基于Hadoop的数据资源管理平台设计
2018-07-25黄华林庞欣婷
黄华林 庞欣婷
1(广西电网有限责任公司 广西 南宁 530000) 2(广西第一工业学校 广西 南宁 530000)
0 引 言
随着信息化时代的到来与人工智能技术的不断发展,世界各主要国家相继提出“智能电网”这一概念。近几年,各国均在大力推进智能电网项目的建设与发展。随着智能电网建设进程的逐步深入,智能电网所产出的数据量也呈指数式增长,特别是智能电网的电网状态监测数据[1-3]。这对智能电网的数据管理平台的可靠性和实时性均提出了更高的要求,传统的数据管理模式远远不能满足这些求需求[4]。因此,在智能电网中,研究如何存储、管理和共享这些关键数据成为急需解决的关键问题。
电网状态监测数据的显著特点是数据规模大,且数据是由分布在不同地域的设备采集的,需要分布式管理。Hadoop是一个开源的云计算架构,具备可靠性高、数据处理量大以及容错性高等优势,已经成为信息领域研究的热点[5-6]。
为解决智能电网中海量电网状态监测数据的高效管理,本文设计了基于Hadoop的数据资源管理平台。首先分析了海量电网状态监测数据管理平台结构与功能;然后分别针对海量电网数据分布式存储和海量数据检索提出了基于Hadoop集群的存储方法和基于MapReduce的数据检索方法;最后对数据资源管理平台进行了性能测试。
