性能计算(High Performance Computing,HPC)是利用并行处理和互联技术将多个计算节点连接起来,从而高效、可靠、快速地运行高级应用程序的过程,在许多情况下又被称作超级计算(Supercomputing),可以提供比普通台式计算机或工作站更高的性能,以解决科学、工程或商业中的复杂问题,已成为解决科学研究、经济发展、国家安全等方面诸多重大难题的重要手段。发展高性能计算催生了许多高端技术,并推动了下游产业的发展,因此各发达国家多年来均投入大量资金和人力发展高性能计算。
目前,我国已建成由17个高性能计算中心构成的国家高性能计算服务环境,资源能力位居世界前列,尖端成果不断涌现。我国研制的超级计算机已连续10次在以Linpack性能排名的HPC TOP500中夺冠,我国学者开发的超算应用还连续两次获得ACM戈登·贝尔奖,说明我国不但能造出世界上速度最快的计算机,而且能在超级计算机上实现其他国家还做不到的实际应用,高性能计算已像航天和高铁一样成为中国的“名片”[1]。同时,各国纷纷加强高性能计算研发布局和应用拓展,我国已做好百亿亿次计算的战略部署,新一轮竞争已经开始。在此背景下,本文对全球高性能计算发展态势进行了剖析和讨论。
2 主要国家和地区战略规划与项目部署
2.1 美国
美国以“国家战略性计算计划”为主要纲领,由不同政府部门协同推进未来高性能计算,特别是百亿亿次计算研发与应用。
2015年7月,美国正式启动“国家战略性计算计划”(National Strategic Computing Initiative,NSCI),旨在使HPC的研发与部署最大程度地造福于经济竞争与科学发现。NSCI确定了HPC研发的指导原则与目标,界定了参与机构的性质与职责,并设立了协调机构。2016年7月发布的“国家战略性计算计划战略规划”[2]则在此基础上,进一步明确了各机构在每一项发展目标中的具体责任。该计划设定的战略目标有:加快可实际使用的百亿亿次计算系统的交付;加强建模、仿真技术与数据分析计算技术的融合;在15年内为HPC系统乃至后摩尔时代的计算系统研发开辟一条可行的途径;实施整体方案,综合考虑联网技术、工作流、向下扩展、基础算法与软件、可访问性、劳动力发展等诸多因素的影响,提升国家HPC生态系统的可持续能力;创建一个可持续的公私合作关系,确保HPC研发的利益最大化,并实现美国政府、产业界、学术界间的利益共享[3]。
此外,一些政府科研部门也有相应部署和投入,主要包括:
2.1.1 美国国家科学基金会超算系统投资计划
作为美国国家科学基金会(NSF)“极限数字发展计划”(XD)的一部分,2014年11月,NSF宣布投资1620万美元构建两套超算系统,用于补充开放科学团体现有的资源,使研究人员能在更广泛的前沿科学领域中利用HPC[4]。这两套超算系统被分别命名为“桥(Bridges)”和“喷流(Jetstream)”,并于2016年投入使用。
1)“桥”(Bridges)。Bridges获资960万美元,位于匹兹堡大学的匹兹堡超级计算中心,重点帮助科学家解决需要处理和移动大量数据、对计算速度要求不高的科学问题,可针对不同的问题和数据量,为用户提供定制化的内存、数据带宽、计算能力。
