语音识别领域的特征提取技术专利分析
2018-07-31么旭君
么旭君 安 飞
一、全球专利状况分析
(一)申请趋势
语音识别中的特征提取技术相关申请始于20世纪80年代,并从19 86年开始,该领域有了持续的专利申请。图1显示了从19 86年至2016年的申请量按最早申请日/优先权日的年度分布的情况。
从图中可以看出,语音识别领域的特征提取技术自19 86年开始萌芽。最先提出相关申请的有美国和日本的申请人,使用的特征提取技术包括L P C线性预测编码、基于字典的方法等,且申请量在此后一直呈逐渐上升趋势;从19 9 7年开始,随着语音识别技术的大规模兴起,特征提取技术的专利年申请量开始持续增长,并于2000年突破120件;2004~2007年申请量有所回落,保持在100件左右,这可能和技术发展的遇到瓶颈有关;2008年之后,随着语音识别技术飞速发展,全球申请量有了持续的大规模涨幅,从2008年的132件达到2016年的年申请量235件。

图1 全球专利申请量年度变化图
(二)区域分布
1.产出地专利布局
图2为全球专利申请产出地分布图。可以看出,我国在语音识别领域的特征提取技术上非常活跃,申请量近千件,接近居于第二位的美国和第三位的日本的申请量之和,居世界首位。美国和日本在特征提取技术上的申请量也较多,申请量都超过了500件。而产自韩国、德国以及英国的申请量偏低,韩国不足两百件,德国、英国不足100件。
2.产出地申请趋势
可以看出,美国在语音识别领域的特征提取技术上起步较早,在19 9 8~2004期间处于领先地位,申请量保持在25件左右,于2004年~2006年期间申请量略有下滑,于2007年开始有所回升,并于2007~2009年再次保持在年申请量25件左右,2009~2014年申请量有所增加,至2014年达到申请量的顶峰,为52件。日本在该领域研发也较早,发展规律与美国类似,在19 9 8~2015年期间年申请量一直保持在25件左右,只于2004年和2007年略有波动。我国在该领域起步较晚,2004年之前的年申请量处于10件以下,在2004~2007年有所增长,2007年达到18件,并于2007年之后呈现出快速增长趋势,年申请量远超其他国家,于2016年达到年申请量212件。总体上,美国、韩国、日本的申请量在2012年之前都保持基本稳定,在2012年至今申请量取得了一个小幅度上升,而我国的专利申请量从2008年开始呈增长趋势并远超其他国家,此外,近三年的申请量则受到公开滞后因素的影响。
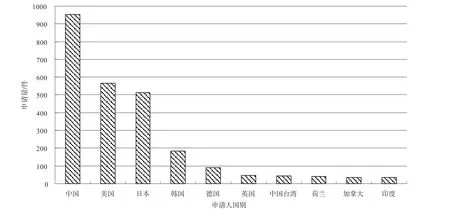
图2 全球专利申请产出地分布图

图3 全球主要产出地近20年申请量年度变化图
3.产出地专利布局

表1 主要产出地的专利布局区域分布
表1是主要产出地的专利布局区域分布情况。语音识别领域的特征提取技术主要产出地为日本、美国、韩国和中国,各产出地普遍重视在本国和美国进行专利布局,可见美国是语音识别领域最重要的市场之一。此外,我国的大多数申请都集中在本国,向国外申请的专利数量较少,需要更加重视在国外进行专利布局。
4.目的地申请趋势
图4为全球专利申请目的地分布图。其中将我国作为目的地的专利申请占比最高,达到26.5%,可见各国申请人对我国市场的重视程度。此外,美国申请量也较多,与中国相差并不大,可见美国市场也是语音识别领域的重要市场。这样的分布除反映市场的受重视程度外,另一方面,申请量受到该国本国申请人以及技术水平的影响,上文已经分析过,我国产出量在近10年显著增长,并且以本国为目的地的申请占据了大部分比重,这也是我国作为全球专利申请目的地占比最高的一个因素。因此,上述国家和地区中,市场竞争主要集中在本国和处于市场主导地位的美国,我国作为新兴市场,也已经成为各国申请人进行专利布局的主要地区。

