基于Docker swarm 集群的动态加权调度策略
2018-07-25孟庆永谢雨来秦磊华
黄 凯,孟庆永,谢雨来,2* ,冯 丹,2,秦磊华,2
0 引言
由于Docker相对于传统虚拟机的优势,越来越多的研究工作者开始使用 Docker来代替虚拟机[1]:Tihfon等[2]借助于Docker实现了多任务PaaS(Platform as a Service)云基础架构,通过Docker实现了应用的快速部署,应用程序的优化和隔离;Nguyen等[3]通过Docker,实现了用于高性能计算的分布式MPI(Message Passing Interface)集群,借助于Docker,使原本耗时的设置MPI集群工作变得相对简便;Julian等[4]借助于Docker优化了自动缩放网络集群,而且他们认为Docker容器可以在更大规模的生产环境中进行更广泛的应用。
目前Docker swarm提供的资源调度策略比较单一,只考虑节点能否满足任务需求和节点上的容器数量,没有在节点之间进行负载比较来选出最合适的节点来部署容器,因此会出现节点上资源使用率不均衡的情况[5]。
针对Docker集群网络负载的资源调度,Dusia等[6]提出一种调度策略,可以保证不同优先级的应用容器享有不同比重的带宽,在尽量满足高优先级网络服务的同时,将剩余带宽尽可能分配给低优先级的服务,从而保证网络上的服务质量(Quality of Service,QoS)。这种调度策略,通过在原Docker架构中增加分组分类器和优先级调度器来实现网络资源调度。流中的分组被分类并添加到三个可用优先级队列中的一个。调度器对数据包进行出队,并根据队列的优先级将每个数据包发送到容器。同时,该调度策略通过对每个优先级类的流执行随机排队规则,使得每个优先级内各容器能够依次发送数据,保证流传输的公平性。此外,该调度策略增加了一个限制容器发送数据包速率的功能,通过这个功能,就可以为容器分配精确的网络上下限,限制容器的网络占用,实现更好的资源调度。
McDaniel等[7]对于容器的 I/O争用提出了一种扩展Docker和Docker swarm的双层方法(即在集群和节点级别),使得它们能够监视和控制Docker容器的I/O。在节点级,通过设置容器的优先级来分配给容器对应比例的I/O;而在集群级则通过对节点I/O资源的使用分析,实现更好的负载平衡。
Monsalve等[8]通过将时间切片的概念扩展到虚拟化容器的级别来解决计算资源过度使用的问题。他们使用观察决定法(Observe Decide Act,ODA)控制循环来扩展Docker,实现了一个简单的roundrobin时间切片策略。他们为单个容器保留整个系统的CPU资源,然后每个容器只运行一段时间间隔。这种类型的策略在容器级别具有与组调度相同的优点。
以上调度方式都只针对某一资源作了优化,应用在对此资源偏重的负载下能起到不错的优化作用,但是也存在着问题,优化都是针对于节点内部的,在集群的角度,没有根据应用的资源偏重,将不同偏重的应用混合放在一个节点上,来从源头上减少资源争用的开销。
为了改善Docker集群的资源调度,卢胜林等[5]提出了另外一种基于Docker swarm集群的容器加权调度策略。通过对节点分配和消耗资源的分析,计算出节点权值,然后将新的容器部署在低权值的节点上,以实现集群的负载均衡。在这种调度策略下,系统统计了4项参数指标。针对不同的集群,对参数分配以不同的权重,以适应不同侧重的应用系统,大大改善了Docker swarm的集群调度策略;然而,这种调度策略虽然改善了Docker集群的负载均衡问题,但并没有对应用的资源偏重进行分析,因为对于集群来说,很难保证各个服务的资源偏重会和已经分配的权重吻合,这样就存在很大可能当前服务是CPU偏向的,但是被分配到内存占用少的节点上。这样结果就是某些节点权值高,但只有某项资源消耗很高,其余资源并没有太多的占用。
