面向汉维机器翻译的调序表重构模型
2018-07-25潘一荣杨雅婷米成刚
潘一荣,李 晓 ,杨雅婷,米成刚,董 瑞
(1.中国科学院 新疆理化技术研究所,乌鲁木齐830011; 2.中国科学院大学,北京100049;3.新疆民族语音语言信息处理实验室,乌鲁木齐830011)
(* 通信作者电子邮箱 xiaoli@ms.xjb.ac.cn)
0 引言
在统计机器翻译的研究中,不论是基于词还是基于短语的翻译模型,调序都是其中的重点与难点。由于不同的语种间存在句法结构差异性,需要对目标语言端的词序进行调整,使之更加接近目标语言的表达形式,保证翻译结果的准确性和流畅性。传统的词汇化调序模型[1-2]基于词和短语的对齐结果对调序信息进行建模,并使用统计学方法构建调序模型,对于解决局部调序问题具有较好的效果,但忽略词和短语在特定语境中的调序类别,存在上下文无关性及稀疏性问题[3]。
在汉语到维语的统计机器翻译中,针对调序问题主要有句法形态信息处理[4]、基于句法调序[5]、调序表过滤[6]等方法。前两者利用汉维双语的语言学及形态学知识,在汉语端进行预调序,使之在词序上接近维语的语法结构;同时在维语端进行词干词缀切分等操作,使之以词素形式参与翻译系统的训练过程。后者引入深度学习方法,利用递归自动编码机对汉维调序规则进行特征表示,从中获取调序概率并依据其与初始得分之间的差值,对调序表进行规则过滤。
近几年来,统计学调序模型与神经网络方法相结合成为研究热点:杨南等[7]提出基于神经网络的预调序模型,利用神经网络获取词汇的向量表示,将源单词间的调序问题建模为排序问题,实现源语言端的预调序;Li等[8]利用递归神经网络进行语言建模,基于双语句对的特征向量进行调序概率预测,构建神经调序模型并作为额外特征加入至解码部分。
本文延续深度学习方法在统计机器翻译领域中的研究思路,提出基于语义内容进行调序方向及概率预测的调序表重构模型。该模型首先使用连续分布式表示方法,从大规模未标注的维语文本中学习词汇和短语的特征向量,对调序表中的维语规则进行表示,将具有语义相似性的调序规则映射至向量空间中的相近位置;然后通过循环神经网络(Recurrent Neural Network,RNN)对向量化表示的规则进行调序概率预测,结合反向传播算法优化网络参数,最小化初始调序类别与神经网络中学习到的调序类别的交叉熵,获取更加合理的调序概率分布;最后过滤并重构调序表,赋予调序规则优化后的调序概率,并对原始调序表中的规则进行筛选,保留准确度及匹配度较高的规则,同时降低调序表规模,提高后续解码速率。本文在汉维机器翻译任务中进行了相关实验。实验结果表明,面向汉维机器翻译的调序表重构模型可以明显提高翻译性能。
1 相关工作
对于词汇化调序模型中存在的数据稀疏性等问题,将其作为分类任务进行处理较为普遍。Green等[9]使用判别式扭曲代价模型来预测词汇在译文中的移动距离;Nguyen等[10]引入基于最大熵的层次化调序模型,融入句法信息进行调序方向预测;Hadiwinoto等[11]提出基于依赖关系的调序模型,预测相互依赖的源单词在目标端中是否保持原始相对位置。
