Haar特征提取IP核设计及前方车辆检测系统实现
2018-08-08任亮朴徐美华陈高攀
任亮朴,徐美华,陈高攀
(1.上海大学微电子研究与开发中心,上海200072;2.上海大学机电工程与自动化学院,上海200072)
针对汽车安全驾驶的智能驾驶辅助系统是现在的研究热点,它需要检测路面的环境信息。对路面的环境检测有行人检测、车辆检测、车道线检测等,其中前方车辆检测是非常重要组成部分。
基于计算机视觉的车辆检测是现在的主流方法,在早期研究过程中,一般采用车辆的对称性[1]、边缘特征、颜色信息[2]等来检测车辆。在最近几年,车辆的特征转变为更加普适和更具鲁棒性的特征,如Haar特征[3-5]和 HOG(Histograms of Oriented Gradients)特征[6]或混合特征HOG+Haar、Haar+对称性等,对这些提取的特征分类的方法有支持向量机[7-8](Support Vector Machine,SVM)、人工神经网络[9-10](Artificial Neural Network,ANN)、AdaBoost[11-12]等。为了使车辆检测算法能够真正用于汽车驾驶上,我们还需设计对应的车辆检测嵌入式系统。文献[13]采用FPGA来实现前方车辆检测,但是它采用的是直观的特征,准确性较差。文献[14-15]采用GPU硬件平台取得了比较好的效果,但是也很难应用于汽车嵌入式处理系统。
由于Haar特征相比HOG特征硬件实现更加简单,SVM相对于人工神经网络有更好的数学理论支持且针对未训练过的样本预测能力更强。文中设计完成了基于Haar+SVM前方车辆检测系统中的Haar特征提取的IP核设计,通过部分积分图结构、流水线结构、乒乓操作、数据复用等方法提高Haar特征的计算速度;并且针对提取到的Haar特征,采用AdaBoost进行降维操作,再用SVM进行分类训练,提升了分类能力。最终,采用Xilinx公司的XC7Z020作为核心处理芯片将整个算法在嵌入式系统实现后,检测精度为97.2%,系统处理速度平均为每秒21.6帧。可以满足前方车辆检测的要求。
1 前方车辆检测算法架构
基于单目视觉的前方车辆检测算法主要分为两个部分,训练部分和识别部分,结构图如图1所示。训练部分包括图像预处理、Haar特征提取、AdaBoost降维、SVM分类器训练四个部分,用于生成识别过程用到的Haar特征以及分类器。识别部分是对摄像头实时传回的图像进行处理来检测车辆。图像预处理过程包括帧预处理、感兴趣区域提取等操作,为后面的Haar特征提取做准备。
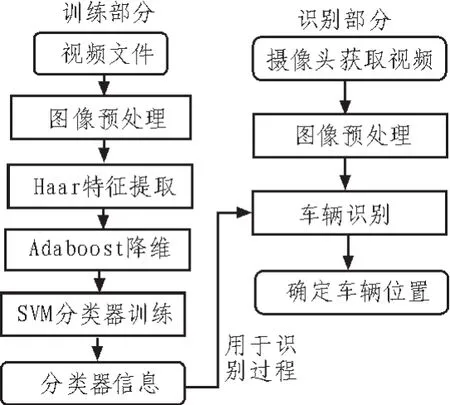
图1 前方车辆检测算法结构图
2 Haar特征提取IP核设计
针对前方车辆检测算法中Haar特征提取,本文提出Haar特征提取IP核设计,进行硬件加速,提高算法的运算效率。
2.1 Haar特征提取IP核
