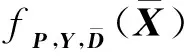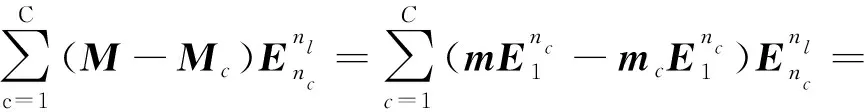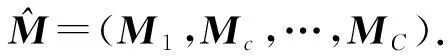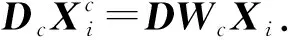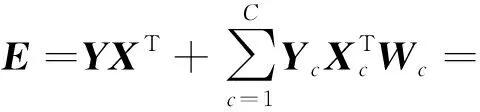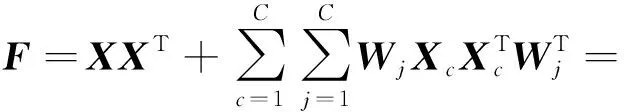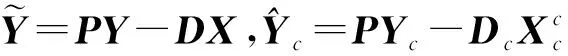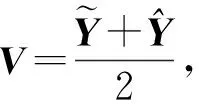稀疏约束下快速低秩共享的字典学习方法及其人脸识别
2018-08-06李爱师
田 泽 杨 明 李爱师
(南京师范大学计算机科学与技术学院 南京 210023) (zetian_edu@126.com)
人脸识别存在光照、表情、姿态、小样本等挑战性问题,同时,人脸识别的高维问题也增加了人脸识别的难度,通常使用经典的降维方法主要有LDA[1],LPP[2]和PCA[3],降维得到的子空间能够提高人脸识别的准确率.但是这些方法对人脸识别存在的光照、表情等问题不具有良好的鲁棒性.稀疏表示可以较好地解决这些问题.
稀疏表示[4]已经成为信号处理领域的强大工具.应用包括压缩感知[5]、稀疏信号恢复[6]、图像分割[7]以及信号分类.在这些应用领域中,信号通常可以由固定的字典来表示.基于这一理论,稀疏表示分类器被提出并应用于人脸识别.然而,固定的字典对于分类任务并没有足够的鉴别力,这就促进基于稀疏约束的字典学习研究.
字典学习可以分为无监督字典学习和有监督字典学习.KSVD[8]算法为无监督字典学习的典型代表,通过奇异值分解对字典原子进行更新.文献[9]提出DKSVD算法,将线性分类器加入KSVD字典学习模型,促使KSVD算法具有分类能力.文献[10]将鉴别性稀疏编码误差项加入DKSVD算法促使稀疏编码的判别能力进一步加强.文献[11]将Fisher判别准则嵌入到字典和稀疏编码中,这促使稀疏编码和字典都具有判别能力,但其仅考虑样本中特有的信息,没有考虑样本间的共享信息.针对这一问题,文献[12]提出利用低秩约束字典来获得样本间的共享信息,这增强了字典和稀疏编码的判别能力.
此外,大部分有监督字典学习[9-12]都是先对数据进行降维再进行字典学习,这些方法不能从原数据集中获得更为重要的特征,从而降低字典的学习能力.针对这一问题,稀疏嵌入框架[13]被提出,通过同时降维和字典学习的策略来增强字典和稀疏编码的判别能力.文献[14]通过约束投影矩阵正交来获得紧凑的特征,但其投影矩阵的求解是不恰当的且收敛性不能被保证,因此降低了字典的学习能力.针对此问题,SEDL[15]通过Cayley[16]变换来保护投影矩阵的正交性,从而获得重要和紧凑的特征.
针对上述所提字典学习的不足,本文提出一种稀疏约束下快速低秩共享的字典学习(FLRSDLSC)方法,并将其用于人脸图像分类.本文的主要贡献有3个方面:
1) 字典学习框架由特定类的字典和共享的子字典所组成.对于特定类的字典,嵌入Fisher判别准则;对于共享的子字典,嵌入低秩约束.因此,该方法能从样本中获得共享和特定类的特征,以此增强字典和稀疏编码的判别能力.
2) 通过Cayley变换保护投影矩阵的正交性来获得紧凑的特征.
3) 采用降维和字典学习同时进行的方法,增强字典对降维后样本的表示能力.
1 相关工作
1.1 稀疏嵌入字典学习(SEDL)
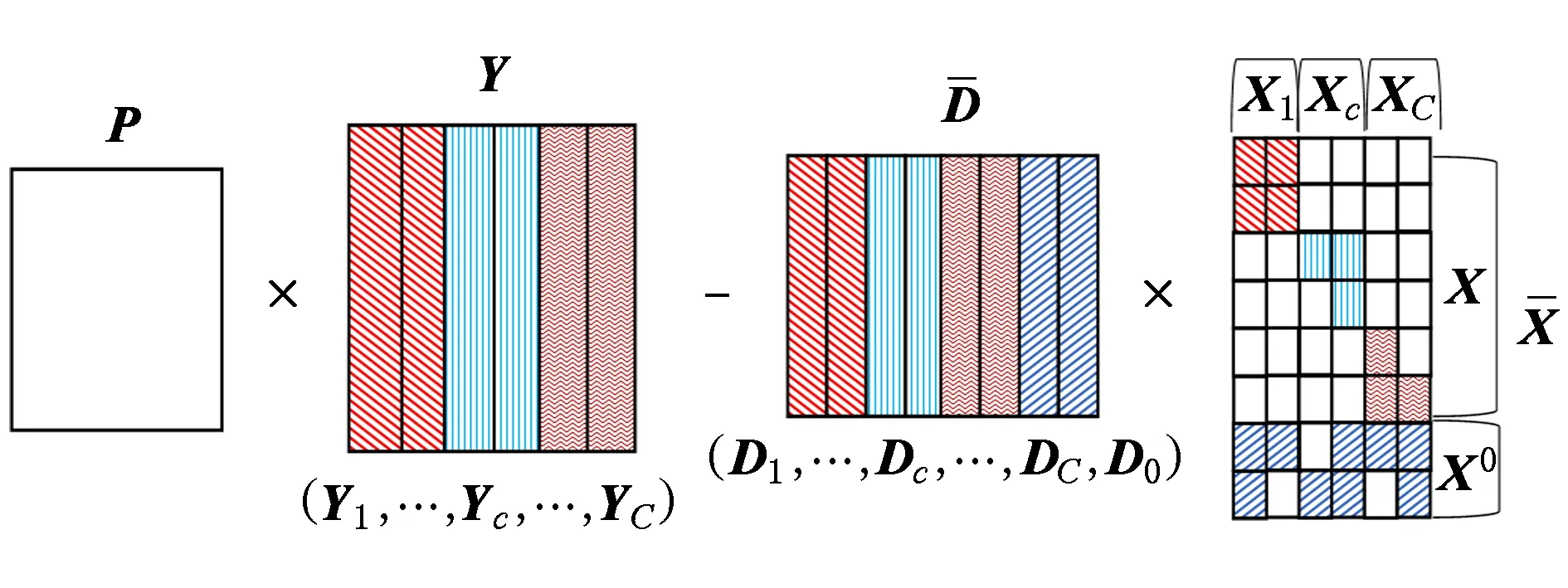
Chen等人于2017年提出一种同时降维和字典学习的方法(SEDL)应用于人脸识别.其目标函数如下:
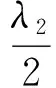
(1)
s.t.PTP=I,
其中,f(P,Y,D,X)为变量P,Y,D,X的函数,
(2)

