浅谈数据挖掘在高职院校学生成绩预警中的应用
2018-08-11朱敏朱珍元张林静
朱敏 朱珍元 张林静

【摘要】随着大数据技术的发展及对此认识的提高,愈来愈多的人开始利用大数据来获取有价值的信息。我国高职院校的不断扩招使得高职院校教育系统中的数据规模愈来愈庞大,教师想要从其中获取自己需要的信息愈来愈困难。鉴于这种情况,利用大数据挖掘中的Apriori 算法,通过对高职院校学生成绩信息的收集、分析以及处理,根据预设支持度与置信度找出数据库中具有联系和不同可信度的课程成绩作为关联规则,将关联规则应用到学生成绩预警中去,从而形成对成绩处于危险状态的学生进行预警的反馈机制。
【关键词】数据挖掘 关联规则 Apriori算法 学生成绩 预警
【基金项目】安徽省2017年度高校自然科学研究项目重点项目(项目编号KJ2017A639);安徽省2016年度高校自然科学研究项目重点项目(项目编号KJ2016A167)
【中图分类号】G712 【文献标识码】A 【文章编号】2095-3089(2018)13-0047-02
本文將通过收集计算机网络专业学生主干课程的考试成绩,然后对这些数据实施统计、分析以及处理。通过这一过程学校会对某一些不及格课程科目数比较多、可能无法按时毕业或者无法取得毕业证的学生进行预警,以便于督促这一部分学生更加努力地进行学习。我们都知道,相同的专业不同课程间肯定具备着一定的关系,本文就是在基于使用数据挖掘技术对高职院校学生得考试成绩进行统计、分析以及处理的基础上,深度发现不同科目成绩间的关联性,探索出他们之间的逻辑关系,进一步掌握学生学习状态,更好的对学习成绩处于危险状态的学生进行预警,督促学生更好的进行学习,提升他们的及格率以及毕业率。
一、数据挖掘技术与常见算法
数据挖掘(Data Mining)就是有组织性和目的性地搜寻数据,通过对这些数据进行分析使之成为信息,从而寻找潜在规律以形成发现有价值的非同寻常的新信息和知识的过程,数据挖掘填补了数据和信息之间的鸿沟。
数据挖掘是一个在大数据上进行的自然行为,数据挖掘算法是大数据分析的核心部分,要科学表现大数据的特点就需要针对这些数据的类型及格式制定相应的算法。这些算法可以说是基于统计学的统计方法,也只有这样,挖掘出来的数据才具有相应的价值,同时算法在处理数据速度方面起到了关键的作用,若一个算法需要很长时间才能获得结论,那么大数据的价值也就无从谈起。数据挖掘的主体没有限制,主要是将现有数据通过数据挖掘算法进行预测性分析,进行一些高级别的数据分析,可利用Mahout工具实现。下文列举一些比较常用的数据挖掘方法。
MBR(Memory-Based Reasoning),这是一种基于历史的分析方法,利用已知的case(案例)来预测未来case的一些attribute(属性),即先根据知识和经验寻找相类似的情况,然后将这些情况的信息应用于现在的例子中。具体MBR首先寻找和新记录情况相类似的邻居,然后利用这些邻居对新数据进行分类和估值。使用MBR有三个亟待解决的主要问题,寻找确定的历史数据;决定表示历史数据的最有效的方法;决定距离函数、联合函数和邻居的数量。
Decision Tree(决策树),此算法主要是对未知数据进行分类或预测,它以法则的方式即一连串的问题来表达,再通过不断询问最终导出所需要的结果。典型的生成决策树的方法是采用自顶向下的方式在部门搜索空间中搜索解决方案。它着眼于从一组无次序的、无规则的事例中推导出,该技术主要是用于预测和决策,在商业、科研、工业等领域具有广泛的应用。
Cluster Detection(聚类分析),又称为群分析,古人云:“物以类聚,人以群分”,描述的正是这类算法。它是一种广泛应用于研究分类问题的数据挖掘方法,主要是在没有给定具体划分类即未知类的情况下,找出数据当中以前未知的相似群体。经常被用来提供不同类对象特征的报告。目前已经在许多领域 中有广泛地应用,包括模式识别、图像处理、模式分析以及市场研究。