图4 全球专利申请目的地分布图
(三)主要申请人
1.主要申请人分布
图5为全球主要申请人分布。在排名前20的申请人中,有6位中国申请人,6位日本申请人,4为美国申请人,3位韩国申请人和1位荷兰申请人。日本申请人数量最多,并且申请人的申请量排名靠前,东芝公司的申请量居于首位,为65件,索尼公司申请量为53件,都远超其他申请人,可见日本在语音识别领域的研究较为深入。中国的6位申请人中,包括联想、华为、中兴三家公司和中科院等三家科研院所,这体现了我国企业和高校对技术研发方面的发展程度和对专利申请的重视。此外,中国申请量排名第1位的联想公司在全球申请人中排名第8位,可见我国申请人数虽然较多,但是在数量上距离世界先进水平仍有差距,存在一定的提升空间。

图5 全球主要申请人分布
2.主要申请人申请趋势

表2 主要申请人申请趋势单位/件
表2示出了全球重要申请人微软、东芝、韩国电研、联想、索尼这五位申请人的申请趋势情况。可以看出,在2004年之前,我国的联想公司的申请量一直处于领先地位,19 9 9~2000的申请量为2~3件,2003年增长至5件,2005年之后联想公司的申请量有所下降,2006至2016年的申请量0~2件波动,申请量不大,这可能与该公司的主要研究方向有关。韩国电研起步较晚,从2001年开始申请量从0逐步增加至2007~2008年的7件,于2010年降至1件,2011年回升至5件,此后的2012~2016年申请量在0~2件波动,可能不再侧重特征提取领域的研究。微软公司的申请量波动较大,19 9 8~2000年起步期间的申请量为1~2件,2001年申请量为0,2002~2003年逐渐增加至4件,2005~2006年申请量下降为1件,并于2007~2008年逐渐增长至6件,2008~2010年逐渐下降为1件,并于2011年申请量再次增加至4件,2012年申请量为0,2013~2014年再次增加至4件,这样的波动可能是由于其技术研发周期长或有多项技术同时研发造成的。东芝公司起步也较晚,2005年之前为其起步期,申请量在2件以内,2005~2009年逐步增加至5~6件,2009~2013年降至2~3件,并于2013~2015年维持在1件。各公司2016年申请量较少与其研究重点和技术布局有关,也可能与专利尚未公开有关。
二、中国专利状况分析
(一)趋势分析
1.专利申请趋势

图6 中国专利申请量年度变化图
图6显示了我国语音识别领域的特征提取技术专利申请量的年度变化情况。从图中可以看出,从图中可以看出,在2000年之前,我国的语音识别领域的特征提取专利年申请量很小,都在60件以下,从2002年开始,年申请量开始有所增加,其中以国外来华申请为主。从2010年开始,年申请量开始迅速增加,2012年至2014年申请量稳定在160件左右,2016年增长至180件。从国内申请量和国外在华申请量对比来看,2008年以前,我国的语音识别领域的特征提取专利主要以国外来华申请为主,国内申请比重较小。2008年国内申请量首次超过国外在华申请量,并从2012年开始摇摇领先于国外来华申请。可以说,2010年之后我国语音识别领域的特征提取专利数量的迅速增长主要来自于国内申请的迅速增长。
2.专利授权趋势

图7 中国专利授权趋势图
图7展示了语音识别领域特征提取技术相关专利的授权趋势图。由图可知,2010年之前我国授权量较低,虽略有波动但一直不足10件,2010年之后有了显著增长,2011年增长至33件,2012~2013授权量略有下降,分别为25件和23件,2014年再次增长至36件,2015年下降至27件,并于2016~2017年逐渐上升至36件。授权量在2010年的大幅度增长与该领域的申请量在2008年之后迅速增长有关,其后的授权量波动也与申请量的波动有关。总体上,授权量在2010年之后大幅度提高,这与该领域技术的发展和申请量的趋势一致。
(二)申请人区域/省市分析
1.国外来华申请国家分析
图8显示了国外来华申请人区域分布情况。可以看出,日本申请人所占比例最大,达到38%,美国仅次于日本,占27%,韩国占9%,说明日本、美国和韩国比较重视中国市场,这也与这三个国家在语音识别领域的研发实力相统一。