(3)

(4)
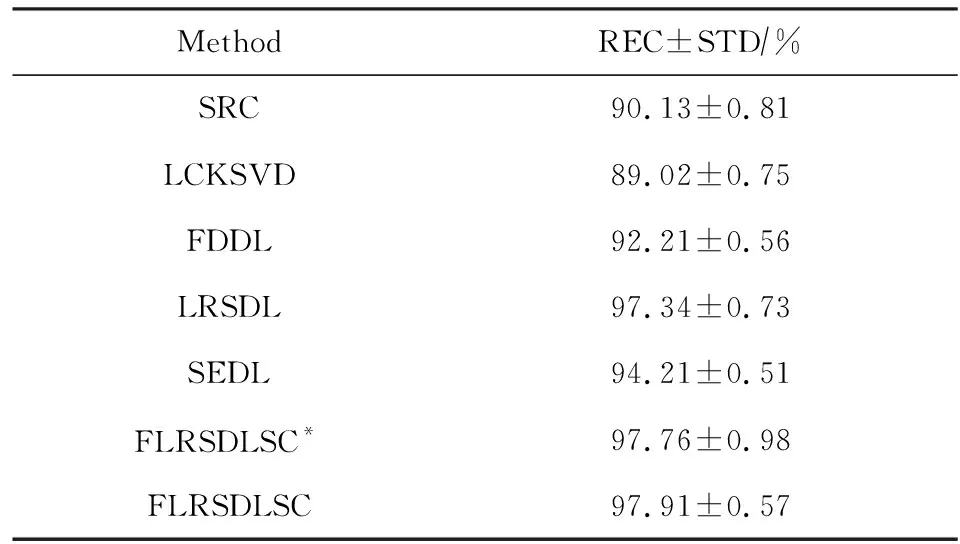
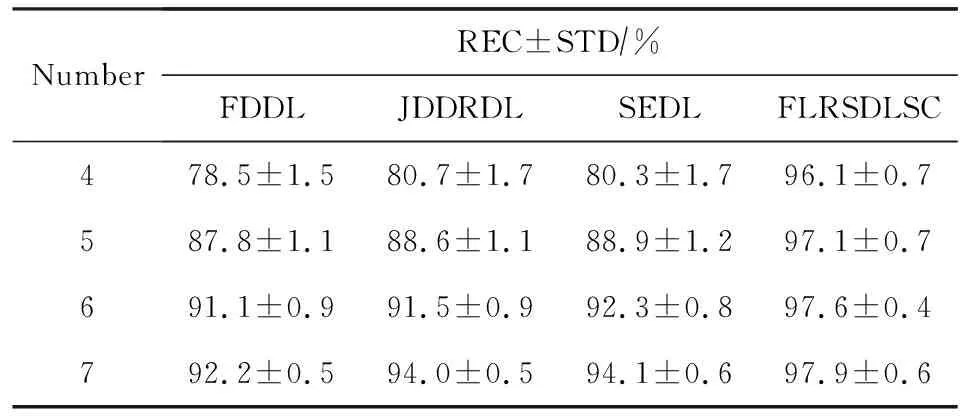
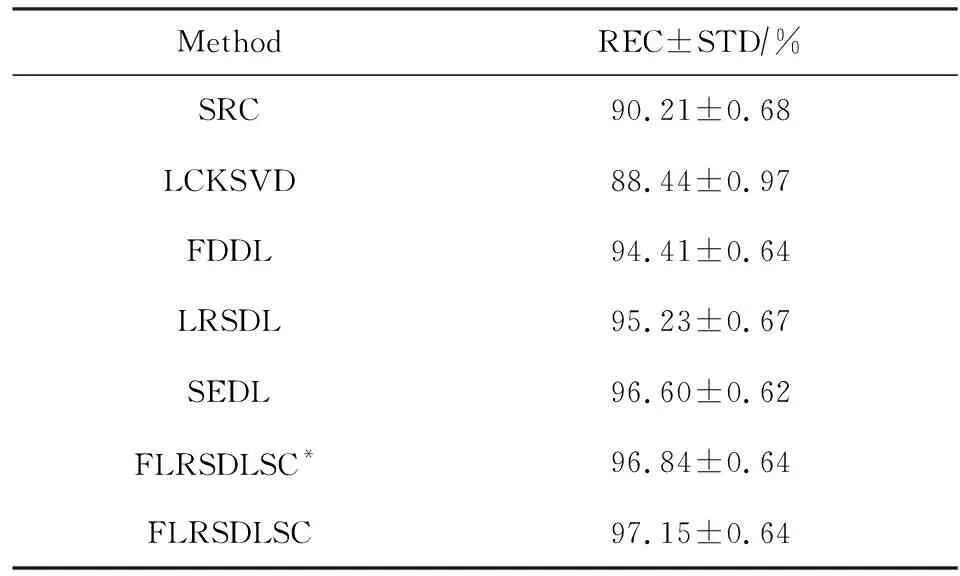
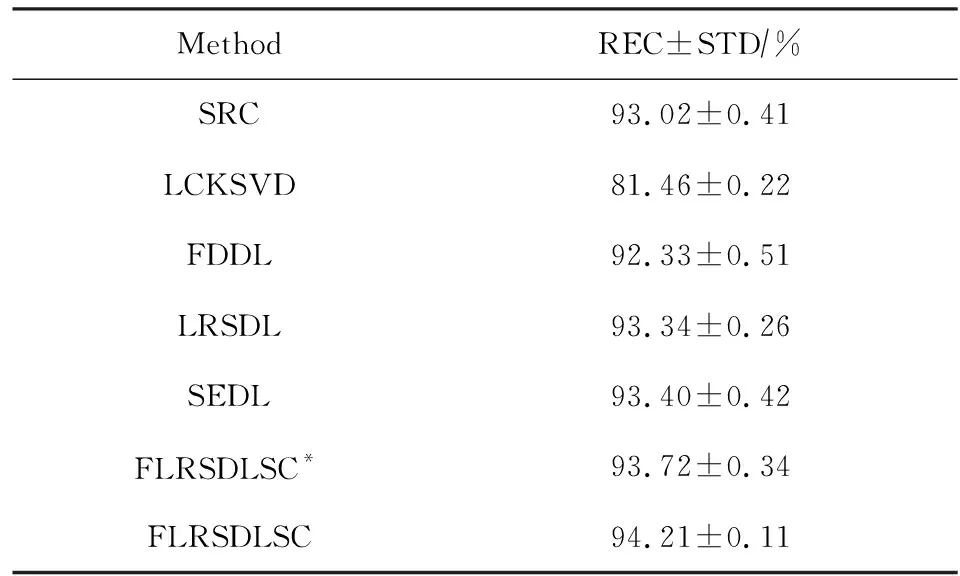
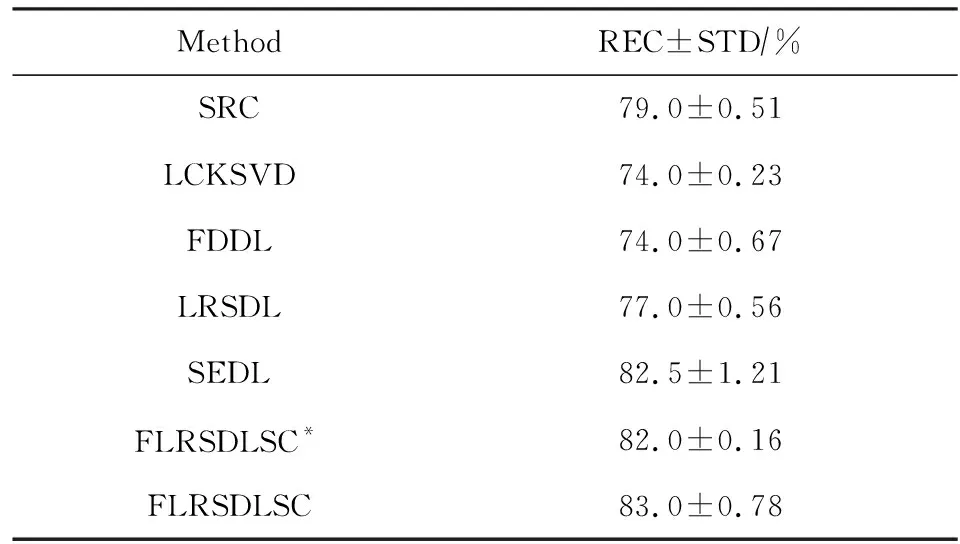
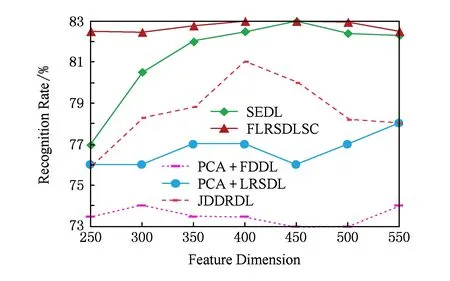
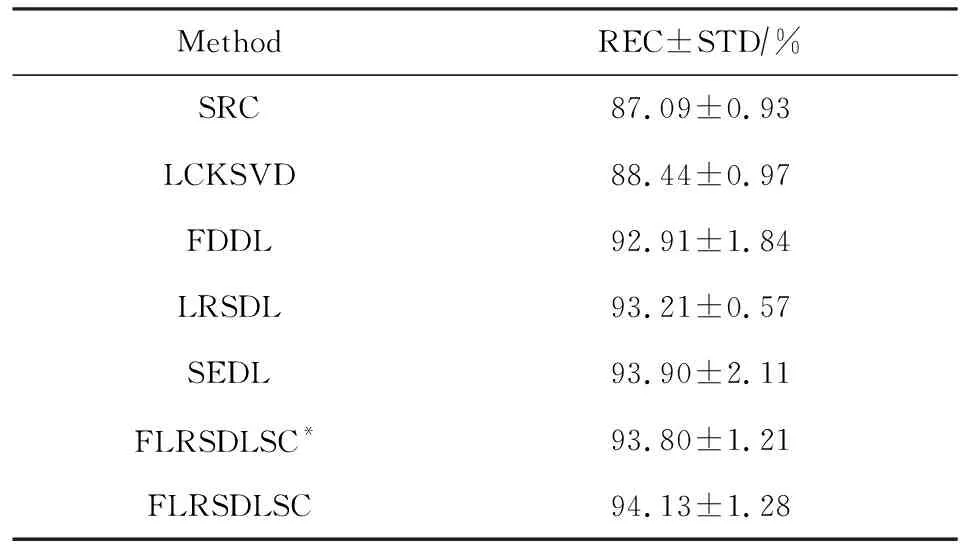
Y=(Y1,…,Yc,…,YC)∈d×N表示大小为N的训练数据集,Yc∈表示第c类训练样本,其中N=n1+…+nc+…+nC.降维的目标是学习投影矩阵P∈p×d(p Natarajan于2006年提出用稀疏近似解[17]去求解矩阵最小化问题,其目标函数如下: (5) 其中H∈s×dt是决策变量,L是线性映射,L将H从s维映射到p维.然而式(5)的求解是NP难问题.当式(5)的解就是核范数(即所有奇异值之和)的解.人们转而求解如下凸优化问题: (6) 式(6)通过奇异值阈值[18]算法近似求解. (FLRSDLSC) 针对SEDL方法的不足,本文提出一种稀疏约束下快速低秩共享的字典学习方法.该方法学习特定类字典和共享子字典,以此增强字典和稀疏编码的判别能力,同时采用字典学习和降维同时进行的方式.其模型定义如下: (7) s.t.PTP=I, 其中, (8) (9) Fig. 1 The relationship between variables in term (8)图1 式(8)变量间的关系 λ1,λ2,η,λ3为正则化参数;X0列的均值向量为m0,X0的均值矩阵为M0=(m0,…,m0);D0∈为共享子字典,为总字典,为核范数正则化促使子字典D0具有低秩结构.X0代表Y在共享字典D0下的编码系数,代表Y在总字典下的编码系数. Fig. 2 The relationship between variables in term (9)图2 式(9)变量间的关系 (10) 其中 (11) fP(D)=f(P,D)代表P固定D的函数,用式(11)求导后的结果和FISTA[19]算法对式(10)进行求解,式(11)求导如下: (12) 式(12)的第1分量推导如下: (13) (14) (15) 证明. 见附录A. 式(12)的第2分量,使用引理3,推导如下: (16) (17) 式(14)和式(17)组合求解式(12). (18) 证明. 见附录B. 式(18)运用ODL[20]算法进行求解. (19) 证明. 见附录C. 基于引理3,式(19)简化如下: (20) 式(20)使用ADMM[21]模型和奇异值阈值算法.ADMM过程如下:首先选择一个正数ρ,初始化Z=U=D0,然后迭代求解如下子问题直到收敛: (21) 其中 (22) (23) Z=Kn ρ(Dc+U), (24) U=U+D0-Z, (25) 其中K为软阈值运算符.式(21)的优化问题运用ODL算法进行求解. 2.2.3 更新降维矩阵P (26) 式(26)使用Cayley变换求解P,其求解简化为 (27) (28) 通过对上述变量的更新,输出P,D,D0,X,X0. (29) (30) 其中,w为平衡参数,mc为xc的列平均向量. 输入:训练集Y,参数λ1,λ2,λ3,η和最大迭代次数T; 7) 重复步骤2到步骤6,直到达到收敛条件或者满足最大迭代次数; 我们的算法快速主要体现在更新稀疏编码X和结构化(特定类)字典D上,本节比较了原始和高效的FDDL字典学习方法的复杂度.每个算法的复杂度被估计为一次迭代所需乘法的数量.假设:1)每类样本数量是特定类字典数量的2倍,特定类字典数量与共享类字典数量是相同的.