本文提出的Haar特征提取IP核结构图如图2所示,主要包含3个模块,积分图计算模块,Haar特征模块,特征值计算模块。积分图计算模块负责积分图的计算,Haar特征模块存储所需的特征模块类型和坐标信息,特征值计算模块是将前两个模块输入的信息进行计算,得到对应特征模块Haar特征的值。
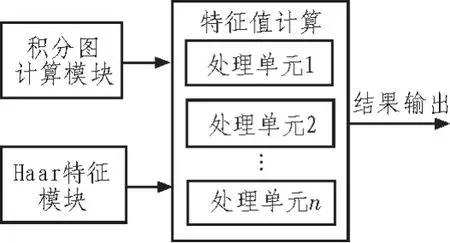
图2 特征提取IP模块结构图
2.1.1 积分图计算
对于一个大小为24×24像素的图像子窗口,基本的4个Haar特征的总数就超过了16万个,这样巨大数量的特征将直接导致训练和检测的速度减慢,为了快速计算在不同尺度下的特征,引入了积分图的概念。积分图的定义为:
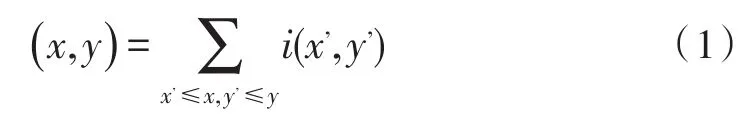
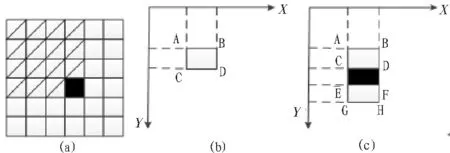
图3 积分图及灰度快速计算
在图(a)中,黑色处点的积分数值为所有绿色像点的灰度和加上黑色处本身的灰度值。图(b)表示一个矩形块的内像素点灰度和计算示意图,其公式为:Y=A+D-B-C,Y表示方框内灰度和,A、B、C、D分别为各处像素点对应的积分图的数值。图(c)为一个Haar特征的计算示意图,其公式为:Y=A-B-2C+2D+2E-2F-G+H。用这种方法计算Haar特征时不必每次都计算块内灰度和,大大提高了计算速度。
2.1.2 部分积分图架构
对于Haar特征的积分图计算,首先对积分图数据采用芯片(ASIC或FPGA)内部的RAM资源进行存储,但是芯片内部的RAM资源极为有限,不能采用全积分图的架构,而文献[16]中的部分积分存储结构所使用的存储容量依然太大,仍无法满足要求。针对文献[16]的思路,可以将部分存储进一步的“部分化”,即积分图只存储一个扫描滑窗的积分图数据。这样虽然需求的存储资源减少,但是在提取完Haar特征时每次都需要重新计算下一窗口积分图,使计算速度极为缓慢。为解决此问题,采用行列分开计算存储架构,将行积分与列积分分开来进行计算,先进行一次行积分,再进行列积分,列积分的结果同行积分一样存储在RAM中,完成后就是最终的积分图。
2.1.3 流水线结构设计
在特征值计算模块,我们采用流水线式结构。积分模板的地址信息存储在ROM块中,当列积分完成后,ROM表开始生成Haar模板地址,RAM读到地址后,产生用于计算的数据。在加法器计算Haar特征时,由于需要的数据更多,导致RAM需要对不同的寄存器赋值,增加了寻址的逻辑资源;另外计算一个Haar特征所需周期数目也更多。为解决此问题,设计中采用了寄存器队列结构和双端口ROM、双端口RAM。使用了双口的RAM和ROM,一个周期可以取两个数据到寄存器队列中,与原来相比,虽然消耗的逻辑资源增多,但是计算速度加倍。另外寄存器每个周期都向下移位一次,这样RAM就只需要对第一个寄存器不断赋值就可以了,减少了不必要的寻址逻辑资源。
2.1.4 乒乓结构设计
对此存储计算结构的进一步分析会发现,当数据流向列计算的RAM时,从列积分流向行积分的计算处于停止状态,而从第二个RAM流向下一级寄存器处于活跃状态。为了提高IP接口的利用率,引入乒乓操作,在数据输入端增加了一个数据选择器,同时RAM变为原来的两倍。计算时,当第一个列计算RAM块满时,利用数据选择器对第二个列RAM块输入数据,当第二个RAM满时又切换到第一个RAM。
