基于多模态信息特征融合的犯罪预测算法研究
2018-07-25唐德权史伟奇张波云
唐德权 史伟奇 张波云
(湖南警察学院信息技术系 湖南 长沙 410138)
0 引 言
随着互联网技术普及和深度应用,以大数据、云计算、物联网、人工智能、数据挖掘等先进技术成熟和广泛应用,公安科技信息化为现代公安警务插上了科技的翅膀。同时犯罪分子通过“互联网+”的各种数据信息渠道从事隐蔽更深、危害更大的犯罪活动,已经演变成一场犯罪分子与公安部门在“互联网+”技术、数据信息技术、大数据技术策略、措施、方法领域的竞赛与对抗。尽管有上述技术与方法,但大多数现有方法只可以在相同的基础上处理来自多个域的数据,比如直接连接特性或执行加权求和。有些方法没有考虑来自多个域的数据的不同特征,即多模信息特征[1]。因此,寻找一种方法从多个域多模信息特征进行融合对犯罪预测研究具有现实意义。
1 相关工作
1.1 犯罪发生因素
犯罪学的早期研究试图证明犯罪和各种影响因素之间的关系,如人口统计学、经济学和失业。近年来,这些研究仍在继续证明犯罪和各种影响因素之间的关系。例如,Kelly[2]认为美国城市县的不平等与犯罪之间的关系,并证明社会弱势群体犯下了最暴力的罪行;Hojman[3]研究了拉丁美洲城市的不平等、失业和犯罪,考虑到城市的多样性,并利用回归分析,指出了威慑、贫穷和不平等是犯罪原因的作用;Poveda[4]在哥伦比亚的七个城市研究了社会经济和暴力犯罪。他们的分析表明,城市的经济贫困和人口密度高是他杀率的重要因素。对犯罪的空间模式分析是一种经典的方法,如Cusimano等[5]利用多元泊松回归模型,分析了加拿大多伦多地区暴力伤害的时空模式。Mohler等[6]将犯罪行为从最初的犯罪地点传播到周边地区,并解释了犯罪学和流行病学之间的学科共性和差异。
1.2 犯罪预测方法
犯罪预测方法利用了多种机器学习技术,如回归分析、核密度估计(KDE)[7]、支持向量机(SVM)等。Liao等[8]利用地理信息和受害者特征建立了基于贝西亚的犯罪预测模型。Gorr等[9]提出了一个短期犯罪预测方法,使用一个月的时间范围。