阵列处理器分布式存储的簇内全访问结构设计
2018-08-10蒋林,刘鹏,山蕊,刘阳
蒋 林,刘 鹏,山 蕊,刘 阳
(1.西安科技大学 集成电路设计实验室,陕西 西安 710054;2.西安邮电大学 电子工程学院,陕西 西安 710121;3.西安邮电大学 计算机学院,陕西 西安 710121)
0 引 言
随着计算机技术的发展,延用传统的方法,即通过提高处理器主频和指令集的并行性来提升处理器性能的方法已经不再适用[1-2]。随着集成电路制造工艺的改进,芯片的集成度显著增加,通过增加处理器的核数来提高处理器性能已经成为设计主流,多核处理器(MCP,Many-Core Processor)应运而生[3]。特别是文献[4]中提出了处理器的发展方向从原来的单核到双核、多核,再到现在的众核处理器,推动了体系结构向更高性能的发展。但是随着多核处理器内部计算核数目增多,集成的功能日益复杂,对主存的数据访问需求逐渐增加,且处理速度与存取速度失配所引发的“存储墙”问题[5-6]也随着工艺的进步而日益严重,成为制约处理器性能提高的重要因素。
目前针对日益严重的访存延迟和功耗,普遍的方法是处理器中采用多级Cache技术来缓解不断恶化的“存储墙”问题[7]。文献[8-10]中都采用了多级Cache技术来解决存储带宽带来的性能瓶颈。然而,多级Cache结构需要附加电路才能完成地址映射,保证数据的一致性,而且,随着Cache在处理单元或者处理系统中的增加,Cache的一致性保证也相对难以满足,会加入额外复杂的一致性保证算法[11]。特别是Cache一致性是存储系统的一个重要组成部分,被广泛认为是存储系统中最复杂的部分之一[12]。文献[13]中为了解决GPU中存储瓶颈问题,在GPU结构中采用了两级Cache技术,但是为了保证Cache一致性问题,结构中添加了更为复杂的硬件电路,使得设计更为复杂化。
采用多级Cache技术不仅仅会带来Cache一致性问题,而且还会给系统造成额外的功耗。随着集成电路工艺的不断进步,片上集成的处理器核数显著增加,多核处理器中Cache的数量也将增加,Cache所占片上面积越来越大,采用多级Cache存储结构不仅会增加电路的复杂度,而且会消耗更多的功耗[14]。文献[15-16]都是为了缓解多级Cache技术带来的功耗压力,对存储结构进行了优化,虽然优化后的功耗降低,但是多级Cache技术带来的额外功耗给片上低功耗设计要求带来了不小的挑战。除了功耗的额外增加以外,特别是针对目前相对复杂的算法,比如机器视觉、虚拟现实和人工智能等算法的映射过程中,存在着大量的数据级并行运算,多级Cache技术对此应用的效率比较差,不能满足实时性的要求[17]。
为了缓解“存储墙”给片上存储带来的压力,除了采用多级Cache技术还可以在片上采用分布式存储结构设计[18-19]。针对于复杂的片上网络(NOC,Network-on-Chip),存储结构采用分布式存储结构不仅可以灵活地适应于密集型应用,而且有利于开发者更加高效地开发和编程[20]。文献[21-22]都在存储结构上做出了优化设计,都采用了分布式存储结构,提高了访存的实时性,降低了访存延迟。为了解决片上多核处理器的“存储墙”问题,文献[17]中提出了统一编址方式下的分布式共享存储结构(UaDSMS,unified addressing distributed shared memory structure),逻辑上为共享存储结构、物理实现上为分布式存储结构。尝试采用统一编址方式,将分布式的存储块逻辑上关联起来,每个处理器通过统一编址方式下的地址信息直接访问片上所有存储块。从处理器角度看,片上存储结构为共享结构;而物理实现上,采用多个独立的存储块。