面向MapReduce异构集群的低功耗调度技术研究
2018-07-25任桂山刘梦泽陈学梅李红艳徐朝农
任桂山 刘梦泽 陈学梅 李红艳 徐朝农
1(中国石油大港油田公司采油工艺研究院 天津 300280) 2(中国石油大学地球物理与信息工程学院 北京 102249)
0 引 言
现今,很多服务性公司都有庞大的客户群以及客户在使用过程中产生的数据资料信息。随着我们对这些海量数据进行计算、分析的需求的提升,各种各样的计算挑战也随之而来。其中最主要的挑战就是降低处理这些数据过程中产生的计算能耗。2010年全球数据中心耗电量达到全球总耗电量的1%~1.5%,到2012年全球数据中心耗电量为占全球总用电量的2%[1],而2016达到了3%,并且随着数据中心数量和规模的扩张电量消耗仍在以每年15%的速率不断增长[2]。2016年全球数据中心电量消耗已经达到1 520亿千瓦时,且仍以每五年翻一倍的速度快速增长,电费成为数据中心建造的需首要考虑的问题之一[3]。2011年IT领域电量消耗导致的二氧化碳排放量占全球总排放量的2%,按照现有的增速计算,到2020年,排放量将是现有排量的两倍。我国的数据中心也存在相同的情况而且计算电量使用的效率和国际平均水平有一定的差距,截至2015年数据中心总量已经超过40万,年用电量超过社会用电量的1.5%,平均电能使用效率(PUE)普遍大于2.2[4]。因此无论是从降低数据中心成本还是从环境保护的层面出发,研究海量数据处理任务的节能调度技术都是势在必行的。
一般数据中心使用少则数十个,多则成百上千个节点处理数据,其中绝大多数采用MapReduce作为数据处理思想。MapReduce是谷歌提出的一种关于超大量数据并行计算的编程模型[5]。MapReduce将任务处理划分为Map和Reduce两个阶段,分别对数据进行映射和归约。Hadoop是现今实现MapReduce思想的主流并行计算框架,它默认提供FIFO、容量以及公平调度方式。这些调度方式着重考虑负载平衡和执行效率,忽略了处理能耗的问题。
