依据在线评论的商品排序方法
2018-07-26毕建武樊治平
毕建武,刘 洋,樊治平
(东北大学工商管理学院,辽宁沈阳110167)
1 引 言
随着互联网的不断发展,越来越多的电子商务网站和社交媒体平台鼓励消费者在网站上发表他们已购买或使用过的商品的相关评论信急[1,2].与商品卖方提供的商品描述相比,这些由消费者提供的商品在线评论信急能够更加客观的反应商品的真实情况.一些研究结果表明,大众消费者在购买商品(尤其是价格较高的商品)之前通常会阅读关于该商品的在线评论信急,并依据商品在线评论信急做出最终的购买决策[3−6].然而,由于商品在线评论属于非结构化文本数据而且其数量往往较大,如果让消费者逐条阅读和分析大量在线评论信急进而做出购买决策将会非常繁琐和困难[7].因此,为了支持消费者的购买决策,如何客观的对大量的商品在线评论进行自动化分析并对相关商品进行排序是一个非常值得关注的研究问题.
目前,基于在线评论的商品排序已经引起了国内外一些学者的关注,并取得了一些研究成果.例如Zhang等[8]较早的关注到了基于在线评论的商品排序问题并提出了相应的排序方法,在其方法中,首先提出了一种动态规划技术来识别评论中的比较语句和评价语句,然后依据情感分析技术对比较语句和评价语句的情感倾向进行判定,在此基础上构建了针对同类商品比较的有向加权图,依据有向加权图采用改进的PageRank算法确定了商品排序.在文献[8]的基础上,Zhang等[9,10]通过考虑在线评论所涉及的商品属性,评论获得的有用性投票(点赞)数量和评论发表时间等因素,对文献[8]所提出的方法进行了改进.Peng等[11]通过统计商品在线评论中不同属性特征词出现的频率,确定了消费者所关注的重要商品属性,在此基础上,提出了一种基于模糊PROMETHEE的商品排序方法.Chen等[12]依据同类商品的在线评论信急,通过集成主题模型,TOPSIS和多维尺度分析提出了一种基于在线评论的市场结构可视化方法,通过使用该方法可以确定同类商品的排序.Najmi等[13]通过考虑商品的品牌,评论的情感倾向和评论的有用性等因素,提出了一种基于在线评论的商品综合排序方法.Yang等[14]同时考虑了消费者针对商品的打分评级,文本评论和对比性投票等三类信急,提出了一种基于有向加权图的商品排序方法.
已有研究对于基于在线评论的商品排序做出了重要贡献.然而,目前针对此方面研究所取得的研究成果非常有限,仍显不足.在已有的研究中[8−14],通常是首先识别在线评论的正向或负向的情感倾向,再依据得到正向和负向的情感倾向进行商品排序.目前,一些学者已经明确指出,仅识别在线评论的正向和负向的情感倾向而不考虑相同情感倾向评论的不同情感强度,是过于简化的处理方式,容易导致信急损失[15,16].如果可以识别商品在线评论不同的情感强度,则可以基于大量在线评论的情感强度来确定商品的排序.为此,本文提出一种基于多粒度情感强度分析和随机TOPSIS的商品排序方法.在该方法中,首先通过提出多粒度情感强度分析算法确定每条评论针对商品属性的情感强度值,然后构建备选商品针对商品属性的多粒度情感强度分布形式的属性值,进而采用随机TOPSIS方法确定备选商品的排序.
2 依据在线评论的商品排序问题及排序方法
2.1 依据在线评论的商品排序问题
图1展示了一类依据商品在线评论的商品排序问题.由图1可以看出,消费者在购买商品之前,通常会根据自身的需要和商品的价格等相关信急,初步确定几款备选商品.为了从多个备选商品中选择最适合的商品,消费者可能会通过商品销售和评论网站获取备选商品的相关在线评论信急.依据消费者关注的备选商品和属性,如何依据在线评论确定备选商品针对属性的评价结果,并依据属性评价结果和属性权重确定备选商品的排序,这是本文所要解决的问题.为了便于分析说明,下面的符号用来描述该问题中所涉及的集合和变量.