采用“逻辑共享,物理分布”的优势在于,一方面免除了Cache中复杂电路的设计,减少了电路的复杂度,同时可以实现片上存储资源的合理高效利用;另一方面,可以满足高带宽和低延迟的实时性要求。例如,定义4×4个处理单元(PE,Processing Elements)为一个处理器簇(PEG,Processing Elements Group)分别对应4×4个存储块(MB,Memory Bank),如果PE与MB需要进行数据访问时,则只需要通过簇内的高速交叉开关实现,这样就可以满足簇内低延时、高速率的数据传输。针对分布式存储结构的簇内互连问题,目前簇内4×4个PE与4×4个MB互连基本都采用高速交叉开关的形式实现,文献[23]提出命名为行列交叉访问结构(LR2SS,Line Row two-stage Switch),这种结构虽然访问延迟降低,但是针对数据密集型的算法并不能很好的并行实现。本文针对这种结构做出优化,设计出一种访问延迟小、带宽高的簇内全访问(FS,Full- Switch)互连电路结构。
1 阵列处理器分布式存储结构
论文的工作基于可重构类数据流处理单元组成的阵列处理器,该处理器结构在提高非数据级并行计算效率的同时,多扇出输出端口能够为应用映射提供更大的灵活性和更高的性能[24]。阵列处理器中每4×4个PE组成一个阵列处理器簇,每个PE的访存数据位宽为16位,可以满足多种数据密集型算法的数据访问需求。簇内分布式存储结构如图1所示,其上层为4×4个PE组成的PEG,下层为4×4个512×16 bit大小的MB,中间层为高速访问单元——全访问结构(FS,Architeture)。从PE角度看,每个PE能够直接访问片上所有存储资源,是片上共享存储结构;物理实现上,采用多个独立的MB块,通过簇内全访问结构实现对本地存储单元优先访问,簇内远程存储单元次之的优先级策略,同时利用多个存储块的并行存储技术,实现了4×4个PE的并行访问。
簇内全访问高速互连结构是一种总线型互连结构,它是最直接且使用效率较高的互连方法,实现了4×4个PE与4×4个MB的交叉互连。当发生访问冲突时,全互连的交换结构能够对冲突的请求进行仲裁。当PE访问存储单元时,簇内存储结构接收来自PE的读写请求,根据地址判断是对本地存储单元访问还是对簇内远程存储单元访问,当PE访问本地存储单元时,由于其优先级最高,可无阻塞直接访问;当PE访问簇内远程存储单元时,簇内存储结构会根据访问的地址判断出所要访问的具体MB块,并选出对应的访问路径进行数据传输。

图1 分布式存储结构Fig.1 Intra-cluster distributed storage architecture
2 簇内全访问电路结构设计
分布式存储结构簇内PE与存储Bank之间的互连访问结构目前已有LR2SS结构[24],但是这种结构设计复杂,提供的访问带宽有限,针对密集型算法的并行化实现访问延迟还有优化的空间。总线型的全访问互连结构是一种利用率较高的互连方式,只要PE不同时访问一个MB,PE的请求将立即被响应,簇内全访问的结构如图2所示。全访问互连结构主要由decoding模块、arbiter模块、en_select模块、addr_select模块、data_select模块和ack_unit模块组成。
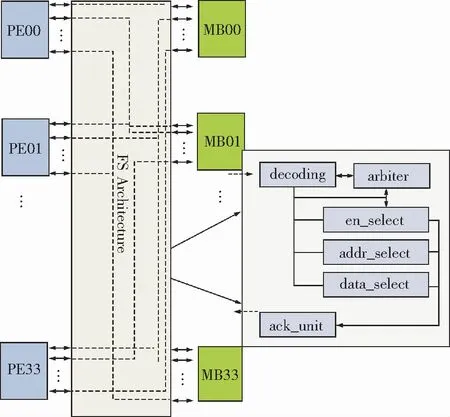
图2 簇内全访问结构Fig.2 Intra-cluster Full-Switch architecture
由于读过程和写过程相似,所以在这里以写操作为例描述各个模块的简要功能。
decoding模块:用16位的独热码表示簇内的16个PE,从低位到高位表示PE00-PE33.
