基于改进单类支持向量机的工业控制网络入侵检测方法
2018-07-25刘万军秦济韬曲海成
刘万军,秦济韬,曲海成
(辽宁工程技术大学软件学院,辽宁葫芦岛125105)
(*通信作者电子邮箱lgc_qinjitao@sina.com)
0 引言
目前,大部分关键的基础设施和工业系统,例如石油天然气管道、自来水处理系统、水库阀门控制、电力电网以及核电厂等,都通过监控和数据采集系统(Supervisory Control And Data Acquisition,SCADA)来控制[1]。这些系统允许远程监控,并为地理上分散的设施提供远程访问和控制,这使得这些设施中的运营商能够实时监控和控制整个系统,而这种控制网络对外是完全封闭的。随着工业控制系统和计算机网络的发展,为了方便对工业生产过程进行控制,工控组态网络与IT网络结合起来,工业控制网络(以下简称工控网络)就变成了完全开放或者半开放的网络;但是,工控网络缺乏相应的防护措施和安全机制,因此近些年来对于工业控制设备的攻击越来越多,特别是2010年伊朗震网病毒的爆发[1],暴露出工控网络中存在的重大缺陷,同时,给网络入侵检测带来了新的难题和挑战。
网络入侵检测主要完成以下功能:识别入侵者,识别入侵行为,检测和监视已经成功的安全突破,提供重要的安全信息。在入侵检测方法上工控网络与计算机网络相比没有本质区别,它们都是通过收集和分析网络行为、安全日志、审计数据、其他网络上可以获得的信息以及计算机系统中若干关键点的信息,检查网络或系统中是否存在违反安全策略的行为和被攻击的迹象[2-3]。目前,大部分入侵检测的工作都是基于正常网络数据流量的特性来建立异常检测模型,而单分类方法在计算机网络入侵检测中获得了广泛的关注[4-6],而且取得了比较好的检测效果。
工业网络入侵检测的研究并没有成熟的理论体系,因此,现在与工控网络入侵检测的研究大部分采用传统网络入侵检测的方法。在单分类方法中,单分类支持向量机(One-Class Support Vector Machine,OCSVM)广泛应用于异常检测中[5-6],但是OCSVM应用于异常检测时,无法克服内部异常点和离群点对决策函数产生影响的缺陷:2015年,尚文利等[5]使用粒子群优化(Particle Swarm Optimization,PSO)算法自动寻找OCSVM算法的参数,并建立入侵检测模型,但是该方法没有解决OCSVM易受到孤立点的影响而且无法检测内部异常点的问题;Bartman等[7]介绍了如何将网络入侵检测方法与SCADA(Supervisory Control And Data Acquisition)网络结合,完成工业入侵检测的任务,同时也讨论了工业网络攻击者的攻击方式以及工业网络的脆弱性;万明等[8]研究了Modbus/TCP协议中的功能码特性。利用深度包解析技术(Deep Packet Inspection,DPI)解析协议中的功能码,然后利用模式匹配的方法进行规则匹配,以判断异常或正常,利用规则的入侵检测实时性高,能够检测出部分攻击,但是仅仅利用功能码解析,反而产生了漏报行为;Kim等[9]利用了分层误用检测和异常检测相互结合的入侵检测方法,该算法使用C4.5构建误用检测模型,将正常训练数据分成多个子集,然后使用子集数据创建多个OCSVM模型,该过程虽然避免了内部异常点检测的难题,但孤立点对OCSVM的影响却没有消除;吴丽云等[10]利用偏最小二乘回归(Partial Least Squares Regression,PLSR)提取数据主成分进行特征选择,构造数据集,并考虑到支持向量机(Support Vector Machine,SVM)算法不适用于大样本数据的缺陷,利用SVM在大规模数据上的改进核向量机(Core Vector Machine,CVM)算法,构造网络入侵检测模型。实验结果表明,该方法具有较高的精确率、较低的误报和漏报率以及较高的实时性,避免了孤立点的影响,但是忽略了内部异常点导致的检测精度不高的问题。