A={A1,A2,...,An}表示消费者关注的n个备选商品集合,其中Ai表示消费者关注的第i个备选商品,i=1,2,...,n.F={f1,f2,...,fm}表示消费者关注的m个商品属性集合,其中fj表示消费者关注的第j个属性,j=1,2,...,m.w=(w1,w2,...,wm)表示消费者关注的备选商品属性权重向量,其中wj表示属性fj的权重,且满足wj=1,wj≥0,j=1,2,...,m.备选商品属性权重向量可以由消费者根据自身偏好预先给定.Q=(q1,q2,...,qn)表示备选商品的评论数量向量,其中qi表示针对备选商品Ai的评论数量,i=1,2,...,n.Ri={Ri1,Ri2,...,Riqi}表示针对备选商品Ai的评论集合,其中Rik表示针对商品Ai的第k条评论,i=1,2,...,n,k=1,2,...,qi.本文所要解决的问题是,依据消费者提供的属性F,属性权重w和在线评论信急Ri,i=1,2,...,n,如何确定备选商品A1,A2,...,An的排序,以支持消费者进行商品购买决策.

图1 基于商品在线评论的商品排序问题Fig.1 The goods ranking problem based on online reviews
2.2 依据在线评论的商品排序方法
为了解决上述问题,这里给出一种基于多粒度情感强度分析和随机TOPSIS的商品排序方法.该方法的基本思想是:首先,采用爬虫软件和ICTCLAS软件对消费者关注的备选商品的在线评论进行获取和预处理;然后,依据预处理后的评论,通过提出多粒度情感强度分析算法确定每条评论针对消费者关注的商品属性的情感强度值;再次,通过对得到的情感强度值进行统计分析,构建备选商品针对商品属性的多粒度情感强度分布形式的属性值;最后,依据得到属性值,可以采用随机TOPSIS方法确定备选商品的排序.下面给出该方法的具体描述.
2.2.1 备选商品在线评论获取和预处理
备选商品在线评论获取和预处理是备选商品在线评论多粒度情感强度分析的基础工作.本文采用爬虫软件对商品在线评论进行获取,采用ICTCLAS汉语分词系统(http://ictclas.nlpir.org/)对获取的评论进行预处理,具体过程如下:
1)备选商品在线评论获取
根据消费者关注的备选商品集合A={A1,A2,...,An},采用爬虫软件按照设定的规则对备选商品在线评论进行获取,可以得到备选商品在线评论Ri={Ri1,Ri2,...,Riqi},i=1,2,...,n.
2)备选商品在线评论预处理
针对备选商品在线评论的预处理包括两个步骤,即分词和词性标注和停用词删除.下面分别针对这两个步骤给出具体的描述.
(a)分词和词性标注.采用ICTCLAS汉语分词系统对备选商品在线评论进行分词和词性标注.通过分词和词性标注能够将句子形式的评论分解成若干词语并且在每个词后标注了相应的词性.例如,评论“画质非常好”经过分词和词性标注得到的结果为“画质/n非常/d好/a”,其中n,d和a分别表示名词,副词和形容词.
(b)停用词删除.停用词通常是指出现频率高,但又没有实际意义的词,例如“了”,“的”,“呢”等.为了提高情感强度分析的效率,通常需要对评论中的停用词进行删除.本文使用中文停用词表对停用词进行删除.具体的,将分词及词性标注处理后的评论与中文停用词表中的停用词(保留标点符号)进行比对,并删除在停用词表中出现的词.
将经过预处理后得到的关于备选商品Ai的第k条评论的词集合记为其中表示WSik中的第v个词,qik表示WSik中的词总数,i=1,2,...,n,k=1,2,...,qi,v=1,2,...,qik.
2.2.2 备选商品属性评论多粒度情感强度分析
依据备选商品在线评论预处理结果,为了进行商品排序,需要确定备选商品在线评论针对消费者关注的商品属性的多粒度情感强度值.为此,这里给出一种基于情感词典的在线评论多粒度情感强度分析方法,该方法主要包括三个步骤,包括备选商品属性的同义词合并,备选商品领域情感词典建立和备选商品属性评论多粒度情感强度识别.下面给出每个步骤的具体描述.
1)备选商品属性的同义词合并
不同的评论者在发表评论时描述同类商品的同一属性可能使用不同的词,因此有必要首先对描述同一商品属性的同义词进行合并.本文采用基于词语相似度的方法来对描述同一商品属性的同义词进行合并.具体过程如下.
