基于移动用户出行数据的城市热点挖掘算法
2018-07-30焦君
焦君
(广州杰赛科技股份有限公司,广东 广州 510310)
1 引言
出租车或者浮动车的GPS数据是当前城市热点挖掘的主要数据源,基于出租车或者浮动车GPS数据对城市热点进行研究,目前已经取得一定的成果:秦昆[1]等人利用出租车的GPS数据构建城市区域的空间交互网络,在此基础上实现城市热点的社团探测,从而识别城市热点;李婷[2]等人通过分析传感器的位置数据提取城市热点区域,为城市居民的出行提供参考;杨格格[3]等人采用出租车的GPS数据,提取北京对外交通枢纽的乘客OD时空分布特征;赵鹏祥[4]通过研究城市出租车轨迹的时空特性,构建多模式的城市道路网络模型,实现基于轨迹聚类的城市热点提取;Zou[5]等人采用浮动车的数据分析城市道路的热点区域和冷点区域,为城市规划和交通控制等领域提供数据支撑。但是出租车、浮动车等交通工具采集的数据量有限,且基于GPS方式产生的数据计算复杂度过高,不利用大面积推广应用。针对上述问题,本文尝试采用移动用户出行数据进行城市热点提取。移动用户出行的数据具有广域、海量、实时性强、提取方便等优点,实验表明,能够比较真实地反映一个城市的热点分布以及人口驻留现象。
2 移动用户出行数据研究
2.1 移动用户出行规律
移动用户的出行规律是指通过提取移动用户发生业务的时间与位置信息而得到的移动用户出行行为特征。胡永凯[6]通过提取移动通信网络的信令数据,并将原始信令数据的位置划分到预先定义好的交通小区里,克服由于基站覆盖范围的变化而导致用户轨迹与实际轨迹出入太大的情况,从而提升移动用户出行出发地和出行目的地(OD, Origin and Destination)匹配的方法精度,实现移动用户出行规律的研究。Schlaich J采用时间序列方法对移动用户的手机信令数据进行处理并获取移动用户的出行轨迹,通过对移动用户轨迹的叠加获得整个城市范围内的用户出行信息点(POI, Point of Information),为交通规划领域提供数据支撑。李耀辉[8]利用移动用户的信令数据提取移动用户的轨迹,并通过交通小区语义化以及DBSCAN聚类的方法识别用户聚集区域,实现居民出行目的的判断。本文借鉴相关学者的研究成果,对移动用户出行规律进行定义:根据移动用户的信令数据,对移动用户的时间-位置序列进行提取并排序,形成动态移动用户轨迹OD向量,根据上述的用户的OD向量获取移动用户的驻留区、移动区,从而为城市热点提供基础数据。
2.2 基于移动用户信令数据的OD分析
目前基于移动信令数据的OD分析研究主要集中在用户的出行端点识别,也就是根据基站切换的位置来表示用户的出行开始点和结束点,每一个OD的结束站点也是下一个OD的开始站点。目前,基站的覆盖面积大多数假设是泰森多边形假设、六边形假设以及扇形假设。在处理移动用户的出行端点时,一般以多边形的中心点表示用户所处的位置。部分移动用户的OD出行表如表1所示。
在获取移动用户出行OD位置点的基础上,采用时间序列方式对上述OD位置点进行排序,形成移动用户的出行轨迹。在获取移动用户轨迹后,采用关联规则的方法获取移动用户关键的OD站点,以便找到移动用户频繁出现的OD站点,剔除一些随机发生的OD站点。本文采用Apriori算法挖掘移动用户关键OD站点,完成移动用户出行数据的预处理。
2.3 基于移动用户出行数据的空间交互网络研究
在分析每一个移动用户的关键OD节点后,可以从个体和聚集两方面进行研究。在聚集层面上,可以根据众多移动用户的OD数据反映每一个区域的交互特性。这个区域是以基站为节点的,以移动用户频繁移动产生的交互为边,产生了一个无向带权网络G=(V,E,W),其中V表示基站节点集合,E表示移动用户在移动过程中产生的交互集合,W表示边权重集合。本文以关键OD点构造用户出行的空间交互网络。
2.4 城市热点挖掘的算法研究
城市热点挖掘实质上是通过一些信息化的手段监测不同地区的“准实时”人流变化情况,并根据不同区域的特点给出人群的特征分布。从上述的定义可知,城市热点具有动态、实时的特点。因此,采用传统的监督分类的方法来识别不同时间段的热点区域分布是不现实的。本文尝试采用一种半监督的方法,采用少量具有标签的热点区域的特征去捕捉整个城市的“准实时”的热点区域分布。
标签传播算法(LPA, Label Propagation Algorithm)的核心思想非常简单:依靠节点自身的相似性,在传播过程中,未标记节点根据邻居节点的标签情况来迭代更新自身的标签信息,如果邻居节点与未标记节点的相似性越高,那么对未标记节点的影响权值越大,邻居节点的标签更容易进行传播,并且相似的数据应该具有相同的标签。LPA算法包括两个流程:
(1)构造相似矩阵。LPA算法是基于图G=(V, E),在对上述的移动用户出行数据构建一个图后,图中的节点V代表基站个体,节点包含“标签”数据和“无标签数据”,具有“标签”的数据一般通过人工经验设定。E代表节点所在的边,表示基站之间的相似度。根据节点之间的相似度,构造的相似性矩阵如下:
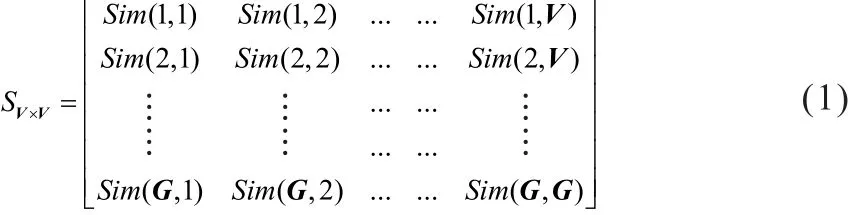
本文所描述的基站相似度是基于移动用户的签到数据的交集进行计算的,考虑了移动用户共同签到的基站的特性,类似于一些网站采用Jaccard算法来挖掘博客相似浏览,因此,本文采用Jaccard算法来衡量基站之间的相似性:

F(u)表示在某个时间段内与基站u具有切换关系的邻居基站数量;F(v)表示在某个时间段内与基站v具有切换关系的邻居基站数量;F(u)∩F(v)表示在一段时间内与基站u和基站v都具有切换关系的基站数量。同理,F(u)∩F(v)表示在一段时间内与基站u或基站v具有切换关系的基站数量之和。上述的相似性仅仅考虑了某个区域领域的移动用户在某一个时间段内共同签到的基站与全部签到的基站占比情况。上述情况是没有考虑到基站的交互次数,也就是有多少比例的移动用户在两个基站之间的切换关系。通过Jaccard相似度计算相似矩阵中两两基站的相似度,最终构造LPA的相似矩阵。
(2)通过标签的传播找到相同标签的数据,标签相同的标签归为一组。每个节点都以一定的概率传播给其他节点,如果两个节点的相似度越高,那么对方的标签越容易被自己的标签赋予。由于事先确定的标签是具有不变性,因此,随着具有标签数据不断将自身的标签传播出去,最后类边界会穿越高密度区域,而停留点则会留在低密度区域中,相当于每一个类别都随着标签的传播划分自己的范围,最终形成了一个类别。
(1)节点相似性度量
在构建空间社交网络后,通过对空间交互网络的交互指标进行分析,实现城市热点的挖掘。当前,城市热点挖掘的相关研究有:通过轨迹聚类方式实现城市节点提取[4];根据位置签到数据的聚类方法提取城市热点[9];利用位置签到数据实现POI显著度计算,再利用邻域分析和相关指标的统计,实现提取城市特点的目的[10]。本文的城市热点挖掘算法是基于空间交互网络实现的,首先,通过分析每一个节点的邻居节点的Jaccard相似度来衡量节点之间的关系,其次,采用重叠社团划分的方法来实现对社团的探测。以空间交互网络的内聚子图来反映城市的热点区域,体现城市商圈的特性。
经过归一化处理之后,基站u和基站v的相似度为:
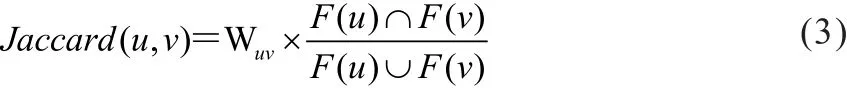
其中Wuv表示基站u和基站v之间的权重,表示基站之间的交互次数,等于某个时间段内移动用户从基站u进入基站v或者从基站v进入基站u的人数除以基站u和基站v的移动用户数之和。
(2)基于节点相似性的社团发现算法
经过节点的相似性度量后,构造空间交互网络的相似性矩阵。通过标签传播算法(LPA, Label Propagation Algorithm)来实现社团探测,以网络的内聚子图来构成城市热点区域。LPA的基本思想是依靠节点自身的相似性,在传播过程中,未标记节点根据邻居节点的标签情况来迭代更新自身的标签信息,如果邻居节点与未标记节点的相似性越高,那么对未标记节点的影响权值越大,邻居节点的标签更容易进行传播。
第一步,基于节点相似性计算传播概率,构建节点之间的传播概率传播矩阵P:

Pij表示从节点i转移到节点j的概率。在标签重读次数相同的情况下,节点i对节点j的传播概率越大,那么节点j的标签越有可能被节点i选中。上述公式是第一次迭代的概率,随着迭代次数的变化,节点之间的传播概率是动态变化的。
第二步,通过事先确定的标签,构造标签矩阵。假设事先定义C个类别和L个具有标签的样本,定义一个L×C的YL标签矩阵,第i行表示第i个样本的标签指向量,如果该行的样本类别为j,那么该行的第j个元素为1,其余元素为0。同理,给其余U个无标签的样本构造一个U×C的YU标签矩阵。将上述的两个标签矩阵合并,形成一个N×C的标签矩阵F[YL; YU]。
第三步,执行传播。将传播矩阵和标签矩阵相乘,得到每一个节点的传播概率。刷新所有节点的标签,在每次迭代中,将每个节点的标签更新为其最大数量的邻居所具有的标签。如果该标签值有且仅有一个,那么就确定为该标签值;如果该标签值有多个,那么模型会随机选取一个,得到新的标签矩阵。
第四步,重复上述的步骤,每个节点的标签与其邻居节点出现次数最多的标签相同,那么算法达到结束的条件。
3 实验结果及分析
本文以某地市运营商的2万名移动用户的移动出行数据为分析对象,并将数据分成两个时间段进行分析,工作日在工作时间段(8点至20点)以及非工作时间段(20点至次日8点)。
在提取移动用户出行数据的OD关键点后,构建基于移动用户出行数据的空间交互网络。在构建移动用户出行空间交互网络后,通过移动用户的出行数据构建基站之间的Jaccard相似度,比如:某个区域有基站u和基站v,根据大量的移动用户出行数据的挖掘可知,用户到达基站u后将会前往到基站1、基站2等20个基站,那么基站u的邻居基站集合为F(u)=20;同理计算基站v的邻居基站集合,F(v)=15。而F(u)与F(v)的共同基站数量为8。根据某段时间段内逗留在基站u的移动用户数量1 002,逗留在基站v的移动用户数量580,以及在两个基站上相互“进出”用户数量360,得到基站u和基站v的相似度为:
同理,计算所有基站之间的相似度,最后计算出基站之间的转移概率Pij。节点之间的传播概率越大,那么节点之间的标签越有可能相同。具有“热点”标签的基站i与没有标签的基站j的传播概率越大,那么基站j越有可能被选中,最后都有可能成为“热点”基站。
假如整个城市范围内定义“热点”和“非热点”两类基站,其中“热点”基站标签矩阵为L,“非热点”基站标签矩阵为U,那么形成标签矩阵如图1所示:

图1 标签矩阵示意图
图1 中红色字体代表热点基站的标签矩阵,黑色字体代表非热点基站的标签矩阵。结合基站之间的相似度计算基站传播概率,根据每一个传播概率Pij刷新所有节点的标签,在每次迭代将每个节点的标签更新为其最大数量的邻居所具有的标签,其示意图如图2、图3所示。
上述圆形代表具有“标签”的基站,方形代表“无标签”的基站。给每一个基站添加标签以代表其所属社区,并通过标签的传播概率Pij“传播”形成同一标签的“社区”结构。
在第二次迭代中,原本没有传递信息的标签开始传播。在经历多次传播后,标签的每个节点的标签与其邻居节点出现次数最多的标签相同,那么算法达到结束的条件。最终采用LPA算法实现“热点”基站识别,实现空间交互网络的社团划分,得到不同时间段的城市热点结果如图4所示。

图3 第二次迭代示意图

图4 非工作时间段的城市热点挖掘结果
图4 红色及黄色部分表示非工作时间段的热点区域,而绿色部分表述该时间段内非热点区域。从图4可知,在非工作时间段,该城市的热点区域集中在城市的东南角,主要是居民的住宅区、大型的商场、休闲区以及大型公园等。工作时间段的城市热点挖掘结果如图5所示:

图5 工作时间段的城市热点挖掘结果
图5 红色及黄色部分表示工作时间段的热点区域,而绿色部分表述该时间段内非热点区域。从图5可知,在工作时间段,该城市的热点区域集中在城市的东南角、中部以及西南角。居民的住宅区、大型的商场、商圈、休闲区以及大型公园等主要分布在该城市的东北角,因此无论是工作时间段还是非工作时间段人群的密度相对较高。而中部以及西南角主要是一些高档的办公楼、银行、工业园、IT企业以及政府机关的聚集区域,因此在工作时间段的人群密度相对较高,在非工作时间段的密度较低。
通过对比上述图4和图5的结果,本文挖掘的城市热点能够有效分析出城市不同功能区的分布,能够通过移动用户的出行数据快速识别该城市中8 943个以居住和休闲为特性的城市热点(以基站为单位)和38 394个以办公为特性的城市热点(以基站为单位)。城市热点的发现有利于研究城市的变迁与发展,也能够为城府或者相关部门的城市的规划工作提供数据支撑。
4 结束语
本文基于真实的移动用户出行数据提出了一种基于移动用户出行数据的城市热点挖掘算法。首先,通过移动用户的出行端点识别关键的OD点;其次,基于关键OD点构建整个城市范围内的空间交互网络;再次,采用Jaccrad相似度度量空间交互网络节点之间的相似度;最后,采用LPA来实现空间交互网络内聚子图的划分,实现了整个城市范围内热点区域的识别。实验证明,上述算法识别的城市热点区域比较符合现实情况。