为了避免OCSVM对孤立点敏感的缺点以及内部异常点无法检测的问题,本文主要从单分类支持向量机(OCSVM)入手,结合工控网络入侵检测的背景,提出了一种基于具有噪声的密度聚类(Density-Based Spatial Clustering of Applications with Noise,DBSCAN)和K-means聚类与OCSVM算法的组合入侵检测方法(DBSCAN K-means One-Class-Support-Vector-Machine,DKOCSVM)来满足工控网络中异常检测的需求。
1 单分类支持向量机在入侵检测中的应用
单分类支持向量机(OCSVM)算法是SVM在单类分类方面的一种改进[12-13]。它在小样本下存在最好的分类效果和泛化能力;同样利用了核函数的方法解决数据线性不可分的问题,避免了直接计算高维空间映射的难题[14-15]。
OCSVM最大化样本点和原点之间的距离,以此构建超平面[15]。在原点至超平面一侧的数据被划分为一类,超平面外层的被划分为另一类,图1给出了OCSVM二维空间中的一个示例。在图中,OCSVM为单类别数据构建模型,来区分出原点和数据样本。
OCSVM算法通过单类数据集D={x1,x2,…,xn}构建决策函数f(x)=ωTφ(x)-ρ,其中ω为f(x)的法向量,ρ为偏移项,φ(x)是样本在高维空间中的映射。为了将样本点与原点尽可能分离,OCSVM被简化为求解如式(1)的二次规划问题。

其中,εi变量是为了避免函数过拟合,在目标函数中加入的惩罚项,也可以称作松弛变量;n是训练数据集的大小;v则是正则化参数,通常取值范围为[0,1]。显然,式(1)是一个凸二次规划问题。为解决式(1)中模型,利用拉格朗日乘数法,构造出的拉格朗日函数具有如下形式:

αi和 γi均为拉格朗日乘数。令式(2)对 ρ、εi、ω 的偏导数均为0,将这些关系代入式(2)中,最终可以得到式(1)的对偶问题(3)。其中,k(xi,xj)表示核函数,引入该函数是为了解决低维数据线性不可分的问题。
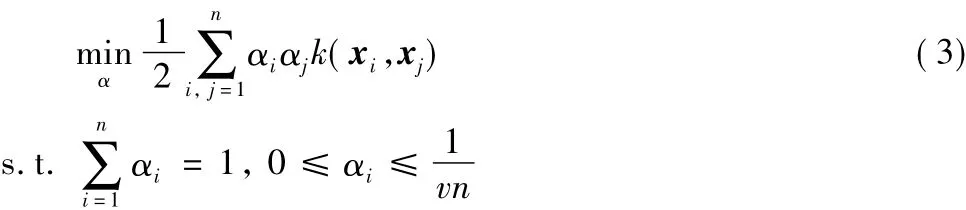
利用OCSVM方法进行新样本的检测时,决策函数通过核函数可以转化为如下形式:

当f(x)≥0时,该样本被认为是正常样本,即位于训练数据集一侧;当f(x)<0时,样本被判定为超平面和原点之间的异常值。

图1 OCSVM在二维空间中的分类原理Fig.1 Classification principle of OCSVM in two-dimensional space
2 K-means聚类
K-means算法对需要进行聚类的数据有一个基本假设:在每一个聚类簇中存在类中心点,使得该类簇中的所有样本点到该中心点的距离最小(https://en.wikipedia.org/wiki/K-means_clustering)。K-means聚类方法本质上解决的是一个最小化聚类误差的优化问题。该聚类误差如式(5)表示:

当满足聚类误差最小时,此时的聚类被认为具有最高的类内样本相似度并具有最优的聚类结果。通过以下的迭代步骤可以寻找满足聚类误差最小条件下的聚类结果:1)生成初始聚类中心;2)计算样本点到这些中心的距离,距离相近的归为一类;3)重复上述过程,直到终止约束。