Chen[10]等在我国的某个城市应用了一个自回归综合移动平均模型来预测短期犯罪预测,所使用的模型是一种著名的时间序列分析方法,用于预测未来事件。Shingleton等[11]使用了一种基于回归分析的方法来预测在加州萨利纳斯的三种犯罪类型(暴力、凶杀和攻击),使用普通最小二乘法、泊松回归和负二项回归模型。Kianmehr等[12]提出了一个在俄亥俄州、俄亥俄州和密苏里州圣路易斯用k-means集群使用SVM的计算框架。Wang等[13]利用SVM预测犯罪再犯,使用的数据集来自国家档案馆的刑事司法数据的跨大学联盟政治和社会研究。最近,一些研究使用社交媒体数据和KDE进行犯罪预测。
1.3 基于深度学习的特征级数据融合
深度学习在计算机视觉中表现出了显著的表现,如图像分类。此外,深度学习已经被用于新的特征表示和抽象。使用这种机制,可以很容易地应用于从大量数据或复杂数据中总结关键信息或特性。在计算机视觉中,在一些研究中使用深度学习进行特征级数据融合。Lu等[14]融合了全局整体和局部细节图像,以进行图像完美的质量评估,为此他们建立了两种卷积神经网络(CNN)模型:第一个模型用于图像的完全调整;另一种用于精细的随机裁剪图像。每个CNN模型都为图像美学提取了全局和局部特征。提取的特征在第一个完全连通的层中融合。Liu等[15]提出了使用深度自动编码器的音频和视频之间的中层特征表示方法,他们提出的模型由联合表示和多任务结构组成。
1.4 环境上下文信息
使用的环境背景信息是受到BWT[16]的启发。这两种理论证明了邻里表象和犯罪活动之间的联系。BWT认为,社会环境的混乱,如破碎的窗户、垃圾、撞坏的汽车等,是犯罪活动增加的原因。也就是说,一个视觉感知障碍的地方有很高的犯罪发生机率。这是一个城市规划和建筑设计方案,目的是防止犯罪和减少使用建筑环境犯罪的恐惧。它的设计有三个原则,即自然监视、自然访问控制和领土强化。Salesses等收集了街道图像,并通过与人类视觉感知的对比实验,测量了视觉感知的安全、唯一和作用图像,发现视觉感知安全得分与犯罪负相关。
2 多模态信息融合模型