2)“喷流”(Jetstream)。Jetstream获资660万美元,分散安置于印第安那大学的泛在技术研究所和德州大学奥斯汀分校的德州先进计算中心(TACC),是全球最大的公共科技云之一,用于补充美国国家网络基础设施中基于云的计算能力,帮助研究人员按需访问云计算和数据分析资源,以满足科学与工程研究群体的多样化计算需求。
2.1.2 美国陆军研究实验室2015—2019年技术实施计划
2015年1月,美国陆军研究实验室(ARL)发布“2015至2019年技术实施计划”,分别从技术研发和基础设施建设两个层面提出美国陆军对高性能计算研发与建设的短、中、长期目标,如表1和表2所示[5]。

表1 超级计算技术研发目标Tab.1 Technical goals for supercomputing
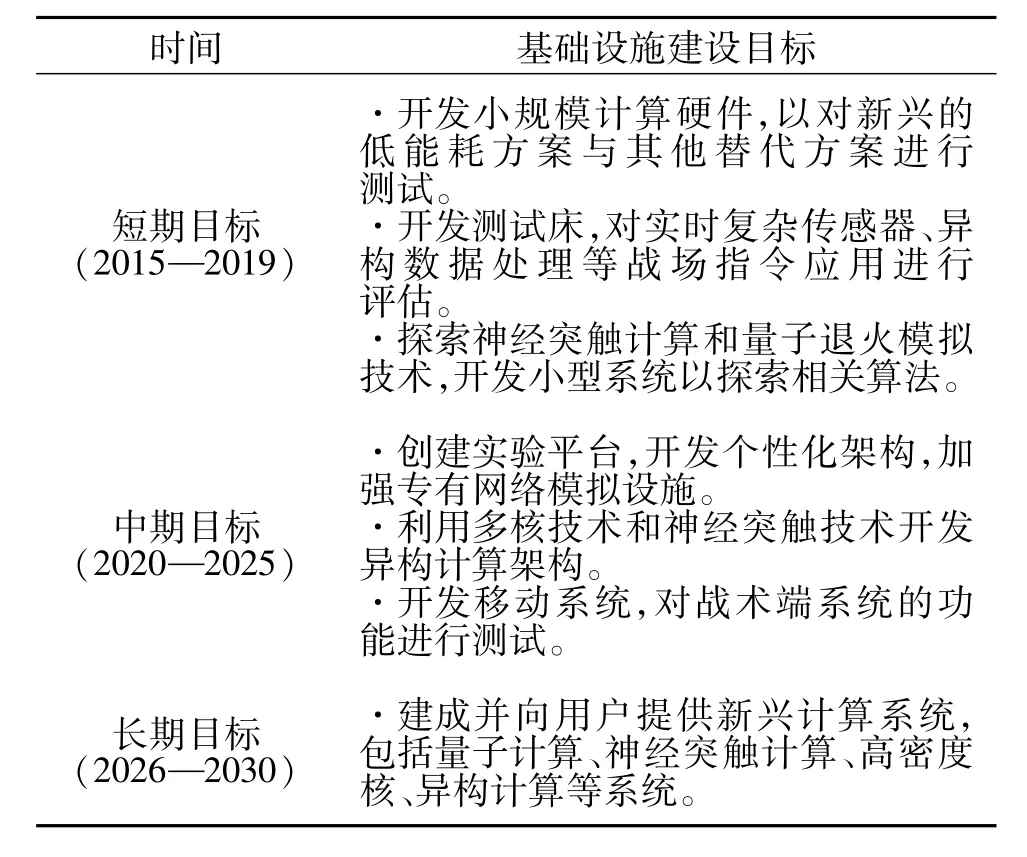
表2 超级计算基础设施建设目标Tab.2 Infrastructure construction goals for supercomputing
2.1.3 美国能源部下一代超级计算机研发项目
针对“国家战略性计算计划”,美国能源部(DOE)于2016年4月推出了“百亿亿次计算项目”(Exascale Computing Project,ECP),将此前处于初期的“百亿亿次计算行动计划”(Exascale Computing Initiative)逐步转变为正式的DOE项目[6]。ECP旨在解决对未来百亿亿次系统的有效开发和部署至关重要的硬件、软件、平台和人才发展需求,使高性能计算为美国经济竞争力、国家安全和科学发现带来最大程度的利益。ECP将开发运算性能是当前的千万亿次系统50~100倍甚至更高的超算系统,提供突破性建模与仿真方案以在更短的时间内分析更多数据。
作为十年期项目,ECP重点关注以下四个领域:
1)应用开发:使ECP的应用套件具备可扩展的性能,能在ECP百亿亿次系统上有效执行。
2)软件技术:扩展现有的DOE SC和NNSA软件栈,使其能有效使用百亿亿次系统。同时开展工具与方法研发,改进生产性能并提升可移植性。
3)硬件技术:资助超算供应商开展创建百亿亿次系统所需的硬件架构设计研发。
4)百亿亿次系统:资助测试床和先进系统工程的开发,关注采购功能性百亿亿次系统所需增量式现场准备和系统扩展的成本。
总额为3980万美元的首轮经费[7]全额资助了15项应用开发项目和7项种子基金项目,涵盖45家研究和学术机构,旨在开发侧重于可移植性、可用性和可扩展性的先进建模和模拟解决方案,应对DOE在科学发现、清洁能源、国家安全和与国立卫生研究院(NIH)的国家癌症研究所(NCI)合作的精准医疗计划等方面所面临的具体挑战。
2.2 欧盟
2.2.1 ETP4HPC与欧盟高性能计算战略研究议程
欧洲高性能计算技术平台(ETP4HPC)在欧洲HPC生态系统中发挥着“研发新技术、提升社会经济效益、协调机构与项目间合作”等多重关键作用。2013年12月,ETP4HPC与欧盟委员会签订合同制公私伙伴关系(contractual Public-Private Partnerships,cPPP),欧盟“地平线 2020”(H2020)计划对HPC投资7亿欧元,而ETP4HPC也将提供匹配研发资金。2015年9月,ETP4HPC与PRACE联合启动为期30个月的“欧洲极限数据与计算行动计划”(EXDCI),以促进欧洲HPC生态系统中关键机构和项目之间的合作。