1 平台结构与功能
海量电网状态监测数据资源管理平台的主要目的是实现海量、分布的电网状态监测数据的高性能存储和检索,为后续高效准确地实现电网状态监测数据的分析与挖掘奠定基础。整个电网状态监测数据管理平台有四个模块构成:元数据管理模块、信息管理模块、节点管理模块和海量存储模块。基于分布式结构设计数据管理平台,实现了不同地区电网状态监测数据的高效集中,主节点的服务器可以对其他节点数据进行有效的调度与管理。数据资源管理平台的结构图如图1所示。
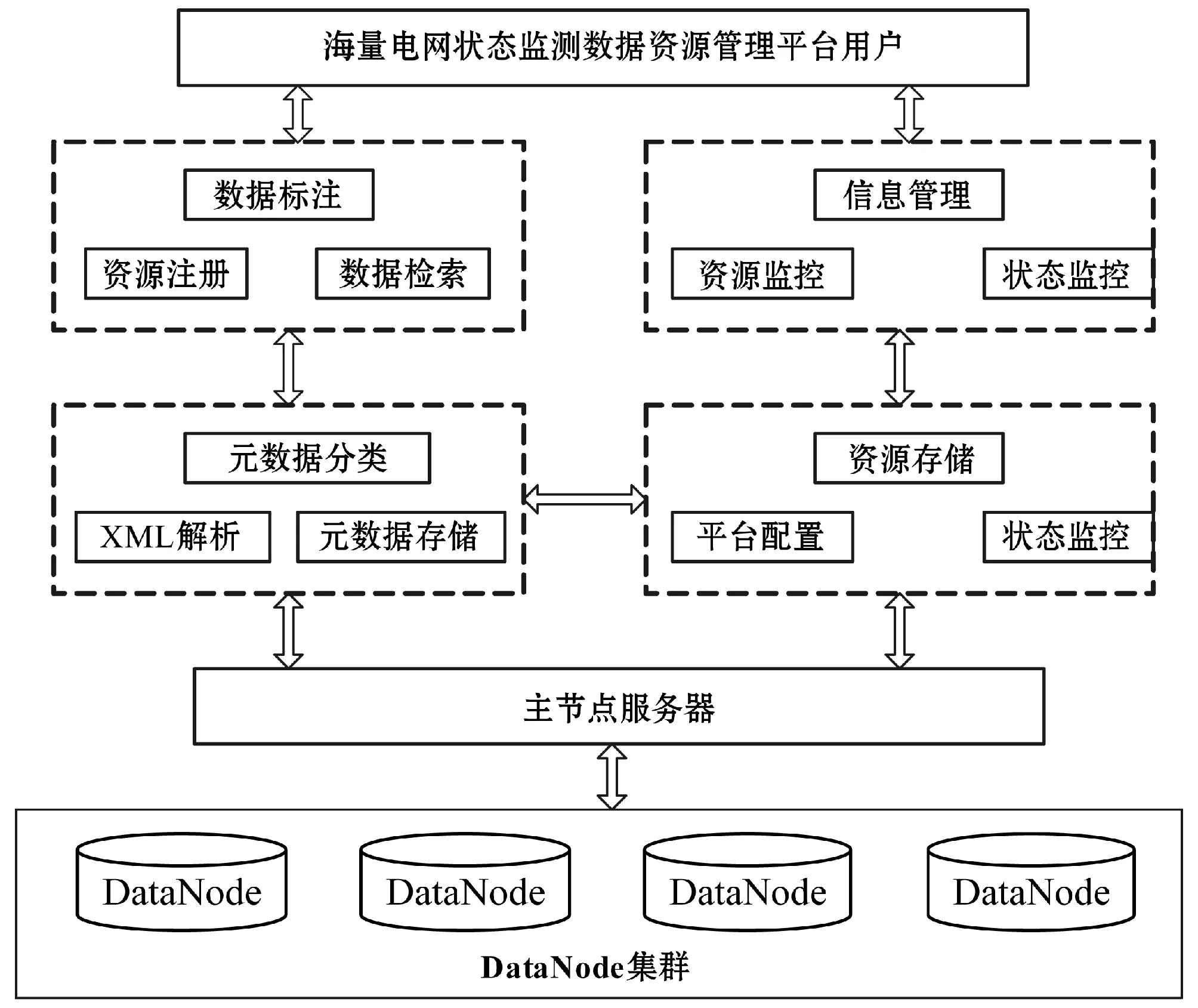
图1 平台总体结构
1.1 元数据管理模块
平台基于XML Schema实现元数据的表示规范、元数据界面生成方法以及元数据的组织管理,基于元数据实现电网状态监测数据的有效分类与管理。XML Schema不但可以对电网状态监测数据进行分类存储和检索,还可以实现数据的动态管理。平台的元数据管理包含分类管理、Schema管理、XML解析、XML验证等几个子功能模块。各个功能模块既相互独立,又有机配合,共同完成对海量电网状态监测数据的组织管理。平台元数据模块的组织形式如图2所示。
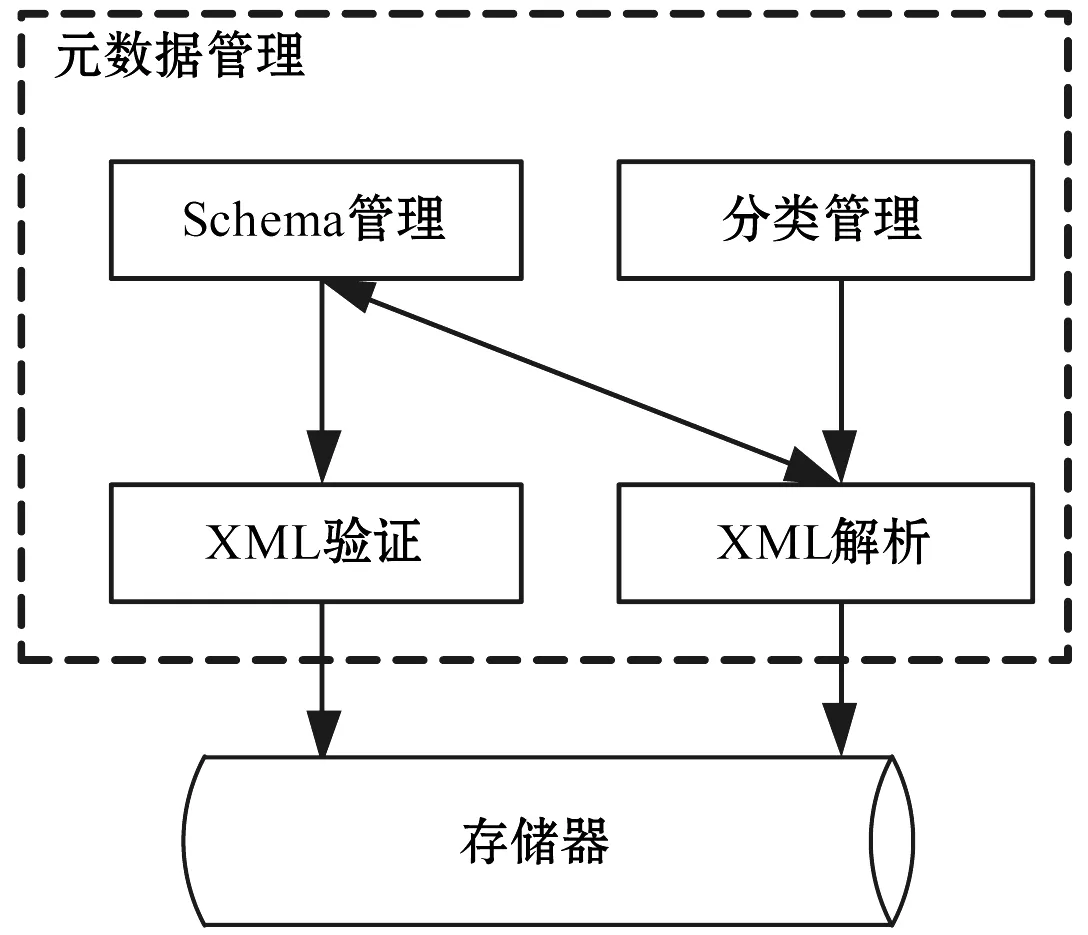
图2 元数据管理
1.2 信息管理模块