深度学习方法需要对数据进行预处理,将其表示为固定维度的特征向量,对于文本分析相关任务,词袋模型(Bag of Words,BOW)[12]较常用,它基于词频信息对文本进行表示,但忽略特定单词的语义内容及单词间的排列顺序,并且存在稀疏性和超维度等问题。随着神经网络向量表示技术的发展,从 Mikolov等提出的词向量表示[13-14]到短语级、语句级[15-16]等大规模文本表示方法,神经网络语言模型的研究日趋成熟。本文引用Le等[17]提出的连续分布式表示方法,将汉维调序表中的维语规则映射为低维稠密的实值特征向量,并在此基础上进行调序方向及概率预测。
2 模型
2.1 词汇化调序模型
在汉维统计机器翻译中,以 MSD(Monotone,Swap,Discontinuous)双向调序模型生成的调序表为例,如图1所示,它由源语言短语、目标语言短语、双向调序概率分布三部分组成,其中最大概率所在类别作为该条规则的调序方向(维吾尔语从右至左书写)。

图1 汉维机器翻译MSD双向调序模型Fig.1 MSD bidirectional reordering model for Chinese-Uyghur machine translation
在基于短语的机器翻译系统中,当给定源语言语句f、目标语言短语序列e={e1,e2,…,en}、短语对齐信息a={a1,a2,…,an}时,其中ai表示目标短语ei对应于源短语fai,词汇化调序模型对于调序方向o={o1,o2,…,on}的概率估计由式(1)所得,oi在不同的调序模型中具有不同的调序类别。
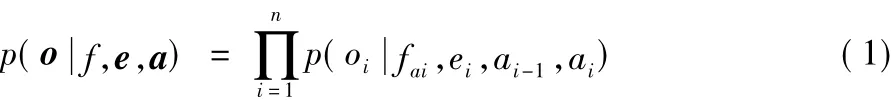
在基于短语的MSD前向调序模型中,包含3个调序方向:单 调 (Monotone, M)、交 换 (Swap, S)、非 连 续(Discontinuous,D)。调序类别由当前目标短语与其前面短语所对应的源短语对齐信息进行判定,具体如式(2)所示:

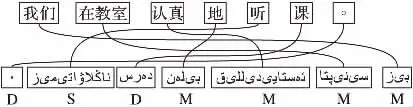
图2 汉维翻译MSD前向调序实例Fig.2 MSD forward reordering example for Chinese-Uyghur translation
词汇化调序模型基于当前短语对中的单词进行调序概率估计,使用统计学方法构建调序概率信息,如式(3)所示,赋予调序表固定的概率分布值,因此对于特定的词汇和短语忽略语义内容以及上下文信息,无法获取高质量的调序模型。
2.2 调序表重构模型
如图3所示,维吾尔语一般为主宾谓结构,汉维短语对[学习,]在不同的语义环境中具有不同的调序方向。
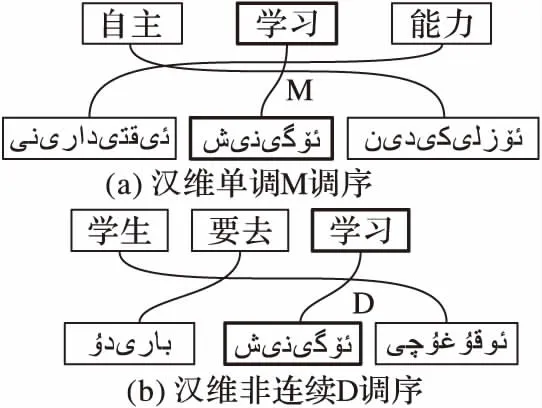
图3 汉维短语对在不同语义环境中的调序方向Fig.3 Reordering orientations of Chinese-Uyghur phrase pairs in different semantic environments
2.2.1 调序方向及概率预测
针对词汇化调序模型的不足,提出了基于语义内容进行调序方向及概率预测的调序表重构模型,如式(4)所示:
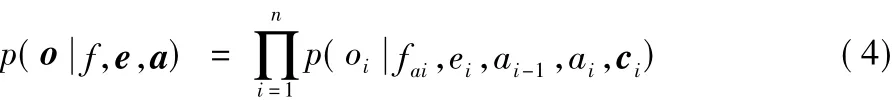
其中:ci表示当前目标短语语义信息的特征向量。本模型引入当前短语的语义内容以及单词的上下文信息,对词汇化调序模型中的调序概率重新进行预测及评估。
2.2.2 调序表过滤及重构策略