首先,依据备选商品在线评论预处理结果,从所有备选商品的评论词集合中提取名词.令WSnoun=表示从所有备选商品评论中提取的名词集合,其中表示WSnoun中第l个名词,qnoun表示名词集合中名词的数量,l=1,2,...,qnoun.
然后,令Wfj表示针对商品属性fj的标准用词,j=1,2,...,m.通常,针对消费者可能关注的属性,电子商务网站可以预先设定商品属性的标准用词,并且要求消费者通过对所提供的标准用词进行勾选来确定消费者所关注的商品属性.因此,考虑针对各商品属性的标准用词为已知条件.这样,通过文献[17]提出的方法,可以计算词与商品属性标准用词Wfj的相似度sim(Wfj,),即
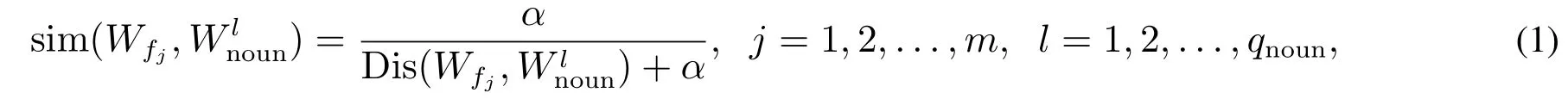
其中Dis(Wfj,)表示依据同义词词林[17]计算得到的Wfj和之间的距离;α为可调参数,α的默认取值为1.6.
由sim(Wfj,)的值的大小可确定词Wfj和是否为同义词.具体的,若sim(Wfj,)≥0.5,则认为词Wfj是Wlnoun的同义词;如果sim(Wfj,)<0.5,则认为词Wfj不是的同义词[11,17].通过相似度计算,可以得到针对词Wfj的同义词集合其中,表示WSj,将评论词集合WSik中的替换为Wfj,即可完成同义词合并,i=1,2,...,n,j=1,2,...,m,k=1,2,...,qi,p=1,2,...,qfi.
通常一条商品评论中可能包含针对多个属性的评论信急,为了识别一条评论中关于不同属性的多粒度情感强度值,需要首先识别一条评论中针对不同属性的评论信急.记为WSik中的针对属性j的评论信急,i=1,2,...,n,j=1,2,...,m,k=1,2,...,qi.关于的确定方式如下:将替换同义词后得到的WSik中的词与属性标准用词Wfj进行比对,如果Wfj∈WSik,则提取WSik中包含词Wfj的两个相邻标点符号之间的评论所包含的形容词,动词和副词[18],可以得到其中表示中的第 u个词,qj表示中词的总数,i=1,2,...,n,j=1,2,...,m,k=1,2,...,qi.特别的,如果Wfj/∈WSik,则记= “− ”,i=1,2,...,n,j=1,2,...,m,k=1,2,...,qi.
2)备选商品领域情感词典建立
考虑到针对不同商品的情感词集合可能不同,为了提高多粒度情感强度分析的准确性,有必要建立商品领域情感词典.备选商品领域情感词典建立的具体过程如下.
令WS′={W1,W2,...,Wq′}为针对备选商品评论的意见词集合,其中Wg表示WS′中的第g个意见词,q′表示 WS′中词总数,g=1,2,...,q′.WS′可以通过式(2)确定,即

依据得到的WS′,本文利用HowNet(http://www.keenage.com/)来构建商品领域的正向情感词典和负向情感词典.具体的,令和分别为HowNet中通用的正向评价词语和负向评价词语的集合.根据和WS′初步构建备选商品领域正向情感词典和负向情感词典其中

需要指出的是,由于可能出现WS′中的部分词同时不属于的情况,针对以上情况需要通过人工识别来确定相应词所隶属的领域情感词典,并最终得到备选商品领域情感词典.记WS+和WS−分别表示最终确定的备选商品领域正向情感词典和备选商品领域负向情感词典.