基于XML Schema实现海量电网监测元数据的组织与存储后,每一类元数据都会有相应的组织方式,利用XML Schema可以进行高效存储与检索。由于海量电网状态监测数据的复杂性,平台采用自上而下的方法实现电网信息的元数据管理。因此,当用户上传数据资源后,必须要准确填写该数据资源的描述字段,平台会自动生成一个描述文件,可以为后续的数据统计和资源检索提供支撑。此外,用户上传数据资源后,平台还会将该资源的物理存储地址写入数据库,方便后续资源维护。图3为平台的信息管理流程。
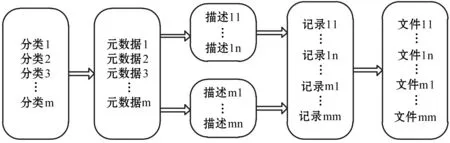
图3 平台信息管理流程
1.3 节点管理模块
节点管理模块是平台设计的关键技术模块之一。平台的节点管理包括节点信息管理和节点管理两部分。在测试目前常用的节点管理算法(例如随机算法、轮询算法、最小负载算法)的基础上,平台采用了一种基于抖动系数的最小负载算法[6]。该算法有效提高了负载均衡,能够对各个子节点进行动态监测,还可以监控布置于各地电网系统的分布式服务器中的数据资源、知识资源以及系统资源等。
1.4 海量存储模块
基于对开源Hadoop分布式文件系统(HDFS)[7-9]的测试基础上,平台对传统的存储架构进行了改进,以适应对海量电网状态监测数据的高效存储、管理与检索。图4为平台设计的海量电网状态监测数据的存储结构与数据访问关系。