arbiter模块:当多个处理单元写一个MB时,经过仲裁优先级选择正确的顺序进行写操作使能信号。
en_select模块:根据输入的地址选择,以及arbiter模块输入的使能信号选择正确的写使能信号。
addr_select模块:根据输入的地址信号和en_select模块输出的正确的写使能信号选择出正确的写地址信号。
data_select模块:根据en_select模块输出的写使能信号和addr_select模块输出的写地址信号,选择正确的写数据信号。
ack_unit模块:主要完成信号的反馈。当完成写操作时,将正确的信号反馈给处理单元,通知处理单元已经完成写操作。
3 硬件实现和算法的并行化映射
3.1 簇内全访问电路结构硬件实现
基于分布式存储簇内全访问结构设计采用Verilog HDL硬件描述语言实现,在ModelsimSE-64 10.1C工具下进行功能仿真验证,选用Xilinx公司的ZYNQ系列芯片XC7Z045FFG900-2 FPGA进行综合测试,其中芯片的资源使用情况见表1.综合后全访问的互连结构,在无冲突的情况下最高频率可达223 MHz,访问峰值带宽达7.42 GB/s.文献[23]中提出的行列交叉访问结构,在无冲突情况下最高频率为170 MHz.通过实验结果可以看出,相比于文献[23]中提出的行列交叉访问结构,在没有冲突的情况下可以提供更高的访存带宽,带宽提高达32.3%.

表1 FPGA芯片资源使用报告Table 1 FPGA chip resource usage report
3.2 Canny算法的并行化映射
为了验证簇内全访问结构的可行性与正确性,将其应用于可重构类数据流处理单元,形成如图3所示2×2的拓扑结构。该结构的每个PEG由4×4的PE阵列和多Bank的存储单元组成,PEG内读写访问采用簇内全访问的互连结构,PEG间的读写访问采用簇间路由器进行数据交互。

图3 2×2阵列拓扑结构Fig.3 2×2 Array topology architecture
在图3所示的阵列结构中,选取像素块为256×256和512×512大小的像素矩阵进行边缘检测的canny算法进行映射与分析。canny边缘检测有4个部分组成:①彩色图像转换为灰度图像;②高斯滤波,即对图像进行高斯模糊;③计算图像梯度;④阈值分割。第1部分的初始化工作利用matlab做好,后面3个操作过程选用PEG00和PEG01进行并行化映射实现。利用PEG00采用分块并行的处理方式,用15个PE并行执行,完成了高斯滤波计算过程;PEG01采用数据流的映射结构,充分利用互连方式,完成了梯度大小的计算及阈值分割。