对于各个调序规则,本文将调序模型的初始概率分布oi与预测的概率分布pi进行对比:若两者的调序类别c相同,则赋予该条规则预测的调序概率;否则不再考虑当前规则。通过调序表过滤及重构,去除掉词汇化调序模型中概率分布不合理的调序规则以提高调序信息准确度,同时降低调序表规模,加快后续解码速率。

2.3 连续分布式向量表示方法
维语词向量表示和短语向量表示框架如图4所示。通过连续分布式短语向量表示方法,可以将具有相似语义的维语规则映射至向量空间中的相近位置,并使用低维稠密的实值特征向量进行表示,同时认为它们具有相同的调序类别。连续分布式向量表示中蕴含了调序规则的语义内容和上下文信息,在此基础上应用深度学习方法,对于各个规则的调序信息进行分析,赋予调序模型更加合理的调序方向以及概率分布。

图4 维语词向量和短语向量表示框架Fig.4 Vector representation framework of Uyghur word and phrase
2.3.1 词向量表示
连续分布式词向量表示方法通过给定上下文单词序列进行后续词汇的预测。具体来说,单词被存储在词矩阵W的列向量中,并且根据其在词汇表中的位置进行索引;词序列中的词向量按序进行合并构成上下文特征矩阵,以预测后续可能出现的单词。
给定一个长度为T的词序列,词向量表示模型的目标为最大化平均对数概率,如式(6)所示:
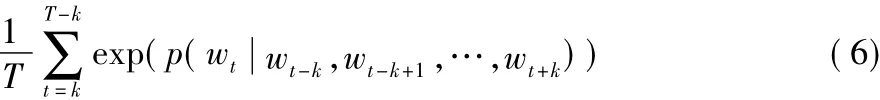
词预测任务由softmax函数进行多类概率值输出,U和b为softmax参数,h为该序列中词向量组合而成的矩阵,具体如式(7)所示:

2.3.2 短语向量表示
延续词向量表示方法思路,引入分布式记忆模型对短语向量表示进行学习。该模型从训练语料中随机抽取固定长度的词序列进行后续词汇预测,并且使用Phrase ID进行索引,将其作为记忆模块以识别该序列中的缺失内容。
在该模型中,词向量表示存储在词矩阵W中,短语向量存储在短语矩阵P中。词序列由定长滑动窗口在训练语料中进行随机采样,将采样得到的词序列的Phrase ID与该序列中的所有词向量按序进行合并,作为特征矩阵以预测后续词汇。词向量具有全局性,相同词汇在不同序列中共享向量表示;只有在相同语句中采样的词序列共享Phrase ID。该模型使用无监督方法进行训练,避免人工标注的繁琐性与不确定性,同时考虑词汇在特定上下文中的语义内容,且保留词序信息。
2.4 循环神经网络预测调序方向及概率
对于预测类任务,如语音识别[18]、文本序列生成[19]等,循环神经网络(RNN)可以获得较好的实验效果,结构如图5所示。RNN可被视为由同一个神经网络经过多次复制而成的深度前馈网络,该网络中所有神经单元共享权重。由于具有深层循环结构,RNN能够维护隐藏层的历史状态并保持信息记忆的持久性,在给定上下文信息的前提下,有效地预测该序列中后续内容的概率分布。
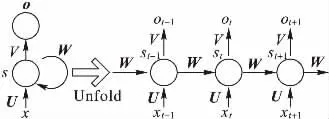
图5 循环神经网络结构Fig.5 Structure diagram of RNN
本工作利用RNN学习序列化数据的高效性,对向量化表示的维语规则进行调序方向及概率预测,流程如图6所示。

图6 循环神经网络预测调序概率分布值流程Fig.6 Flow diagram of RNN for reordering probability distribution prediction