海量存储模块由三部分构成,即存储端、查询端与访问链路。海量电网状态监测数据的来源是网络,包括Zigbee网络或者以太网等。海量存储模块以Hadoop为核心,DataNode中保存各地分布式节点上传的电网状态监测数据。图4中,海量电网状态监测数据的实时存储由左侧的存储客户端完成,而海量电网状态监测数据的检索查询功能由右侧的检索客户端完成。其中存储客户端通常部署在各地的电网监测部门,而查询客户端位于数据中心或数据监测工作区内。
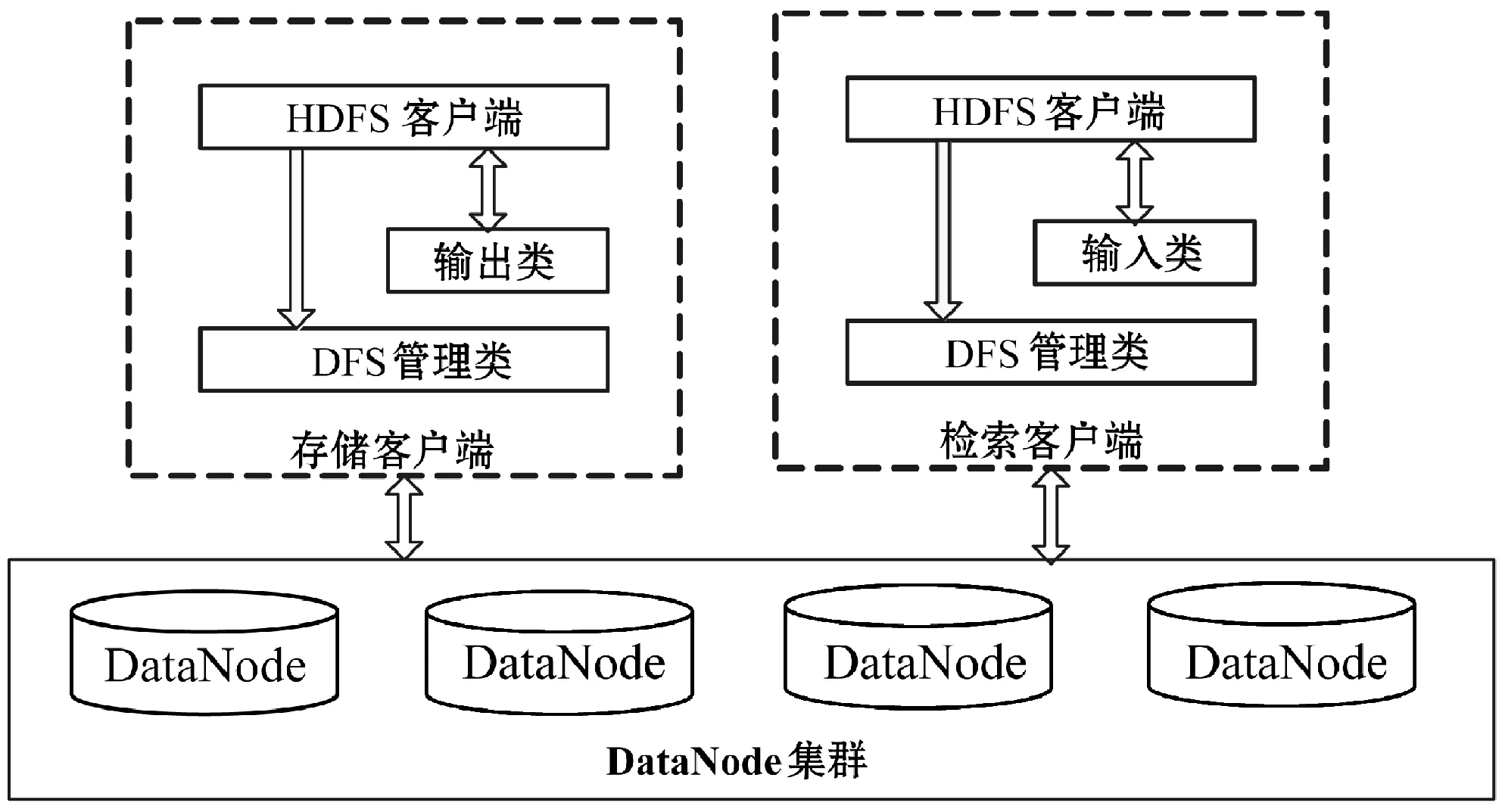
图4 数据存储结构与数据访问关系
2 平台实现关键技术
随着智能电网建设进程的不断加快,电力设备采集的状态数据类型也不断增加,例如:用户数据、绝缘子数据、报警数据、设备数据(张力、倾角等)、线路数据等。随着时间的增长,对存储这些数据所需的空间需求也会越来越大,传统的数据库无法存储和处理这些海量的电网状态监测数据。针对海量电网状态监测数据的存储与检索问题,平台设计了基于Hadoop集群的数据存储方式和基于MapReduce的数据检索算法。
2.1 基于Hadoop集群海量数据分布式存储
对海量电网状态监测数据进行分类。基于数据状态,将数据分为静态数据和动态数据两类。