图8 国外来华申请人区域分布图
2.国内申请省市分析
图9显示了国内申请人的省市分布情况。可以看出,北京所占比例最高,达25%,反映出北京在语音识别领域特征提取技术方面研发实力最强,这也与大量相关企业、高校和科研院所位于北京有关。接下来分别是广东、江苏和上海,分别位于我国长三角和珠三角,这两个地区科技发展速度快,研发实力也比较强,集中了国内有优势的高校如浙江大学、华南理工大学等,代表了国内语音识别领域特征提取技术的整体实力。
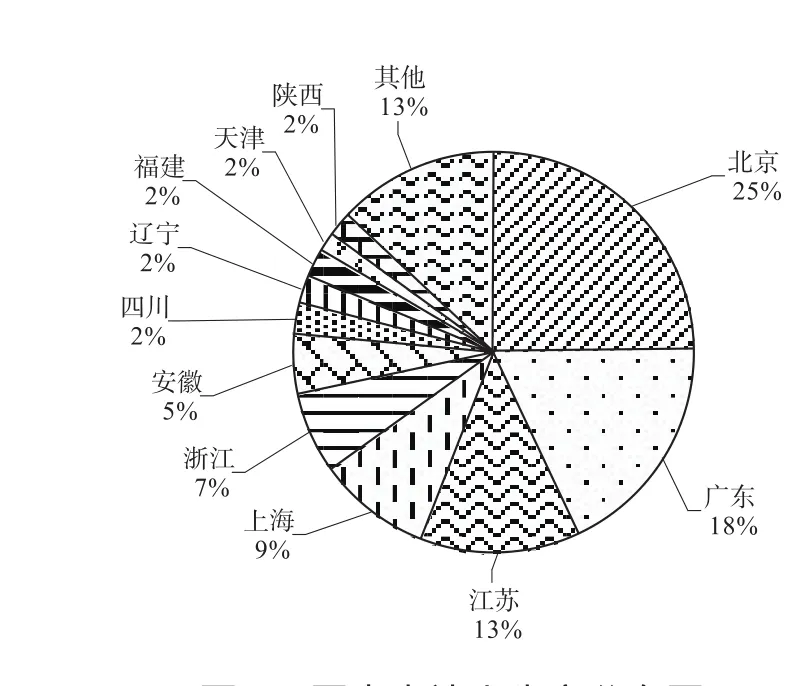
图9 国内申请人省市分布图
(三)申请类型和法律状态
1.法律状态(授权、驳回、视撤、在审、终止)

图10 中国专利申请的法律状态
图10展示了申请人在华专利申请中发明专利申请的法律状态。从图中可以看出,授权专利在处理中的专利申请占比最高,占比39%;其次是处理中的专利申请,占比33%;权利终止的专利申请在13%左右,其余各种失效状态的占比较少。
2.申请类型
图11显示了国内申请的申请类型分析情况。从图中可以看出,对于语音识别特征提取技术领域的专利申请中,发明专利申请所占比重极大,为9 9%,实用新型专利申请仅占1%。

图11 申请类型分布
(四)主要申请人
1.申请人类型
如图12所示,大专院校和企业的申请占据了申请量的绝大部分,其中专利申请人中大专院校所占比例最大,为55%,代表了我国高校在语音识别领域特征提取技术上的科研实力。其次是企业申请,占比41%,证明了我国企业的科研实力和对专利权保护的重视。之后是科研单位和个人申请等,差距量不大,占比在6%~8%。