首先将维语规则的特征向量以矩阵形式输入至RNN中;然后在网络输出层添加softmax函数用于输出多类调序概率,最大值所在类别为该规则的调序方向;之后与初始调序类别计算交叉熵,使用随机梯度下降(Stochastic Gradient Descent,SGD)和反向传播算法更新网络参数直至结果收敛;最后输出预测的调序概率分布值,用于调序表重构模型中。
在给定当前短语的语义内容及上下文信息时,调序概率分布值由式(8)所得:

其中:ci为当前短语的连续分布式特征向量,Mo为权重矩阵,bo为偏置向量,Mo和bo为RNN中的网络参数。
3 实验与分析
3.1 实验语料及设置
本文使用2015年全国机器翻译研讨会评测中公开的汉维双语语料数据,结合斯坦福大学开发的分词器[20]对汉语语料进行分词。实验数据分为训练集(11万句对)、开发集(1095句对)、测试集1(1000句对)和测试集2(1000句对)。
本文从新闻网站(http://uy.ts.cn)中抓取78万行维语文本,作为训练数据进行学习。实验建立在机器翻译平台Moses系统[21]上;使用 GIZA++工具[22]进行汉维平行语料的词对齐操作;使用SRILM工具[23]对五元语言模型进行训练;使用大小写不敏感的BLEU值[24]作为翻译结果的评价标准。
3.2 参数设置
1)维语短语向量表示学习。采用skip-gram模型[25]和分层采样方法[26];设置初始学习速率alpha=0.025;设置上下文采样窗口window=5;设置最小词频min-count=3;设置短语向量维度size=128。
2)RNN预测调序概率。设置优化器Optimizer=SGD,初始学习速率lr=0.001,动量参数momentum=0.9,并且每轮更新后lr的衰减值decay=1E-4;设置目标函数为多类交叉熵loss=categorical_crossentropy;设置性能评估函数metrics=categorical_accuracy;采用分批数据进行训练,batch_size=200;设置shuffle=True进行随机数据训练;训练轮数epoch=500,此时可以产生收敛的交叉熵值,输出调序概率分布值。
3)多层感知机(Multilayer Perceptron,MLP)预测调序概率。本文设置两种不同的网络结构以对比实验效果。MLP相当于将多个前馈神经网络串联,该结构由隐藏层及其中的神经元节点构成,在输出层添加softmax激活函数进行多类调序概率值输出,其他网络参数设置与RNN保持一致。
3.3 训练数据采样
对于汉维MSD前向调序模型,考虑当前短语与其前短语所对应的源短语对齐信息;对于后向调序模型,考虑当前短语与其后短语所对应的源短语对齐信息。汉维MSD双向调序实例如图7所示。
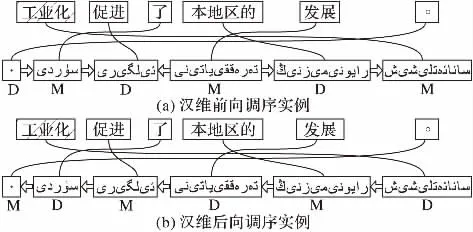
图7 汉维翻译MSD双向调序实例Fig.7 MSD bidirectional reordering examples of Chinese-Uyghur translation
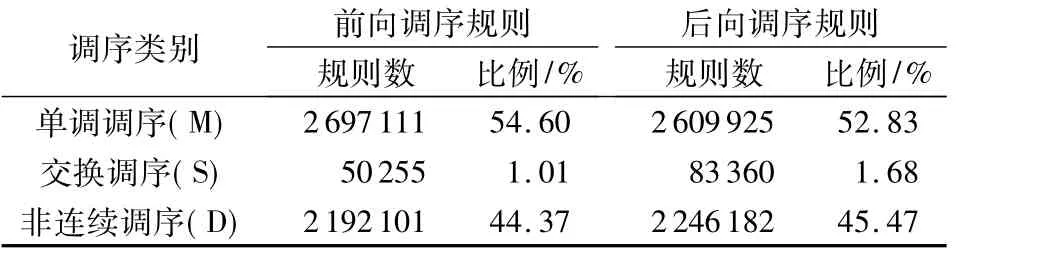
表1 汉维翻译中MSD双向调序规则分布Tab.1 MSD bidirectional reordering rule distribution of Chinese-Uyghur translation
