基于HBase和Hive 的航班延误平台的存储方法
2018-07-25吴仁彪屈景怡
吴仁彪,刘 超,屈景怡
(中国民航大学天津市智能信号与图像处理重点实验室,天津300300)
(*通信作者电子邮箱qujingyicauc@163.com)
0 引言
根据中国民航航空局发布的2016年民航行业发展统计公报,2014年,全国民航运输机场起降架次793.3万架次,比上一年增长8.4%;2015年,全国民航运输机场起降架次856.6万架次,比上一年增长8.0%;2016年,全国民航运输机场起降架次923.8万架次,较上一年增长7.9%[1]。航班架次如此高速的增长,对民航信息技术部门来说不仅是数据流的增加、业务的拓宽以及工作量的加重,而且这些新的挑战对民航海量数据的存储以及处理速度提出了新的要求。由此可见,民航界逐步向数据量大、文件类型多、价值密度低与速度时效高的“4V”特性的大数据行业发展[2]。为了应对航班持续稳定高速增长的挑战,亟需探索新的海量航班延误平台的设计方法和机制。目前我国民航使用的是由国家空管局与航空公司合作的航空类企业开发的航班延误平台,主要面向旅客提供机票购买、酒店预订、航班路线查看、行程记录等服务,同时帮助旅客实时查看航班准点信息,获得航班起飞时间与到达时间,国内比较常用的应用有航班管家、航旅纵横、飞常准等APP,国外有PlaneFinder、FlightTrack等。目前这些国内APP大多数是基于传统基础架构的,航班数据一般存储于价格昂贵的大型服务器上,数据库管理软件采用关系型数据库系统,比如Oracle、SQL Server等,而报表系统也正是建立在这些关系型数据库上,业务耦合度紧密,系统扩展性较差、成本较高。
作为高效的数据存储和处理能力的HBase数据库可以轻松满足海量航班数据扩展的要求[3],文献[4-7]将HBase数据库分别应用于城市智能交通系统、船舶自动识别系统、云智能室内环境监测系统、生物DNA与蛋白质对存储等领域,都验证了HBase作为大规模数据存储的可靠性。文献[8]基于协处理器在HBase区域直接创建二级索引,需要将不同索引字段组合一同存进HBase索引表,造成了额外存储空间的浪费。文献[9]基于Solr实现了HBase数据库中数据的检索,然而只是简单地实现了HBase二级索引,并未将索引的建立与查询一体化,仅在Solr管理页面进行了检索,没有考虑实际页面加载大量数据所带来的延迟问题。Hive作为Hadoop生态圈的数据仓库工具,利用存储于Hadoop底端的海量分布式文件进行 MapReduce离线并行计算[10-11],并提供类 SQL语句的开发语言,其优势在于快速实现数据的统计分析,而不必特定编写MapReduce任务。文献[12-13]在Hive基础上构建了一种并行数据仓库,验证了千万条数据复杂查询和多维分析的性能,确保了联机查询和分析的可操作性。
因此,本文在上述技术基础上,设计了基于大数据架构的航班延误平台,其主要特色在于结合了HBase数据库和SolrCloud搜索引擎,利用HBase可扩展性和SolrCloud支持的SQL功能接口的特点,并合理设计行键,从而实现了海量航班数据存储以及基于Web界面的航班实时跟踪,然后给出两种航班数据查询算法,通过实验验证了该查询算法的高效性。最后,设计了基于Hive的航班数据仓库,为航班延误的治理提供了决策层面的技术支持。
1 本文整体架构设计
J2EE是一种利用Java2平台来简化企业解决方案的开发、部署和管理相关复杂问题的体系架构,它使用了多层分布式的应用模型,包括客户层、Web层、业务层、企业信息系统层[14]。本文在J2EE的体系结构基础上,引入大数据计算组件、大数据分布式数据库、大数据可视化等组件,重新设计了海量航班监控平台的系统架构模型。