K-means聚类算法通过最小化类内误差确定类别,因此可以保证类内高聚合性;当数据分布密集时聚类效果很好;但是,K-means聚类算法效果与聚类初始中心相关,而且孤立点和噪声点会干扰聚类的过程,导致聚类不准确。
3 基于密度的聚类(DBSCAN聚类)
DBSCAN是一种基于密度的空间聚类算法(https://en.wikipedia.org/wiki/DBSCAN)。通常,密度聚类算法从样本密度的角度来考虑样本之间的关系,并且基于密度连通性,样本不断扩展聚类簇以获得最终的聚类结果。
对于数据集D={x1,x2,…,xn},DBSCAN的目标是将上述数据集D分成k个类别以及噪声点的集合。该算法有2个重要参数:考察密度时的邻域半径Eps和定义核心点时候的阈值MinPts。DBSCAN算法将所有分成3种点:核心点(在半径Eps大小内含有超过MinPts数目的点)、边界点(在半径Eps内点的数量小于MinPts,但是落在核心点的邻域内)和噪声点(既不是核心点也不是边界点)。
直观上讲,核心点对应着数据稠密区域的点集,边界点是核心点区域边界上的点,而噪声点则为数据中稀疏区域中的点,如图2所示。对于DBSCAN算法,还有以下3个重要的概念:1)Eps邻域。与一个点的距离小于等于Eps距离的所有点的集合。2)直接密度可达。如果一个点在核心点的Eps邻域内,则称该点到核心点是直接密度可达的。3)密度可达。对于多个点p1,p2,…,pn,pi+1是从pi关于Eps和MinPts直接密度可达的,则点pn是p1密度可达的。

图2 噪声点、边界点和核心点示意图Fig.2 Schematic diagram of outlier,boundary and core points
DBSCAN的基本执行步骤为:1)所有点标记为核心点、边界点以及噪声点;2)删除噪声点;3)为距离在Eps之内的所有核心点之间赋予一条边;4)每组连通的核心点形成一个簇;5)每个边界点指派到一个与之关联的核心点簇中。
由于DBSCAN算法是一种基于密度聚类的方法,因此该算法可以根据数据的空间特点选择出聚类中心和聚类个数。虽然不像K-means受限于起始点的选择,但是邻域半径Eps值的确定能够影响DBSCAN聚类的效果。
4 改进的工业控制网络入侵检测方法
在大部分研究中,研究人员将工业控制网络入侵检测作为分类任务处理。得益于机器学习算法在分类任务的优良效果,能够分类出正常和异常的数据。但是由于机器学习需要正负样本共同学习,而工业控制网络中负样本很难获得,因此实际该网络的入侵检测都是基于大量正常样本构建异常入侵检测模型,而OCSVM算法能够完成这种工作。但是在工控网络环境下,利用OCSVM算法构建异常入侵检测模型却存在很多缺陷。
4.1 OCSVM 的缺陷
虽然OCSVM同SVM一样,具有比较好的分类效果和泛化能力,但是OCSVM算法在某些数据上存在一些分类上的缺陷。
1)离群点影响决策函数的生成。
在OCSVM训练过程中,训练数据的一些离群点会对决策面的构建造成影响。以图3为例,在图中,虚线方框中的几个样本点距离绝大部分样本点较远,属于远离样本空间的离群点;当计算决策面时,这几个点作为支持向量(图中虚线圆框标识)来确定决策面;由于这几个支持向量更加靠近原点,导致决策面向原点偏移。显然,决策面如果向样本点集中的方向偏移(如加粗实线所示),更加符合OCSVM分类的目的。

图3 二维空间下离群点对于OCSVM算法的影响Fig.3 Influence of outliers on OCSVM algorithm in two-dimensional space