令nc=n,kc=k0=k;2)每类字典的个数、训练样本的数量都远小于样本维数,即k 在本节分析中使用以下事实:1)如果A1∈m1×n1,B1∈n1×p1,则矩阵乘法A1B1具有复杂度O(m1n1p1);2)如果A1∈n×n是非奇异的,则矩阵求逆的复杂度为O(n3);3)矩阵的奇异值分解A1∈p×q,p>q,其复杂度Ο(pq2). 1) 更新X(O-FDDL-X) 参考文献[12],原始的稀疏编码更新被分为C个子问题O-FDDL-X的复杂度: C2k(dn+qCkn+Cdk). (31) 2) 更新X(E-FDDL-X) 由引理1可知, (32) (33) (34) 3) 更新D(O-FDDL-D) 参考文献[12],原始的字典更新被分为C个子问题,O-FDDL-D的复杂度: Cdk(qkn+C2n). (35) 4) 更新D(E-FDDL-D) 参考文献[12],E-FDDL-D的复杂度: Cdk(Cqk+Cn)+C3k2n. (36) 表1,2分别展示原始的FDDL算法和高效的FDDL算法的复杂度分析与不同字典学习方法的总体复杂度分析. Table 1 Complexity Analysis for the Proposed Efficient Table 2 Complexity Analysis for Different Dictionary 选择一系列参数集合:类别数为100、数据降维后的维度为50、数据维度为500、迭代次数为50、特定类与共享类字典数为10、每类训练样本为20,也就是C=100,n=20,d=500,q=50,k=10.假设q2=50.从表1,2可以得出高效FDDL算法相比原始FDDL算法实现低复杂度. 本文在4个公开的数据集上进行实验:AR[22],Extended Yale B[23],CMU PIE[24],FERET[25]人脸数据集.对比的方法主要有SRC[4],LCKSVD[10],FDDL[11],LRSDL[12],SEDL[15],FLRSDLSC*.为了解释联合降维和字典学习的能力,固定降维矩阵的FLRSDLSC*的方式被提出.在所有实验中,主成分分析的方法应用于数据的降维或者初始化SEDL,FLRSDLSC*的降维矩阵.在AR,the Extended Yale B,CMU PIE,FERET和AR性别数据集下,FLRSDLSC模型的训练参数设置如下:λ1,η统一设置为0.001与0.003;λ2分别设置为0.2,0.2,0.2,0.001,0.2;λ4分别设置为0.5,0.3,0.4,0.3,0.5.其分类参数设置如下:w分别设置为1.2,0.1,1,1,0.1;λ1分别设置为0.001,0.3,0.001,0.01,0.01;λ2分别设置为0.1,10,1,1,1. 由实验参数的设置可以看出,式(7)的第1项与第4项对FLRSDLSC的贡献几乎同等重要,说明获得结构化(特定类)字典和防止病态降维的重要性;式(7)的第2,3,5项对FLRSDLSC的贡献相对较小. AR数据库由126个个体的4 000多幅图像组成,这些图像在照明、表情和配件方面各不相同.如文献[15]中所述,使用包含100个个体中的1 400张图像,其中50名男性,50名女性,其人脸图像只存在表情和光照问题.图3展示AR数据集中第1个人的样本图像.每一个个体随机选择7张图片用于训练,剩下的7张图片用于测试.重复实验10次以计算识别率的平均值和相应的标准偏差.所有实验人脸图像大小调整为60×43.在AR数据集上的对比实验中,特征的维度通过PCA降至300. Fig. 3 Sample images of the first subject on AR dataset图3 AR数据集第1个人的样本图像 表3展示不同的方法的识别率.在SRC,LCKSVD,FDDL和LRSDL字典学习方法中,LRSDL达到最佳性能为97.34%,比FLRSDLSC方法低0.5%左右.基于特征和字典联合学习的SEDL方法获得了第3高的识别率为94.21%,比LRSDL方法低3.1%左右,可以得出样本间共享信息的重要性,比FLRSDLSC方法低3.7%,这是因为未考虑样本中共享信息.