2015年11月,ETP4HPC发布2015年版HPC战略研究议程(SRA)[8],旨在提出欧洲百亿亿次计算的路线图。该议程在原有的六大重点领域外,还提出了新的技术领域和新的概念,以及HPC技术研发四维度(图1),具体包括:1)新技术研发,为更广泛的HPC市场提供更多具备竞争性和创新性的HPC系统;2)通过为新技术提供增强的、合适的特性,解决极限规模需求;3)开发新的HPC应用,包括复杂系统(如电网)控制、云模型、大数据等;4)通过HPC技能培训和服务支撑,提升HPC解决方案的可用性。
2.2.2 欧盟HPC公私合作伙伴关系
2013年12月,欧盟委员会针对八个领域宣布与欧洲产业界建立合同性公私合作伙伴关系(cPPP)[9],并通过“地平线 2020”计划提供 62亿欧元,其中HPC cPPP获得7亿欧元的资助,用于携手技术供应商和用户开发下一代百亿亿次超级计算机技术、应用和系统。其预期成果是:制定对产业竞争力、可持续发展、社会和经济效益具有显著影响的研究与创新战略,促进涵盖整个产业链的HPC生态系统,通过提供HPC资源和技术使用的便利条件来扩大用户群。

图1 HPC技术研发四维度Fig.1 Four dimensions of HPC R&D
2016年5月,欧盟根据其2016—2017工作计划,发布H2020计划HPC领域招标公告,此次招标属于未来新兴技术(FET)前瞻计划的一部分,旨在利用从千万亿次向百亿亿次计算过渡中出现的新机遇,创建下一代极限性能计算。
2.2.3 欧盟1.4亿欧元资助多个HPC项目和卓越中心
2015年9月,欧盟宣布投资1.4亿欧元,资助21项“迈向百亿亿次高性能计算”的HPC项目并新建8所面向计算应用的卓越中心。其中三个项目——ExaNest,ExaNode和 ECOSCALE于2016年底合作完成了ARM64+FPGA架构的百亿亿次超算机原型。
2.2.4 欧盟框架计划百亿亿次计算项目研究进展
欧盟希望在2022年前能建造3台全球顶级的超级计算机,为此H2020之前的FP7框架计划(2007—2013)资助了8项百亿亿次计算研究项目,且在2011—2016年间投入的资助超过5000万欧元。这些项目主要用于解决算法和应用开发、系统软件、能源效率、工具和硬件设计等方面的挑战。
2016年9月,欧盟委员会发布百亿亿次计算研究概述报告[10],回顾了FP7所资助计算项目的研究进展,包括:CRESTA,百亿亿次软件、工具和应用的合作研究;DEEP/DEEP-ER,动态的百亿亿次入口平台及其拓展;Mont-Blanc I+II,面向节能HPC的欧洲路径,目前已经进入第三阶段,计划在2019年前设计出一个新的高端HPC平台,能以更低的能耗、更高的性能运行真实应用;EPiGRAM,百亿亿次编程模型,在消息传递接口(MPI)并行编程设计中引入和实现新概念,以实现MPI在执行时间和内存消耗方面的可扩展性;EXA2CT,百亿亿次算法与先进计算技术;Numexas,面向工程和应用科学中关键百亿亿次计算挑战的数值方法和工具等。
2.3 日本
2013年12月,日本文部科学省推出百亿亿次超级计算机研发项目,旨在保持日本在计算科学和技术领域的领先优势。新的超级计算机“后京”(Post-K)预计于2020年投入使用,速度将是日本现有最快超级计算机“京”的100倍。