现代信息庞大且复杂多样,在不同的应用领域信息的特征都不相同。在形式上主要有文本、图形、图像、音频、视频等,在信息的分布上有分布式存储在不同地域、不同网络服务上。预防犯罪需要提供准确、及时、全方位的信息。针对多源异构信息在形式上具有多样性和复杂性的特点,必须结合数据挖掘与数据融合技术,构建多模态信息融合模型。
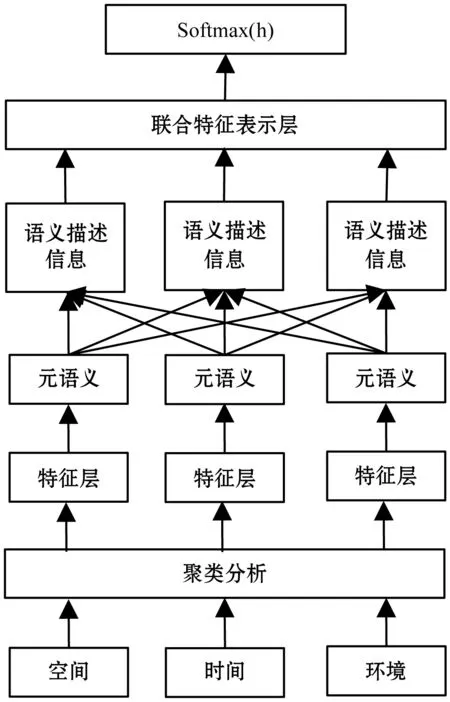
图1 多模信息融合预测模型
在多模态数据融合技术中, DNN用来学习多个数据集的联合特征表示。也就是说,DNN学会了如何将功能集成到一个统一的特性中。因此,基于特征级数据融合方法的基于DNN的预测模型通常比直接拼接方法更能令人满意,原因是它能克服传统方法的局限性,如:过度拟合,难以发现高度非线性关系,以及多数据集之间的冗余和依赖等。本文采用深度神经网络DNN(deep neural network)技术[17]和学习方法进行多模特征融合,使用了三个不同特征组的特征级数据融合,即:空间、时间和环境。首先将这三个类型特征分别进行聚类分析处理,然后进行特征融合,再从元语义中进行语义分析得到联合特征表示,最后预测犯罪事件,其预测模型如图1所示。
图1显示了DNN的结构。我们将DNN配置为四层:空间、时间、环境上下文,以及联合特征表示层。首先,空间、时间和环境上下文特征层独立运行。每个特征层都使用相应的特征组,这些特征组由具有类似于其输入的属性组成的数据组成,以执行多级特征表示和抽象。特征层用来从输入信息中提取特征。将这三个特征层的语义描述结果连接起来,然后提供给联合特征表示层,将这些特征整合成一个统一的特征。联合特征表示层学习适当的权重,以整合这三个特征。空间、时间和环境上下文特征层由三个层组成,分别为256、256和128个神经元。联合特征表示层有三层,尺寸为1 024、1 024和2。所有层都应用了整流线性单元,用于激活函数和退出。因为涉及二进制分类,所以在Caffe框架中使用了Softmax[18]作为损失层。Softmax(h)是用来计算逻辑损失一个多分类任务的函数,通过Softmax(h)函数传递实值进行预测,以获得类的概率分布。Softmax(h)输出类的概率为:
(1)
式中:n和k分别表示批处理大小和类。损失E计算公式如下:
(2)
3 本文算法