3)备选商品属性评论多粒度情感强度识别
步骤1判断是否为空集,若= ∅,则←0;否则跳转到步骤2;
步骤2判断是否为 “−”,若=“−”,则←“−”;否则跳转到步骤3;
步骤3判断与WS+的交集是否为空集,若WS+∩̸= ∅,则← 1;否则← 0;
步骤4判断与WS−的交集是否为空集,若WS−∩̸=∅,则←1;否则←0;
步骤5判断与WSneg的交集是否为空集,若WSneg̸=∅,则←1;否则←0;
步骤6判断与WSd的交集是否为空集,若WSd= ∅,则← 0;若则←1;否则←−1;
步骤7若==0或者=1,则←0;若=1,=0和=1或者=0,则←−2−否则

其中i=1,2,...,n,j=1,2,...,m,k=1,2,...,qi.
2.2.3 备选商品排序
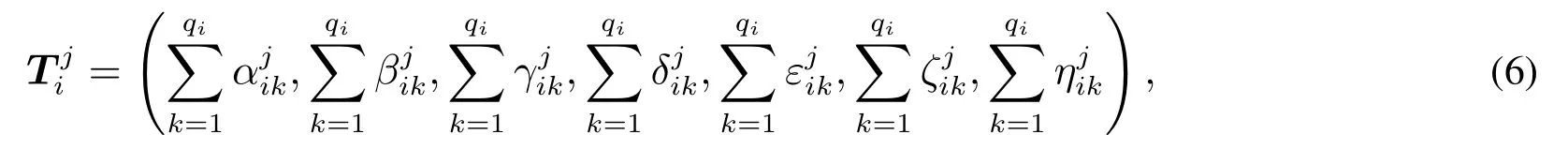
其中i=1,2,...,n,j=1,2,...,m.
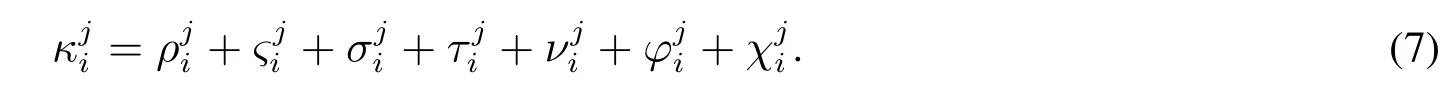
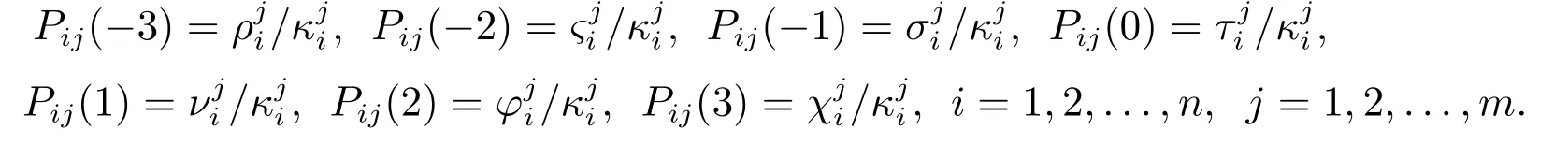
针对Pij(x),x=−1,−2,−3,0,1,2,3的表达式,相应的累积分布函数可以写为
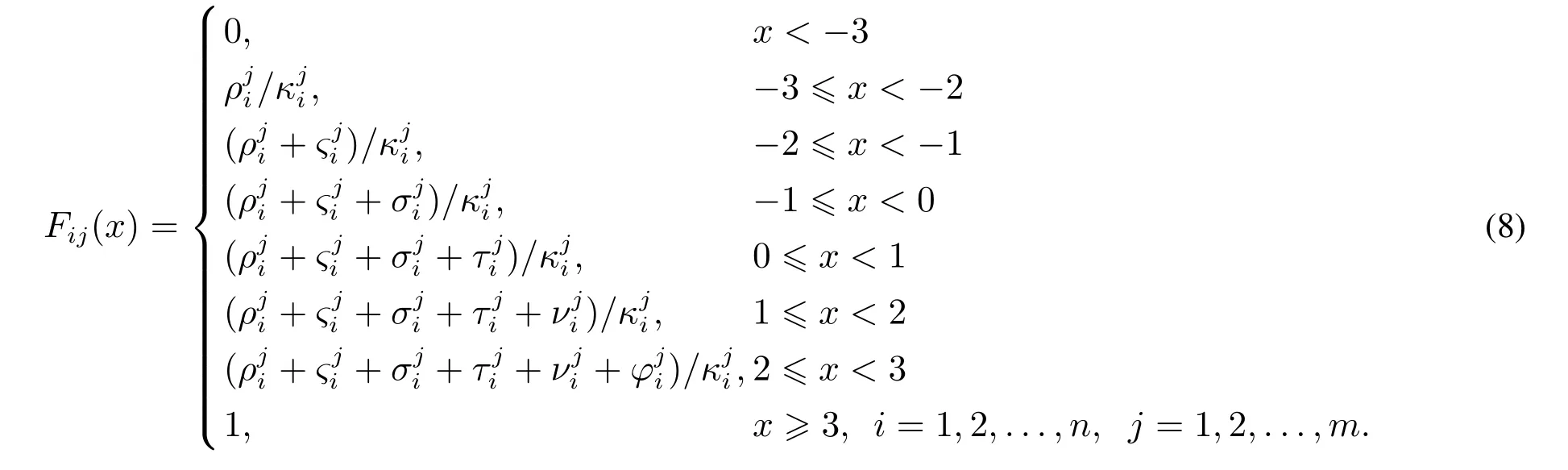
在此基础上,可以采用随机TOPSIS方法[19],对备选商品进行排序.