实验验证我们的方法在光照、表情变化下人脸识别具有鲁棒性. 图4展示了不同维度的识别率.PCA+FDDL,PCA+LRSDL,JDDRDL,SEDL作为基准线进行比较.FLRSDLSC方法与其他方法相比在不同维度下都实现了最佳性能,并且在低维特征的人脸识别上仍然能获得高分类性能,说明在表情和光照下的人脸图像上具有良好的鲁棒性.SEDL和FLRSDLSC方法在特征维数为450~600时识别率缓慢增加,到600维时开始降低,这说明增加维数对字典学习方法可能无效. Table 3 Recognition Rate on AR Dataset表3 在AR数据集下的识别率 Fig. 4 Recognition rate under different dimensions of features on AR dataset图4 AR数据集下不同特征维度的识别率 表4展示用不同数量的样本(4~7)进行训练获得的识别率.FLRSDLSC方法与3种经典方法(FDDL,JDDRDL,SEDL)进行比较,在不同数量的训练样本下都实现了最好的性能.当样本为4时, Table 4 Recognition Rate with Different Numbers ofTraining Samples on AR Dataset FLRSDLSC方法在识别率上比SEDL高出15%左右,并且实现96.1%的准确率,说明对小样本的人脸识别也是有效的.当样本为5~7时,识别率增长地缓慢,但仍然要比其他方法要高至少3%. 图5绘制了FLRSDLSC的收敛图.如图5所示,迭代次数从1增加到100,目标函数值从18.9下降到18.62且函数值在每次迭代中都下降并最终收敛. Fig. 5 The convergence of FLRSDLSC on AR dataset图5 在AR数据集下FLRSDLSC的收敛性 Extended Yale B数据库包含38个个体在各种光照条件下的2 414张图像.图6展示第1个个体在各种照明条件下的样本图像.对于每个个体,随机选择20张图像进行训练,其余用于测试.实验重复10次,所有人脸图像大小都调整为54×48.在Extended Yale B数据库的对比实验中,特征的维度通过PCA降至500. Fig. 6 Sample images of the first subject from Extended Yale B dataset图6 Extended Yale B数据集中第1个人的样本图像 表5展示了不同算法下的识别率.在SRC,LCKSVD,FDDL和LRSDL字典学习方法中,LRSDL达到最佳性能为95.23%,但比基于联合学习的SEDL模型低了1.3%左右.FLRSDLSC*的识别率高于SEDL大约0.2%,说明样本间共享信息对字典学习的重要性.FLRSDLSC方法比FLRSDLSC*高出0.3%左右,这是因为降维时能获得更为紧凑的特征. 图7展现了不同维度下the Extended Yale B数据的识别率,对比方法有PCA+FDDL,PCA+LRSDL,JDDRDL,SEDL.在200~400维时,FLRSDLSC方法比其他算法有显著的提升,再次说明其算法在低维特征人脸识别的有效性.当特征维度为700时,识别率达到最高,说明提高特征维数对字典学习起到了促进作用.与AR数据集不同的是SEDL在不同维度下的识别率比LRSDL高,展示在该数据集下SEDL通过降维和字典学习同时进行的方法能获得更重要的特征,从而加强字典的判别能力. Table 5 Recognition Rate on Extended Yale B Dataset表5 在Extended Yale B数据集下的识别率 Fig. 7 Recognition rate under different dimensions of features on Extended Yale B dataset图7 Extended Yale B数据集下不同特征维度的识别率 表6展示用不同数量的样本进行训练获得的识别率,FLRSDLSC方法实现了最好的实验效果,对比方法有PCA+FDDL,JDDRDL,SEDL.