基于聚类分析的微博广告发布者识别
2018-07-25赵星宇赵志宏王业沛陈松宇
赵星宇,赵志宏,王业沛,陈松宇
(南京大学软件学院,南京210093)
(*通信作者电子邮箱zhaozhih@nju.edu.cn)
0 引言
微博这一概念最初于2006年由美国Twitter网站的创始人Evan Williams提出[1]。2009年,新浪将这一自媒体表现形式引入国内。经过几年的成长,微博早已走进了人们的日常生活;而伴随着微博的迅猛发展,越来越多的垃圾信息也随之出现,这些信息不仅影响着用户体验,也对微博的相关研究工作造成了极大的负面影响[2]。
针对微博空间中的垃圾信息,传统的发现方法主要依靠微博信息中的显示统计特征:Zhang等[3]利用重复信息检测提出一种局部性敏感散列算法来过滤大量相似的微博;丁兆云等[4]针对微博中关注网络的有向特性,给出了邮箱网络中局部三角形数量统计算法DirTriangleC,结合用户博文数量和局部三角形比例发现隐式垃圾用户;Thomas等[5]针对Twitter中出现的URL(Uniform Resource Locator)进行处理来识别其中的推销内容。利用统计特征进行计算具有一定的局限性:1)数据处理能力低,无法实现大数据量计算;2)计算主要依据经验,检测具有一定的滞后性。
Benevento等[6]将垃圾信息的检测转化为机器学习的分类问题,他们使用用户行为(关注数、粉丝数、tweet条数)和微博内容(广告关键词、URL)等特征,采用支持向量机(Support Vector Machine,SVM)方法发现twitter平台上的广告内容及广告发布者;Wang[7]通过提取用户特征、传播特征等,采用朴素贝叶斯分类算法进行训练,从而筛选出样本中的垃圾信息。国内学者也针对微博空间进行了相应的研究:李赫元等[8]针对垃圾用户提出了基于用户图、用户资料、微博内容的3大类7种检测特征,并最终使用支持向量机得到了较好的实验结果;赵斌等[9]针对微博中的反垃圾处理问题提出了基于重用检测模型的垃圾用户检测算法,利用文本相关性和时间相关性对发帖行为进行建模,而使用分类算法需要对大量的样本数据进行人工标注,训练集大小有限,对此,马彬等[10]提出了通过聚类实现微博话题检测的思想,他们使用基于线索树的双层聚类方法进行实验并取得了较好的效果。因此,本文使用聚类算法进行计算,但由于实验目标对象为微博广告发布者,作为微博用户群体中的非正常用户,采用具有离异点处理能力的基于密度的空间聚类(Density-Based Spatial Clustering of Applications with Noise,DBSCAN)算法更为合适。
对比现有研究,本文提出了以下几点改进方法:
1)提出核心微博序列概念。本文针对更为常见的在广告微博中夹杂大量的普通微博这一现象进行处理,提出核心微博概念,从大量混杂的微博中筛选出用户核心主题和对应的核心微博序列,用于之后的特征提取。
2)基于聚类算法处理多维微博特征。本文使用DBSCAN算法,通过每个样本是否为噪声点来判断其是否为广告用户。由于使用聚类算法,从而避免了大量的人工标注行为,使利用大数据集进行实验成为可能。
3)基于用户粒度进行检测筛选。现有研究多针对单条微博进行判断,而以单条微博为粒度的数据集数据量巨大,处理困难。本文以用户为粒度,以检测用户是否为微博广告发布者为目的,单条微博只会与同一用户的其他微博进行交叉计算,极大减少运算量。
1 微博数据集及特征提取
1.1 新浪微博数据集
本文数据集来源于新浪微博,内容更新至2015年11月12日。此数据集内包含用户数据和微博数据,都为结构化数据,以CSV格式存储。其中,weibo_users.csv文件描述用户信息;lvX_weibo.csv文件描述微博发帖信息。

表1 weibo_users.csv用户信息数据结构Tab.1 Data structure of user information weibo_users.csv

表2 lvX_weibo.csv微博信息数据结构Tab.2 Data structure of weibo information lvX_weibo.csv
1.2 核心微博序列提取
微博广告发布者经常使用各种手段掩盖其广告内容,其表现特征有以下几种:1)在广告微博中夹杂大量的普通微博来稀释其中的广告特征,如表3所示;2)在某一时间段进行广告发布,其余时间段均表现为正常微博用户。普通微博的存在会严重影响各个文本特征计算的准确性。另一方面,微博广告发布者大都围绕一个或几个类别的实体进行宣传。因此,本文引入基于关键词的核心微博序列提取方法。