如图1所示,航班延误大数据平台由航班监控模块、航班查询模块和航班分析模块组成。航班监控模块负责航班的监控显示,定时请求航班数据存储层以获取临时缓冲表的最新航班数据,并依据成功执行回调数据里的航班号这一字段在LeafLet地图添加新的移动图标或为原有移动图标添加新的航路点;航班数据查询模块负责海量历史航班数据的搜索查询,结合Solr搜索引擎,为HBase海量航班数据提供多条件过滤查询的功能;航班数据分析模块负责将HBase表中的每日航班数据抽取、转换、加载进Hive数据仓库,并调用Spark引擎将Hive中的数据转换成图表,以供决策支持。
基于HBase海量航班数据存储、基于SolrCloud海量航班二级索引以及基于Hive海量航班数据仓库的构建是航班延误平台存储的核心组成部分,下面分别对这三部分所涉及的功能模块进行介绍。
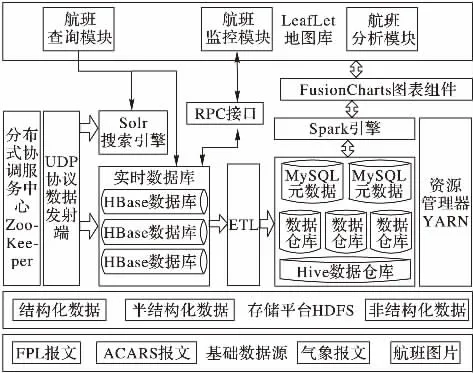
图1 航班延误大数据平台系统架构模型Fig.1 System architecture model of flight delay big data platform
HBase是一种构建在分布式文件系统(Hadoop Distributed File System,HDFS)之上的分布式、面向列的、可伸缩的动态模式数据库,用于实时读写、随机访问超多规模数据集,包括主服务器HMaster、管理和服务区域块HRegionServer,以及作为协调服务中心的ZooKeeper。本文搭建的HBase集群体系框架图2所示。

图2 HBase集群的体系框架Fig.2 Framework of HBase cluster
Solr是一个基于Lucene而实现的开源搜索服务器,除了提供强大的全文搜索外,还包括如图3所示的高亮显示、动态聚类、数据集合、切面检索等功能[15]。SolrCloud实现了基于Solr的分布式检索,作为集群的配置信息中心——ZooKeeper实现了自动容错功能,保证了航班延误大数据平台稳定性。
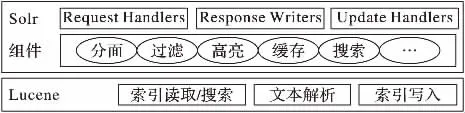
图3 Solr组成模块Fig.3 Solr component module
Hive是一个利用类似传统SQL语句HiveQL实现海量数据的查询、转换、提取等操作的数据仓库,Hive的组成模块如图4所示,它提供了三种用户接口:命令行模式、浏览器模式以及基于Thrift服务器的客户端模式[16]。Hadoop集群支持处理TB或PB级以上数据,以Hadoop MapReduce为框架的Hive因此也能满足有延迟的海量数据交互查询和分析要求。

图4 Hive组成模块Fig.4 Modules of Hive
2 基于HBase海量航班数据存储方案设计
海量航班数据的集中存储目前是各大航空公司亟待解决的问题,逐步由传统的关系型数据库转到可扩展的NoSQL型分布式数据库将是民航业未来数据存储方向。HBase数据库作为一种构建在HDFS之上的分布式、面向列的、可伸缩的动态模式数据库,通常用于实时读写、随机访问超大规模数据集,可以作为海量航班数据存储很好的选择。
2.1 HBase数据库部署与设计
HBase遵从主从服务器架构,它由 HRegion服务器(RegionServer)群和 HBase Master服务器(HMaster)构成。HBase服务器的所有协调服务由ZooKeeper进行协调,除此之外,ZooKeeper还负责Hbase命名空间里的meta表信息的存储,感知RegionServer的健康状态,通过ZooKeeper的Master Election机制保证HMaster单个机制,避免HMaster的单节点故障[17]。
HBase自带ZooKeeper,本文在HBase集群所在三台机器上独立部署ZooKeeper,避免HBase和ZooKeeper的强耦合,方便后期对HBase集群的升级、管理以及对航班延误大数据平台的扩展,因此本文禁用HBase自带的ZooKeeper。同时,考虑到ZooKeeper作为SolrCloud的集中式配置中心,而它的作用是分布式协调者,一旦组件信息、索引信息等配置变动,所有的机器都可以通过它感知到,同时ZooKeeper可以为突然崩溃的程序提供自动容错的机会,通过重新选出候选者,从而执行上次未完成的任务。独立部署的ZooKeeper也可以为HBase二级索引提供支持,实现自动负载均衡。