对于256×256和512×512的像素块PEG00并行高斯滤波处理过程中,PE00和PE32分别处理相同行数据,PE01,PE02,PE03,PE20,PE21,PE22,PE23,PE30和PE31分别处理相同行数据,PE33用于将高斯滤波后的结果给PEG01.由于15个PE并行化处理高斯滤波过程,每个PE可以通过确定读地址和写回地址、边界判断、边界处理和非边界处理4个过程完成滤波过程。梯度计算和阈值分割2部分处理过程由PEG01完成,在PEG01上并行化实现的映射结构图如图4所示。
选取PEG01的PE10,PE11,PE12,PE21,PE22,PE23,PE32,PE33完成滤波和阈值分割操作。若PEG00完成滤波操作后,则向PEG01的PE33最后一个地址中存储一个握手信号,在进行梯度计算前首先要判在PEG01中的PE33最后一个地址中是否存有握手信号,如果能取到握手信号则证明PEG00已完成滤波过程,可以进行梯度计算操作。进行梯度计算时PE33主要完成取数的功能,将取到的4个像素点分别送到PE23和PE32。PE23和PE32完成的功能都一样,主要完成2个像素点的减法将结果给PE22。PE22 接收到数据将2个减法后的结果分别左移1位后将结果分别给到PE21和PE12。PE21接收到PE22的数据后将其保存,然后将数据取平方值的结果和原数据给PE11。PE12处理过程和PE21相同。PE11接收到PE21和PE12的处理数据后进行加法运算,然后对加法运算结果取算术平方根,最后将取算术平方根的结果给PE10来完成阈值的分割处理,处理后的数据写入到一个指定的txt文件中,然后利用matlab完成对txt文件中的数据进行图像恢复。
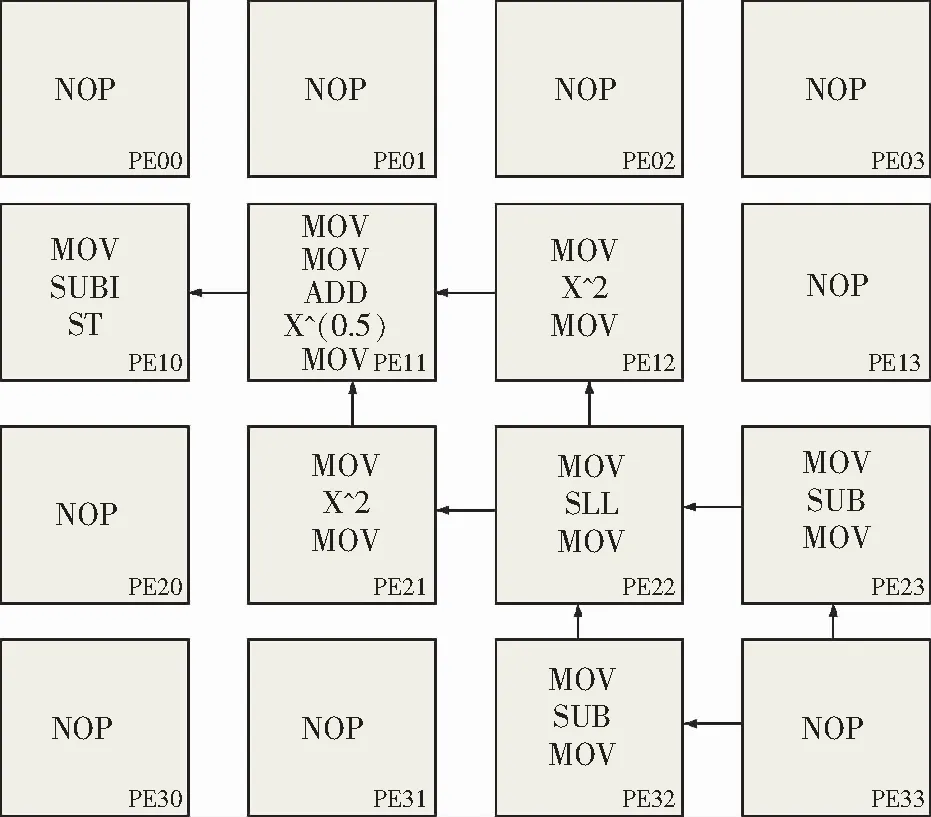
图4 梯度计算和阈值分割映射结构Fig.4 Gradient computation and threshold segmentation mapping structure
测试结果表明,在如图3所示的拓扑结构上仅用PEG00和PEG01就可完成边缘检测canny算法的处理过程。在没有冲突的情况下,该结构支持簇内16个PE同时的写/读操作,写操作1个周期完成,读操作2个周期完成。在有冲突的情况下,互连结构单元能够正确地发送ack反馈信号告知PE。簇间PE和存储Bank访问方式采用全访问的互连结构,簇间采用路由器完成数据访问。PEG00完成高斯滤波的全过程,PEG01完成梯度大小计算和阈值分割过程并且可以采用流水线的方式完成256×256和512×512像素块的处理,最终在算法的正确处理下,执行时间分别为3.52和14.08 ms.