现有对MapReduce集群中任务调度的研究侧重对任务执行时长和负载均衡的优化。绝大部分基于MapReduce的应用对执行时长没有较高的需求,而在异构集群中负载均衡不可避免地带来能量利用率低的问题。因此,近年来,MapReduce的性能优化问题得到了广泛的研究,关注点主要集中在执行时间、任务负载以及功耗优化上。
Yao等[7]研究了任务之间具有依赖性的前提下,执行时间最优化的问题。Ibrahim等[8]根据MapReduce中数据的本地性,将任务和其数据分到同一节点从而优化总任务执行时间。针对大型电商网站任务规模小,数量大的特点,Ren等[9]提出了最优化执行时间调度算法Fair4S。另外,Pastorelli等[10]考虑在任务切片大小不同且已预估出每个任务大小的情况。Wolf等[11]为公平调度器增加了弹性的特点,从而保证响应时间最短。Verma提出了一个叫ARIA(资源自动分析分配)的框架,通过分配Map slot和Reduce slot的数量使得MapReduce执行性能得到优化。
在负载均衡的优化上,Polo等[12]通过定时获取数据的处理情况,动态调整资源分布,Nanduri等[13]的启发式策略避免将当前任务分配到过载的机器上。另外,Sandholm等[14]提出了一个有动态的优先级的Hadoop并行调度器,并且给出一个可以由用户自己定制任务分配方式以及执行先后顺序,从而达到按规定的时间以及用户想要的方式执行[14]。
Kurazumi等提出了一个动态的slot调度技术针对IO密集型任务进行调度,从而在IO等待的时间高效利用处理器资源的目的。Tian等[16]针对MapReduce Job强周期性的特点,在节点空闲的时间关闭节点从而降低整体能耗。Narayanan[17]根据数据访问频率将数据分到不同的磁盘上并对访问频率低的磁盘进行节能处理,达到在存储上节能的目的。Salehi等[18]根据任务优先级、密集程度、剩余执行时长等,使用DVFS(动态电压频率调节)和DPM(动态电源管理)技术来优化功耗。Mashayekhy等[20]预测了每个任务的执行功耗和执行时间,建立功耗模型,并使用贪心策略对问题求解,然而他以slot为研究对象而不是与实际更契合的节点。