2.2 海量航班数据rowkey的设计
由于航班数据的索引不直接采用Coprocessor协处理器方案,而是引入了HBase与Solr结合的方案,所以HBase中行键无需依据索引字段来设计,行键的设计需要尽量避免“热点”问题[18]。“热点”问题是由于将递增的航班飞行时间当作行键,向HBase写入操作总是集中在一个数据管理基本单元区域块region上。解决的思路是随机散列化飞行时间,并提前为航班数据表建立预分区,随机散列化飞行时间采用信息摘要算法(Message-Digest Algorithm,MD5)[19]。飞行时间time由不含分隔符的飞行日期与实际飞行时间两部分组成,时间格式不够的填充位用零补足。由于航班查询模块会根据每个飞机图标的航班号直接索引,所以行键末位还需要拼接上航班号,最后需要将飞行时间转换为哈希值再转换化Bytes类型,加上自身和航班号转为Bytes类型的值,即可组成最终行键。最后生成rowkey的函数如(1)所示:
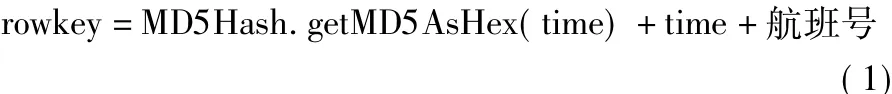
2.3 海量航班数据列簇的设计
航班数据主要字段包括:航空公司、航班号、尾流号、起飞机场、降落机场、起飞日期、预计起飞时间、实际起飞时间、预计降落时间、实际降落时间、延误时长等109个字段。起飞时间与降落时间采用4位时间占位符进行存储,精确到分钟级别。飞行日期采用8位占位符,其他字段统一解析成字符串类型存储。因为列簇越少时region刷新 I/O开销越少,且航班数据各字段应用较统一,所以所有字段共同构成航班数据唯一列簇FProperties。海量航班数据列簇设计如表1所示。
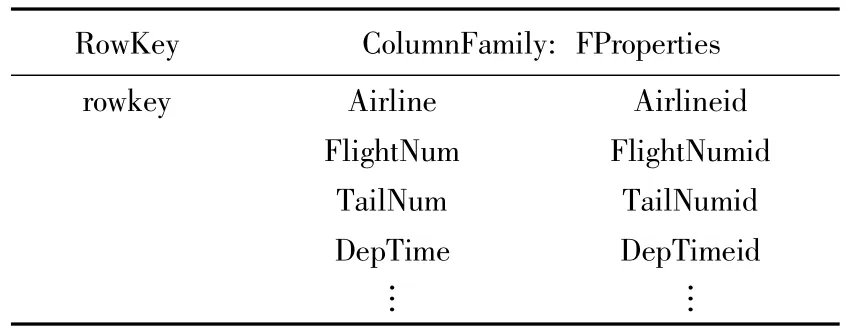
表1 海量航班数据表结构Tab.1 Structure of massive flight data table
2.4 海量航班数据索引字段的存储
为了实现多条件查询的业务需求,本文设计了基于Solr+HBase的存储组合方案。HBase作为航班数据主表的存储机制,Solr作为主表rowkey以及涉及条件过滤字段的存储机制。过滤查询6个字段包括:飞行日期、航空公司号、尾流号、航班号、起飞机场、降落机场。Solr模式配置中7个参数类型都是字符串:indexed属性必须全部设置为true,最终返回值为符合条件的rowkey字段,固只需要将rowkey的stored属性设置为true,其他无关过滤字段设置为false,以便节省存储空间,uniqueKey对应的字段为rowkey,条件过滤字段设置信息如表2所示。

表2 条件过滤字段信息表Tab.2 Information table of conditional filter fields
实现基于Solr索引数据存储的基本思路是在往HBase主表插入航班数据之前,调用HBase的Server端的协处理器Obervers,Observers是散布在 RegionServer端的 hook钩子,这些hook函数是实现二级索引条件存储的基础,RegionServer会调用 Observers的钩子函数 prePut,读取 Put类包含的rowkey以及查询字段,将rowkey设置为模式配置中的唯一键,同其他字段一同封装在Document中并保存到缓存里,达到上限之后则将缓存内所有的数据提交到SolrCloud中,从而在SolrCloud中为所有的涉及条件过滤的字段建立索引。钩子函数完成索引数据提交之后,Region Server才会真正去执行插入操作,将航班号、起飞机场、降落机场、尾流号、起飞时间等信息插入HBase主表中。