除上述方法外还有购物篮分析、遗传算法、OLAP分析、连接分析、神经网络、判别分析等等,在此不做一一介绍。
二、数据挖掘技术在相关领域的应用
数据挖掘的最中目的是要实现数据的价值,而商业智能是在企业中实现数据价值的最佳方式之一。数据挖掘能力将成为一个企业未来的核心竞争力,并且挖掘能力将成为一个衡量企业业务水平高低的重要指标,通过数据挖掘以及数据分析抓住用户特点,只有这样才能实现大数据的真正价值,实现商业价值。它的蓬勃发展正是由于它在各个领域的广泛应用,一般较常见的应用案例发生在营销领域的零售业、直效行销界、制造业、财务金融保险、通信业、医疗服务业以及各种政府机关等。
在众多的应用案例中,数据挖掘在营销领域的应用应该是最为广泛的。数据挖掘可以从销售的各项数据中发掘消费者的消费习惯,即通过交易记录找出顾客偏好的产品组合,以进行交叉销售(Cross-selling)、向上销售(Up-selling)。找出流失顾客的特征和新产品的时机点等也都是数据挖掘在零售业中常见的应用。
数据挖掘在金融业中也有着充分的应用。例如,股票交易商可以利用数据挖掘来分析时长动向,并预测个被公司的营运状况以及估价走向等;又例如,采用数据挖掘中的关联规则挖掘技术,我们结业成功预测银行中不同客户的需求,一旦获得了这些信息,银行就可以改善对不同客户的服务项目。
三、数据挖掘技术在学生成绩预警中的实践分析
(一)关联规则算法:Apriori 算法
1.关联规则
设 I{I1,I2,…I}为所有项目的集合,设与任务相关的数据库DB是数据库事务的集合,其中每一个事务T是项的集合,使得TI。每一个事务都关联一个标识符,称作TID。假设A是一个由项目组成的集合,称为一个项集,事务T包含项集A,当且仅当AT。如果项集A由k个项目组成,称为k项集。项集A在与任务相关的数据库DB中出现的次数占DB中总任务量的百分比叫做项集A的支持度。如果项集的支持度超过用户给定的最小支持度阈值,就称该项集是频繁项集。关联规则是XY的逻辑蕴含式,其中XI,YI,且XY=φ。如果数据库DB中有s%的事务包含X∪Y,则称关联规则XY的支持度为s%,若项集X的支持度记为support(X),规则的置信度为support(X∪Y)/support(X)。由此可见,支持度表示模式在规则中出现的概率,置信度表示规则的可信性,置信度越高表明规则越有价值。通常人们只研究支持度高的关联规则,具有高置信度和强支持度的规则成为强规则。即support(X∪Y)=P(X∪Y),confidence(X∪Y)=P(Y|X),同时满足最小支持度阈值(min_support)和最小置信阈值(min_confidence)的规则称作强规则。关联规则数据挖掘的基本任务是发现大型数据库中的强规则。
2.Apriori 算法
Apriori算法作为关联规则的标准方法,具体挖掘程序如下:
(1)提前设定好系统的最小支持度阈值,然后选择使用迭代的方式来对数据库中涉及到的项目集进行快速检索,从而发掘出位于此范围之内的数据库相关项目组,即找出所有频繁项集(Large Itemsets)。频繁项集的意思是指某一项目组出现的频率相对于其他项目组而言,必须达到某一水平。
(2)系统地分析由上一步骤频繁项集产生的所有关联规则,并选择置信度大于用户给定阈值的关联规则作为强关联规则,即这些规则必须同时满足以上两个条件最小支持度和最小置信度。
(二)Apriori 算法在学生成绩分析中的应用
1.数据的预处理
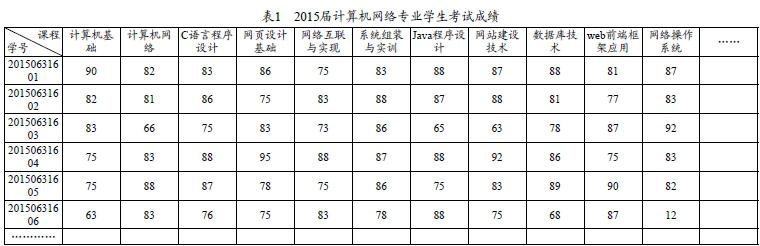
本文以某高职院校2015届计算机网络专业学生的考试成绩来作为对象进行研究,工作人员获取学生的成绩单之后,采用关联规则算法对学生的卷面考试成绩以及不同科目之间的关系进行深度挖掘。学生的成绩如下表1所示,其中包含2015届计算机网络专业学生全部专业课程与选修课程的成绩。