在实际应用中,许多工作使用了机器学习的算法,对系统应用的资源需求进行预测,从而提前进行资源分配调度,让资源在对应时间段分配给不同的服务,从而实现资源的充分利用。
Kang等[9]提出了一种高效的异构Docker容器资源管理策略,使用k-medoid算法、分割周围类算法等方法,实现了工作负载能效感知的容器代理系统,并通过这个系统既降低了由运行容器应用程序引起的能耗,又保证了系统性能。Calheiros等[10]提出了一个基于自回归积分滑动平均模型(Autoregressive Integrated Moving Average model,ARIMA)的云计算负载预测模型,平均准确率达到了91%。
机器学习的调度策略能够实现更加优秀的资源利用,但是相对也更为复杂,需要依据具体的集群设计算法模型,对于大型的项目而言,其优势明显;而对于简单的集群则有些得不偿失,因为机器学习算法需要有足够样本的训练集,对于容器集群,则需要收集大量的时间序列的容器资源使用量,有着不小的存储和计算开销。
因此本文综合考虑服务对资源的偏向以及节点上资源利用情况,提出了一种动态加权调度算法。该算法能根据服务对资源的偏向性,动态调整资源权重,由资源利用率和权重计算出代表节点负载的权值,以此来进行调度。该算法既能实现更准确的资源调度,也避免了机器学习调度带来的巨大开销。
1 Docker的资源调度策略
1.1 Docker整体架构
Docker整体是一个 C/S模式的架构[11],而 Docker的后端属于松耦合架构,这使得Docker的各个模块相对独立,不会因为对于某些模块的修改或者添加模块对其余模块造成很大影响,因此,在对Docker源代码进行相关改动,修改添加功能时,不会对其他功能造成太大影响。
Docker主要由Docker Client和Docker Daemon两部分组成,两者通过相互通信协作,共同实现Docker系统的功能,进行容器管理。
Client主要负责用户交互,通过用户指令与Daemon通信,显示Daemon的执行信息;Daemon属于主要执行模块,Docker的容器管理和集群管理等大部分功能都在该部分实现。
1.2 Docker swarm的资源调度
Docker swarm提供了 Random(随机)、Spread(扩散)和Binpack(装箱)三种资源调度的方法[12]:Random调度策略随机选择容器的部署位置,这种调度显然问题很大,一般只用于集群的测试;Spread调度策略,按照各节点总内存和CPU内核数来部署容器,这样能够让容器相对均匀地分散在每一个节点上;Binpack调度策略,先把一个节点的资源使用完后再向别的节点部署容器,这种调度方式可以尽可能地使用每个节点的资源,节省未启动节点的资源。
Docker swarm自带的这三种资源调度方式,可以满足一些对集群的工作效率要求不是很高的应用,但是对于有些应用(如云平台),需要充分使用集群的整体性能,其对于负载均衡、资源利用率要求会比较高。在这些情况下,Docker swarm自带的调度策略则存在明显的不足。
首先,Docker swarm主要根据各个节点的全部内存大小这一参数来分配任务。因为对于Docker容器来说,内存资源是可以准确统计的,但是对于CPU的资源分配则只能指定内核数或者指定使用的权重大小,并不能准确统计CPU的使用情况。
然后,Docker swarm并没有考虑每个节点实际的可用资源,以及分配出去的资源使用情况。例如,Docker swarm所存储的节点内存总量来自节点计算机的内存总量,但是在节点机器自身运行操作系统和软件都是会占用内存的,这导致节点实际可用内存会比Docker swarm所统计的要少。此外,一般情况下,为了应用能够稳定运行,都会为应用分配足够多的资源,但是实际上,大多时候应用都不是在以最高的负载在运行,而且CPU、内存、网络等也不会同时处在最高负载,这样分配的资源很多时候都不会用尽,而Docker swarm并不会对未使用的资源重新分配,造成了资源的浪费。