针对基于MapReduce的应用对低能耗的迫切需求,本文建立了以低能耗为目标的任务调度模型,分析了执行能耗过高的因素。另外,和其他降低能耗的工作不同的是,本文在MapReduce的节能方面做了如下工作:使用了更切合实际的能耗模型,对基于任务分配的功耗最优化问题进行建模;通过优化工具对问题进行求解,并在GridSim模拟的分布式环境中对任务的执行功耗进行评估和分析,揭示了调度策略时限和能耗的关系。
1 模型定义
如图1所示,一个MapReduce集群通常将不同执行能力的节点整合起来,而每个节点根据自己的执行资源(处理器核心数、磁盘大小、内存大小等)被等分成一定数量的slot。这些slot是虚拟执行概念并非实体的物理结构,Map-Reduce任务便在这些slot中执行。执行一个MapReduce Job需要将以Key-Value形式存储的数据读取出来,这些数据默认以每块64 MB存储在分布式存储中,假设一共需要处理BM块。而后在执行 Map阶段时,JobTracker将这些数据块作为任务块分配到集群的各个处理节点的Map slot中处理。Map阶段执行完毕,经过聚合以及洗牌之后共有BR个任务块,将这BR个任务块再分配到各个节点中的Reduce slot中执行Reduce阶段,最后将结果写回分布式存储中。我们使用(BM,BR)表示一个MapReduce Job。
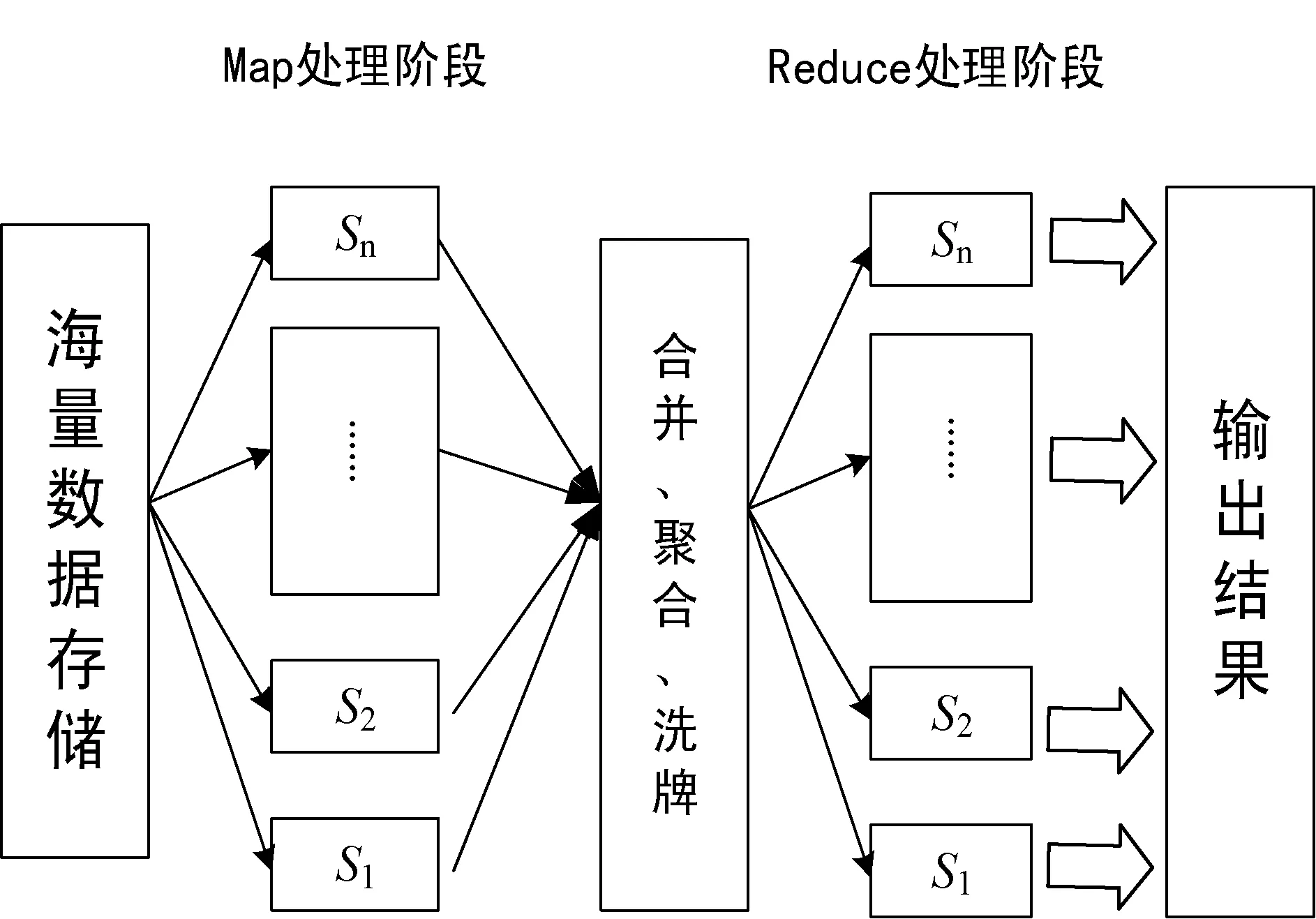
图1 MapReduce执行流程示意图
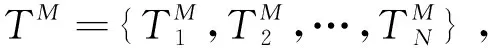
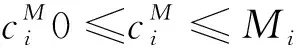
(1)
(2)
式中:Ci是和节点相关的常数,f是处理器频率(固定值),根据频率上限最低的节点得出,vi表示该频率下该处理器电压。