新的百亿亿次超级计算机研发被文部科学省列为“旗舰2020计划”(Flagship 2020 Project),由日本理化学研究所(RIKEN)的计算科学研究机构(AICS)负责实施。文部科学省2015年8月公布的2016年预算显示,该计划2016年获得了76亿日元的拨款,比前一年的39亿日元增加了近一倍。
“后京”的研发秉持四项基本的设计方针[11]:能解决实际的社会和科学问题;在能效方面具备国际竞争力;最大程度地利用前任“京”确立的技术、人才和应用;2020年以后也能针对半导体技术的发展实现有效的性能扩展。基于这四项方针,“后京”的开发将通过系统与应用的协同设计(Co-design)进行,一是开发下一代超算系统“后京”,二是面向“后京”的使用开发相应的应用,以解决革命性新药开发、生命科学计算、灾害预测、气象预测、绿色能源系统实用、宇宙演化分析等9项重要的社会和科学问题。
“后京”的开发分为四个方面:架构开发、协同设计推进、系统软件开发、应用开发,AICS为此设立了4个专职研发团队。从预定的计划来看,“后京”的研发将在2018年完成制造并开始量产,2019年进行设置和调整,2020年投入运行。不过,2016年9月在美国奥斯汀举行的HPC用户论坛上,该项目负责人——RIKEN的石川裕表示,正式运行的时间可能会延后1~2年,但并未说明延后的原因。有报道称,可能是由于半导体设计问题导致的CMOS制造技术尚不成熟,或者是芯片开发的时间比预期要长[12]。
2.4 法国
法国的新一代超级计算机研发主要是通过国立科研机构与企业的合作开展,部分研发项目如下:
法国布尔公司(Bull)于2014年11月公布其百亿亿次计算的研发计划[13],在提高处理器运算速度和数据处理能力的同时,开发超快的互联技术和更好的冷却技术,提高能效,并从根本上重新设计软件。该计划拟开发一台开放式、高度模块化并具有最顶级互联能力的百亿亿次超级计算机SEQUANA及其配套的软件栈,以及一系列具有超高内存性能,支持内存数据库、预处理、后处理和可视化等操作的服务器。
2015年7月,法国源讯公司(Atos)与法国新能源与原子能委员会(CEA)签订合同,约定于2020年向CEA提供百亿亿次超级计算机“Tera1000”[14]。系统的第一部分组件已在 2015年4月交付,原型系统也在2017年建成并投入运行,其理论峰值达到9.3千万亿次/秒、实测峰值达4.9千万亿次/秒(2017年11月)。CEA军事应用科为其开发了一套生态系统,使其能够基于Atos的高性能计算技术提供具有竞争力的、耐用的、符合自身需求的超级计算能力。
2015年8月,IBM和法国国家大型计算中心(GENCI)宣布将开展一项合作,充分利用Open-POWER联盟带来的创新技术,以及IBM基于OpenPOWER生态系统开发的最先进HPC技术,加快迈向百亿亿次计算的步伐。该合作得到POWER加速设计中心的支持,主要致力于为超算系统编写复杂的科学应用,这些系统的运算速度有望超越十亿亿次级并迈向百亿亿次级。此项合作将多点接口技术和共享存储并行编程技术作为共享内存多处理器编程的第一步,致力于理解编程模型的进化。由于系统迈向百亿亿次的过程中可能出现潜在变化,此项合作也将考察多种应用程序接口。