当训练样本为5时,JDDRDL获得第2高的性能,但比FLRSDLSC方法少8%,说明了FLRSDLSC方法对于光照、小样本问题的人脸识别具有鲁棒性.在不同数量的训练样本下,FLRSDLSC都实现了最高的性能.当训练样本为20时,FLRSDLSC只比SEDL高出0.6%,展示了从样本间提取共享信息的重要性. Table6RecognitionRatewithDifferentNumberofTrainingSamplesonExtendedYaleBDataset 表6ExtendedYaleB数据集下不同数量的训练样本的识别率 NumberREC±STD∕%FDDLJDDRDLSEDLFLRSDLSC568.6±2.070.4±1.970.3±1.778.4±1.41083.5±1.885.1±1.586.2±1.290.9±1.02094.4±0.695.7±0.696.6±0.697.2±0.4 CMU PIE数据集包含68个个体的41 368张图像,图像中含有不同的姿态、光照、表情等问题.如文献[15]所述,取CMU PIE数据集的子集(C05,C07,C09,C27,C29)并且每个个体有170张图片.图8展示第1个个体不同姿态下的样本图像.每个个体随机挑选20张图片进行训练,剩下的图片作为测试样本.重复实验10次计算识别率的平均值和相应的标准偏差.所有人脸图像大小调整成60×45.在CMU PIE数据库的对比实验中,特征的维度通过PCA降至500. Fig. 8 Sample images of the first subject from CMU PIE dataset图8 CMU PIE数据集第1个人的人脸图像 表7显示我们的方法实现了最佳性能,识别率为94.21%,比SEDL高出约0.8%,说明样本间的共享信息增强了在姿态、光照、表情问题下的人脸识别.LRSDL与SEDL的性能基本相同,意味着样本间的共享信息与降维和字典学习同时进行的方式都能对鉴别性字典的学习起到促进作用. 图9展示了不同维度下CMU PIE数据集的识别率,对比方法有PCA+FDDL,PCA+LRSDL,JDDRDL,SEDL.我们的方法在200,250维下的识别率要小于PCA+LRSDL的实验结果,但在其他维度上都要好于其他算法,展示了姿态问题对降维和字典同时进行学习的影响.PCA+LRSDL的性能整体上要好于SEDL和JDDRDL,说明LRSDL模型中样本间的共享信息对于解决人脸识别的姿态问题有着重要作用. Table 7 Recognition Rate on CMU PIE Dataset表7 CMU PIE数据集下的识别率 Fig. 9 Recognition rate under different dimensions of features on the CMU PIE dataset图9 CMU PIE数据集下不同特征维度的识别率 Fig. 10 Sample images from FERET dataset图10 FERET数据集样本图像 FERET数据库由14 051张具有不同姿态、光照和表情的图像组成.如文献[15]所述,使用200个个体中带有“ba”,“bj”和“bk”的图像,即使用600张图像进行实验.图10展示了FERET 数据集的部分样本,每个个体使用“ba”和“bj”的图像作为训练集,剩下的一张图片作为测试集.所有图像大小调整成70×60.在FERET数据库的对比实验中,特征的维度通过PCA降至400. 