图12 申请人的类型分布
2.申请人排名

表3 中国专利申请的主要申请人排名
表3列出了中国专利申请的前15位申请人的分布情况。其中中国申请人11位、日本申请人3位,美国申请人1位。中国的11位申请人中有6位高校及科研院所申请人和5位企业申请人,体现了我国企业和高校对技术进步、专利保护的重视程度;国外申请人中微软公司的申请量最多,为12件,其次是日本的松下电器产业株式会社和索尼公司,申请量都为9件,这在一定程度上反映了国外申请人对我国市场的重视。前15位申请人的申请总量占全部中国专利申请总量的28.8%,还有大量申请分布在中小企业和高校及科研院所,这反映了还有大量中小企业和科研院所处在研发的起步期,我国申请人在语音识别领域特征提取技术上还有进步空间。
3.申请人申请趋势
纳入标准:(1)患者肝、肾等功能正常。(2)患者有焦虑症状,SAS评分>50分。(3)有正常语言表达和理解能力。
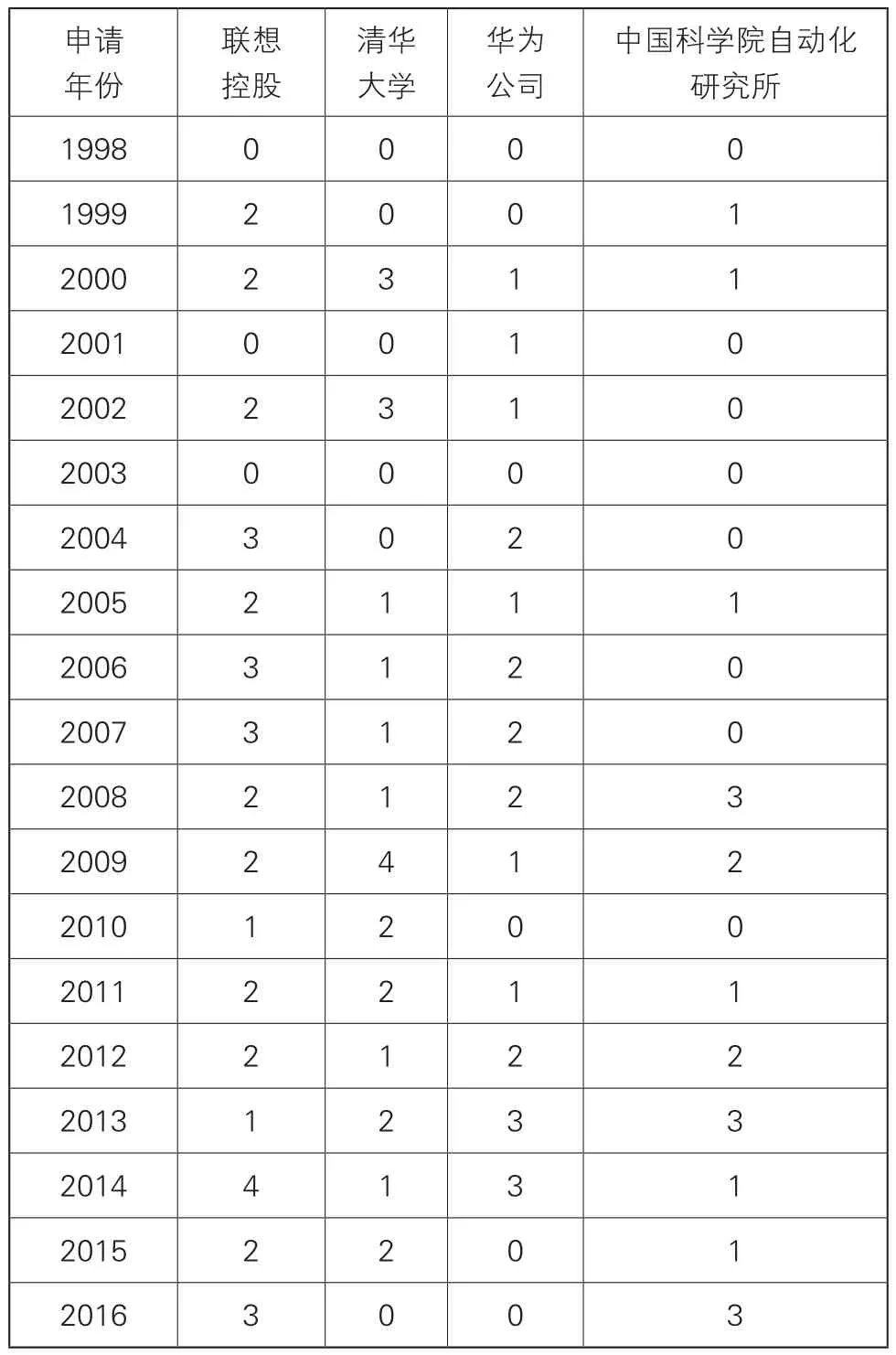
表4 主要申请人申请趋势
中国申请的重要申请人以我国申请人为主,表4选取了重要申请人进行分析,示出了联想控股、清华大学、华为公司、中国科学院自动化研究所四位申请人的申请趋势情况。可以看出,在2005年之前,四位申请人的申请量都在0~3件,我国在语音识别领域特征提取技术上还处于萌芽阶段。从2005年开始,我国在该领域有了初步发展,申请量有所增加,每位申请人的申请量维持在每年2~3件。从2011年开始,我国在该领域进入蓬勃发展阶段,除表中所示的四位申请人之外,还有一批中小型企业和高校的申请量也值得一提,如安徽科大讯飞公司在2012年的申请量为8件,华南理工大学在2013年的申请量为6件,虽然这些申请人的总申请量还不高,但已经体现了其科研实力和知识产权保护意识,也为该领域的进步做出了一定的贡献。而上表中的几位申请人在近几年的申请量总体呈下降趋势,这可能也和该公司的研究方向有关。