3 高性能计算面临的挑战与趋势
3.1 计算性能的提升
2015年10月,美国计算社区联盟(CCC)在《下一代计算的机遇与挑战》报告[15]中指出,目前气候建模与仿真等超算应用的精度受限于计算能力。各国都在大力研发下一代的百亿亿次计算,但科研界担忧超算应用是否能跟上百亿亿次计算硬件的发展步伐,一个主要的困难就是没有人确切地知道未来的百亿亿次计算架构。多位科学家认为[16],超算应用面临着正式建模、静态分析与优化、运行时分析与优化、自主计算四大关键挑战,并建议基于百亿亿次系统目前的假设和可用的数据,采取逐步改进的方式将现有超算应用移植到未来的百亿亿次计算系统上。
3.2 能耗的降低
随着高性能计算机的速度日益提升,能耗成为一个亟待解决的关键问题。各国目前制定的百亿亿次计算规划基本将系统功耗目标设定为20MW。但从目前各方面的技术水平来看,要在2020年左右实现这一目标仍存在相当大的困难。目前最“绿色”系统为日本理化所研制的Shoubu system B(2017年11月 Green500排名第一),其能效为17 GFlops/w。由此推算,百亿亿次计算系统的功耗将达到58.8MW,距离既定的能效指标尚有近3倍的差距。
2015年4月,在美国NSF与半导体研究联盟(SRC)联合举行的高能效计算研讨会上,与会专家展望了高能效计算研究的机遇。例如,相变的控制对研发能在极低压下工作的计算设备而言是一条潜在的途径,传导则是其他有前景的低功率开关机制之一。在储能线路中部署绝热开关也是改善能效的一条途径。此外,需要更多的关注更高级的架构。例如,磁滞设备具备非易失性逻辑与存储功能,可以改善现有架构的性能;线性与非线性光学设备和紧凑型光发射器近年来在小型化与能效改善方面都获得了巨大进步。其他架构研究领域也可能利用新兴的设备理念来大幅提升计算能效。相关研究主题包括:异构系统的架构、最大程度减少数据移动的架构、神经形态架构、新的随机计算方案、近似计算、认知计算等。
3.3 软件与算法的开发
GPU已经大幅提高了计算能力,但对新软件和新算法的需求仍然迫切,一些重要问题包括:随着晶片上集成的晶体管数量急剧增加,摩尔定律可能失效的推测将促使计算架构发生重要变化,这就需要新的软件和算法能来帮助新的计算架构发挥最大效用;放宽对计算精确度“近乎完美”的要求可能开创一个“近似计算”的新时代,从而更好地解决系统故障。任何对网络基础设施的投资都需要考虑到软件的更新和重新开发,算法、数值方法、理论模型的创新对未来计算能力的提升可能发挥重要作用[17]。另一方面,开展应用数学研究对促进软件与算法开发也非常重要。只有在应用数学方面取得进展才能开发出高性能应用程序,从而应对百亿亿次计算面临的大量科学与技术挑战。美国著名计算科学家杰克·唐加拉(Jack Dongarra)建议美国能源部“先进科学计算研究”项目(ASCR)优先开展针对百亿亿次计算的应用数学研究,以帮助DOE保持在先进计算方面的优势,包括:对新模型、抽象化、算法的研发投入大量经费,以充分利用百亿亿次计算的巨大性能;利用应用数学方法寻找平衡点,以准确区分各项研究是否需要百亿亿次计算支持。
3.4 硬件架构的发展