2 动态加权资源调度策略
加权调度算法采取以下的计算方式,选择4项参数:CPU使用率N(c)、内存使用率N(m)、网络负载N(n)和已分配内存的平均使用率N(u)。使用W(k)代表节点k的总权值来反映节点负载,权值越高,说明节点负载越高。k1、k2、k3、k4来代表4项参数初始所占权重。为了解决某参数值偏大而总权值不高无法准确反映节点负载的情况,引入α、β、γ三项参数进行权值调整。α、β、γ 原值为1,当 N(c)、N(m)、N(n) 有一项超过0.8后,增大对应α、β、γ的值为h(h>1),通过增大该项资源权值以修正节点权值,更确切地反映节点负载。节点k权值计算公式如式(1)所示:
W(k)=k1αN(c)+k2βN(m)+k3γN(n)+k4N(u) (1)
但是为了实现更好的节点资源利用和负载均衡,需要避免出现某项资源利用率过高而其余资源利用较低的情况,在加权调度算法的基础上对调度策略进行优化。
普通的加权调度算法会出现节点资源使用不平衡的情况,主要是没有考虑到实际的服务占各类资源的比重和集群设定的资源权重不是一直近似的。因此针对这类特定服务,需要对权重进行重新调整。引入新的参数bias,当创建的服务对资源的需求权重和集群分配的权重近似时,设置bias为空值;当两者权重不相近时,通过指令对这两个参数进行动态调节。
例如当前集群的CPU资源权重为0.4,内存资源权重为0.6,而新创建的服务对CPU资源需求比较高,如果按照原本的权重进行调度,因为内存资源占比重较大,所以这个服务很可能被分配到一个内存剩余资源比较多的节点上面去,但是这个节点的CPU资源未必是丰富的。这时通过参数bias告诉系统当前应用服务对CPU资源需求高,将CPU的权值调整为2×0.4,这样最终CPU资源与内存资源的比重就会变为8∶6,只针对于这个服务而言,本次调度会把其分配到一个CPU资源充分的节点上。这样不仅能够对适合集群资源偏向的普通服务进行调度,对于那些资源偏向特殊的服务,也能实现良好的负载均衡。
改进后的节点k权值计算公式如式(2)所示,b1、b2、b3代表创建服务时指定的对应资源的偏向性,在创建服务时由用户指定,会直接和权重相乘。其他参数同式(1)。
W(k)=b1k1αN(c)+b2k2βN(m)+b3k3γN(n)+k4N(u)
(2)
设计系统整体模块如图1,图中阴影部分为需要增加或修改部分。其中:集群资源获取模块,为自行设计实现;指令相关模块在原本的基础上修改添加部分功能;而Filter模块和Scheduler模块则在源代码的基础上进行修改。
指令相关模块,通过接口函数调用相关服务,实现对系统的调用和控制;Swarmkit接口模块,属于指令模块的一部分,通过添加指令参数和接口函数,实现新指令对服务的调用的通道;集群资源获取模块,结合原节点管理模块,通过节点资源获取模块和TCP通信,将各个节点信息发送到主节点,实现对集群资源信息的获取;调度相关模块中,Event进行事件监测,触发事件后通过集群资源获取模块获取集群节点资源信息,而后Filter模块进行节点过滤,Schedule模块在过滤后的可用节点上进行服务部署,完成调度。
权值的计算主要包括3部分。首先,通过集群资源获取模块收集集群资源信息;然后,将获取到的资源信息按照发送规则进行解析,同时依据资源利用情况进行权重调整:当资源利用率达到0.8后,对权重进行自动调整,提升权值,从而提升节点的权值,防止单项资源占用过高,而整体权值较低不能反映节点实际负载;另外,根据指令参数bias,主动调整资源权重,针对一些对资源有明显偏向性的服务,可以将服务分配到需求资源最充足的节点上。