五、重点技术分析
通过对我国语音识别中的特征提取技术专利分析可知,目前常见的特征参数包括基于线性预测编码系数(Linear Predictive Coding,LPC)、线性预测倒谱系数(Liner Predictive Cepstrum Coefficient,LPCC)和基于人耳听觉原理的梅尔频率倒谱系数(Mel-Frequency Cepstrum Coefficient,MFCC),以上参数都能够获得很好的语音个性特征,根据特性不同,分别用于不同的系统中。同时,LPC、LPCC 和MFCC 还有着技术上的递进顺序,其中MFCC 是目前语音识别中广泛使用的特征参数之一。MFCC 是在80 年代由Steven.B.Davis 提出的,它是将信号短时频谱先在频域将频率轴变换为梅尔频率刻度,再变换到倒谱域得到的。当前很多类型的声音辨识是采用MFCC、MFCC的差量(一阶变化量)以及MFCC 的次差量(二阶变化量)的组合,或上述值的线性变换为特征参数,因此具有可观的研究价值。
在探究MFCC的技术发展路线之前,需要进一步理解MFCC参数的计算过程。MFCC是基于人耳听觉模型建立的倒谱系数,人的听觉系统是一个特殊的非线性系统,它响应不同频率信号的灵敏度是不同的,通常是一个对数关系。也就是说,人耳对不同频率的语音具有不同的感知能力,声音的物理频率表示单位是梅尔(Mel )。Mel刻度表示了人耳对于频率感知的非线性特性,根据人类听力的临界带效应,设计若干个具有三角形或者正弦型的带通滤波器,然后把语音处理成能量谱,再输入到该滤波器组。通过取对数,作离散余弦变换,就能得到MFCC系数。具体如图13所示:

图13 MF C C参数的计算过程
具体可以解释为:
(1)将语音信号,即时域信号进行傅里叶变化(DFT),求出线性频谱;
(2)将得到的线性频谱经过梅尔滤波器组形成Mel频谱;
(3)然后经过对数能量处理,得到对数频谱;
(4)将对数频谱经过离散余弦变换((DCT)得到倒谱频域,即可得到Mel频谱倒谱系数,即MFCC参数。
近些年,在特征提取领域MFCC是最常用的特征参数,因此下面将针对MFCC的技术发展路线分析其技术重点和研究方向。
2012年,国际商业机器公司提出了一种声音特征量提取方法(CN 1024839 16A),该申请针对傅里叶变换后的频谱信息,使用线性域的差分作为声音的差量特征量及次差量特征量,以此计算MFCC参数,通过该方法可提取较先前技术更能抗回音及噪音的特征量,且其结果可改善声音辨识的正确率。该方法具体为获取输入声音信号的各频率的频谱,对于各帧,对上述各频率算出前后的帧间的频谱的差分,作为差量频谱;通过将上述各频率的差量频谱除以该频率的总发音即平均频谱的函数而正规化,将输出设为差量特征量,最终计算出MFCC参数。
对于输入端进行改进的还有2016年联想公开的一种MFCC提取方法及装置(CN 105513587A)。该申请是针对现有技术里,在提取MFCC的过程中,无论语音数据帧的大小,均采用固定的量化位数对每一帧语音数据帧进行定点化处理(包括放大处理),而对于能量较小的语音数据帧,即使放大后,数据范围还是很小,因此,在通过后续各处理步骤的累积后,形成的误差依然不可忽视。因此,该发明依据语音数据帧的范围,确定第一处理参数,并使用所述第一处理参数,放大经过预处理后的语音数据帧,随后提取放大后的语音数据帧的MFCC,也就是说,在进行MFCC提取之前,先将数据帧进行放大,并且因为第一处理参数与所述预处理后的语音数据帧的数据范围反相关,即语音数据帧的数据范围越小,第一处理参数越大,所以,对于能量较小的语音数据帧,在进行定点化时,比能量大的数据帧放大的程度更大,因此大数据帧比小数据帧更能抵消定点化带来的误差,提高从小能量的语音数据帧中提取到的MFCC的精度。

