一种基于LSTM的视频车辆检测算法
2018-08-06李岁缠
李岁缠,陈 锋
(中国科学技术大学 信息科学技术学院,安徽 合肥 230027)
0 引言
近年来,基于视频的车辆检测在自动驾驶和交通视频监控领域得到了广泛的应用。另一方面,基于深度学习的静态图像目标检测也取得了重要的进展和突破。基于深度学习的图像目标检测算法可以分为两类:基于单阶段的算法[1-3]和两阶段的算法[4-6]。相比于两阶段算法,单阶段算法具有更快的处理速度,因此更适合实时的应用,比如视频车辆检测。但是,将这些基于静态图像的目标检测算法直接应用于视频目标检测,即将视频帧进行独立的处理时,并不能取得好的检测结果。因为针对视频进行目标检测时,总会遇到运动模糊、视频失焦等问题,而基于静态图像的目标检测算法容易受这些问题的影响,得到比较差的检测结果。
视频中通常包含着目标的时间维度的信息,这些信息对视频目标检测具有非常重要的作用,而基于静态图像目标的检测算法忽略了这些信息。如果能够有效利用视频包含的时间维度的信息,则可以有效解决运动模糊与视频失焦等问题。比如,如果当前视频帧中的目标出现模糊,那么就可以利用其邻近帧的目标信息帮助对当前帧的检测。因此,如何提取目标运动信息则是最关键的。最近,循环神经网络LSTM[7]由于其强大的记忆能力以及可以有效克服训练神经网络时出现的梯度消失问题的优点,被大量应用于解决时间序列问题,比如机器翻译[8],并且取得了比较好的效果。
本文提出一种基于LSTM的单阶段视频车辆检测算法,称为M-DETNet。该算法将视频看做一系列视频帧的时间序列,通过LSTM去提取视频中目标的时间维度信息。该模型可以直接进行端到端的训练,不需要进行多阶段的训练方式[4-5]。利用DETRAC车辆检测数据集[9]训练该算法并进行验证和测试,实验结果表明该算法可以有效提升视频车辆检测的准确率。同时,将M-DETNet与其他典型的目标检测算法进行了对比,实验结果表明M-DETNet 具有更好的检测准确率。
1 LSTM网络
LSTM(Long Short-Term Memory)[7]属于循环神经网络(Recurrent Neural Network, RNN),其最大特点是引入了门控单元(Gated Unit)和记忆单元(Memory Cell)。LSTM网络单元如图1所示。
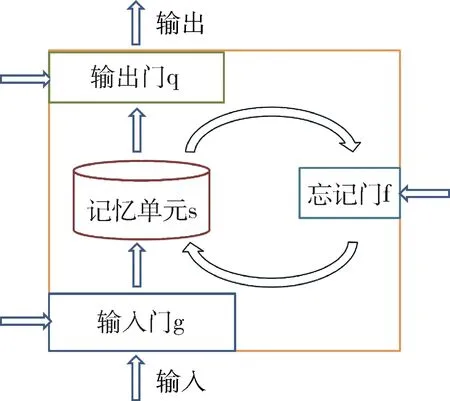
图1 LSTM单元示意图
LSTM循环网络除了外部的RNN循环外,其内部也有自循环单元,即记忆单元。由图1可以看出,LSTM具有3个门控单元,分别是输入门g、忘记门f和输出门q。门控单元和记忆单元s的更新公式如下:
(1)
(2)
(3)
(4)
其中,x(t)是当前网络输入向量,h(t)是当前隐藏层向量,b是偏置向量,U、W是权重向量,⊙表示逐元素相乘。
将普通RNN神经网络中的神经元替换为LSTM单元,则构成了LSTM网络。
2 M-DETNet
本文提出的模型M-DETNet如图2所示。从图2可以看出,M-DETNet由3个子模块组成,分别为ConvNet模块、LSTMNet模块和FCNet模块。设算法输入视频帧个数为K。ConvNet模块首先对K个视频帧分别处理,提取空间特征;空间特征作为LSTMNet的输入,得到时间维度的特征信息;FCNet预测输出最终的结果。
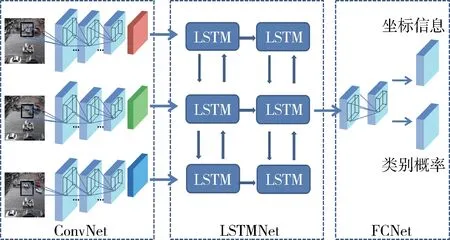
图2 M-DETNet结构图
2.1 ConvNet模块
DarkNet-19[2]是一个应用广泛的分类卷积神经网络,其包含有19个卷积层和5个池化层;相比于其他被广泛应用的卷积网络,如VGG-16[10], DarkNet-19的特点是需要学习的参数更少,并且执行速度也更快。使用ImageNet数据集[11]训练DarkNet-19,可以达到72.9%的top-1准确率和93.3%的top-5准确率。本文使用经过在ImageNet上预训练的DarkNet-19网络,并去掉最后一个卷积层,作为空间特征提取主干网络,称为ConvNet。ConvNet对K个输入视频帧分别处理,提取丰富的空间特征。