2.1.5 数据复用与扩展设计
为了提高检测的准确率,滑窗会有部分重叠,对于这种情况,可以采用数据复用的设计,在每次移动滑窗后,使用前一次计算积分图计算所留下的数据,这样做的好处是可以使计算一次积分图的数据减半,提高计算速度。其计算与存储结构如图4所示。
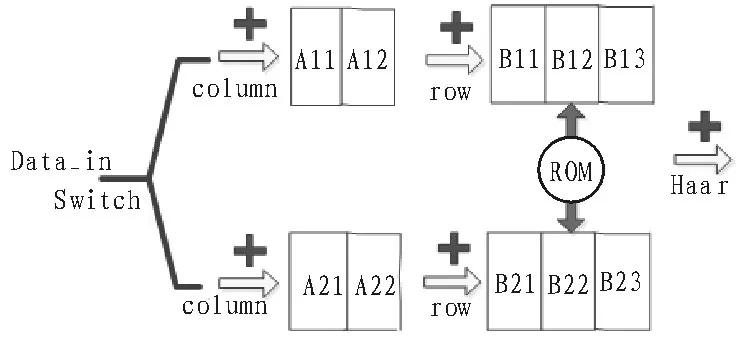
图4 数据复用结构图
在图4中,当B1RAM块(包含B11和B12两部分)内积分图数据使用完毕时,滑窗向右移动。若需要使用滑窗内原始的部分数据,直观的方案是通过移位将原始滑窗右半边的数据移到左半边,然后更新左半边的数据。但是在RAM内不能像寄存器那样移位,这里提出虚拟的B13结构,即新的滑窗由新的B12和B13组成,这里无需改动RAM块B12的数据,直接更新B13块中的数据。当下一次更新窗口时只需更新B12块中的数据。在使用特征模板进行特征计算时,需要判断此次积分图为B11+B12模式还是B12+B13模式,然后对模板地址进行变换,而这只需要一个标志位即可解决。
在基本的Haar特征提取IP基础上,如果增加RAM的数量(A1-An,B1-Bn),就可实现需要更多的Haar特征应用情况下的扩展型IP设计。
2.2 接口设计及仿真实验
针对设计的IP核,用Verilog写出具体的数字电路,IP接口定义如表1所示。
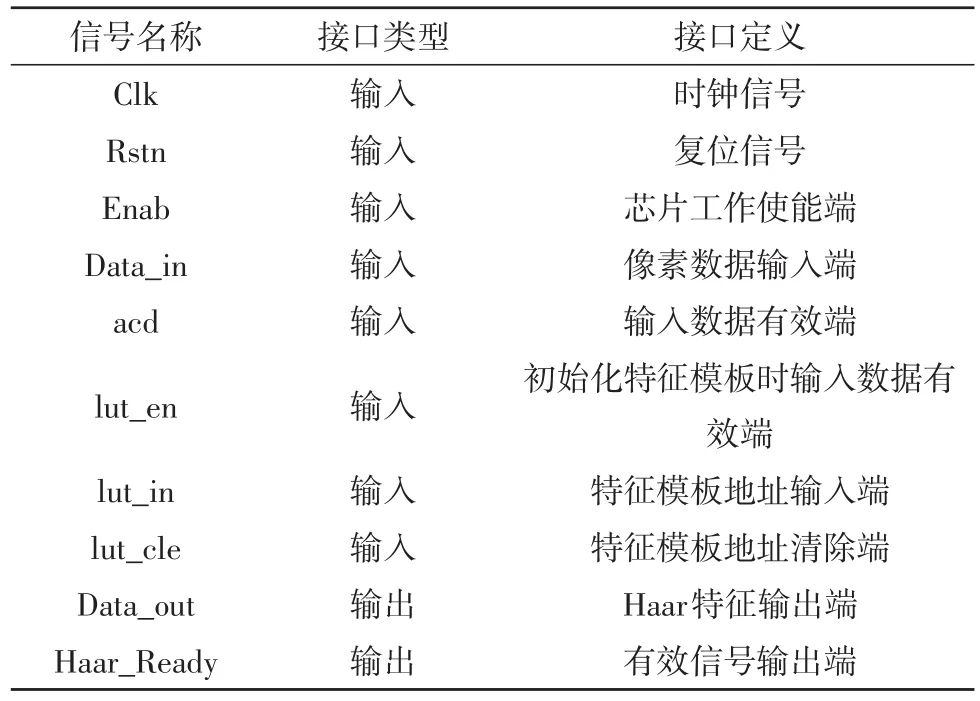
表1 IP接口定义
对此IP编写testbench,并用Synopsys的VCS进行仿真,这里选取的特征模板为图3(c)所示,其中各个点坐标为 A(0,0)、B(0,10)、C(1,0)、D(1,10)、E(2,0)、F(2,10)、G(3,0)、H(3,10),输入的像素一直为1,根据公式可得最终的结果应该为10。仿真结果如图5所示,从图中可以看出,data_in端口的数据一直为1;输入到Rom表中的数据lut_in为:x800,0x80a,0x820,0x82a,0x840,0x84a,0xc60,0xc6a;在Haar_ready拉高时,data_out端输出0x000a;Haar_ready每四个时钟周期拉高一次且会一直持续下去。这些都符合我们的预期,其中lut_in的高两位为标志位,后面十位为地址位,由此可知IP功能符合设计需求。

图5 VCS仿真
3 AdaBoost降维和SVM训练
AdaBoost算法是一种提升树的方法,先对一个训练集训练出不同的弱分类器,然后把这些弱分类器集合起来构成一个强分类器。每一个弱分类器识别错误率小于1/2(即准确率仅比随机猜测略高的学习算法),但是将这些弱分类器以一定的权重组合成一个强分类器就能使得分类能力提高。