Docker在Scheduler模块下用函数声明了节点调整规则和任务部署规则。内容如下:首先判断两个节点在规定时间内的失败次数,如果有节点失败次数达到了规定的失败上限,就优先返回失败次数少的节点,但是如果两个节点失败次数相同,就执行后续的比较;然后比较节点上运行的当前服务的任务数量,优先调度当前运行任务量少的节点,如果两节点任务数量仍然相同,则比较两个节点运行的任务总数,优先调度总任务量少的节点。如果任务总量仍然相同,就返回false调度当前节点,在完成本次调度后,当前节点服务对应任务数量就会超过下一个节点,在下次调度时就会优先使用后续节点。而动态加权调度算法则是将原本以运行任务总量为依据的判断改为以权值大小为判断依据。
相对Docker swarm提供的调度策略而言,优化的动态加权调度算法存在以下优势:
首先,增加了集群节点资源获取的功能,所以在进行节点过滤时,可以根据实际资源利用情况选出满足资源需求的节点,避免了因为节点分配的资源没有完全使用而造成浪费。
其次,因为对调度策略进行了改进,综合考虑各项资源利用情况,在将任务分配到节点时,会根据节点实际资源使用率进行分配,使得最终各个节点的资源使用率相对接近,实现了更好的负载均衡。
最后,通过参数bias对资源占用权重进行动态调整,这样在部署某些对资源需求比较特殊的服务时,也能够通过改变资源权重,将服务分配到对应资源丰富的节点上,实现节点各项资源使用的相对平衡,充分使用了集群的资源。
3 实验与结果
3.1 测试平台搭建
本次测试在一台物理机创建两个ubuntu虚拟机作为子节点,将本机作为管理节点,这样一共3台计算机,构成了一个简单的集群。各节点信息如表1。
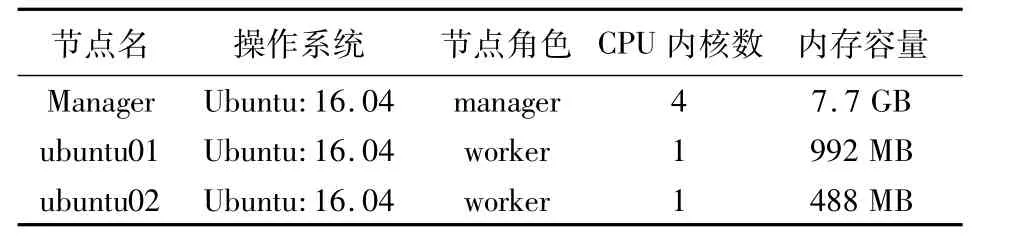
表1 集群节点信息Tab.1 Information of nodes in cluster
3.2 服务调度测试
分别对Docker的原本调度策略、无参数调整的加权调度策略和动态加权调度策略3种调度方式进行测试,统计各个节点的CPU资源和内存使用情况,来分析各调度策略的优劣。
在调度开始之前,查看当前节点的资源利用状况,如表2。其中节点Manager的权值明显高于其余两个节点,是因为这个节点是本机,运行着虚拟机和其他的各种软件,所以资源占用一开始就高,不过这样反而更能测试调度策略的资源调度能力。
测试分为A、B两组进行,在A、B两组各部署30个服务:其中A组部署了20个CPU偏向的应用服务,10个内存偏向的应用服务,这个集群对CPU的资源需求更高;而B组部署10个CPU偏向的应用服务,20个内存偏向的应用服务,该集群对内存资源的需求更高。
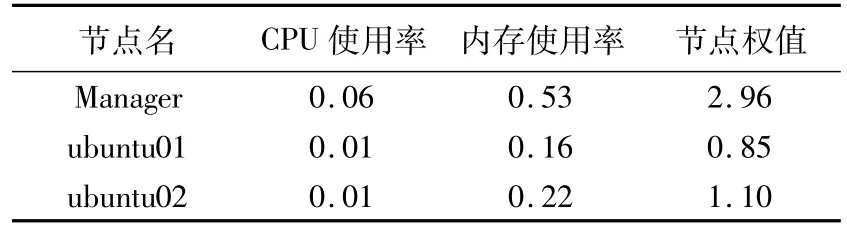
表2 节点初始资源信息Tab.2 Information of nodes initial resources
因为集群的调度结果和应用服务部署顺序有关,所以在A、B两组内分别按照不同顺序对服务进行两次部署,避免部署顺序导致的偶然性,这样一共进行4组对比实验。具体测试应用服务部署如表3。
3.3 调度结果分析
3.3.1 A 组测试结果分析
3种调度策略的A-1组和A-2组测试数据如表4,5所示。可以发现,不论是在A-1组的测试还是A-2组测试,动态加权调度策略的CPU使用率和内存使用率都更加均衡,优于Docker的调度策略和普通加权调度策略。
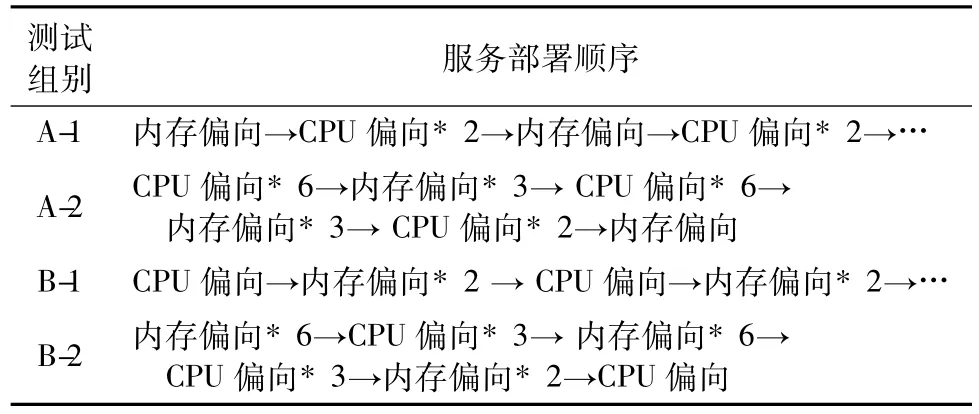
表3 应用服务测试部署顺序Tab.3 Order of deployment
3.3.2 B 组测试结果分析
3种调度策略的B-1组和B-2组测试数据如表6,7所示。可以看出,动态加权调度策略的调度结果资源使用率最均衡。Docker原调度和普通加权调度策略都出现了节点内存资源占用超过0.8,然而优化的调度策略内存使用率都保持在0.6~0.7,避免了节点负载过重,优化了资源利用。

表4 A-1组测试结果Tab.4 Test results of group A-1