图14 MF C C技术发展路线图
针对梅尔滤波器的设置方式,2009年,北京中星微电子有限公司公开了一种语音信号的MFCC系数提取方法、装置及一种Mel滤波方法(C N 101577116A),该发明为解决H T K的MFCC系数提取方法中子代数量不匹配的问题,特地在进行Mel滤波时,增加Mel滤波器组的子带数量,在频率范围内进行Mel滤波,得到对应每条子带的Mel滤波输出;然后,将高频范围内的子带数量进行聚合,得到聚合后相应子带数量的Mel滤波输出;随之继续对低频范围和聚合后高频范围的Mel滤波输出进行非线性变换和离散余弦变换,最终提取出MFCC系数。该发明既保证了低频信号有足够的频率分辨精度,同时,又将高频范围内的子带数量进行聚合,提高了高频的抗干扰能力,从而优化了提取的MFCC系数,能够语音识别的准确率。
在随后的2013年,百度提出了一种MFCC特征的提取方法及装置(CN 10339 0403A),从其他角度优化了MFCC参数的计算方法。该方法为通过令Mel滤波器组中包括高频段Mel滤波器,对经过预处理的音频信号进行过滤处理,以生成Mel域高频分量,进而对所述Mel域高频分量进行离散余弦变换,以生成每个所述Mel域高频分量的变换特征,使得能够根据每个所述Mel域高频分量的变换特征,获得所述音频信号的MFCC特征,由于利用Mel滤波器组中所包括的高频段Mel滤波器,对经过预处理的音频信号进行过滤处理,可以获得Mel域高频分量。该方法能够去掉容易受环境影响的Mel域低频分量,使得从测试数据中提取的MFCC特征与从训练数据中提取的MFCC特征不会存在较大差异,从而提高了MFCC特征的鲁棒性,是我国申请人在特征提取技术上作出的又一项改进。
接着,2015年联想公开了一种语音特征信息的提取方法及电子设备(CN 1049 00227A)。该发明获取与语音信息对应频率宽度中的信息分布参数,基于所述信息分布参数,确定三角带通滤波器组在频谱上的分布系数,根据分布系数,将三角带通滤波器组分布在频谱上进行滤波,获取Mel频谱,基于所述Mel频谱,获取Mel频率倒谱系数MFCC。由于三角带通滤波器组是根据所述信息分布参数来所述频谱上进行分布的,使得所述频谱中携带信息量多的频带设置较多的三角带通滤波器组,以及携带信息量少的频带设置较少的三角带通滤波器组,从而解决了现有的电子设备在获取语音特征信息时,存在不能根据实际情况自动调整三角带通滤波器组的分布的技术问题。
针对得到对数频谱后再进一步进行处理的申请包括:2014年,华南理工大学提出了一种结合局部与全局信息的语音情感特征提取方法(C N 103531206A)。该发明针对忽略Mel滤波器内部能量分布信息以及每一帧不同滤波器结果之间的局部分布信息造成的对噪音敏感的问题,提出了以下改进:(1)将语音信号分帧;(2)对每一帧进行傅立叶变换;(3)使用Mel滤波器对傅立叶变换结果滤波,对滤波结果求能量,并对能量取对数;(4)对取得的对数结果使用局部H u运算,获得第1类特征;(5)对局部H u运算后的每一帧进行离散余弦变换,获得第2类特征;(6)对第3步计算的对数结果进行差分运算,然后对差分结果的每一帧进行离散余弦变换获得第3类特征。该发明可快速有效地表达各类情感的语音,应用范围包括语音检索、语音识别、情感计算等领域。该申请的发明构思为:在语音情感不同时,发音清晰度、基音变化程度、发音强度、语速都会发生相应的变化,这些变化将改变语谱图能量的集中程度,如发音比较清晰、发音强度高时语谱图能量比较集中。而H u的一阶矩恰好能够评价数据能量集中到数据重心的程度,这样能够很好的提取语音情感变化时导致语谱图上能量集中度发生的变化。另外情感发生变化时会改变语音信号的频率分布,从而在语谱图的频率轴上发生变化,所以该发明使用频率轴上的导数来提取这些变化。
随后,河海大学2017年还公开了一种基于对数谱信噪比加权的鲁棒特征提取方法(C N 106373559 A)。该发明首先对输入语音进行声学预处理、短时谱估计和Mel滤波,得到每一帧的短时Mel子带谱;再利用改进的对数函数对Mel子带谱进行非线性变换,得到对数谱,同时从Mel子带谱中估计输入语音的对数谱域信噪比;然后,利用估得的对数谱域信噪比对输入语音的对数谱进行加权,得到加权对数谱;最后,对加权对数谱进行离散余弦变换并作时域差分,得到输入语音的特征参数。该发明提高了噪声环境中提取的特征参数的环境鲁棒性,减小加性噪声对语音识别系统的影响。