实际情况下,飞机在空中飞行时持续报告它的飞行信息,接收端必须一直处于接收状态,比如实际情况下飞机上的广播式自动相关监视(Automatic Dependent Surveillance-Broadcast,ADS-B)发射机与地面的ADS-B接收机之间的航班信息传输。类似发射机采用UDP(User Datagram Protocol)的客户端来代替,类似接收机以部署的服务器端来代替,客户端是一个由C++编写的可执行程序,启动后创建客户端数据报套接字并开启线程,间隔将每行数据拼接成字符串并放进缓存,利用抓取到的应用程序数据直接抛到网络中,从而向应用层提供无连接的服务。
3 基于SolrCloud的海量航班数据关联查询
在建立上述海量航班飞行数据存储及二级索引的基础上,本文利用存储于SolrCloud中的索引文件及返回的行键对航班飞行数据进行多级关联查询。多条件查询请求参数标记为 Q(QD,QA,QT,QF,QO,QD),其中:QD 表示飞行日期,QA表示航空公司号,QT表示尾流号,QF表示航班号,QO表示起飞机场,QD表示降落机场。根据航班查询模块所选的参数,找出符合查询条件(QD,QA,QT,QF,QO,QD)的所有飞行数据,并在Web界面分页显示。除了采用基于SolrCloud索引策略,还给出基于Filter过滤器的查询策略,并针对每种查询策略提出一种查询算法。
算法1 基于Filter过滤器的多条件索引查询。
输入 封装 QD,QA,QT,QF,QO,QD 查询条件的conditionModel。
输出 航班数据结果集列表flightsList。
先判断每个查询条件是否为空,然后将非空查询条件封装在它所对应的SingleColumnValueFilter过滤器中,并依次将新生成的过滤器放在集合列表中。如果集合列表不为空,根据集合列表生成过滤器集合,并设置过滤组合条件为“与”,得到符合QD&QA&QT&QF&QO&QD查询要求的组合过滤器集合,根据过滤器集合设置扫描对象scan,最后通过scan扫描HBase原表,得到集合列表flightsList返回给客户端。
该算法在查询条件较少且返回的数据量不大的情况下效果比较好,但是在过滤条件较少时往往导致返回数据量很大,比如只限制QD与再增加一个QA查询条件时查询范围也许会增加一个数量级。其次该算法使用了全表扫描,这是一种代价昂贵的查询办法,直接导致查询性能低下,HBase查询代价最小的办法就是通过行键查询,因此本文设计了基于SolrCloud二级索引查询方法,将行键的索引提前存储于SolrCloud中,获取行键后再在主表中依据行键查询。
算法2 基于SolrCloud的多条件二级索引查询。
HBase二级索引目前业界采用的解决方案主要有MapReduce方案、ITHBase方案、IHBase方案、华为的HIndex方案[20],检索性能正稳步提升。本文在华为协处理器创建二级索引表的基础上,将HBase协处理器所持有的类似触发器应用于SolrCloud索引字段的创建上,把HBase毫秒级实时搜索的优势与Solr多条件组合查询的优势结合起来,实现了基于SolrCloud的HBase海量数据多条件快速检索。具体查询步骤如算法2所示:
输入 封装 QD,QA,QT,QF,QO,QD 查询条件的conditionModel。
输出 航班数据结果集列表flightsList。
实际查询过程如图5所示:1)建立完索引;2)客户端直接发送包含(QD,QA,QT,QF,QO,QD)查询请求 SQL命令,Solr Client通过内部处理逻辑接收并解析SQL语句后依据分片数目启动分布式查询,查询结果返回给最初的Replica,Replica基于一定的规则合并子查询结果;3)Replica将最终结果返回给用户,这些符合查询条件的结果是以集合形式返回,而这些结果正是HBase中符合过滤条件数据的行键,这样用户就可以快速获得符合过滤条件的rowkey值,拿到这些rowkey之后放进缓存列表中;4)根据这些行键在HBase中执行批量查询,依据行键找到对应的region位置,获取region所对应的列的值;5)HBase最终返回符合过滤条件的所有结果。