本文提出了一种新的多模信息融合犯罪预测算法(Multi-modal Information Fusion Crime Prediction),简称MIFCP算法。MIFCP预测模型采用DNN的前向传播算法,利用特征的混淆矩阵W,偏倚向量b,特征向量x进行一系列线性运算和激活运算,从输入层开始,一层层的向后计算,一直运算到输出层,得到输出结果为止。
算法1MIFCP
输入:层数L,混淆矩阵W,偏倚量b,特征向量值x
输出:输出层的输出aL
M1:初始化a1=x
M2:For l=2 to L do
M3:al=Softmax(zl)=Softmax(Wlal-1+bl)
M4:输出aL,结束。
算法2k-均值特征聚类
输入:犯罪类型、集群的数量,初始值。
输出:混淆矩阵a,b,c,d的值。
K0:n个数据成员初始化;
K1:随机选择聚类中心;
K2:根据它们与聚类中心的距离分配实例;
K3:调整聚类的中心;
K4:根据目标函数,如果收敛则进入第K5步,否则转步骤K1;
K5:输出混淆矩阵W,结束。
算法2输出混淆矩阵的格式如表1所示。
所有这些值都来自于事实表提供的信息,也称为混淆矩阵,提供了预测器中实际(TPR)和预测(FPR)的分类计算公式如式(3)和式(4),预测的正确率和精确率如式(5)和式(6)。
TPR=a/(a+b)
(3)
FPR=b/(b+d)
(4)
Accuracy=(a+d)/(a+b+c+d)
(5)
Precision=a/(a+b)
(6)
k-means算法定义k个中心,每个中心为一个特征聚类[19],将n个数据对象划分为k个聚类以便使得所获得的聚类满足目标函数。有了k个中心之后,必须在相同的数据集点和最近的新中心之间进行新的绑定,生成一个循环。由于这个循环,我们可能会注意到k中心会一步一步地改变它们的位置,直到没有做更多的改变,或者换句话说,中心不再移动。因此算法的时间复杂度上界为O(n·k·t),其中t是迭代次数。该算法的目标是最小化目标函数,即平方误差函数J(v)如下:
(7)
式中:‖xi-vj‖是xi和vj之间的欧几里得距离,ci是第i个集群中的数据点个数,c是集群中心个数。
4 实验与评价
4.1 实验数据集