其中静态数据是指稳定性强,占用的存储空间相对较小的数据,包括用户数据、线路数据、检测设备数据、绝缘子数据等;动态数据是指数据会随着时间的推移而飞速增长,需要的存储空间大,包括电网状态检测过程中采集的温度数据、报警数据、张力数据以及倾角数据等。动态数据是电网状态监测数据存储与检索的重点和难点。平台的静态数据采用传统的关系数据库存储。针对海量电网状态监测动态数据的存储问题,设计了基于HDFS的快速存储框架。
在数据资源管理平台中,数据的接收与上传是由存储客户端完成的,因此电网状态监测额数据由存储客户端上传到HDFS[10]。为了提高数据存储速度以及减少系统与硬盘的交互次数,建立一个数据缓存区,用于保存数据发送端传输的数据,依据客户端数据处理能力,自适应地设定缓存区大小(如64 MB、128 MB)。当接收数据存满缓存区后,客户端将数据上传至HDFS。因此,客户端与HDFS每次交互的数据大小相等,既便于数据维护,又显著地减少了数据交互次数与元数据量。具体实现流程如图5所示。
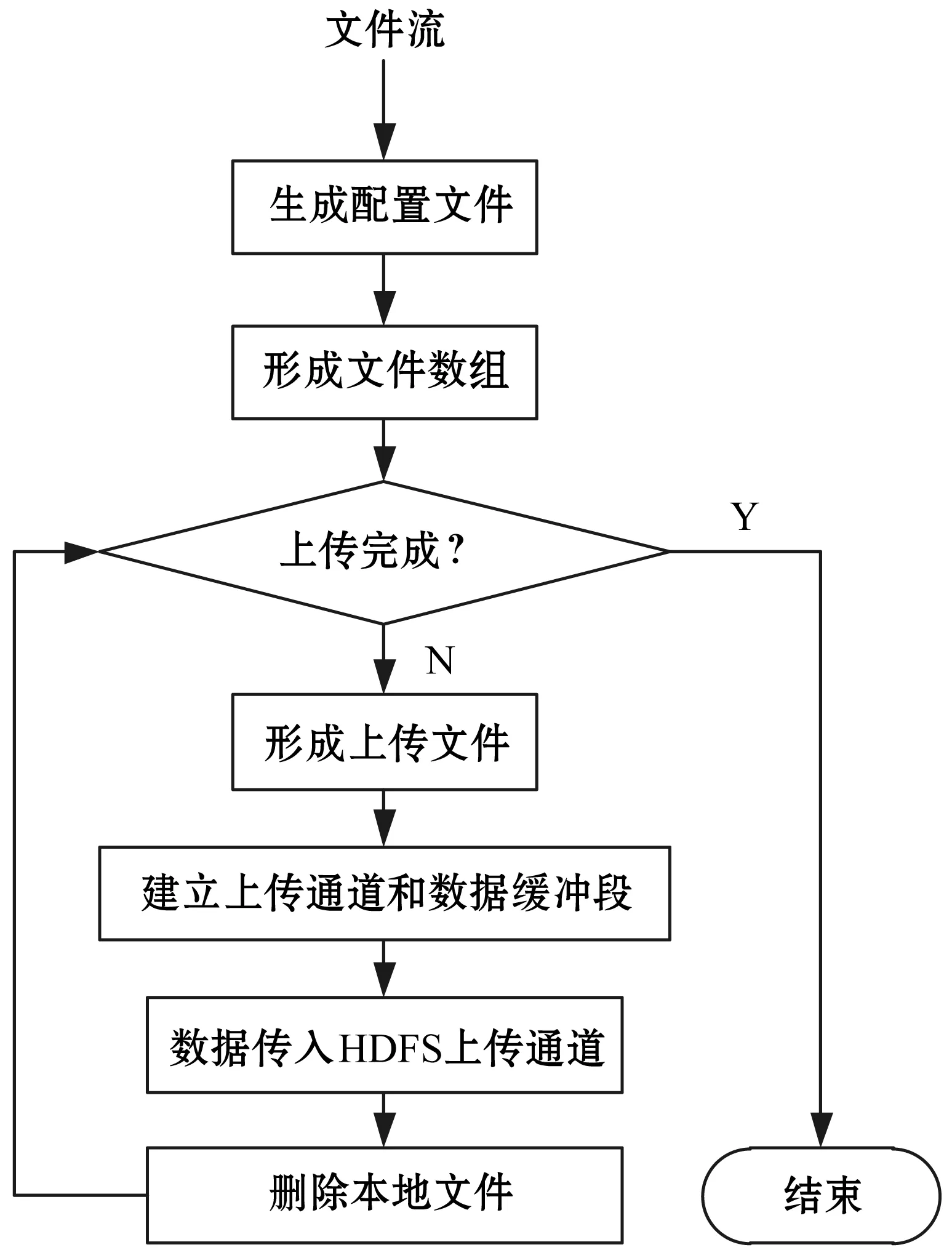
图5 数据存储流程
2.2 基于MapReduce的海量数据检索算法
为提高海量电网状态监测数据的检索效率,平台设计了基于MapReduce的海量数据检索算法。该检索算法中,核心内容是Map和Reduce函数。