由表中数据可以看出,三类调序规则分布严重不均,若应用深度学习技术,会导致实验结果明显偏重于训练数据规模庞大的调序类别[27]。有实验证明,随机下采样方法可以有效地解决数据失衡问题,例如:利用支持向量机(Support Vector Machine,SVM)方法结合随机下采样[28]实现时间序列分类;利用AdaBoost集成策略结合随机下采样[29]实现蛋白质残留物的预测等。因此,本文保留最小规模类别中的全部调序规则,对其他各类规则进行随机下采样,并且保证以上三类训练样本的均衡分布。
3.4 实验结果
本文设置以下几组对比实验,用于分析不同调序模型对于翻译结果的影响,实验结果如表2所示(规则表示调序规则数目,测试集1和测试集2表示机器翻译在两个测试集上的BLEU值,均值表示两个测试集BLEU值的平均值)。

表2 不同调序模型的实验结果对比Tab.2 Experimental result comparisons of different reordering models
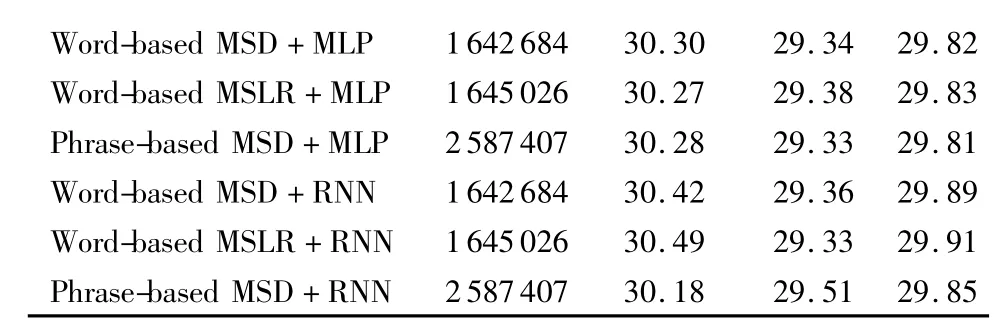
85 Word-based MSD+MLP 1642684 30.30 29.34 29.82 Word-based MSLR+MLP 1645026 30.27 29.38 29.83 Phrase-based MSD+MLP 2587407 30.28 29.33 29.81 Word-based MSD+RNN 1642684 30.42 29.36 29.89 Word-based MSLR+RNN 1645026 30.49 29.33 29.91 Phrase-based MSD+RNN 2587407 30.18 29.51 29.
1)Distance-based。基于移动距离的调序模型,该模型对词和短语的移动幅度进行线性评估,并且不产生调序表,作为本实验的基线系统。
2)Word-based MSD。基于词的MSD双向调序模型,该模型由词对齐结果进行调序方向判别以及调序概率估计。
3)Word-based MSLR。基于词的MSLR双向调序模型,该模型由词对齐结果进行调序方向及调序概率估计,共包含monotone、swap、discontinuous-left、discontinuous-right四个调序类型,相当于将MSD词汇化调序模型中的非连续调序(D)进行细分。
4)Phrase-based MSD。基于短语的MSD双向调序模型,该模型由短语对齐结果进行调序方向判别以及调序概率估计。
5)Word-based MSD+MLP。基于词的MSD双向调序模型,结合MLP重构调序表。
6)Word-based MSLR+MLP。基于词的MSLR双向调序模型,结合MLP重构调序表。
7)Phrase-based MSD+MLP。基于短语的MSD双向调序模型,结合MLP重构调序表。
8)Word-based MSD+RNN。基于词的MSD双向调序模型,结合RNN重构调序表。
9)Word-based MSLR+RNN。基于词的MSLR双向调序模型,结合RNN重构调序表。
10)Phrase-based MSD+RNN。基于短语的MSD双向调序模型,结合RNN重构调序表。
3.5 分析