表8展示了在FERET数据集下的识别率.SEDL实现第二高性能比FLRSDLSC*高出0.5%,它保护了投影矩阵的正交性,获得了更紧凑的特征.FLRSDLSC实现了最高的识别率,展示了该方法在光照、表情下人脸识别的鲁棒性. Table 8 Recognition Rate with Different Number ofTraining Samples on FERET Dataset 图11展示了不同维度下FERET数据集的识别率,对比方法有PCA+FDDL,PCA+LRSDL,JDDRDL,SEDL.与AR,Extended Yale B数据集相似,FLRSDLSC在光照、表情下的人脸识别都要高于其他方法且在200维时高于其他方法5%,说明该方法适合解决光照、表情下的小样本问题. Fig.11 Recognition rate under different dimensions of features on FERET dataset图11 FERET数据集下不同特征维度的识别率 AR数据集通常用于性别分类的研究.如文献[15]所述,使用1 400张图像进行实验,其中50名男性和50名女性.我们选择随机选择25名男性和25名女性的图像进行训练,其余图像进行测试,实验重复10次.所有图像大小调整为60×43.在AR性别数据集下的对比实验中,特征的维度通过PCA降至300. 表9展示FLRSDLSC在AR性别数据集下取得最高的识别率并且高于SEDL方法,说明了该方法对光照、表情问题下的人脸识别具有鲁棒性. Table 9 Recognition Rate with Different Numbers ofTraining Samples on AR Gender Dataset 本文提出了一种稀疏约束下快速低秩共享的字典学习(FLRSDLSC)方法.在字典学习阶段,嵌入Fisher判别准则来获得结构化字典,同时嵌入低秩约束获得低秩共享字典;在特征学习阶段,利用Cayley变换保护投影矩阵的正交性来获得紧凑的特征信息.最后,特征和字典进行联合学习促使字典获得更为重要的特征信息,以此增强字典和稀疏编码的判别能力.实验结果表明该方法在表情变化下的人脸识别具有很强的鲁棒性,并对光照起到了抑制作用,尤其适合解决光照、表情变化下的小样本问题. TianZe, born in 1994. Master candidate. His main research interests include machine learning, pattern recognition and computer vision. YangMing, born in 1964. PhD, professor. Member of CCF. His main research interests include machine learning, pattern recognition, image processing and computer vision. LiAishi, born in 1994. Master candidate. His main research interests include machine learning and computer vision(liamgsal@gmail.com). 附录 附录A证明引理1. 先求f(Y,D,X)和g(X)的梯度. 的梯度,其函数重写如下: 其中, 然后我们获得 当目标函数定义如下: 我们推导出: 因此我们获得: Mc-M我们重写为如下2个式子: (A11) 然后推导如下: 现在我们证明 (A12) 然后我们推导出: (A13) 证毕. 附录B. 证明引理2. (B1) 其中, (B2) (B3) 令: (B4) 根据Wj的定义,我们观察到“左乘”矩阵Wj迫使矩阵在除了第j个块行之外的任何地方都为零.同样,“右乘”矩阵将只保留其j块列.从而得到如下结果: (B6) (B7) 其中, 证毕. 附录C. 证明引理3. 当P,Y,D,X固定,我们有 我们得到: 证毕.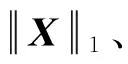
1.2 矩阵秩最小化理论