采用Solr作为HBase的二级索引替代方案,除了因为Solr拥有独立、高并发的企业级搜索优势外,还因为它是采用纯Java并基于文本搜索引擎库Lucene而开发的子项目,与目前大数据HBase、Hive、Hadoop等组件能很好地兼容,并能支持多种输出格式,包括可扩展标记语言(Extensible Markup Language,XML)、JavaScript对象标记语言(JavaScript Object Notation,JSON)、扩展样式表转换语言(Extensible Stylesheet Language Transformation,XSLT),支持的分页索引功能弥补了HBase数据库分页索引的不足,也方便了后期对航班延误大数据平台的功能扩展[21]。
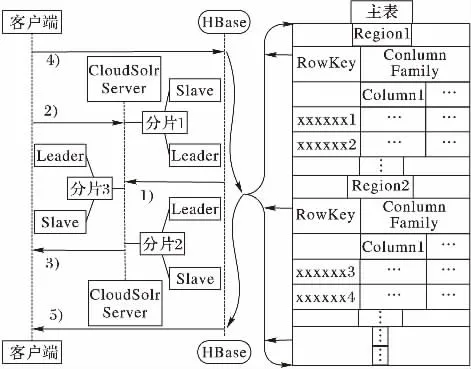
图5 基于Solr的二级索引执行流程Fig.5 Secondary index execution flow chart based on Solr
4 基于Hive海量航班数据仓库的构建
在实现了基于HBase、SolrCloud的航班存储与航班查询框架后,航班查询和航班跟踪两个在线事务模块基本完成。通过利用HBase数据库历史航班数据,构建基于Hive海量航班飞行信息数据仓库来寻找与航班延误最具有相关性的指标参数,统计分析出各大机场日均延误、时均延误等与航班延误相关的统计分析情况,作为航班延误大数据平台航班数据报表层。
4.1 基于Hive海量航班数据仓库多维分析
对于航班飞行信息数据来说,典型的主题域包括航班、机场等主题。其中航班主题记录了与单个航班延误相关的历史飞行数据,如计划起飞时间、计划降落时间、实际起飞时间、实际降落时间等;而机场主题记录了机场全部的历史航班数据,包括航班号、尾流号等。本文利用HBase提供的航班飞行数据,在已提前制定的飞行计划静态状态量中加入每日航班飞行监控状态属性,依据机场和飞机的每日、每月、每季度、每年航班延误等新规则,将这些规则作为数据维,定时将HBase存储的前一阶段航班数据映射到Hive中,结合这些航班数据维,生成符合业务主题的航班延误决策信息,并将决策信息存入Hive事实表中,从而实现航班数据的入库操作。
基于Hive的航班数据仓库系统旨在高效地存储和分析持续不断产生的海量航班飞行数据,以高度整合的形式集成与展现历史航班延误数据,能够为航空公司运营者、机场管理者、空域调度者和旅客提供每月与每季度的延误原因占比、各大机场与航空公司每季度与每年延误排名情况、机场某月每日平均延误分钟数、各大机场当日时间区间的延误航班数量与某飞机的历史延误统计。
4.2 基于Hive的海量航班数据仓库系统结构设计
针对航班延误海量数据和数据仓库统一管理与分析的应用需求,本文设计了基于Hive的海量航班数据仓库,系统结构主要由4层组成:负责底部数据存储的存储层、负责执行SQL语句的计算层、负责查询处理的控制层和负责具体业务需求的应用层。存储层是基于HDFS,数据来源包含HBase存储的每日飞行数据和提前制定好的飞行计划报文;计算层由Hadoop底层MapReduce与Spark底层基于弹性分布数据集的有向无环图组成,选择的方式由实际业务的需求与繁琐程度决定;控制层包括HiveQL和SparkSQL两种查询语言组成的数据库引擎,处理来自应用层的不同请求,引擎的选择决定了计算层的选择方式;应用层主要集成了各大机场延误报表、航班延误辅助决策等组件,可以实现每日报表的生成。
4.3 基于Hive海量航班数据仓库工作流程
航班分析模块为用户提供了良好的Web界面,利用JSP标签库来提供执行OLAP(Online Analytical Processing)操作的相关按钮以及数据显示,主要标签包括地区、机场、飞行日期、飞行时间段等。为了实现对时间维度的上卷、下钻等操作,需要创建表的时候将默认静态分区属性设置为动态分区属性,后台根据用户的选择实现查询分析处理并将结果保存至MySQL数据库中,即可实现针对机场、航班等不同主题的即席查询,最终以基于FusionCharts的图表形式呈现。