检索客户端主函数的功能是实现用户检索与MapReduce框架直接的信息交互。在海量电网状态监测数据管理平台中,用户在检索过程中,需要录入的检索信息包括:检索文件地址、检索结果导出文件地址、检索关键词、关键词位置以及Reducer个数。检索算法基于用户输入的检索信息,将符合条件的数据进行高效汇总,汇总后的数据直接呈现给用户。因此,数据检索过程的重点是客户端主函数和Map函数。
2.2.1 主函数
主函数的重要功能就是设置与数据检索过程相关的各个参数,平台中需要设置的检索参数如图6所示。
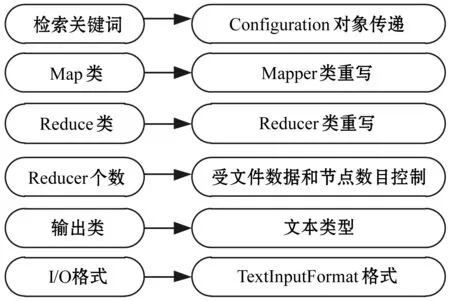
图6 主函数需要设置的参数
2.2.2 Map函数
首先对主函数导入的检索信息进行分割形成多个Split,每个Map函数检索一个Split,并对存储的数据进行检索查询,具体查询过程如下:
步骤1Map任务开始,读取相关检索信息。
步骤2读入一行关键词数据,将数据分解为字符串数组。
步骤3读取待检索的存储数据。
步骤4与检索关键词匹配。若匹配成功,将键值保存如临时文件;否则继续匹配下一个关键词。
步骤5检测是否有下一个关键词。若有,转入步骤4;否则,当前Map任务结束。
步骤6导出数据检索结果。
3 实验与分析
为验证文中设计的海量电网状态监测数据管理平台的性能,在实验室搭建的Hadoop平台上进行性能测试。测试的内容包括平台的I/O基准性能、数据存储性能和数据检索性能。测试环境如下:平台共有27个节点,每个节点客户端的配置均为8核CPU,主频3.3 GHz,内存8 GB,网络为千兆以太网,Hadoop版本2.6.0。