当前,对于MFCC参数计算过程中对于特征的二次提取也备受申请人关注。2017年,电子科技大学公开了一种基于基音周期和MFCC的融合特征参数提取方法(C N 106782500A)。该发明通过增加Mel倒谱参数的维度来提高声纹识别效率,具体为通过每一帧语音数据获得该帧语音的Mel倒谱参数,Mel倒谱参数的一阶差分参数,二阶差分参数以及该帧的说话人基音周期参数,将这四个参数结合成一个(3L+1)维的特征矢量,这样更逼近语音的动态特征和人体的生理结构,可以提高声纹识别的效率。
2017年,重庆邮电大学公开了一种基于融合特征M GFCC的说话人二次特征提取方法(C N 107274887A)。该发明首先利用Mel滤波器对说话人语音进行处理得到MFCC特征;其次,同时利用Gammatone滤波器对说话人语音进行处理得到GFCC特征;然后,对两种特征在噪声环境下的各维特征区分度进行计算;接着,统计两种特征的每一维特征处于最大F R值的次数;随之根据两种特征在噪声背景下的最大次数的不同进行特征融合;最后对融合特征进行微分和重组得到二次提取特征。该发明可以在复杂噪声环境下依然有较好的识别,并且较强的鲁棒性,能够进一步提取出说话人的隐藏特征,在较大程度上提升了说话人识别系统的性能。
2017年,苏州大学公开了一种用于语音测谎系统中的稀疏谱特征提取方法(C N 10729 3302A)。该发明首先提取语音信号的梅尔频率谱系数、小波包频带倒谱系数,并融合所述梅尔频率谱系数和小波包频带倒谱系数构成倒谱特征;其次,采用K-奇异值分解算法对倒谱特征进行训练得到混合过完备表示字典;然后,在混合过完备表示字典上,采用正交匹配追踪算法对倒谱特征进行稀疏编码,获取稀疏谱特征。该发明一方面可以弥补传统梅尔频率谱系数提供中高频段信息存在的不足,另一方面可以解决非线性融合参数集的冗余问题,降低分类模型的计算复杂度。
综上所述,在对特征参数选择的问题上,目前主流的研究热点是基于人耳听觉特性的梅尔倒谱系数(MFCC),并且对于提取MFCC参数的改进基本集中在对于输入端数据的过滤、对于滤波器的设置个数和位置、计算过程中对于特征的二次提取方式。分析表明,我国高校对于特征提取技术有着持续的关注,且近几年能够不断提出价值较高的技术方案。同时,百度和联想等涉及人工智能领域的国内大公司也对特征提取技术保持着研究。
六、企业建议
通过以上对于语音识别技术中特征提取技术的专利分析,可知我国在该领域高校的研究热情较高,且其专利价值也较为客观。同时,我国涉及人工智能的大公司也对其保持着持续的研究和关注,但鲜有在国外的专利布局。因此,结合我国的技术现状给出如下企业建议:
(1)宏观上讲,国内公司应当加强校企合作,从技术和人员储备、产品研发等环节,与涉及研究特征提取技术的高校合作;积极拓展全国知名高校的合作意向和研究领域,以高校技术为依托,企业加强资金投入和产品研制,在全国建立多个技术研究的研发中心。尽可能地把科研成果转化为可以带来经济效益的生产力,同时提高教学质量和科研水平,在实践中培养高科技人才,促进学校、企业和社会的共同进步为目标,在优势互补、平等合作、互惠互利、共同发展的基础上建立全面的校企合作关系。
从技术方面来说,通过上述分析,企业应该吸取高校对于特征提取研究中涉及多算法融合技术的相关技术方案。高校科研工作通常擅长算法研究和模拟仿真,对于提高特征提取精度、鲁棒性,提高计算效率、降低复杂度,所提出的方法通常是十分有效,因此具有客观的借鉴价值。
(2)企业应当培养专业的科研型人才,企业创新的快速发展离不开对专业人才的培养。首先,可以加强与国外人才的交流与合作,借鉴欧美发达国家的先进经验,培养具有创新精神的研发人才,引进高水平的研发管理系统,在积累企业先进技术的同时解决技术研发过程中遇到的问题。
(3)鼓励对外专利申请,加快走出去的步伐。近年来,我国在该领域的申请数量连年上升,但在国外专利申请上竞争力仍显得较为薄弱。未来,我国申请人应当考虑目标市场、国际同行等多种因素进行布局,在布局时不拘泥于现有市场和格局,而是着眼于长远,适当先于市场,注重海外专利布局能力,利用创新型企业强大的科研实力,抢占国外发达国家专利申请的领域。
七、结束语
语音识别的研究工作对于信息化社会的发展和人民生活水平的提高等方面有着深远的意义。本文通过对语音识别领域特征提取技术的相关专利进行分析,对我国企业的研究方向和专利布局给出了建议。未来语音识别技术将会取得更多重大突破,特征提取技术的研究也会更加深入,是值得我国申请人关注和研究的重点。