在文献[15]中提到了两种改进OCSVM的方法:一种是改变惩罚函数,将惩罚函数构造成与样本点与样本分布相关的函数,这样可以促使决策平面向密度集中的方向偏移;第二种是通过某种方法剔除离群样本点,直接排除离群点对决策面构造的影响。
2)内部存在的异常数据无法检测到。
一般来说,异常点大多数处于正常点集合的边界上。但是OCSVM构造的是包含绝大部分正常样本的决策面,如果异常点处于正常数据点的内部,则通过OCSVM是无法判断出的,这些点被叫作内部(局部)异常点。
在图4中由于异常点包含在正常数据集内部,因而直接使用OCSVM算法无法对此类点进行判断。

图4 正常数据集中异常点分布情况示意Fig.4 Distribution of abnormal points in normal data sets
4.2 本文对OCSVM的改进
为了实现在工业控制网络中的异常入侵检测,同时也为了解决上述OCSVM算法存在的问题。本文结合了DBSCAN、K-means和OCSVM方法,旨在提高工业控制网络入侵检测中基于OCSVM检测方法[5]的检测性能。
1)K-means聚类算法是基于原型聚类的算法之一,是最简单也是最常用的聚类算法,而且K-means方法也被广泛使用在入侵检测中[16-17]。利用K-means算法将正常数据集进行聚类,获得多个正常数据类簇。在这些类簇的基础上分别建立OCSVM分类器,可以判断出一些在类簇之间存在的异常数据,进行样本检测时,K-means通过计算聚类中心点与检测样本点的距离来判断属于哪一个类簇,方便进行算法扩展。
2)利用具有噪声的基于密度的聚类方法(DBSCAN算法),剔除离群点,避免离群点对K-means和OCSVM算法的影响;而且该算法可以为K-means获取最好的聚类个数,解决了K-means聚类数目难以确定以及对离群点敏感的问题。但是DBSCAN从整个样本进行模型更新,难以进行扩展,因此组合K-means算法对OCSVM算法进行改进。
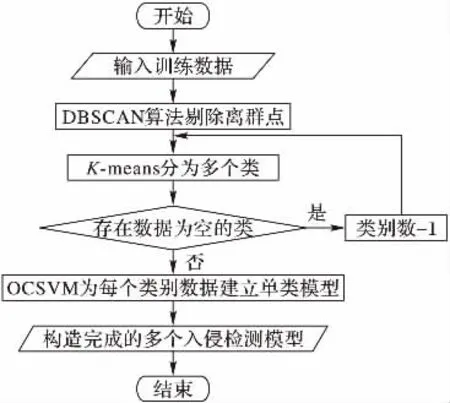
图5 DKOCSVM构建流程Fig.5 Construction process of DKOCSVM
组合算法首先使用DBSCAN算法进行处理,处理后可以获得合适的聚类个数并且消除训练数据集中的离群点,减少了离群点对于OCSVM和K-means的影响,而且为K-means指定了合适的聚类数。然后,K-means算法将正常样本数据划分为多个类簇,利用OCSVM算法为每个类簇建立单类分类器;当利用该模型进行数据检测时,首先判断新数据属于哪个类簇,然后利用该类簇对应的单分类器进行检测,这样可以检测出部分内部异常点。同样,K-means和OCSVM都会受到离群点的影响。
如图6所示,在DKOCSVM的工作过程中,算法首先利用DBSCAN算法进行训练数据集的处理,目的是选取剔除孤立点或离群点的训练数据,并且获得合适的聚类个数K;然后使用K-means聚类为训练数据进行聚类,寻找到训练数据中的K个类簇;利用OCSVM算法为每个类簇建立单分类器。在数据测试中首先判断该样本属于哪个类簇,然后使用该类簇的分类器进行判别。因此,该方法属于聚类方法和分类方法的组合入侵检测方法,满足实用性要求。
实验结果表明,利用DBSCAN和K-means组合的方式进行工业控制网络数据的去离群点和分类,然后构造多个OCSVM入侵检测器的方式,可以提高异常检测中分类的精度。在组合算法中,DBSCAN算法时间复杂度为O(nt),其中n代表着需要聚类样本的个数,而t指代寻找到邻域内所有点的时间消耗,最坏情况下,可以达到O(n2),但是平均情况下,时间复杂度为O(n log n);对于K-mean算法而言,其时间复杂度为O(tnkm),其中t代表算法迭代次数,k代表选择的聚类个数,m代表每个元素的特征数目;而OCSVM算法求解的是一个二次规划问题,其时间复杂度与算法计算出的支持向量的个数相关,也就是说与样本个数存在相关性。