2.2 LSTMNet模块
LSTM模块的主要作用是接收ConvNet产生的空间特征作为输入,得到连续帧之间包含的时间维度的特征信息。由图2可以看到该模块由两层双向LSTM网络组成,使用双向LSTM的原因是便于使用当前帧对应的前序帧和后序帧的信息。普通的LSTM网络的输入通常为向量,而本文模型的LSTM网络的输入为特征图。
2.3 FCNet模块4
普通的卷积分类网络使用全连接网络预测输出,而本文模型的FCNet由全卷积网络组成,即使用全卷积网络产生最后的输出,包括车辆的类别概率和矩形框的坐标。FCNet由3个卷积层组成,前两个卷积层包含1 024个特征图,卷积核的大小为3×3;最后一个卷积层的卷积核大小为1×1。
仿照YOLO[2],网络不直接预测输出包含有车辆的真实矩形框的坐标,而是预测真实矩形框相对于参考矩形框的偏移值,并参数化如下:
bx=σ(tx)+cx
(5)
by=σ(ty)+cy
(6)
bw=pwetw
(7)
bh=pheth
(8)
bc=σ(tc)
(9)
其中,(cx,cy)为参考矩形框所在特征图单元(cell)的坐标;(pw,ph)为参考矩形框的宽和高;σ(·)为激活函数,取值范围为[0,1];(bx,by,bw,bh,bc) 是最终的结果。
2.4 训练方法
使用带动量项(momentum)的随机梯度下降(Stochastic Gradient Descent,SGD)优化方法训练本文模型,动量项设置为0.9,训练循环总次数(epoch)设置为80次。对于学习率,前60次循环时设置为0.001,之后将学习率降低为0.000 1。同时,为了增强模型的泛化能力,本文也做了数据增广,包括随机的裁剪和水平翻转。训练的batch大小设置为32。
由于内存的限制,在训练时选择3个视频帧作为网络的输入,即K=3。在相对于当前帧的偏移为[-10,10]的范围内,随机选择前序帧和后序帧。对于第一帧和最后一帧,简单地重复当前帧代表其前序帧或后序帧。
3 实验及分析
使用DETRAC车辆检测数据集[9]验证本文模型。该数据集包含有4种天气场景(晴天、阴天、雨天和夜晚)下的视频数据,总计有14万视频帧,包含的车辆总计为8 250辆。为了验证模型的有效性,设置了两组实验。第一组实验在验证集上比较了本文模型与YOLO[2],以说明本文提出的LSTM模块的有效性;第二组实验在测试集上将本文模型与其他典型的方法进行了比较。
3.1 M-DETNet的有效性验证
如果本文模型去除LSTM模块,则网络结构与YOLO[2]的结构基本一致。为了验证本文模型中LSTM模块的有效性,在验证集上对比了本文模型和YOLO。实验结果如表1所示。

表1 M-DETNet与YOLO的比较结果 (%)
由表1可知,本文模型不管在4种天气场景下的性能,还是平均性能均优于YOLO。同时,在雨天和夜晚两种场景下,本文算法性能相对于YOLO具有更大的提升,从数据集中可发现在雨天和夜晚,视频帧更容易出现视频模糊等问题。这些结果表明本文提出的LSTM模块具有获取时间维度特征的能力,能够提升车辆检测的准确率。
3.2 M-DETNet与其他典型算法的比较
将M-DETNet与其他典型的算法在测试集上进行了比较,实验结果如表2所示。由表2可知,相比于其他算法,本文模型在测试集上的平均准确率最高,达到了52.28%;本文模型在不同难易程度下均具有更好的检测准确率。同时还可发现,在夜晚和雨天,本文算法相对于其他算法的准确率提升比在晴天和阴天的提升更大。

表2 M-DETNet与其他算法的比较结果 (%)
在检测速度方面,本文算法在GPU(1080Ti)上的检测速度可以达到29 f/s,相比其他算法有很大的优势。
4 结论
本文提出一种基于LSTM的视频车辆检测算法,该算法通过LSTM模块提取视频帧序列中包含目标的时间维度的信息,这些信息可以有助于克服视频模糊等问题,进而提升检测准确率。将本文模型与其他典型的算法进行了比较,实验结果表明本文模型不仅具有更好的检测准确率,而且有更快的检测速度。为了更好地对模型进行测试,未来工作将在实际的应用中对模型进行测试和验证。