数据收集对于准确预测犯罪事件是至关重要的。本文收集了来自七个领域的数据:犯罪发生报告、人口、住房、经济、教育、天气和图像数据。数据来自芝加哥,因为它有大量人口(约270万)和高犯罪率(2014年总共有274 064宗案件)。从芝加哥数据门户网站收集了包含犯罪发生数据的报告。我们使用了2014年的报告,其中包括犯罪的日期、犯罪类型和纬度/经度坐标。该报告列出了26种犯罪类型总共273 914个案件。此外,我们使用了2014年美国社区调查(ACS)数据是从美国检察员(http://factfinder.census.gov)来收集各种社会经济因素(人口、住房、教育和经济数据为美国人),这是在芝加哥普查区规模的组织。最后,我们在801个有不完整数据的人口普查区域中的11个。例如,人口普查区编号9800和9801没有数据,人口普查区编号3406、3501、3504、3805、3815、3817缺乏中位数住房价值数据。
天气和图像数据分别从地下气象API(https://www.wunderground.com/)和谷歌街景图片API(https://developers.google.com/maps/documentation/streetview/)获取。数据包括天气和天气事件的平均值及其最大值和最小值、雪、雨、冰雹和龙卷风。为了比较实验效果,消除了平均湿度和降雪数据的缺失值。此外,冰雹和龙卷风在2014年没有发生,也没有考虑。使用纬度/经度坐标采集图像数据。它们是在芝加哥的边界内使用点抽样法获得的。在芝加哥的边界内,所有0.001纬度/经度坐标增量的数据都被采集到[41.644,-87.940][42.023,-87.524],不包括被排除的人口普查区域(n=60 348)。因为图像数据是结构化的数据,从谷歌街景图像数据中提取特征为我们的预测模型提供环境上下文信息(图像数据在数据集网站http://cvml.catholic.ac.kr获取)。虽然图像数据不是实时采集的,但它们被认为足够提供具有相关环境背景信息的预测模型。利用AlexNet[20]提取图像数据特征,在图像分类方面表现良好,数据集的描述如表2所示。