4 性能分析与对比
4.1 仿真性能统计和分析
为了检验分布式存储的簇内FS结构的正确性和低延迟特性,针对FS结构进行了多种访问情况下的测试,并与文献[23]中的LR2SS结构进行了对比。首先对8种简单的情况进行性能仿真分析,第1种情况让相同行的PEs访问同一列的MBs,比如PE00访问MB10,PE01访问MB11,PE02访问MB12,PE03访问MB13;第2种情况让同列PEs访问同行MBs;第3种情况同行PEs访问同列MBs;第4种情况同列PEs访问同列MBs;第5种情况局部2×2 PEs阵列访问相互交叉访问;第6种情况1个局部2×2PEs阵列中的PEs分别访问1个2×2 MBs;第7种情况局部2×2 PEs阵列分别访问4个2×2 MBs;第8种情况2×2 PEs中的PEs分别访问本地个MBs.在这8种测试情况下,2种结构的读写访问延迟如图5所示。

图5 简单情况下读写访问延迟Fig.5 Read and write delay in simple cases
简单测试情况下,FS的平均写访问延迟是1个周期,LR2SS的平均写访问延迟为1.26个周期。分析简单情况写的读写访问延迟,可以得到FS结构和LR2SS结构在没有冲突或者低冲突情况下具有相同的访问延迟。为了展现FS结构和LR2SS结构的不同特点,文中进一步针对2种结构模拟仿真了4种复杂情况下的访问延迟。由于写操作和读操作相似,所以复杂的4种情况仅模拟写操作的延迟统计。第一种情况是不同行的PEs依次分别访问不同行的MBs;第二种情况是不同列PEs分别访问不同列MBs;第三种情况是基于一定的冲突概率下,不同行的PEs访问不同列的MBs;第四种情况是基于一定的冲突概率下,不同列PEs访问不同行的MBs;第一种和第二种情况视为行访问和列访问,分别模拟16种情况。第三种情况是不同行访问不同列,第四种情况是不同列访问不同行,分别模拟15种情况。
在测试情况中,2种结构的行访问延迟在没有阻塞或低阻塞的情况下写操作的访问延迟都是1个周期。列访问延迟如图6所示,FS结构的平均写访问延迟为1个周期,LR2SS结构平均写访问延迟为2.30个周期。不同行访问不同列延迟情况如图7所示,FS结构的平均写访问延迟为1.42个周期,LR2SS结构平均写访问延迟为1.52个周期。不同列访问不同行延迟情况如图8所示,FS结构的平均写访问延迟为1.42个周期,LR2SS结构平均写访问延迟为2.79个周期。由模拟仿真结果可以看出,FS结构相比于LR2SS结构在多数情况下都具有较低的访问延迟。

图6 列访问延迟情况Fig.6 Row access delay

图7 不同行访问不同列延迟情况Fig.7 Different rows delay with different lines access

图8 不同列访问不同行延迟情况Fig.8 Different lines delay with different rows access
4.2 结果对比
根据前文对存储结构的描述,结合该存储结构的“逻辑共享、物理分布”和多个存储快并行存储特点,表2对边缘检测256×256和512×512的canny滤波算法在该分布式存储结构的可重构类数据流阵列结构上的并行化实现进行性能分析。表2还就文中提出的结构与文献[25]中GPU+CPU结构对canny边缘检测滤波算法的实现进行了对比。

表2 性能比较Table 2 Performance comparison
基于分布式存储的全访问互连结构可同时提供16个16位的数据读写访问,在实现片上共享存储的同时又为16个PE提供本地存储单元的优先访问,使得写操作1个时钟周期完成,读操作2个时钟周期完成,减小了PE的读数据访存难度。相比于文献[25]中对256×256和512×512的canny边缘检测算法的处理过程,文中结构处理时间分别减少了2.84倍和2.91倍。
5 结 论
1)针对阵列处理单元对数据访存问题,设计了一种基于可重构类数据流驱动阵列处理单元的簇内分布式存储结构,该分布式结构免除了采用复杂的Cache高速缓存电路的设计,而是采用分布逻辑设计思想和多个存储块并行访问的技术,提高访问效率的同时减少电路设计复杂度;
2)文中提出的阵列处理器簇内全访问存储结构,相比于簇内行列交叉访问结构可以提供更小的访问延迟和更高的访存带宽。实验结果表明,在没有冲突的情况下最高频率达223 MHz,访问峰值带宽达7.42 GB/s;
3)可重构类数据流驱动阵列处理器簇内全访问的存储结构对256×256和512×512canny算法正确处理的情况下,相比于GPU+CPU结构的处理时间,可以提供2.84倍和2.91倍的加速比,该结构具有访存延迟小、处理速度快的特点。