硬件架构将更趋多样化,分别以提升运算性能、能效和数据密集型处理能力为目标的各种架构会陆续出现。处理器由多核向众核发展,2016年6月的Top500中96套系统使用了众核加速器技术,其中86套使用了协处理器,另外10套使用了最新的Xeon Phi“Knights Landing”处理器作为主要的处理单元,它们是Top500上首批将众核技术作为独立处理器使用的系统。就互连技术而言,206套系统采用了千兆以太网技术,187套系统采用了InfiniBand技术,28套系统采用了Intel Omni-Path技术,该技术在2016年6月的Top500榜单上首次出现。
此外,后摩尔时代的新型计算架构是重要研究热点。《2015国际半导体技术发展路线图》认为,在经历50多年的不断小型化发展之后,晶体管体积将在2021年停止缩减,届时摩尔定律将失效,该路线图自2016年起也已停止更新。2016年3月,英特尔宣布延长处理器研发周期,将传统的研发周期从“制程-架构”的两步战略变为“制程-架构-优化”的三步走战略,业内认为这一策略的转变意味着摩尔定律正式终结。
随着摩尔定律的终结,各国政府、企业和学术界都在加大力度研发新一代的计算架构。例如,IBM公司在2014年7月宣布,将在未来5年投资30亿美元推动计算技术的发展,其中就涉及面向后硅时代的量子计算和神经形态计算研发;2015年1月,美国空军研究实验室提出了2015—2030年在超级计算领域的研发目标,长期目标之一就是实现量子计算、神经形态计算和生物计算等新型计算模式与硬件的集成;美国高级情报研究计划局正在致力于超导超级计算(包括低温存储)的研究;此外,美国桑迪亚国家实验室正在开展一项名为“超越摩尔定律计算”的计划,以开发后摩尔时代的计算技术[18]。
4 我国高性能计算战略部署、进展与提升空间
4.1 我国百亿亿次计算战略部署
为进一步在与各国的高性能计算竞争中取得先机,我国将百亿亿次(E级)超级计算机及相关技术的研究写入了国家“十三五”规划,希望在2020年左右实现这一宏伟研究计划。在2016年启动的国家“十三五”高性能计算专项课题中,国防科技大学、中科曙光和江南计算技术研究所同时获批开展E级超级计算原型系统的研制工作,形成了“三头并进”的局面,拟通过赛马机制打造我国自主的E级超算系统[19]。
该专项总体目标是:在E级计算机的体系结构,新型处理器结构、高速互连网络、整机基础架构、软件环境、面向应用的协同设计、大规模系统管控与容错等核心技术方面取得突破,依托自主可控技术,研制适应应用需求的E级高性能计算机系统,使我国高性能计算机的性能在“十三五”末期保持世界领先水平。
4.2 我国高性能计算研制与应用进展及提升空间
4.2.1 研制能力显著增强
2016年11月公布的第48期全球超级计算机500强(Top500)榜单上,使用中国自主芯片制造的“神威·太湖之光”以较大的运算速度优势轻松蝉联冠军,“天河二号”排名第二。中国超算总体表现出色,以171台上榜数量与美国并列第一。这见证了中国和美国并驾齐驱的超算优势,也反映了中国超算的快速崛起。
在一年后(2017年11月)发布的第50期Top500榜单中,我国“神威·太湖之光”和“天河二号”依旧占据前两名,其中“神威·太湖之光”的核心部件全部为国产,凸显中国在超算领域的自主研发能力。在入围Top500的系统数量方面,我国首次以显著优势领先美国(202套:143套),呈现出全面爆发趋势。在计算资源总量上,我国占到榜单上所有HPC系统总和的35.4%,高于美国的29.6%。