表5 A-2组测试结果Tab.5 Test results of group A-2

表6 B-1组测试结果Tab.6 Test results of group B-1

表7 B-2组测试结果Tab.7 Test results of group B-2
3.3.3 服务运行速度的影响
从上述测试可以看出,优化的调度策略实现了更优秀的资源负载均衡,然而为了证明新的调度策略不会对服务的运行速度产生负面影响,进行服务运行速度测试。
编写两个循环计算程序作为两个子服务,一个控制程序作为主服务。两个计算程序在完成计算后,将计算时间发送到主服务,只有在两个计算都完成之后,才算完成了完整的服务。通过这样的测试程序来测试调度策略对服务整体运行速度的影响。
当集群资源充足时,难以看出服务执行速度的差异。因此,在进行服务速度测试前,先按照各调度策略在集群上部署10个内存偏向的服务和30个CPU偏向的服务,提高集群的CPU使用率,然后再进行测试服务的部署。
对40个服务的不同部署导致的节点资源利用状况,分别对3种调度策略进行测试,结果如表8。
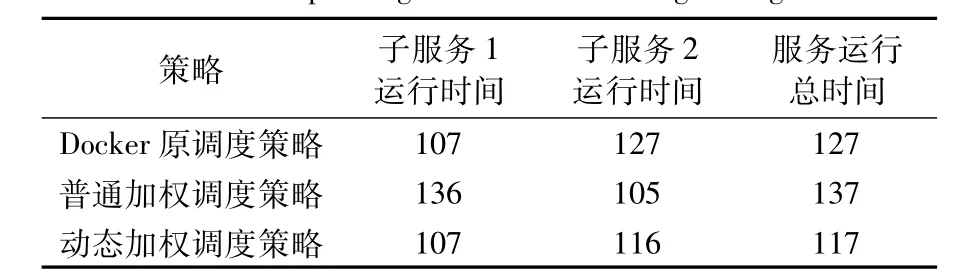
表8 各调度策略的服务运行时间测试表 s Tab.8 Operating time of 3 scheduling strategies s
当存在多个子服务时,服务的运行速度取决于最慢的那个子服务。从表8中数据得知,动态加权调度策略的服务执行速度最快,而无参数调整的动态加权调度策略服务执行却最慢。这主要是因为节点ubuntu01的内存使用率较低,在考虑节点整体权值的情况下,该节点被分配了更多的CPU偏向的服务,最终导致同样对CPU资源需求量高的子服务1运行变慢,拖慢了整体服务;而动态加权调度策略,各个节点资源利用率相对平均,因此子服务执行时间相差不大,服务总运行时间最短;而Docker原调度策略以平均分配容器的方式进行调度,由于节点ubuntu01和节点ubuntu02的CPU资源总量相同,因此最终这两个节点的资源占用反而比较相近,使得两个子服务运行速度没有太大差异,最终服务运行速度居中。
3.3.4 测试结论
A组和B组的测试结果与调度策略相吻合。Docker原本依据各节点容器数量进行调度,因此各个节点容器数量相同,但是因为没有考虑节点资源情况,导致节点间的资源利用率不平衡。
对于无参数调整的加权调度策略,严格按照节点总权值进行调度,忽视了具体任务对资源的实际需求,因此,在B组测试中出现了明显的节点各项资源利用不均衡,其总权值是通过两项资源互相补充实现了相对均衡,而且在B-2组测试中出现了内存资源利用过高导致的CPU资源浪费。对于动态加权调度策略,由于在创建对资源有偏向性的服务时,通过参数bias调整了对应资源的权重,使得系统在节点负载相差不大的情况下,优先将服务部署在所需资源充足的节点上,这样避免节点出现某项资源利用过高而另外资源利用很低的情况,在A组和B组测试中,优化了资源的均衡利用。
同时,通过对具体服务的运行速度进行测试,发现优化的调度策略在集群负载比较高的情况下,实现了最快的服务运行速度。
总体而言,本次的调度策略优化是比较成功的,实现了预期的目标,相比Docker原本的调度和无参数调整的加权调度,无论是对CPU资源需求多的集群,还是内存资源需求资源多的集群,在不同的调度顺序下都实现了更好的负载均衡和资源利用。
4 结语
本文提出了一种优化的动态加权调度算法。该算法在集群调度时,既综合考虑CPU、内存、网络各项资源负载,又实现了节点各项资源的均衡利用,避免了单项资源使用率过高造成的资源浪费,提高了资源使用率。实验结果表明,本文提出的动态加权算法无论在CPU资源需求高的集群服务还是内存需求高的集群服务,优化的调度策略都能实现比Docker原调度策略和普通加权调度策略更优的集群负载均衡和资源利用,并且对正常服务运行时间的影响最小。
