一种改进的延时调度算法
2018-08-10王钟斐王钟磊
王钟斐,王钟磊
(1.宝鸡文理学院数学与信息科学学院,陕西宝鸡721013;2.成都银行四川成都610000)
近年来,随着互联网应用的飞速增长,海量数据的存储以及处理问题得到广泛的关注。基于这一背景,云计算[1-3]应运而生,该新兴的商业计算模型以网络技术、虚拟化技术、分布式计算技术为基础,以按需分配为业务模式,具备动态扩展、资源共享、宽带接入等特点[1]。
当前大多数云计算系统都采用Hadoop平台[4-6]来开发和调试程序,Hadoop项目是由Doug Cutting领队开发的开源框架。Hadoop平台中的作业调度器是以可插拔的方式加载的,目前Hadoop发布版本中的主流调度器有3种:先进先出调度器(First In First Out Scheduler)[7-9]、公平调度器(Fair Scheduler)[10-11]以及计算能力调度器(Capacity Scheduler)[12-14]。其中,FIFO为Hadoop的默认作业调度器,这种调度算法简单明了,但在某些特殊情况下,本地化任务[15-16]不能充分实现。
文中从Hadoop主旨出发,设计了旨在增加本地化任务比率并减少作业响应时间的改进算法。通过分析各个作业的作业时间敏感度指标并进行排序,本文算法优先选择时间敏感度高的作业及任务进行资源分配,同时,引入延时的调度思想,以能够获得更大比率的本地化任务,并且显著缩短作业的响应时间。实验结果表明,使用本文改进算法可以显著降低作业的响应时间。
1 问题的提出
先进先出调度算法(FIFO)为Hadoop的默认作业调度器,适用于在集群中运行单一作业。该算法简单明了,而且JobTracker的工作负担比较轻,但是它也存在以下不足之处。
首先,它遵循严格的FIFO作业顺序来分配任务,这意味着,假如队列中第一个作业还有未被分配的map任务,那么队列中的其他任何作业任何任务都得不到分配。这种缺陷在数据本地性方面也会有很大影响,即便队列中其他作业的任务在某个节点上有多个输入数据块,这些任务在第一个作业所有map任务被调度前,都得不到调度。其次,由于数据本地化是由工作节点的心跳信息序列随机决定的。即工作节点根据自己完成任务的进度以及自身的空闲任务槽情况,发送相关信息给主机节点并请求任务分配,由于集群中节点众多,而且运行情况各异,因此数据本地化的具体信息不能事先估计。
文中考虑到小规模集群系统中短作业比较多、数据规模处理不大的特点,提出了一种改进的延时调度算法。该算法有两个特点,一是优先选择时间敏感度高的作业及任务进行资源分配,这可以优先分配资源给交互型的短作业;二是根据优先级的不同决定每个作业的等待时间,这样可以获得更大比率的本地化任务,并且显著缩短作业的响应时间。
2 改进的延时调度算法
针对原有调度算法在特殊情况下,本地化任务不能充分实现的问题,本文从Hadoop主旨出发,设计了旨在增加本地化任务比率从而减少作业响应时间的改进算法。算法的主要思想是:在执行某个作业的非本地化任务之前,都有公平的机会获得该作业本地化任务。即该算法的中心思想是为每个作业在合理的等待时间内找到一个本地化map任务。
对于短作业的优先调度目标,引入作业进度时间敏感度,即单位时间内作业的进度增加情况。显然,作业进度时间敏感度越高,说明进度对时间的敏感程度越高,这时若该作业等待调度时间越久,则会严重影响到该作业的执行性能,这种延时在交互型作业中更加不可忍受。举个例子:假设我们有两个作业A和B,A是科学计算的作业,在10 s时间中,进度增加了1%,那么说明此刻,该作业的作业进度时间敏感度为0.001,该作业的预期完成时间为1 000 s;而作业B是一个交互型作业,在2 s的时间内,已经运行了50%,那么该作业的PTU值为0.25,预期完成时间为4 s,在这样的情况下,如果A作业延时10 s调度,则不会给作业所属的用户带来非常明显的作业响应滞后的感觉,而如果B作业延时10 s调度,这时云计算的用户体会非常糟糕。我们更关注在短时间内,进展速度快的作业应该优先得到执行,需要尽快分配集群资源响应该作业。因此,我们设计该指标计算公式如下:

公式中的f即调节因子,根据实际情况,调节作业优先级在该作业进度时间敏感度指标中的比重。
首先,该算法在进行任务分配时不必遵循严格的作业顺序。假如作业队列中第一个作业中没有本地化map任务,那么调度器会继续在后续作业中查找。其次,为了给每个作业公平的机会去获得自己的本地化任务,当某个作业等待一段时间T1后,还不能从具有空闲任务槽的节点中找到本地化任务,那么为了避免浪费集群的计算资源,本文提出的算法会分配该作业的一个非本地化任务。这样,该算法不仅能达到高本地化任务的比率,也能增加集群的高利用率。第三,按照作业时间进度的指标对作业进行排序,这样对于某些交互型的需要很快响应的作业,调度器能够优先调度并分配集群资源。第四,当某个新作业加入队列时,把该作业放在队首,优先给该作业分配定额的计算资源,随后该作业在队列中的位置则由该作业的作业时间敏感度值所决定。
优化调度算法的执行示意图如下所示:
1)在0:00时,集群现状如图1所示。
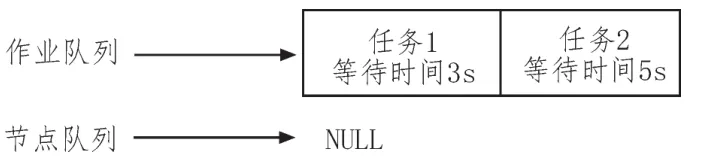
图1 某时刻集群现状
2)0:04 s时,由于此时任务1的等待时间为3 s,故分配该任务给节点A,该任务为非本地化任务,如图2所示。
3)0:08 s时,如图3所示任务3进入队列,则放入队首,同时,由于节点B具有任务2的本地化数据,将任务2分配至节点B,任务2为本地化任务。

图2 某时刻集群现状
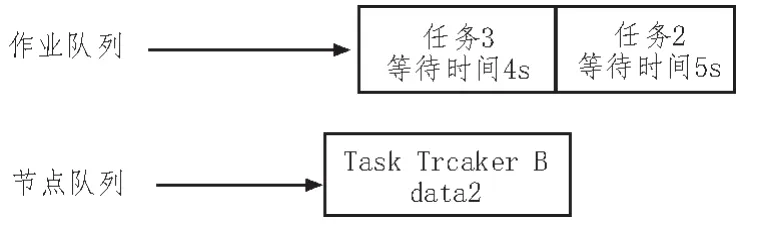
图3 某时刻集群现状
因此在优先响应短作业的前提下,通过对非本地化任务的延时调度,寄希望于具有本地化数据的节点在一定时间内向主控节点报告状态,从而使该非本地化任务编程本地化任务。
优化后算法的伪代码如下所示:

3 实验结果分析
测试数据:设定两组相同的任务,但输入数据规模不同,其中作业A处理数据为1 GB,作业B处理数据为64 MB,这样相对B而言,作业A为长作业,而B为短作业,因此作业B需要及时分配集群计算资源,尽快得到响应。
如图4所示,采用作业时间敏感度排序:当1 GB作业正在运行时,64 MB作业加入到作业队列,刚开始64 MB作业进展缓慢,这是前期集群在准备作业B的执行资源,随后由于B作业处理数据规模非常小,这时其作业时间敏感度相对较高,优先得到调度及计算资源分配,而1 GB作业则由于分配少量计算资源而相对执行速度较慢。

图4 作业时间敏感度因子对作业执行影响
未采用作业时间敏感度排序:1 GB作业和64 MB作业呈现竞争计算资源的情况,作业进度增加速率差别不大。
纵向比较同一个作业在不同情况下的执行结果:
采用作业时间敏感度排序:
64 MB作业:67 s
1 GB作业:252 s
未采用作业时间敏感度排序:
64 MB作业:102 s
1 GB作业:237 s
由上面数据可以看出:对于64 MB的短作业来讲,采用作业时间敏感度的作业运行时间比未采用作业时间敏感度的作业运行时间减少了35 s,减少百分比为34.31%,虽然这时的1 GB长作业运行时间增加了15 s,其增加百分比为6.33%。
因此,加入作业时间敏感度排序指标可以有效减少短作业执行时间,提高用户体验,而长作业虽然响应时间增加,但是增加不大,基本不会影响该作业的预期执行效果。
4 结 论
首先简要介绍了现有Hadoop平台的3种调度算法;然后提出现有算法的本地化任务不能充分实现的问题;为解决此问题,本文考虑到小规模集群系统中短作业比较多、数据规模处理不大的特点,提出了一种改进的延时调度算法;实验结果表明,本文的改进算法不但可以获得更大比率的本地化任务,并且能够显著缩短作业的响应时间。