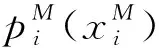
(3)
(4)
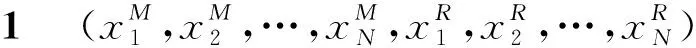
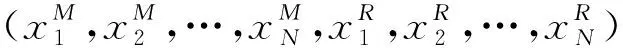
图2描述了一个含有Si={S1,S2,S3}三个执行节点的集群中Map阶段调度策略的执行过程。其中S1、S2和S3各有4个、6个和5个Map slot。
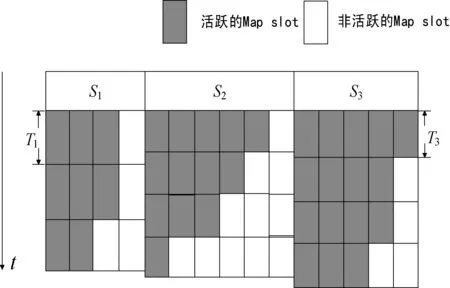
图2 Map阶段调度策略
由此可知,Mi={4,6,5},需要处理BM=37个Map任务,各个节点Si在Map阶段执行任务的时间是TM={T1,T2,T3}。使得Map阶段执行功耗最小:
s.t.
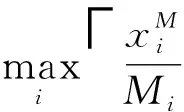
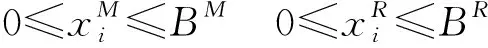
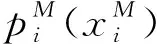
由于该问题是典型的组合优化问题,因此很难快速求解。本文采用成熟的优化工具CPLEX进行求解。
2 实验及分析
本节采用GridSim工具进行实验。Gridsim是一个对大型分布式系统进行资源和应用调度的网格模拟工具,使用它可以对大型的异构分布式系统进行大量资源、海量数据调度和大量用户的场景进行仿真。本次实验使用的是GridSim 5.2 beta版本。按照表1以及其后描述的实验规则分别在15个节点和25个节点的集群中进行实验,且每个节点中的slot的数量服从均匀分布Ai~U(8,30),Map slot的数量服从离散均匀分布Mi~U(1,Ai)。同理可得Reduce slot的数量分布。使用TeraSort和K-means的执行效果作为评价标准。将本文模型与默认调度器以及ARIA中的SLO调度器的能耗效果进行对比分析。实验设置如表1所示。