值得注意的是,我国HPC的研制能力已显著增强,除了国防科技大学、江南计算技术研究所先后研制出最快超算系统外,在第50期Top500榜单中,联想、浪潮、曙光等3家中国厂商所研制的HPC数量依次排名第二、第三和第五,与美国惠普(第一)和Cray(第四)共同构成全球第一梯队。另一方面,美国在Top500榜单上的成绩已跌至历史最差。但从HPC研制企业与核心技术看,美国依旧牢牢占据优势。最新Top500榜单上有471套HPC使用了英特尔的芯片,比6个月前增加了7台,另有14台采用IBM的芯片。
4.2.2 多领域应用获得丰硕成果
随着我国高性能计算的研制不断取得进步以及相关学科快速发展,我国高性能计算的应用在近年取得了丰硕成果,有较大国际影响的包括:
1)千万核可扩展大气动力学全隐式模拟
在2016年11月美国盐湖城举行的2016年全球超级计算大会上,中国凭借“千万核可扩展大气动力学全隐式模拟”研究成果一举获得“戈登·贝尔”奖。该研究由“神威·太湖之光”提供运算支撑,可有效开展全球公里级气象预报,与国际主流的大气动力模式相比,计算速度提升近10倍,与2015年获得戈登·贝尔奖的项目相比,计算效率提升10倍以上[20]。这是我国超算应用团队首次获得有着“超算应用诺奖”美誉的“戈登·贝尔”奖,标志着我国科研人员正将超级计算的速度优势转化为应用优势。
2)钛合金微结构演化相场模拟
钛合金制备工艺复杂,微观组织形成机制和规律难以通过实验获得,常借助于软件模拟。相场法能够模拟微观组织的演化过程,广泛应用于新材料的设计。基于“神威·太湖之光”,中科院计算机网络信息中心自主开发了基于可扩展紧致指数时间差分算法库的相场模拟软件ScETDPF,支持计算材料科学、计算物理、计算生命科学等学科的科研模拟。
该研究由网络中心和中科院金属研究所合作开展,首次实现了国际最大规模的钛合金微结构粗化相场模拟,显著加快了我国新型钛合金的设计和工艺优化。计算扩展到800万核,实现整机规模计算,最大性能达到39.678 PFlops。该应用也入围2016年“戈登·贝尔”奖提名。
3)高分辨率海浪数值模拟
对于海洋模式模拟而言,分辨率的提高会带来计算量的大幅提升。如果水平分辨率提高10倍,模式的计算量将增加数百乃至上千倍,是未来E级计算机系统的驱动应用。
国家海洋局第一海洋研究所、青岛海洋科学与技术国家实验室与清华大学合作,在“神威·太湖之光”超级计算机实现了(1/60)°高分辨率的全球海洋模式,通过核加速、负载均衡、通信重叠和指令流水等优化手段,模式成功扩展到了8,519,680核数,达到最高 30.07PFlops的峰值性能,获得了优异的扩展性与并行效率。该应用同样入围2016年“戈登·贝尔”奖提名。
4)非线性大地震模拟
基于“神威·太湖之光”的强大计算能力,由清华大学、国家超级计算无锡中心、山东大学、南方科技大学、中国科技大学、国家并行计算机工程技术研究中心组成的联合团队成功设计实现了高可扩展性的非线性大地震模拟工具。该工具充分发挥国产处理器在存储、计算、通信资源等方面的优势,可以实现高达18.9PFlops的非线性地震模拟,是国际上首次实现如此大规模下的高分辨率、高频率、非线性塑性地震模拟,对未来的地震灾害救援演习、预防预测等研究具有重要的借鉴意义。“非线性大地震模拟”赢得了2017年“戈登·贝尔”奖[21]。