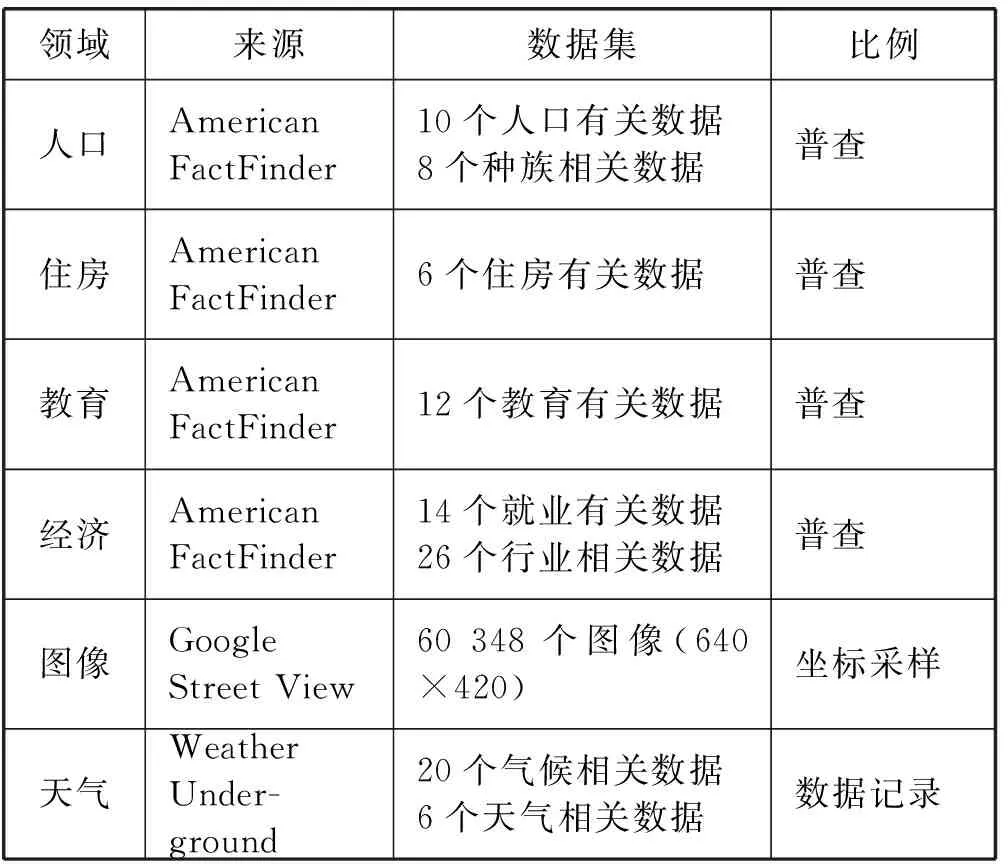
表2 数据集
4.2 数据选择
从各种网上数据库收集的数据可能包含与犯罪发生不相关的信息。为了解决这一问题,有必要消除数据的异常和输出,以选择有意义的数据与犯罪发生相关的统计意义。这种过滤有助于准确有效地预测犯罪事件。为此,对数据选择之前进行Pearson相关系数分析。采用统计分析软件包SPSS 18.0进行Pearson相关系数分析。最后考虑了从-0.2到0.2不等的Pearson相关系数,P值大于0.05,并将其丢弃。Pearson相关系数结果表明,102项信息中有53项与犯罪发生相关。
然而,由于使用图像数据从AlexNet提取的4096-D特征向量,不能从Pearson相关系数的分析中获取环境上下文信息。因此,为了分析与环境背景信息有关的犯罪案件数量的差异,我们进行了kruskal-wallis H检验(也被称为“单项方差分析”),这是一种基等级的非参数测试,用于分析两个或多个独立组之间的统计显著性差异。环境背景信息必须被分组来进行kruskal-wallis H测试,因为它没有假设一个正态分布。每个组都应该由与外观相似的环境上下文信息组成。我们将环境信息分成十个组,使用k-means聚类来进行kruskal-wallis H检验,以及在kruskal-wallis H测试后对P值的Bonferroni型校正P值进行测试。采用R软件包中的平均秩和(PMCMR)包进行成对多次比较进行上述测试,kruskal-wallis H检验结果如表3所示。
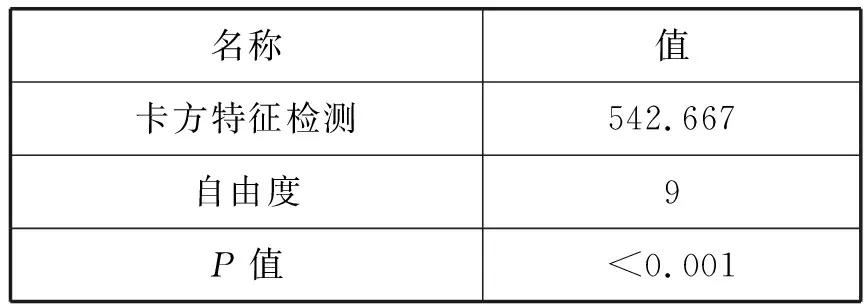
表3 Kruskal-Wallis H测试结果
在kruskal-wallis H检验后对P值的Bonferroni型校正进行了测试。kruskal-wallis H检验结果显示P值小于0.05。此外,在kruskal-wallis H测试后,Dunn对P值的Bonferroni型校正结果显示了环境上下文信息组之间的统计显著性差异如表4和表5所示。这些结果表明,根据环境背景信息,犯罪事件的数量存在差异。换句话说,使用环境背景信息来预测犯罪的发生是恰当的。