航班数据仓库的数据加载方式有两种:存储处理程序模块StorageHandlers用于映射HBase已有历史航班数据,在Hive中创建与HBase表与列簇相互对应的历史航班数据外部映射表;批量装载Load方式用于飞行计划静态数据。所有与主题相关的航班数据装载进Hive之后,客户端发起航班延误数据分析请求,进而启动一个 Spark应用程序,通过SparkSQL解析请求命令,由于已经完成Spark与Hive的整合配置,SparkSQL可以直接对数据位于HDFS中Hive表执行关系型操作,也可以将涉及延误主题的表直接转换成弹性分布式数据集,进行复杂运算后再保存到延误主题表中。返回符合查询请求命令的数据之后,根据这些数据完成涉及的查询与分析、汇总、报表生成等操作,并将最终延误分析结果返回给客户端。海量航班数据仓库工作过程如图6所示。

图6 海量航班数据仓库工程过程Fig.6 Engineering process of mass flight data warehouse
5 实验及结果分析
本实验主要针对多条件查询速度、航班延误大数据平台的海量航班的可扩展性以及多维展示进行测试。实验环境采用4个节点的集群,外加一个客户端。其中服务器hadoop01与 hadoop03内存26 GB、硬盘 1 TB、2.40 GHz的 Xeon E5620 CPU,hadoop02与 hadoop04 的内存 8 GB、硬盘 500 GB、2.66 GHz的Quad Q8400 CPU,4台应用服务器节点用于分发航班数据以及应用逻辑处理;客户端的配置为内存12 GB、硬盘1 TB、3.4 GHz的i7-6700 CPU,用于模拟海量航班的并发请求。
航班延误大数据平台的主界面如图7所示,地图库采用的是目前最流行的可视化工具之一LeafLet[22],大体分成两部分:侧边航班信息收缩菜单栏和右侧航班实时跟踪界面。收缩菜单栏包括航班信息、航班数据、天气、延误警示、延误分析、联系我们这6个大模块,并且每个模块都有一级右拉悬浮页面,可以轻松地关闭悬浮页面并来回自由切换任何一个菜单。当右侧地图界面任何一架航班被首次点击时,航班信息栏都会主动弹出包含该趟航班的飞行信息,包括:起飞机场、降落机场、航班号、计划起飞时间、计划降落时间等。
图7 航班延误大数据平台可视化界面Fig.7 Visualization interface of flight delay big data platform
5.1 基于HBase海量航班数据多条件查询速度测试
设定查询条件为6个:飞行日期、航空公司号、尾流号、航班号、起飞机场、降落机场。测试数据分3组:A组为44.3万条,B组为91.1万条,C组为139.8万条。通过监控层的航班数据查询模块进行实验验证,参考标准是查询条件输入时刻到页面获得实时响应这段时间间隔,分别比较HBase在算法1和算法2查询条件下页面响应时间。过滤条件设置如下:
条件一 起飞机场为SAN;
条件二 起飞机场为SAN,飞行日期为2015-01-17;
条件三 起飞机场为SAN,飞行日期为2015-01-17,降落机场为SMF;
条件四 起飞机场为SAN,飞行日期为2015-01-17,降落机场为SMF,航班号为2800。
从图8的3张图对比可以发现,无论是在算法2的条件下还是算法1的条件下,当索引字段越多的时候,实时查询效率越高,因为过滤条件越多,返回结果越少,无论是数据库查找还是SolrCloud搜索时间都相应减少了;无论过滤条件有多少,算法2相比算法1的查询速度都有所提高,尤其当过滤条件超过两个时,算法1在三种数据量的情况下页面响应时间保持在7 s、25 s、50 s左右,可以推知随着数据量的增长,这种响应时间也会随之延长,而算法2的集群响应时间维持在毫秒级别,即使在C组百万条数据量下,也可以达到实时刷新页面的效果。
通过图9可以发现,当过滤条件为4个,添加二级索引的集群索引速度在A组数据下提高了53.6倍,在B组数据下索引速度提高了195.3倍,在C组数据下索引速度提高了265.0倍,可见当数据量越大时,查询速度差距越明显,可以推测添加二级索引的集群将表现出更加高效的航班查询性能。