(1)科目的选择
通常来讲,高职院校学生在公共选修课的选择上具有非常大的自由度,有可能一个班级仅仅有一两名同学选择某一门课程,也就是说数据集中会出现独立的一个事务涵盖这一项目,这种状况是与关联规则的相关需求相冲突的。从2015届计算机网络专业学生的考试成绩中我们可以得知,在同一个班级中多数同学共同选修一门选修课的状况几乎不存在,因此不把该专业学生的选修课成绩划入数据来源中,也不会对这一部分成绩进行挖掘分析。所以,我们主要是针对学生的必修课与专业选修课成绩范畴的数据库进行研究。
(2)成绩的离散化处理
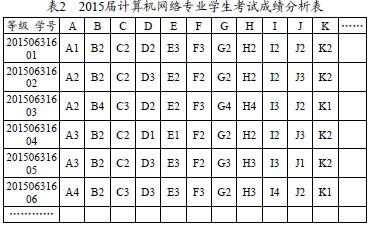
2015届计算机网络专业学生成绩表中的成绩体现为百分制,所以在进行数据处理时应该对其开展统一化处理。本文中将学生的成绩划定为四个范围,分别为1/2/3/4。成绩高于或者等于90分的学生,划入范围1;成绩低于90分且高于或者等于80分的学生,划入范围2;成绩低于80分且高于或者等于60分的学生,划入范围3;其他划入范围4。本文选择该专业的15门课程来开展分析,这些课程用大写英文字母来表示,依次为A、B、C……O。
2.数据的处理
(1)数据的转化
按照数据预处理程序中设定的方式对2015届计算机网络专业学生考试成绩进行转化,结果如下表2所示:
(2)数据的统计
由于部分學生会进行补考或者申请延后考试,所以从教务处中获取的学生成绩单会不可避免的存在重复或者空缺问题。在数据统计过程中,对于出现重复的成绩,在统计时选择第一次考试成绩;对于空缺的问题,将其成绩统计为0。统计离散化后的成绩如下表3所示:
通过表3的统计结果我们能够得知,该班级学生部分课程成绩会在某一个范围进行集中,比如,2015届计算机网络专业1班中共有学生总人数为22,但是有16名学生的“网络操作系统”这一课程成绩处于范围4之中,其他范围的学生人数为6人,占比为6/22,即关联规则的最小支持度不到三分之一。设定关联规则的最小支持度为0.33,当某门课程等级的学生达不到6名时,将他们排除在候选数据挖掘数据库中。通过统上述计,得到下表中以0.33作为最小支持度筛选的数据。
3.算法实现
对所有数据处理完成后,选择使用关联规则典型算法Apriori对它们进行挖掘。本文的所有挖掘算法操作均是在Windows 7系统及MAT-LAB2015a环境下进行的,设置的最小支持度为0.33,最小置信度为0.5,得到347个频繁项集,562条关联规则。对部分结果进行分析可知课程A(计算机基础)、课程E(网络互联与实现)、课程F(系统组装与实训)存在着两两相关、相互制约的关系,学生的成绩普遍较低,课程C(C语言程序设计)与课程G(Java程序设计)、课程D(网页设计基础)与课程H(网站建设技术)也存在着两两相关、互相影响的关系。通过对数据库的检索,可以找出符合这些关联规则的学生名单,由辅导员负责对这部分学生发出预警通告。
四、结语
总而言之,数据挖掘应用于高职院校学生成绩预警工作中,能够有效的提升学校对学生成绩的管理,同步对那些成绩处于危险状态的学生进行预警反馈,督促他们尽快调整学习态度以完成相关学业要求,对于提升学校的教学水平和学生的毕业率具有重要意义。
参考文献:
[1]陈苗,马燕. 数据挖掘在高职院校学生成绩预警中的应用研究[J]. 电脑知识与技术,2017,13(2):204-206.
作者简介:
朱敏(1989-),女,安徽合肥人,安徽警官职业学院教师,研究方向:数据挖掘、大数据分析;朱珍元(1985—),女,湖北黄冈人,安徽警官职业学院教师,研究方向:语义Web、数据挖掘、移动互联网;张林静(1988—),女,安徽合肥人,安徽警官职业学院教师,研究方向:计算机应用。