备选商品Ai关于属性fj的多粒度情感强度分布形式的属性值Pij(x)的累积分布函数Fij(x)到和的距离可以采用式(11)和式(12)进行计算,即
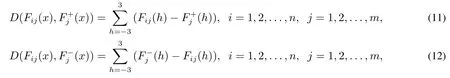

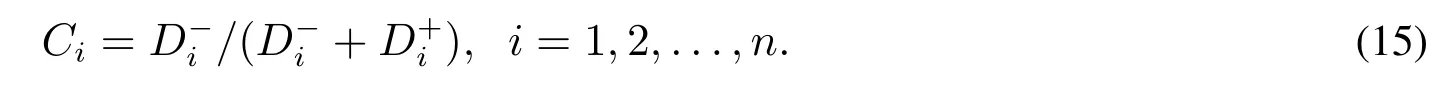
可见,Ci的值越大,备选商品Ai越优.因此按照计算得到的Ci的值的大小对所有备选商品排序,可以得到所有备选商品的优劣排序结果.
综上,下面给出依据商品在线评论的基于多粒度情感强度分析和随机TOPSIS的商品排序方法的具体计算步骤.
步骤1采用爬虫软件获取备选商品在线评论Ri={Ri1,Ri2,...,Rqi},对Ri进行预处理得到每条评论的词集合
步骤2根据式(1),对备选商品属性的同义词进行合并,并确定每条评论中针对不同属性的评论信急=1,2,...,n,j=1,2,...,m,k=1,2,...,qi;
步骤3根据式(2)∼式(4),建立商品领域正向情感词典WS+和负向情感词典WS−;
步骤4根据算法1,计算备选商品属性评论多粒度情感强度值=1,2,...,n,j=1,2,...,m,k=1,2,...,qi;
步骤5根据式(5)∼式(8),构建备选商品针对商品属性的多粒度情感强度分布形式的属性值Pij(x),i=1,2,...,n,j=1,2,...,m;
步骤6根据式(9)∼式(10),构建正、负理想累积分布向量F+和F−;
步骤7根据式(11)∼式(15),计算备选商品Ai的贴近度Ci,并根据Ci由大到小对备选商品进行排序,i=1,2,...,n.
3 算例分析
为了进一步说明本文提出方法的潜在应用,本部分给出一个依据在线评论信急对多款相机商品排序的算例分析.考虑某消费者欲购买一款价格在1万元左右的数码相机,通过多方面了解信急,初步确定了4款备选数码相机,即
A1:佳能6D套机(24 mm∼105 mm);
A2:佳能7D套机(18 mm∼135 mm);
A3:尼康D610套机(24 mm∼120 mm);
A4:尼康D750套机(24 mm∼120 mm).
该消费者关注的备选相机属性为:性价比(f1),操控(f2),画质(f3),电池(f4),镜头(f5),对焦(f6),快门(f7),并且该消费者给出的备选相机属性权重向量为w=(0.2,0.1,0.2,0.1,0.1,0.1,0.2).
为了支持该消费者做出合理的购买决策,需要依据在线评论对以上4款备选相机进行排序.