3.1 I/O基准测试
在数据管理平台没有其他任务的条件下,基于TestDSFIO进行HDFS的基准I/O性能测试。测试内容包括不同文件大小、不同文件个数时HDFS的时间消耗。
首先,测试20个文件不同文件大小的读写操作,测试结果如图7所示。图中绘制了平均写操作的运行时间和文件整体写操作的运行时间。测试结果表明,随着文件大小的逐渐增加,平台写文件的总体时间消耗也逐渐增加,但是平均时间消耗一直在下降。此外,还对读文件的时间消耗进行测试,测试曲线与图7的数值不同但变化趋势相同。
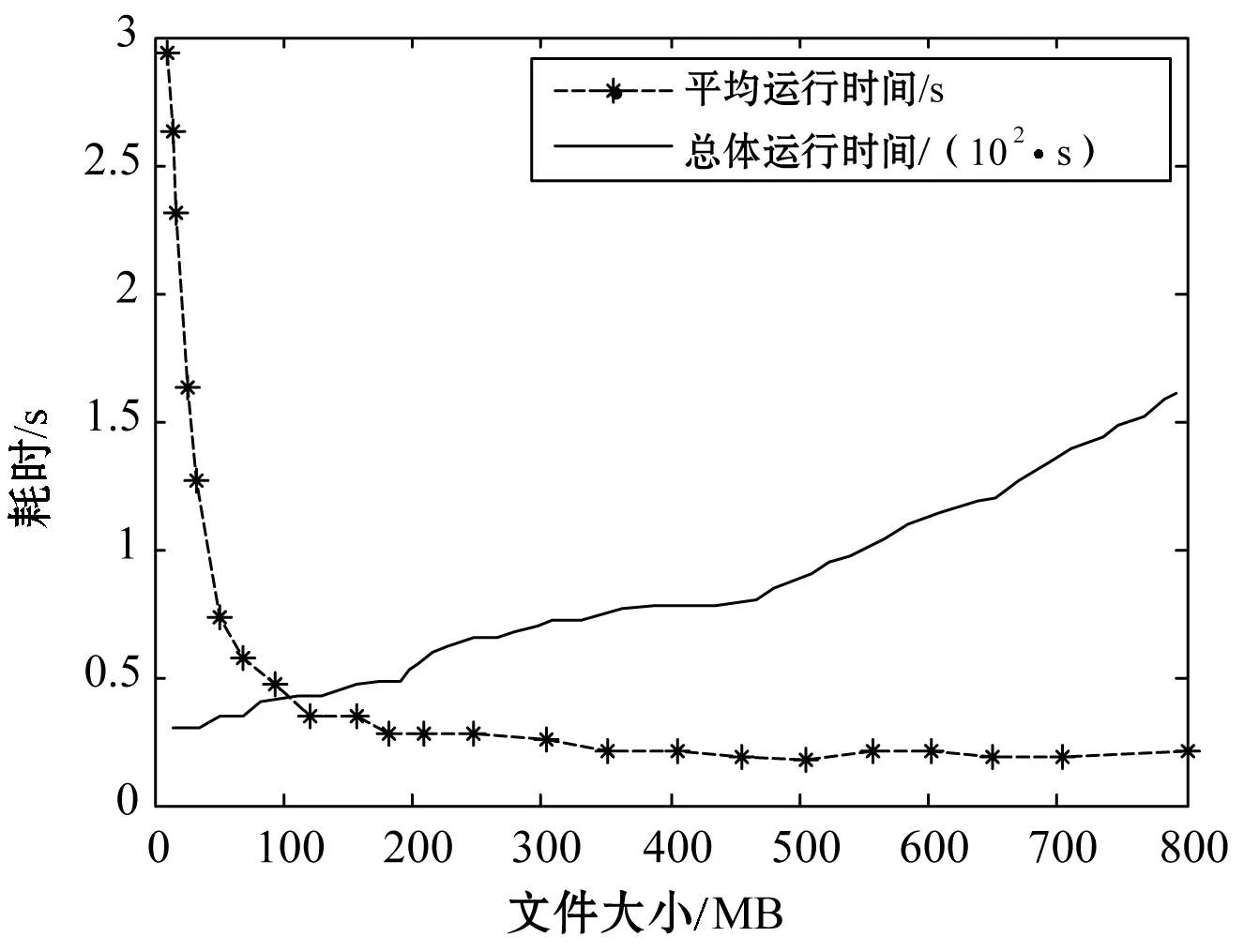
图7 文件大小对运行时间的影响
然后,测试平台对不同文件个数的读写操作,测试结果如图8所示。图8给出的是写文件的时间消耗,文件大小为100 MB。随着文件数量的增多,同样是总体时间消耗逐渐增加,平均时间消耗下降。
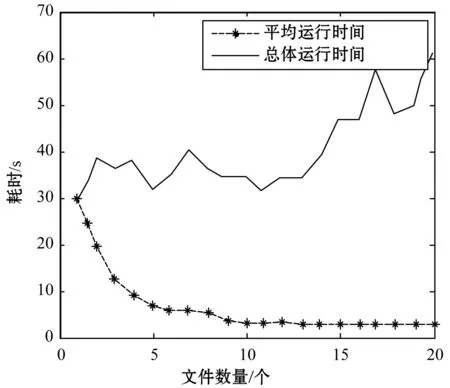
图8 文件个数对运行时间影响
3.2 数据存储测试