图6 DKOCSVM的入侵检测模型Fig.6 Intrusion detection model of DKOCSVM
5 实验过程
5.1 实验数据集概述
实验所用工业控制网络数据集是密西西比州立大学公开的工业控制网络安全数据集[18]:气体管道数据集(gas pipeline)和储水罐数据集(water)。数据集包括网络流量,过程控制和过程测量数据特征,这些功能来自使用Modbus应用层协议的两个工业控制系统的一组28次攻击。这个数据集可以方便和有效地比较SCADA的入侵检测解决方案(该数据集出自 https://sites.google.com/a/uah.edu/tommy-morrisuah/ics-data-sets)。
本文使用的数据集的组织形式都有两个部分:网络流量特性和有效内容特性;网络流量特性与SCADA网络通信有关,而有效内容特性与具体的工业控制过程有关。在有效内容特性中,包含着系统的测量值、关键系统工作状态参数、系统模式等关键信息。
1)气体管道数据集。气体管道数据集包含了天然气气体传输管道控制过程的关键数据,包含有26个特征。在气体管道数据集中,核心属性是气体管道中的压强。气体管道数据存在三种模式,入侵攻击大多数基于三种正常模式构建。
2)储水罐数据集。储水罐数据集模拟了液体在储水罐中的状态:当液体位于储水罐高低警戒位置之间时,系统正常;当超过最高警戒或低于最低警戒位,系统给出相应警报。该数据集包含23个属性值,核心属性是当前水位测量值、最高警戒水位和最低警戒水位。表1罗列出数据集中每类攻击的数目。

表1 两类数据集中各种攻击数据数目Tab.1 Numbers of various attacks in two data sets
5.2 实验仿真与参数调整
实验环境:Intel Pentium CPU G630 2.70 GHz,2 GB 内存,500 GB硬盘,Windows7操作系统。在仿真中,主要采用Python编程语言,实现SVM和OCSVM算法主要来自机器学习库sklearn中的SVM模块,而两种聚类:DBSCAN和K-means则来自机器学习库中的cluster模块。实验中涉及到的核函数均采用径向基函数(Radical Basis Function,RBF)。
组合方法DKOCSVM中,需要调整的参数为邻域半径Eps、核心点阈值MinPts和学习率nu;在gas pipline数据集中,邻域半径设置为0.2,MinPts为10,学习率为0.1;在water数据集中,邻域半径设置为0.2,MinPts为25,学习率为0.07。
5.3 实验方案设计
数据集验证 为了比较DKOCSVM算法是否能够提高工业控制网络入侵检测的效率,本文使用工控网络数据集gas pipeline和water数据集进行算法的验证。
对比实验 为了进行实验的对比,本文从二分类SVM(CSVM)、K-means和OCSVM分类器组合、基于K-means的入侵检测方法、单分类器OCSVM方法作为对比算法,来讨论DKOCSVM算法在工控入侵检测中的整体效果。另外,本文还引入了基于核函数的单分类方法和基于核主成分分析(Kernel Principal Component Analysis,KPCA)的单分类方法[6]作为对比实验(表2、表3中带*),目的是为了观察这两种计算机网络异常检测方法是否适合本文背景下的入侵检测模型。