由以上实验结果对比可以看出,与基于移动距离Distance-based的调序模型(29.49)相比,基于词的MSD调序模型、基于词的MSLR调序模型和基于短语的MSD调序模型可以获得更好的机器翻译效果,其中基于短语的MSD调序模型(29.80)表现最好,说明考虑短语间的调序信息可以明显提高系统对于调序方向类型的预测能力,且以短语对齐结果作为调序方向判别基准,可以显著增强系统对于长距离调序问题的处理性能。不论是基于词还是基于短语的词汇化调序模型,两者都基于短语对齐结果进行解码,故加入短语的语义信息进行调序方向及概率预测,可以有效缓解上下文无关性及数据稀疏性问题,从而赋予调序表更加合理的调序概率值,提高机器翻译质量。
将本文提出的调序表重构模型应用至以上三种词汇化调序模型生成的调序表中,并且设置MLP方法进行对比,用以验证连续分布式表示方法和RNN预测调序方向及概率分布在本工作中的有效性。实验结果表明,结合MLP重构的调序表BLEU值平均提高0.073;结合RNN重构的调序表BLEU值平均提高0.138。RNN效果明显优于MLP。
结合RNN对基于词的MSLR调序模型生成的调序规则进行过滤及重构时,可以显著降低调序表规模,在测试集1上的表现最好(30.49),BLEU值提升0.39,且在本实验中的综合效果最佳;而结合RNN方法重构基于短语的MSD调序模型生成的调序表,在测试集2上的表现最好(29.51),造成此结果的原因可能在于:测试集1和测试集2属于不同领域的测试语料,因此对于不同的翻译模型具有不同的语料匹配程度,从而造成实验结果中测试集1的翻译准确率明显高于测试集2的现象;重构的调序表在该测试集上包含较多相关的调序信息,具有较高的领域匹配度,由此产生明显的BLEU值提升。对于MSLR词汇化调序模型生成的调序表,结合MLP(29.83)和RNN(29.91)进行过滤及重构,可以获得明显的BLEU值提升,可能因为MSLR调序模型中包含了足够多的调序类别,故在调序方向判别及概率预测上具有较好的表现。
在过滤不同调序模型生成的调序规则时,MLP和RNN保留相同规模的规则条目,并且这些规则中的短语对齐信息相同,只是调序概率分布值有差异。本文认为神经网络具有学习调序信息的能力,故两者都可以将某一规则分类至最有可能的调序类别中,但对其赋予不同的调序概率,因而造成翻译性能的差异。根据实验结果可知,RNN具有更好的预测调序方向及调序概率的能力,归因其深度循环结构,可以更高效地分析并评估调序信息,从而显著地提高机器翻译性能。
实验证明,使用MLP和RNN重新预测调序概率分布值,并且在此基础上对原始调序表进行过滤及重构,可以有效地提高汉维调序模型中调序信息的准确度,并降低原始调序表规模,加快后续解码速率。
4 结语
本文提出一种基于语义内容进行调序方向及概率预测的汉维调序表重构模型。该模型首先在大规模未标注的维语文本中学习维语词汇和短语的向量表示,并且在此基础上对调序表中的维语规则进行特征表示预测;然后利用RNN对调序规则的调序方向进行预测,并重新评估调序概率分布值;最后对汉维调序表进行过滤及重构,并将优化后的调序模型加入后续解码进程中。实验结果表明,调序表重构模型可以明显提高汉维机器翻译系统性能。
沿着目前的研究方向,在后续工作中有以下思路。第一,融入维吾尔语的语言学以及形态学知识,对维语进行词干词缀切分、命名实体识别等操作,提高汉维机器翻译中词和短语对齐结果的准确度;第二,学习调序表中双语规则的特征表示,以捕获更多的调序信息和对齐信息。