首先,以中关村在线(http://www.zol.com.cn/)提供的商品点评作为备选相机评论来源,使用Locoy Spider软件采集备选相机在线评论,得到备选相机在线评论Ri={Ri1,Ri2,...,Riqi},对Ri进行预处理得到每条评论的词集合WSik=,i=1,2,3,4,k=1,2,...,qi,q1=402,q2=201,q3=220,q4=350.以备选相机A1为例,对其评论进行预处理的结果如表1所示.
根据式(1),对描述相机属性的同义词进行合并,并识别每条评论中针对不同属性的评论信急,即确定这里以备选相机A1的第一条评论R11为例进行说明,R11中仅包含画质(f3)的评论语句,对该条评论进行同义词合并,提取包含描述属性f3的词Wf3(画质)的两个相邻标点符号之间的形容词,动词和副词可以得到该条评论中针对画质(Wf3)的评论信急为={非常/d,好/a}.

表1 备选相机A1的评论预处理结果Table 1 The pre-processing results of the reviews concerning alternative camera A1
然后,根据式(2)∼式(4),建立相机领域正向情感词典WS+和负向情感词典WS−,部分情感词见表2.

表2 部分情感词Table 2 Partial sentiment words
根据情感强度分析算法,计算备选相机针对属性的评论的情感强度值=1,2,3,4,k=1,2,...,qi,q1=402,q2=201,q3=220,q4=350.这里以={非常/d,好/a}为例来进一步说明如何通过情感强度分析算法确定的值.由于中仅存在正向情感词“好”和情感强度增强词“非常”,即由情感强度分析算法的步骤3,步骤4,步骤5和步骤6可分别确定各指示变量的值,即在此基础上,可以由情感强度分析算法的步骤7确定的值,即=2+1=3.最终得到该条评论关于属性f3的情感强度值为3.
依据表3和式(8),可以得到针对Pij(x)的累积分布函数Fij(x),i=1,2,3,4,j=1,2,...,7.为了节省篇幅,这里以F11(x)为例,简要说明其计算过程.

表3 备选相机关于属性的多粒度情感强度分布形式的属性值Table 3 Feature values in the form of distribution concerning multi-granularity sentiment strengths on alternative cameras
