基于用户兴趣模型及能力评估模型的个性化推荐方法研究
2018-07-25阮怀伟吴晓璇陈艳平
阮怀伟吴晓璇 陈艳平
1 引言
随着互联网规模的不断扩大,网络资源迅猛增长,人类社会已进入一个信息爆炸的时代。同时,用户的社会化标注行为进一步推动着信息的增长。然而,由于用户兴趣、表达方式等方面的差异,促使社会化标签质量参差不齐,信息超载和信息迷航俨然成为学术界和产业界亟待解决的问题[1]。推荐算法通过对用户的行为属性进行分析,挖掘用户的兴趣,从而为用户精确推荐物品或信息[2]。个性化推荐方法是利用用户预先提供的数据[3]或利用数据挖掘[4]等技术挖掘用户潜在的兴趣资源进行推荐。
随着Internet的迅速发展和全球对终身教育的需求,以异步教育方式为主要特征的基于Web的在线学习已成为Internet上的一种重要应用[5-7]。基于在线学习的个性化学习受到越来越多研究者的关注。目前在线学习的应用还存在一些缺点,其中利用动态、异构环境下的分布学习资源进行个性化学习是困扰已久的关键问题,表现在学习过程中缺乏指导,学习资源重用率低,不能以学习者为中心来推送符合学习规律的学习资源。
本文以在线学习为应用背景,基于用户的基本信息和兴趣偏好构建用户兴趣模型,通过用户对知识的掌握程度构建学习能力评估模型,再基于用户兴趣模型和学习能力评估模型进行个性化推荐,通过个性化学习系统推送包括文本、图片、视频、试题等经过语义标引过的学习资源。其中,试题资源还可用于在线测试,以便检验用户的学习效果,同时将测试结果反馈给学习系统,用以不断修订用户兴趣模型及学习能力评估模型,不断优化个性化学习系统的精确性,使得用户通过在线学习获得更好的学习体验和知识积累。
2 用户兴趣模型构建
在线学习背景下,用户兴趣主要由隐性信息和显性信息组成。显性信息包括用户注册时获取的基本信息,如用户的年级、性别、偏好等;隐形信息由用户在学习过程中的系统记录抽取而来,能够反映用户的当前状态,在实际应用中更为有效。单一的信息都不足以体现用户的真实兴趣,无用的信息也会大大增加建模的复杂度和计算成本,因此如何将两者结合,提取出用户真正的兴趣点是用户兴趣信息提取的一个关键问题[8]。本文建立的用户兴趣模型主要从两个方面构建:子知识点及学科。
2.1 子知识点的兴趣模型
在学习资源推荐中,认为用户兴趣与用户对知识点的掌握程度密切相关,也就是说掌握越好的知识点对应的兴趣度就低,而掌握差的知识点,兴趣度就高。知识点兴趣度用知识点的权值来描述。在初始阶段,知识点的权值均设为1,随着用户学习行为的推进,采用隐式计算方法获取并动态修改知识点的权值。
每个知识点的权值wj可以由三个部分:①知识点掌握程度;②用户学习行为;③知识点频率;计算获得,如公式(1):
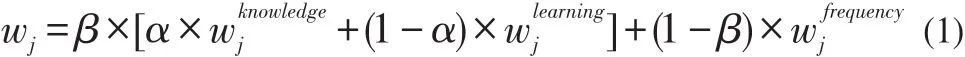
(1)wknowledgej的数学计算如公式(2):

其中,totalscorej表示所有包含该知识点的题目数量;currentscorej表示答对的题目数量。
(2)wlearningj的数学计算如公式(3):
其中,learnj表示用户学习的该知识点的资料数量,total_learn表示已学资料的总数,比重越大,则说明用户对该知识点越感兴趣。
(3)wfrequencyj的数学计算如公式(4):