2 稀疏约束下快速低秩共享的字典学习
2.1 FLRSDLSC模型构建
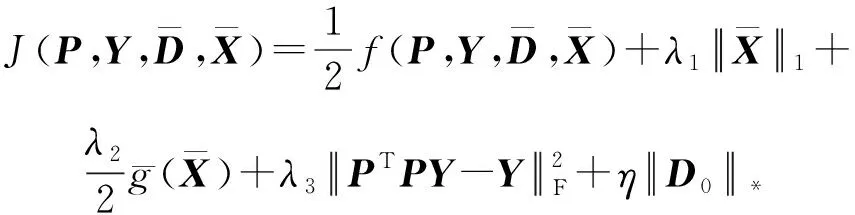
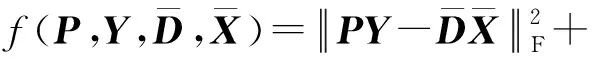


2.2 FLRSDLSC模型求解
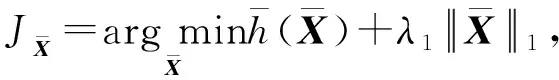

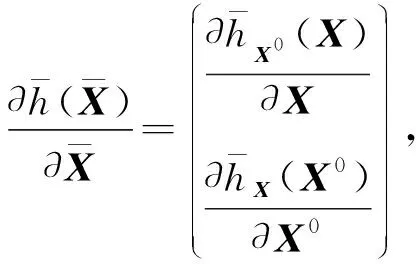
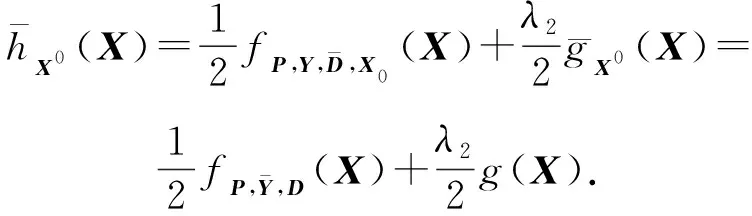
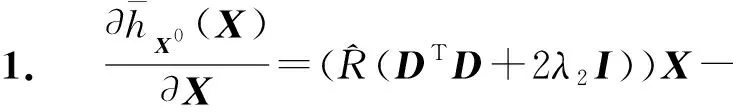
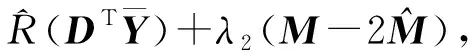