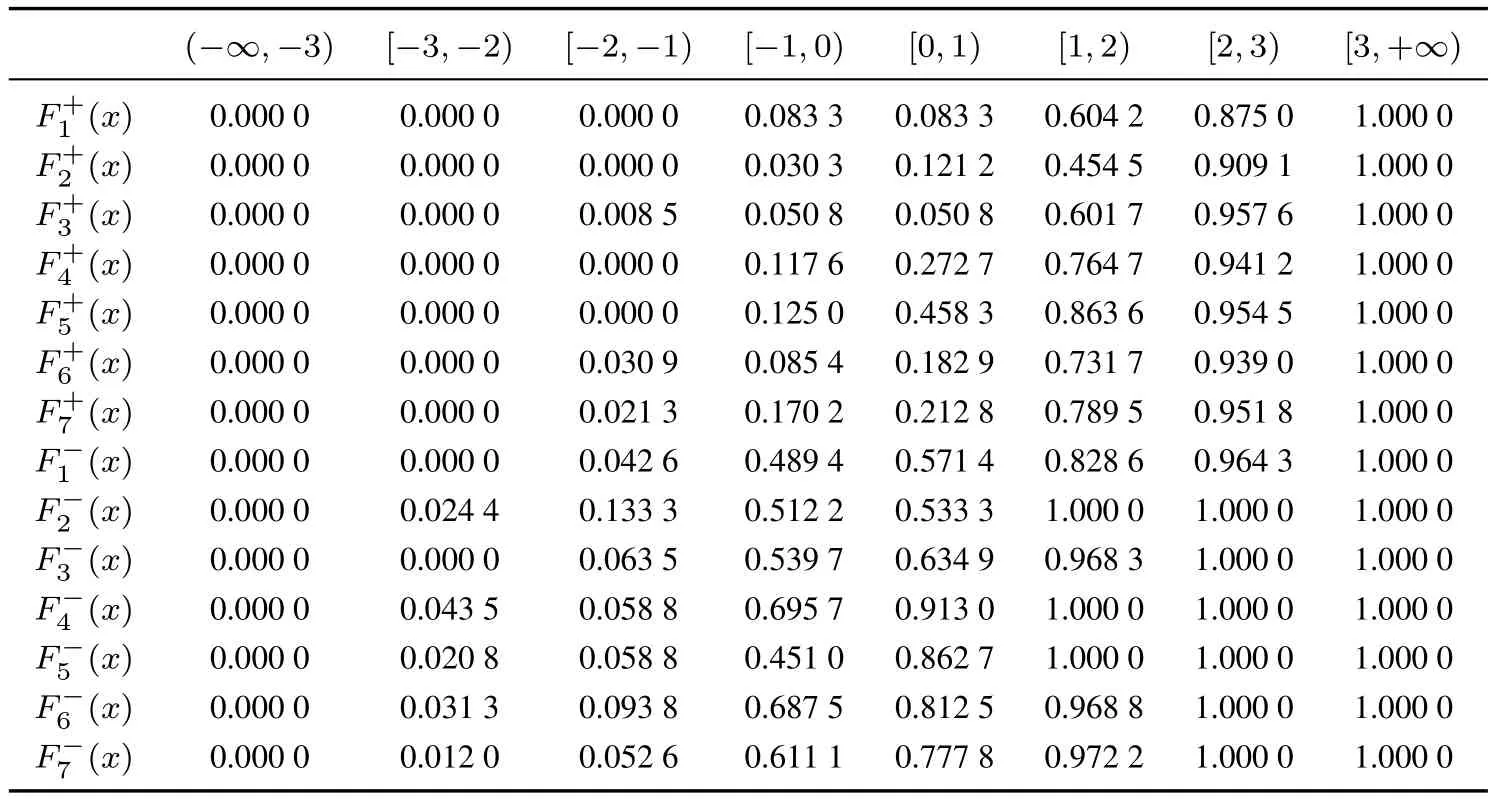
表4 正、负理想累积分布向量Table 4 The probability distributions of the ideal and nadir solutions
由表3可知,备选相机A1关于属性f1的多粒度情感强度分布形式的属性值为

依据式(8),P11(x)的相应累积分布函数F11(x)可以写为

在此基础上,依据式(9)和式(10),可构建正、负理想累积分布向量和结果如表4所示.
根据式(11)∼式(14),计算备选相机Ai到正向和负向理想累积分布向量F+和F−的距离,即i=1,2,3,4.计算结果为=0.533 1,=0.744 9,=0.724 1,=0.497 9,=0.872 4,=0.660 5,=0.681 3,=0.907 5.最后,依据式(15),可计算备选相机的贴近度,计算结果为C1=0.620 7,C2=0.470 0,C3=0.484 7,C4=0.645 7.通过比较4款备选相机的贴近度的值可得到4款相机排序结果为A4≻A1≻A3≻A2,即该消费者可以考虑购买备选相机A4.
4 结束语
本文给出了一种依据商品在线评论的基于多粒度情感强度分析和随机TOPSIS的商品排序方法.在该方法中,首先,采用爬虫软件和ICTCLAS对消费者关注的备选商品的在线评论信急进行获取和预处理.然后,依据预处理后的评论,通过提出的多粒度情感强度分析算法可以确定每条评论针对消费者关注的商品属性的情感强度值.进一步地,通过对得到的情感强度值进行统计分析,可以构建备选商品针对商品属性的多粒度情感强度分布形式的属性值.在此基础上,可以依据随机TOPSIS方法确定备选商品的排序.该方法具有概念清晰、计算简单等特点,有较强的可操作性和实用性,为解决依据在线评论的商品排序问题提供了一种新的思路.
需要强调的是,在本文研究中,提出了一种多粒度情感强度分析算法.使用该算法,可以将在线评论的情感强度划分为七个情感粒度,进而通过统计分析,可以将海量在线评论中所蕴含的针对商品的情感强度转化为多粒度情感强度分布形式的属性值.这种处理方式,一方面避免了仅考虑正向和负向情感倾向所造成的大量信急损失,另一方面方便借助已有的基于随机(频度)分布的信急处理和决策分析方法进行基于海量在线评论信急的信急处理与决策分析,为进一步开展基于在线评论信急的决策分析奠定了良好的基础.