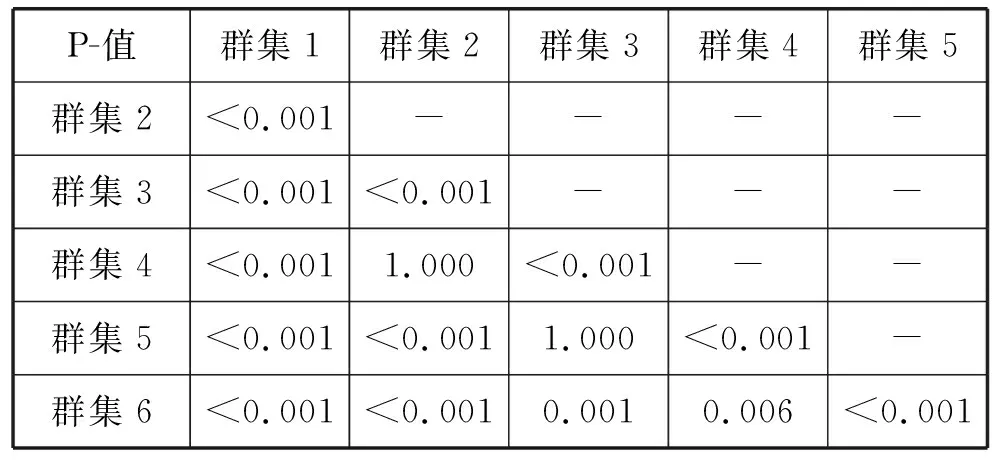
表4 Bonferroni型P值调整结果(1)
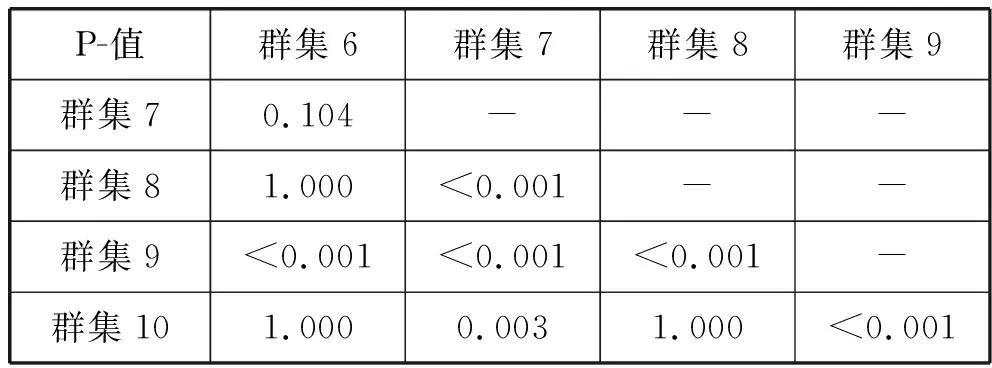
表5 Bonferroni型P值调整结果(2)
4.3 实验性能评价
通过与支持向量机SVM和核密度估计KDE(Kernel Density Estimation)比较,分析了本文预测模型的性能。SVM是一个通用的机器学习框架。使用LIBLINEAR[21]训练了SVM,这是一个公共可用的大型线性分类库。SVM使用了一个统一的特性集,由直接连接生成。对参数c进行了不同的训练,得到了最优值。基于KDE的预测模型是一种估计犯罪发生密度的一般方法,在R软件包中使用ks包进行训练,并利用d标量插件带宽获得了参数h的最优值。然后,通过计算正确率、精确率和曲线下面积(AUC)来测量预测模型的性能。根据DNN的训练数据和DNN模型的独立分类器来评估性能,表6给出了本文算法和其他两种算法准确度/精确度的性能评价结果。
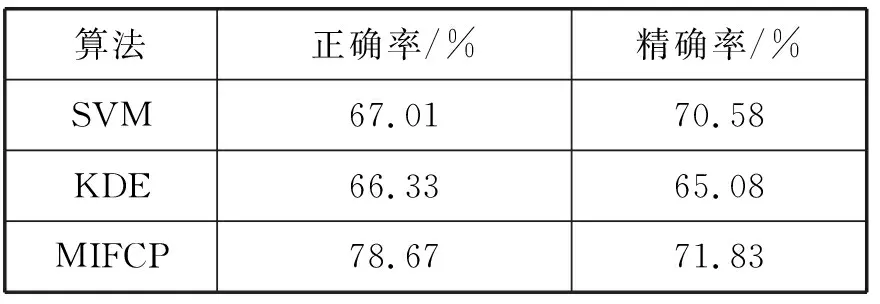
表6 三种算法正确率和精确率结果
图2根据训练集1∶1、1∶2、1∶5、1∶10的比例对三种算法进行绩效(AUC)评价结果。从这些结果中,我们发现,MIFCP算法是预测犯罪发生的一种更合适的方法,而SVM和KDE这两种算法的效率都较低。
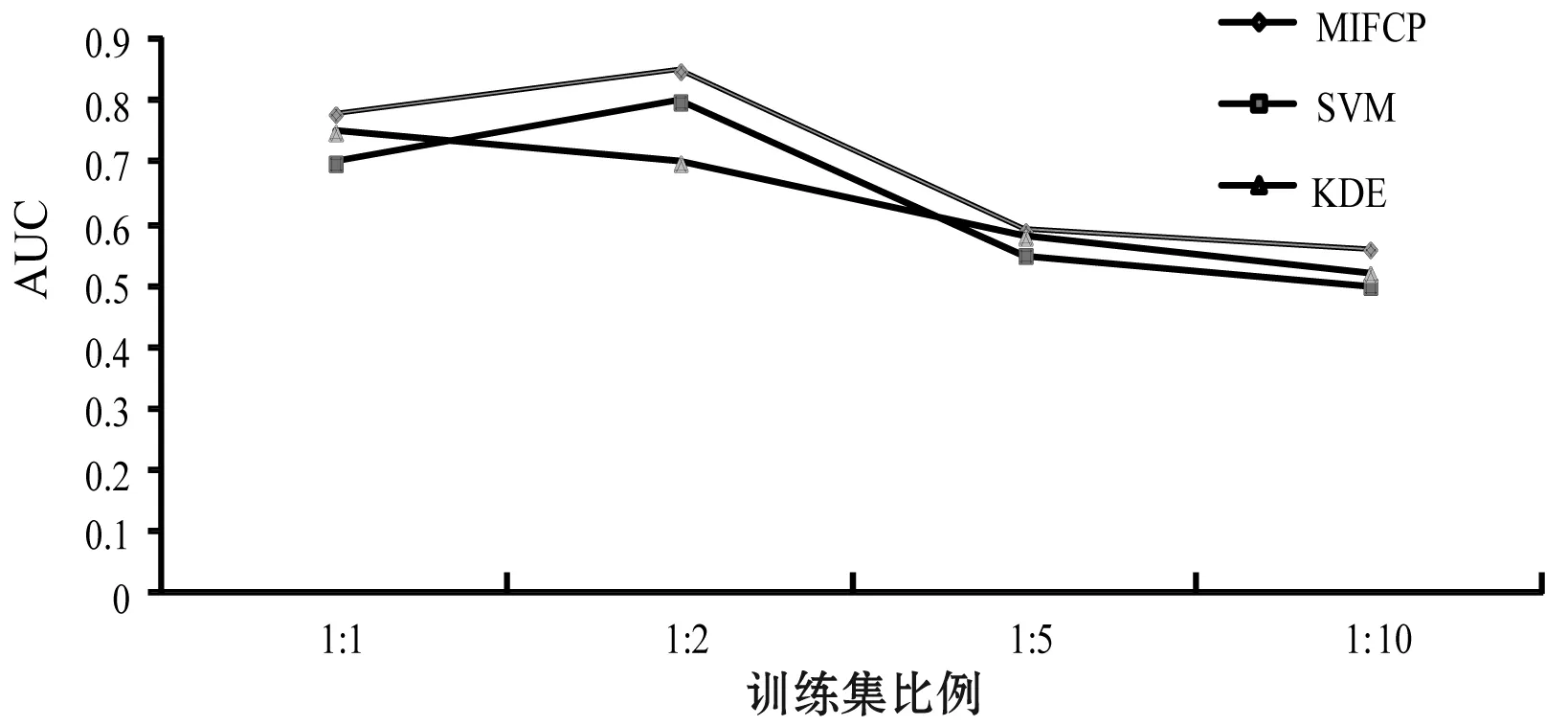
图2 三种算法准确度/精确度性能比较
5 结 语
本文利用环境上下文信息有效地融合多模态数据,结合某个领域过去的犯罪活动记录,并通过有效数据处理预测犯罪的发生,提出了基于多模态信息融合的犯罪发生预测算法。本文首先将空间、时间、环境和上下文信息特征进行融合,然后利用特征目标函数计算逻辑损失,提高了全局特征的正确率和局部特征的精确率。实验结果表明,在不同比例数据训练集条件下,该算法比现有方法的正确率和精确率分别提高了约12%和4%。未来计划能将此项研究工作扩展,以预测犯罪发生的类型和时间,或为犯罪类型和时间的预测寻找其他数据,以提高警察执法效率。