评价标准 在测试集评判时,本文通过以下几种指标来进行度量:检测过程花费CPU时间、整体检测率(accuracy)、算法查准率(precision)、算法误报率(False Positive Rate,FPR)、算法漏报率(False Negative Rate,FNR)。其中accuracy为正确检测出的样本个数与样本总数的百分比;precision是检测出的正常样本数占正常样本总数的百分比;而FPR为误报为异常的正常样本数与正常样本总数的比值;FNR与FPR类似,是漏报的异常样本数和异常样本总数的比值。
实验具体方案 1)分别获得gas pipeline和water数据集中的测试集与训练集;2)为测试集和训练集重新构建标签,当数据条目为正常时标记为1,反之则为-1;3)选择训练集中所有正常数据,作为单分类方法的训练数据;4)利用单分类方法为该训练数据构造单分类器,建立单分类模型;5)利用测试集检测单分类器的效果,给出各种评价指标;6)实验探究特征个数对算法的影响。
5.4 实验结果分析
实验结果(表2和表3所示)表明:二分类C-SVM算法(有监督分类)中,由于C-SVM带有数据标签,因而其分类效果要比其他算法总体上要好,但是C-SVM算法要求需要数据均衡的正反样本进行模型学习,实际网络环境中难以办到。C-SVM的结果可以作为衡量其他入侵检测方法的尺度。
传统基于核的单分类法(Simple One Class)和基于KPCA的单分类法(KPCA One Class)在上述两类数据集上的分类效果都不是很好,从误报率和漏报率来看,它们明显是将大部分数据判断为正例;而且二者的整体花费时间要远远高于其他算法的花费时间。结果说明,这两种计算机网络异常入侵检测并不适合工业控制网络异常入侵检测的背景;无法针对工业网络的特点构造分类模型。而这两种算法都是通过计算整个数据空间中每两个样本的距离来描述样本的分布,但是从结果表现看来,并没有太高的泛化能力。
基于K-means方法的入侵检测方法通过对正样本数据空间进行聚类,然后计算负样本到这些类别中心点的距离来调整分类边界,因此该算法的结果依赖于阈值的选择。本文就是通过不断选择阈值来得到K-means入侵方法最优的检测效果;K-means和OCSVM组合方法类似于本文提到的DKOCSVM方法,但是没有考虑到离群点对组合方法的影响。该组合方法,在gas pipeline数据集中的分类效果比原始OCSVM和基于K-means入侵检测方法的总体检测率要更优,在water数据集中检测效果三者大致相同。利用K-means算法可以降低OCSVM训练样本的数量,提高了OCSVM分类器的训练速度,但是随着K-means算法的加入,整体花费的时间比之前要多。

表2 不同算法在数据集gas pipeline上的训练效果Tab.2 Training effect of different algorithms on gas pipline
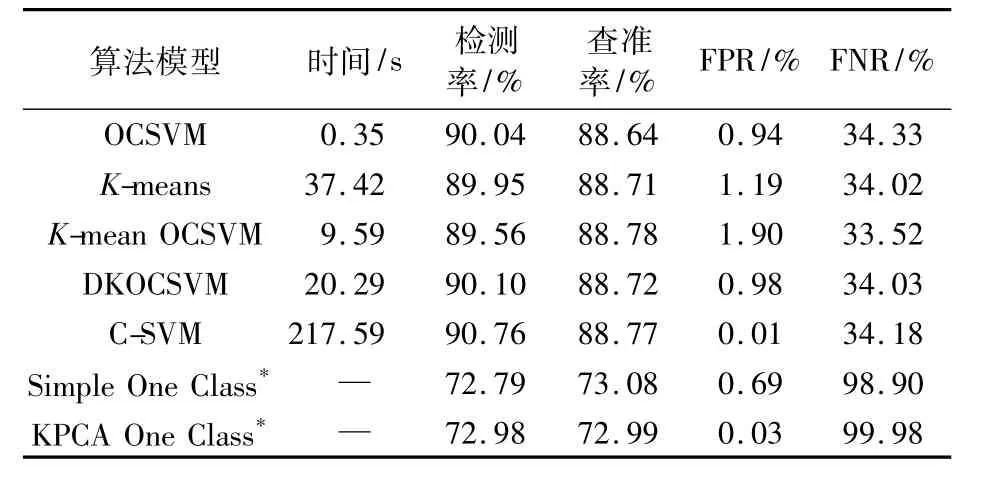
表3 不同算法在数据集water上的训练效果Tab.3 Training effect of different algorithms on water dataset
在DKOCSVM算法的实验效果中,gas数据集的检测效果得到了明显的提升,而water数据集各个指标基本保持不变。由于gas数据中存在明显的工作模式分布,异常点大多分布在这些模式边界或边界与边界之间,利用DKOCSVM算法可以剔除这些点;而water数据集中没有类似的工作模式,因此利用DKOCSVM算法剔除的异常点和孤立点不多,检测效果提升幅度不大。