4.3 我国高性能计算的提升空间及建议
我国高性能计算近年取得了巨大发展,既反映了国家经济实力和创新能力的提升,也说明当前我国的研发与生产需求都十分强劲,尤其是互联网领域对计算的旺盛需求大力拉动了我国高性能计算的发展。但是,一些核心技术仍未实现突破,加之建设、运营、市场化经验有限,导致实际发展与建设目标存在一定差距,依然存在较多提升空间。
4.3.1 构建“大”、“小”高性能计算创新生态系统
我国高性能计算的发展到了关键时期,必须要在此阶段建立起良好的生态系统,方可实现全面领先和持续性进步。从狭义上说,“小”的创新生态系统是要面向处理器研发系统软件、工具软件和应用软件,让处理器得到广泛应用。而“大”的创新生态系统是指产业界、学术界和应用部门之间的协调,即把系统研发、应用研发和整个计算基础设施的研发整合起来,真正形成具有世界竞争力的科学产业和基础设施。需要通过在教育、研究和产业各个领域更好地开展合作来建设这更大的创新生态环境[22]。
4.3.2 改善科研院所高性能计算设施建设
尽管我国入围Top500榜单的高性能计算机数量已大幅超越美国,但其中大部分都排在榜单的后半部分,并且大多被部署在互联网公司、云服务提供商、电信运营商、电力公司和政府部门,用于尖端研发的寥寥无几[23]。与此相对应的,美国大多数高性能计算机被部署在国家实验室、大学以及研究机构中,从事最尖端和前沿的研究。中国的大学和研究机构需要高性能计算设施,应当加大在这方面的投资。
4.3.3 突破软件瓶颈,释放高性能计算设施价值
高性能计算机的寿命通常只有5~7年,并且运行维护费用很高,因此必须快速研制出相关应用程序,才能最大程度发挥其价值。我国高性能计算长期重“硬”轻“软”,导致基础并行环境、基础算法、高性能数学库、操作系统等基础与应用软件的发展落后于计算机系统的发展,进而导致我国高性能计算设施难以充分发挥作用[24]。目前,我国许多研究机构、高等院校大量使用国外商业软件、开源软件,并导致诸多困难:一些软件甚至只是目标程序,很难对物理模型、计算格式、算法进行调整、改进;计算规模受限制;计算精度、分辨率不高;关键应用受到限制。
要使高性能计算在实际应用中真正成为科技创新的重要手段,就必须坚持对基础与应用软件和高性能计算机系统的统筹规划、均衡投资、协调发展。建议成立若干国家并行软件工程中心,统筹、协调全国各行业并行软件的研究、开发、推广和应用,同时采用自研、开源、共享等多种手段,解决国产软件缺乏和市场占有率低的问题。
4.3.4 大力培养高素质跨学科人才
高性能计算是一门典型的交叉学科,其内容涉及计算机科学、计算数学、行业应用知识。我国高性能计算的研发人才已具备相当实力,但应用人才相对短缺,特别是缺乏应用软件和系统软件方面的专业人才。主要原因在于培养相关人才的门槛高、专业性强,学科交叉协作还未形成风气,缺乏鼓励学科交叉合作的具体机制和组织保障[25]。
因此,培养高素质跨学科人才显得尤为迫切。应建立长期的人才培养战略,通过科普让更多年轻人接触、了解高性能计算,同时扩大设置“高性能计算理论+多学科应用课程”的高校范围,加大对“懂计算懂专业”的复合型人才培养力度,大力推动该领域多学科的交叉融合。要加强课程建设、师资队伍建设,还要拓宽人才培养渠道、结合实践培训用户来解决人才不足问题。