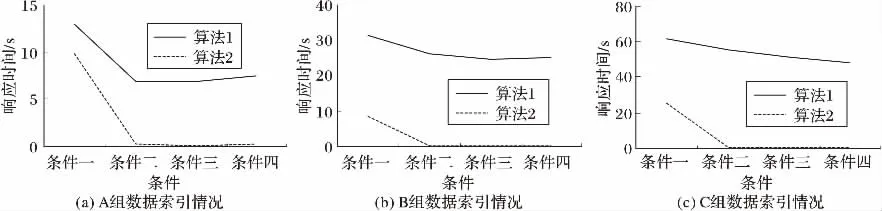
图8 多条件组合下页面响应时间Fig.8 Page response time under different multi-condition combination
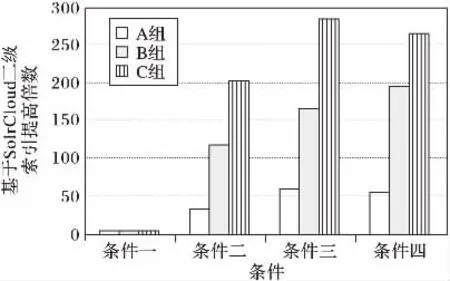
图9 多条件组合下页面响应提高倍数Fig.9 Speedup of page response under different multi-conditional combination
分析其中主要原因是因为SolrCloud能够很好地支持多条件查询,通过索引字段分布式过滤查询,可以直接获取符合过滤条件的行键,从而间接支持HBase的行键索引;而HBase支持行键毫秒级的实时查询,所以查询效率成数量级地提高;而没有添加索引的集群由于过滤条件太多,多次使用过滤器,需要大量的磁盘IO,再加上数据量的剧增,自然速度降低。其中在条件一下,查询速度提高倍数并没有随着数据量的增加而稳步提高,主要是因为返回数据量太大,页面加载延迟造成的。
可以看到HBase高效的查询性能是在建立合适rowkey的基础上,过多使用filter将明显降低查询性能。HBase主要优势体现在海量数据查询上,一旦数据量达到上亿条,它的速度优势将会更加明显。综上分析可以得出,HBase数据库基本符合海量航班跟踪平台的设计需求。
5.2 航班延误大数据平台的可扩展性测试
航班延误大数据平台承受负载最大的部分是HBase数据库,客户端的高速读入以及Web界面持续的post请求都意味着大量的IO消耗,所以航班延误大数据平台的可扩展性、读写速度以及处理能力与HBase数据库直接相关。作为列式存储的数据库,HBase的优点之一是可以自动切分数据,使它在水平方向具有较好的扩展性。实验发现,增加一个HRegionServer的节点仅仅需要在配置文件夹下的regionservers文件中增加一个IP或者主机名就可以。
5.3 基于Hive海量航班延误数据展示测试
在完成航班数据仓库的分析与设计之后,针对航班延误数据多种主题,本文采取多种类型图表来测试分析结果。对于某架航班,关注的是它每趟航程具体延误时长,因此采用二维折线图直接显示延误时长;对于交通管制、恶劣天气、航空公司影响、航班到达晚点、安全因素等延误原因,我们更关注延误原因占比以及最易导致延误因素,因此采用3D动态饼图;对于延误机场,采用2D倒序条形图依照延误率从大到小依次排列;对于每个机场每天平均延误时长,可以采用3D Pareto图立体化显示延误走势。我们以机场每天平均延误时长为例,通过提取 A机场1月份所有延误数据,然后经SparkSQL转换得到的该月每天平均延误时长,最终测试结果如图10所示。
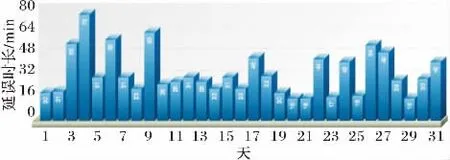
图10 A机场2015年1月份每日平均延误时长测试效果Fig.10 Test result of average delay per day at airport A in January 2015
6 结语
本文设计了面向大数据的航班延误平台,实现了海量航班在LeafLet上的实时监控,将实际飞行情况下航班数据与飞行计划数据作为数据源,依据其特征关联与查询需求,设计了行键与航班索引字段分层存储于SolrCloud的存储技术。此外,针对 HBase的非行键数据检索的问题,提出了基于SolrCloud的查询方案,使用层次索引快速获取要检索的数据,并通过与基于过滤器的查询方案对比,验证了该存储方案的高效性。在此数据基础上,依据航班延误查询所关心的主题,进一步建立了基于Hive的集中统一的航班数据仓库,后期通过与SparkSQL交互查询实验验证了搭建的数据仓库的可行性。以后的工作将会放在预测航班延误上,将预测到的信息嵌入到航班延误大数据平台预留接口中,从而完善航班延误平台。