其中,accessj表示资源库中用户阅览的包含该知识点的资料数量,databasej表示数据库中包含该知识点的资料数量。
在上述计算知识点的权值过程中,不排除下述极端情况:
(1)兴趣度最低
兴趣度最低表示学生没有学习任何教学资源就可以测试通过,表示学生已经掌握了该知识点。
(2)兴趣度最高
兴趣度最高表示学生已经学完了所有该知识点的教学资源,但还是未能通过测试,表示学生还得接着学习该知识点。
(3)兴趣度变化
随着学生学习资源数的增加,兴趣点会逐步分散,之前学过的知识点兴趣度会逐渐减少,后学的知识点兴趣度会逐渐增加。
上述用户兴趣模型是通过计算知识点的权值确定用户的兴趣度,此模型符合用户的学习行为和学习习惯,具有一定的理论和现实依据,可以作为个性化推荐的重要依据。
2.2 学科兴趣模型
在定义知识点兴趣模型的基础上,学科i的兴趣度Wi用学科下所有一级知识点的权值的加权和来计算。其中,知识点的权重由领域专家标注,重点知识点权重大,非重点权重小。

其中,αj为归一化后的权重;wj表示第j个一级知识点的兴趣度权值。一级知识点的兴趣度权值wj由一级知识点本身和它所包含的子知识点的兴趣度来确定,其计算如公式(6):

其中,βk为归一化后的权重;wjk表示第j个一级知识点包含的所有子知识点的兴趣度权值。wj0β0为第j个一级知识点本身的兴趣度。将(5)式、(6)式合并可以获得公式(7):

3 学习能力评估模型构建
用户的学习能力评估由用户在使用系统的过程记录抽取分析而得,能够反映用户对各知识点的掌握程度。在学习能力评估模型中,设定用户能力等同于用户对知识点的掌握程度。掌握程度与用户学习资源数、测试分值呈正比。因此每个知识点的掌握程度pj可通过两部分:①测试结果;②用户学习行为计算获得。其计算公式如下式(8):
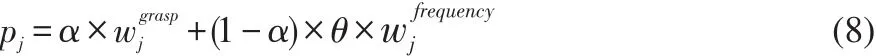

其中,totalscorej表示所有包含该知识点的题目数量,currentscorej表示答对的题目数量。

其中,accessj表示资源库中用户阅览的包含该知识点的资料数量,databasej表示数据库中包含该知识点的资料数量。
(3)θ的数学计算如公式(11):

其中,k表示总资料数量阈值,总资源数越多,则学习行为对能力的影响越大,当达到阈值时影响最大,θ=1。
4 基于用户兴趣模型及学习能力评估模型的个性化推荐方法
构建了基于用户兴趣模型及学习能力评估模型后,需要运用模型为用户提供个性化信息服务,即将用户与资源进行匹配。针对特定的用户,首先根据本体推理获得相关知识点,计算该用户对相应知识点的兴趣程度,按照从大到小的排序顺序将知识点所属资源推荐给用户,实现个性化推荐的目的。在获得学习的基础上,通过用户的使用记录,计算用户对各知识点的掌握程度,在个性化推荐中起到辅助作用。
实现个性化推荐服务,大体流程分为四个阶段:相似用户发现、资源集的确定、资源特征表示和模型匹配运算。该流程的总体框架如图1所示。
在在线学习应用背景下,结合学习能力评估模型,以协同过滤算法为根据,构建个性化学习系统总体框架如图2所示。
5 结束语
本文以在线学习为应用背景,通过上述研究,解决了个性化推荐方法中存在的部分问题,如在线学习过程中,如何刻画用户的兴趣;如何量化用户的学习能力;用标签来描述用户兴趣,不受内容提取技术的限制等问题。虽然对个性化推荐方法中存在问题进行了深入研究,然而由于个性化信息服务系统的复杂性及研究时间、研究条件的限制等原因,还存在以下问题,值得今后继续深入研究:多用户兴趣模型的构建、半结构化数据的稀疏性问题、推荐算法的可扩展性问题、推荐算法的精度等问题。

图1 基于用户兴趣模型的个性化信息服务流程

图2 基于用户兴趣模型及学习能力评估模型的个性化学习系统