开启海量电网状态监测数据管理测试平台,模拟10个数据发送端线程,各线程每秒产生200条数据(数据量约为32 KB)。数据没间隔2小时上传一次,每个上传文件约为120 MB。平台运行10小时后,统计文件分布情况。测试结果表明,文件被成功上传至各个节点,且资源分配十分均匀,没有发生数据丢包问题,存储过程成功完成。
3.3 数据检索测试
设置发送端数据,模拟文件大小和发送频率均不相同的电网数据文件。开启数据检索客户端,测试数据检索时间消耗。为了验证平台的数据检索性能,将同样数据存储到Oracle系统中,并统计检索时间消耗。设置几组检索关键词,分别统计平台与Oracle系统的数据检索性能,测试结果如表2所示。表中每组测试均是5次测试所得的平均时间消耗。
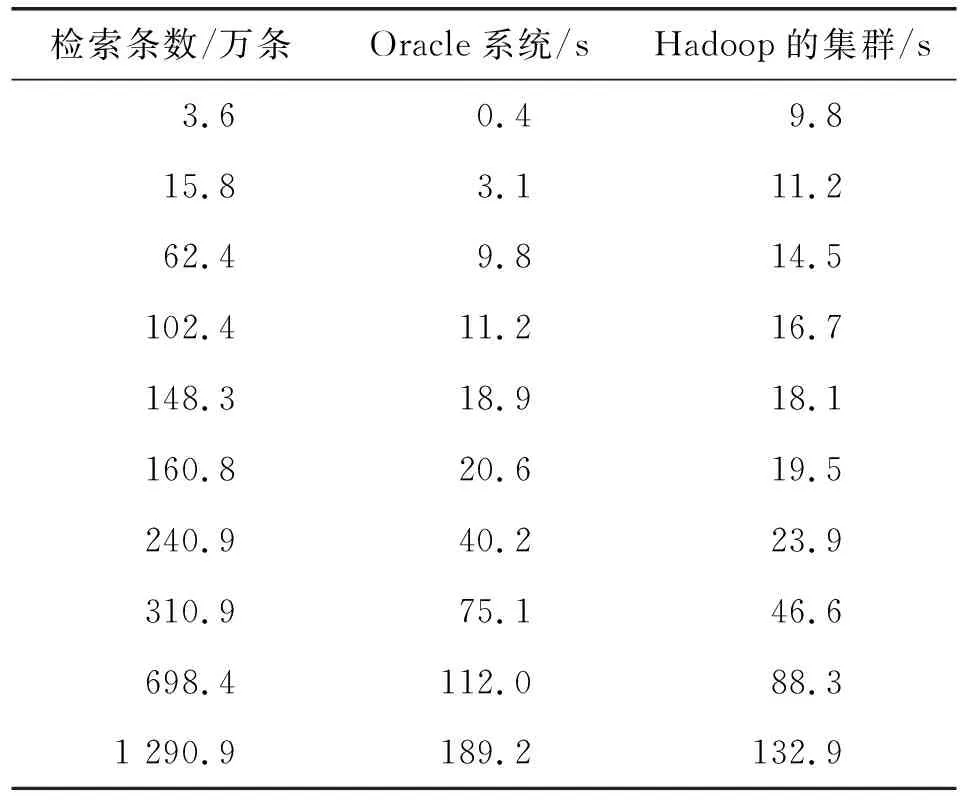
表1 检索时间对比
测试结果表明,当检索条数低于150万时,Oracle系统的时间消耗较少,但是随着检索条数的继续增加,基于Hadoop的集群检索优势得到了充分的体现,检索耗费时间明显少于Oracle系统。测试实验验证了平台更适合海量电网状态监测数据的检索。
4 结 语
本文研究了智能电网中海量电网状态监测数据的存储与管理问题,设计了基于Hadoop的海量数据管理平台。测试结果表明,该平台能够高效地存储与检索海量数据。平台的设计为不同地区电网状态监测数据的分布式存储和管理奠定了基础。进一步测试结果表明,平台对大文件的传输效率还有很大的提升空间,是下一步研究的重点问题。