实验过程中将执行TeraSort过程在实验1到实验4的时间限制分别设置为180、280、200和300 s;执行K-means聚类过程的时间限制分别设置为200、300、220和320 s。
实验1以180 s作为时间限制执行TeraSort。本文调度模型和ARIA框架的SLO调度器分别在175 s和170 s执行完毕。由图3可知,本文调度模型和ARIA框架随着时间限制的增长,功耗在不断降低,说明时间限制是影响最终执行功耗的一个重要因素。但在实际生产的处理过程中,时间限制不能无限制的增加,管理员仍然需要一个合适的时间约束来使得结果有一定的实时性。而在时间限制达到260 s以后,执行功耗下降趋平,说明此时集群接近两者执行功耗降低的极限。
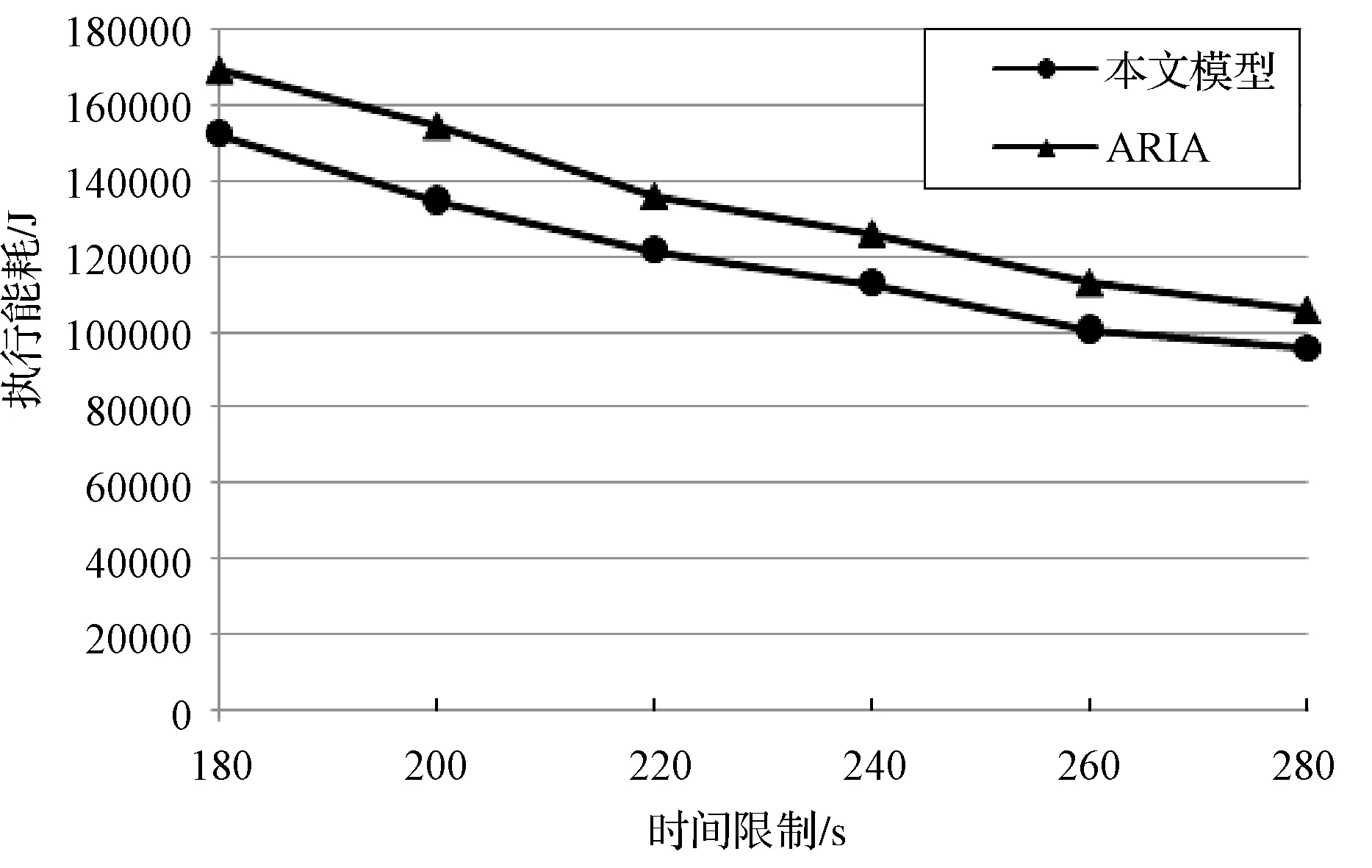
图3 实验1执行TeraSort功耗与时间限制关系图
由图4和图5可以看到执行TeraSort和K-means聚类两个比较标准,本文模型相比默认调度策略和ARIA框架的SLO调度器执行功耗都有明显下降。相对于默认调度策略平均下降了29.7%,相对SLO调度器平均下降19%。在执行K-means的实验4中,本文模型相比默认策略降低了34%,即295 106 J,执行实验1的TeraSort过程中也有26%的下降。执行K-means的实验1中,相比SLO调度器有21%的下降,即108 012 J。不论是执行TeraSort还是K-means,本文模型相比默认策略的节能比率大致上随任务的增多而增大。
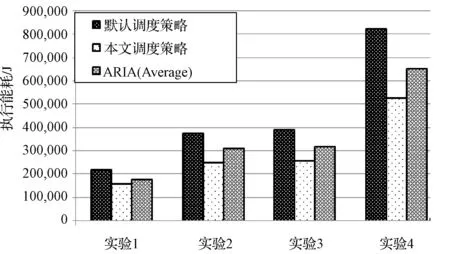
图4 TeraSort各实验功耗对比图
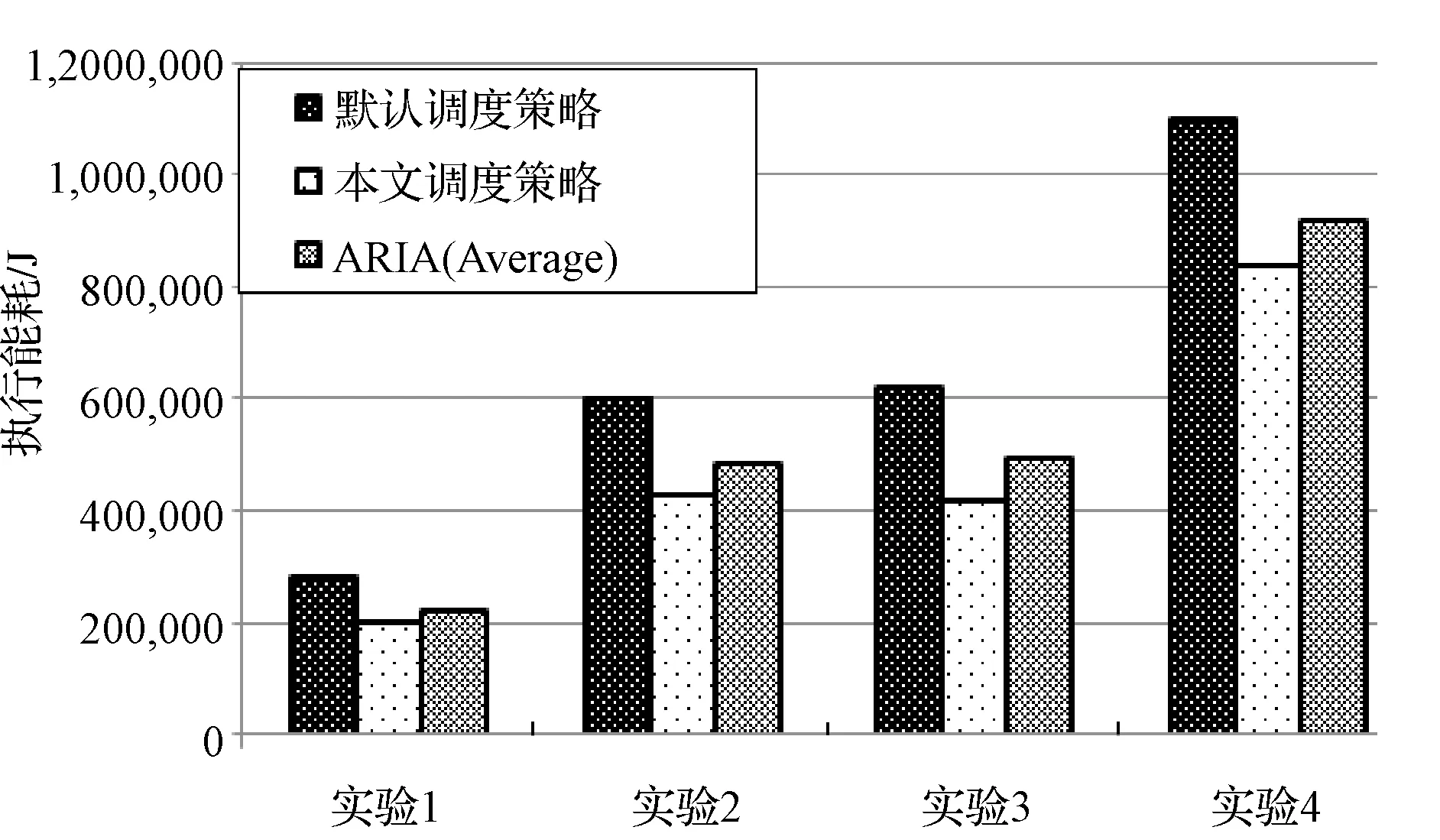
图5 K-means各实验功耗对比图
3 结 语
针对当今数据中心能耗巨大的问题,原来提出的DVFS、参数优化和虚拟机配置都起到了提高能源利用率、降低能耗的作用。而本文通过建立能耗调度模型,优化不同执行能力节点上的任务分配数量从而达到降低能耗的目的。通过实验结果可以看到,该方法比默认和ARIA有更好的节能效果。