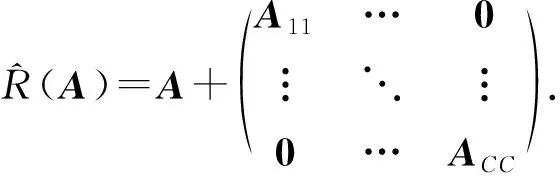
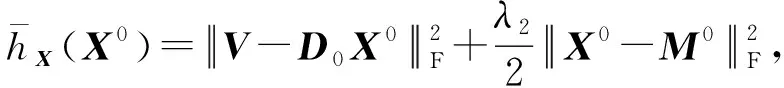
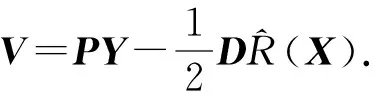

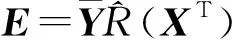

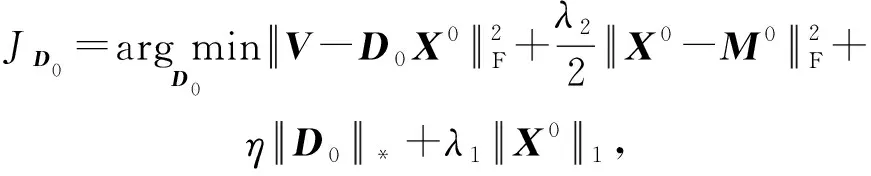
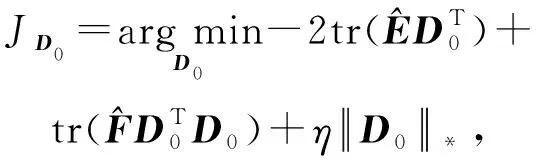
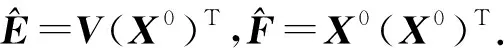
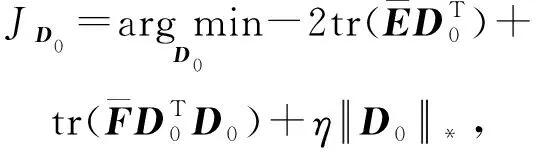
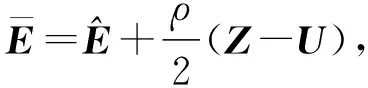
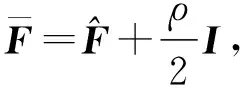

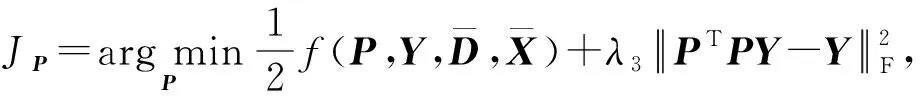
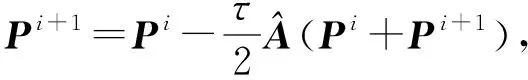
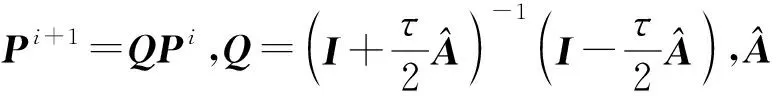

2.3 FLRSDLSC模型的分类



2.4 FLRSDLSC算法

3 复杂度分析
3.1 Fisher判别准则下的字典学习(FDDL)

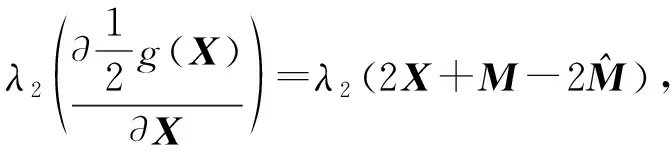



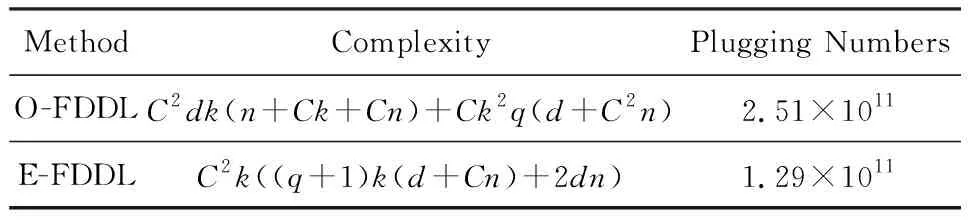
3.2 复杂度计算
4 实验与结果
4.1 AR人脸数据集



4.2 Extended Yale B数据集



4.3 CMU PIE数据集


4.4 FERET数据集

4.5 AR性别数据集
5 总 结