针对入侵检测算法平衡误报率和漏报率比例的目的,DKOCSVM算法在gas数据集中比其他算法更好地平衡二者的比例,尽管与C-SVM相比牺牲了漏报率;在water数据集中,DKOCSVM的性能没有太大上升,但是也没有下降。总体来看,DKOCSVM算法提升了工业控制网络数据的总体检测率,能够为工业控制网络建立泛化能力好的正常样本模型,从而构建出异常检测模型。
在两种实验数据集中,两种数据集的特征数目较少,便于处理,如果其他类别的工控网络具有大量特征数目,就需要进行特征选择。图7(a)显示了主成分分析(Principal Component Analysis,PCA)个数对DKOCSVM算法的影响;而图7(b)中显示了各种特征选择方法对DKOCSVM方法检测率的改变。
图7(a)展示了主成分分析方法对算法检测率的影响。在gas数据集中,利用主成分分析方法进行降维处理可以提高算法的检测效率,当主成分个数为11~14时,此时算法的检测率(accuracy)可以分别达到 91.54%,91.95%,91.86%和91.81%;对比不使用降维方法的检测率91.81%而言,主成分分析降维可以达到减少特征数目,并不降低算法效率的目的。对于water数据集,特征降维后其总体检测率没有太大变化。
图7(b)是四种特征选择算法对DKOCSVM算法的检测率比较。VarianceThreshold(VATH)可以剔除数据集中特征值全部相同的一列;univariateSelect(UVS)方法利用互信息方法计算每个特征与结果的互信息值,根据值大小进行特征选择;DTrecursiveSelect(DTS)和ExtralTreesModels(ETM)都采用决策树的方式来寻找最优的特征子集组合。从检测结果来看,前两种快速的特征选择方法降低了算法的准确性,而后两种树结构的特征选择方法最终选择了数据集中的全部特征,因此检测率没有改变。从PCA方法和特征选择方法的处理结果来看,采用合适的主成分分析方法和特征选择方法可以提高DKOCSVM的检测效率。

图7 主成分分析和特征选择方法对DKOCSVM的影响Fig.7 Influence of PCA and feature selection on DKOCSVM
gas和water数据集中相同算法产生的不同结果表明:不同工业控制生产过程不同,异常产生的侧重点也有所不同。选择合适的算法需要人工进行测试、比较和筛选,但是应用DKOCSVM算法在两种数据集上都能够产生理想的检测结果。
6 结语
本文基于工控网络入侵检测背景,在传统单分类支持向量机(OCSVM)方法基础上,提出一种基于OCSVM的组合分类器DBSCAN_K-means_OCSVM(DKOCSVM)进行入侵检测。算法首先使用DBSCAN方法处理训练数据集,剔除其中的离群点和孤立点,其次利用K-means聚类方法将用于训练的正常数据集划分为多个类簇,最后利用OCSVM算法为每一个类簇建立一个单分类器;在进行检测时,首先判断检测数据属于哪一个类簇,然后使用该类簇对应的异常检测模型进行判别。在两种工控网络数据集上的实验表明,在gas pipeline数据集上,DKOCSVM算法能够提高总体检测率和查准率,比传统OCSVM算法具有更低的误报率和漏报率;在water数据集上,数据的入侵检测效率有略微提升,但是提升没有gas数据集明显。算法在OCSVM的基础上,利用DBSCAN和K-means方法减少了孤立点和内部异常点对分类器的影响。总体上来说,DKOCSVM对OCSVM进行了改善,提升了OCSVM的检测能力。同时,在数据维度更高的情况下,可以采用主成分分析的方法提升DKOCSVM的检测效果。