支持向量机(Support Vector Machine,SVM)是一种在高维特征空间使用线性函数假设空间、有监督的学习方法,广泛应用于统计分类和回归分析。SVM的训练过程是找到一个超平面,或在高或无限维空间,这个超平面可以根据输入的Haar特征将图像分为两类:车辆与非车辆,超平面的函数为:

其中x表示输入的Haar特征值向量,ωT和b为分类器参数。SVM分类的过程就是代入x求值,这样就可以把车辆和非车辆图像分开来。
文中采用AdaBoost对训练集中样本特征进行降维,用SVM对经过降维的前方车辆检测样本库进行分类训练,这里通过Haar特征将二者有机结合起来。如图6所示是AdaBoost训练和测试结果,可以看到训练结果为500轮时,测试错误率区域稳定,平均错误为3.9%。采用降维后的特征信息作为SVM分类器训练的样本库,在4 764个样本中随机选择3 334个样本作为训练集,1 430个样本作为测试集。采用libsvm对样本进行训练,相对于纯粹采用AdaBoost的方法对Haar特征进行训练,采用AdaBoost+SVM的方法将正确率从96.10%提高到了97.26%。
4 前方车辆检测系统实现
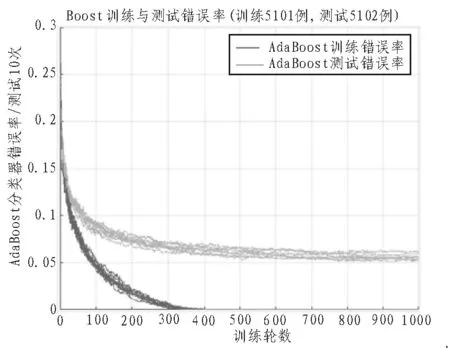
图6 AdaBoost训练和测试结果
根据前面提到的车辆检测算法,将软件和硬件在 Xilinx ZC702 SOC(System On a Chip)上实现。该芯片是采用FPGA+CPU的嵌入式SOC。将MATLAB代码移植到嵌入式Linux操作系统中,并将Haar特征提取的IP核移植在可编程逻辑上。
4.1 系统硬件设计
前方车辆检测系统硬件系统由核心板、主板外设3个部分组成,系统图如图7所示。
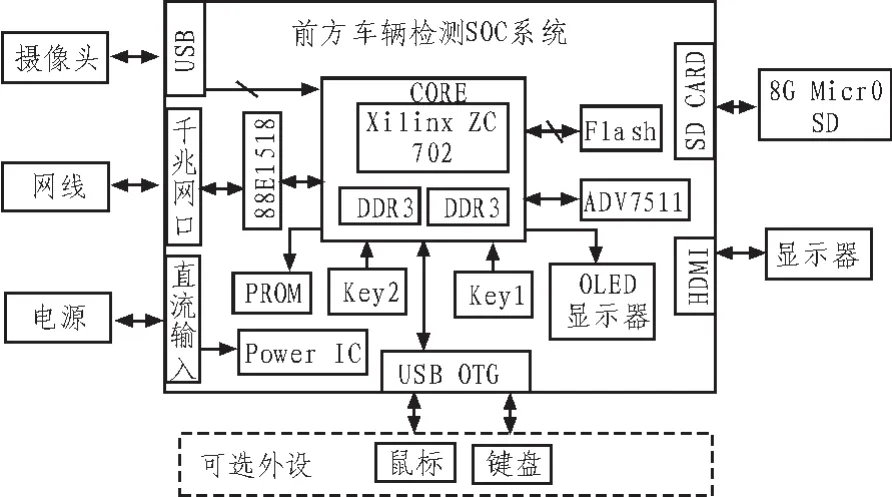
图7 前方车辆检测系统硬件系统
4.2 系统软件设计
软件的开发环境为嵌入式Linux,系统的开发语言选择的是Python,由于Python的执行效率要低于C或者C++,为弥补此不足,使用OpenCV库来进行开发。因为OpenCV库的核心为C++,只是接口部分用Python来连接,所以采用Python+OpenCV的方案使得算法最终的执行效率并没有明显的降低,但开发速度提高。
4.3 实验结果

图8 实物图与测试结果
整个前方车辆检测系统设计实现后,我们对一个视频进行前方车辆检测,图8是系统测试平台的实物图与前方车辆检测的部分截图,从图中我们可以看出,前方的车辆基本都可以检测出来。据统计,系统的检测精度为97.2%,系统处理速度平均为21.6帧每秒。可以满足前方车辆检测的要求。
5 结束语
文中提出基于Haar+SVM前方车辆检测系统中的Haar特征提取的IP核设计,通过部分积分图结构、流水线结构、乒乓操作、数据复用等方法提高Haar特征的计算速度;并且针对提取到的Haar特征,我们采用AdaBoost进行降维操作,再用SVM进行分类训练,提升了分类能力。将整个算法在嵌入式系统实现后,实验结果表明,检测精度为97.2%,系统处理速度平均为每秒21.6帧,验证了所设计的算法和系统的正确性和有效性。