表3 广告内容夹杂普通内容示例Tab.3 Examples of advertising content mixed with ordinary content
此处核心微博的定义为:与当前用户发帖内容中高频主题相关的微博。由于微博内容长度限制,通常无法从中提取出确定唯一的主题,所以此处采用关键词作为每条微博的主题,每条微博提取一个关键词序列。使用各微博的关键词序列,统计其中关键词出现的词频,并对其中的近义词进行合并处理,得到关键词的词频序列。由于同一微博用户的微博主题可能会出现迁移,本文取关键词词频序列中的前10位作为高频关键词,以保证能够筛选出其中的广告主题。最终,保留包含这10个关键词或其近义词的微博组成核心微博序列。
本文使用自然语言处理与信息检索共享平台(Natural Language Processing& Information Retrieval Sharing Platform,NLPIR)中文分词系统提取关键词,每个用户的每条微博都会获得一个关键词列表。

其中:Useri是表示用户i的微博序列,Wi表示其中第i条微博的关键词列表,keyword为具体某个关键词。统计每个用户关键词的词频,将近义词的词频进行合并后取最大词频的10个关键词,组成用户关键词列表,并使用该列表查询包含这10个关键词的所有微博,最终得到该用户的核心微博序列C:

使用核心微博序列进行微博文本特征计算,可有效降低普通微博对计算结果的影响。由于排除了其中大量的普通内容,使得文本相似特征和时间规律性更为显著。
1.3 用户特征选择
特征选择是聚类问题的关键部分,恰当地使用多维特征才能取得较为明显的聚类效果。在本文中,由于实验对象为用户而不是独立的微博文本,所以在选取特征时,不仅选取了用户所发微博对应的文本特征,也加入了发布者的属性特征。结合用户属性特征,不仅可以更接近用户聚类的目的,更能解决仅针对微博文本词汇计算相似度带来的数据稀疏性问题。
1.3.1 文本特征
1)文本相似度。
由于微博广告发布者具有较为单一的主题(购物、旅游、活动等),发帖人也具有比较固定的语言习惯,导致广告微博相比普通微博具有较强的模板化特征,所以其文本相似度显著高于普通微博。
在本文中,计算每个用户的核心微博之间的余弦相似度并求平均值以作为该用户的文本相似度。
其具体步骤如下:
(1)关键词提取后的核心微博序列C。
(2)使用NLPIR对每条微博进行分词处理,得到分词结果。
(3)计算每两条微博W'i、W'j的余弦相似度。
(a)取分词结果的并集。
(b)计算词频。
(c)写出词频向量 Si、Sj。
(d)计算余弦相似度。
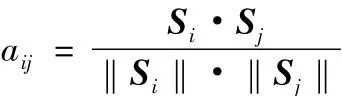
(4)计算相似度平均值

2)时序相似度。
通过对比各个用户发帖时间序列,发现广告发布者的核心微博与普通用户相比具有明显的时序规律性。分析原因有如下几点:a)微博广告发布者为了广告能够获得更好的收益,即获得更高的关注度,通常会研究广告发布的时间曲线,寻找最佳时间点将广告投放出去;b)为了避免给用户造成刷屏的感觉,广告发布者通常会以一定的间隔进行广告投放;c)部分广告实际为机器自动发布,由人工设定内容和时间间隔,因此机器投放的广告微博会呈现极强的时序规律性。
针对上述问题,本文对发帖时间序列进行分析,引入信号学中的白噪声(white noise)检验方法。白噪声序列是没有消息可提取的平稳序列[11]。本文中,白噪声检验结果——统计量whiteNoise值越大表明时间序列随机性越强,即为广告发布者的可能性越低。其计算公式如下:
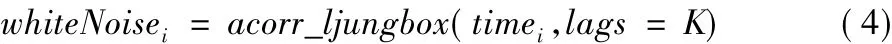
其中:whiteNoisei为第i个用户的白噪声显著性水平,timei表示其发帖时间序列,K为差分阶数。
1.3.2 用户特征
1)广告微博关键词倾向性。
对比广告微博和正常微博,广告微博在词语使用和语言组织上与正常微博相比具有一定的规律性。这是因为以下几点:(1)微博广告发布者为了广告能够获得更好的收益,即获得更高的关注度,通常需要使用具有煽动效果的词语,如爆款、打折等。(2)由于广告自身内容决定某些词语的出现频率会明显高于普通微博,如店铺、购买等。
本文使用已标注的广告发布者数据,统计其关键词词频,并将关键词序列按照词频倒排,从而得到广告微博关键词序列A,但广告微博中也存在许多微博常用语,这些常用语在普通微博中同样高频率存在。为此,本文使用同样的方法针对普通微博统计出普通微博关键词序列P。针对某一词语的广告微博关键词倾向性,本文定义如下:

其中:IndexAi、IndexPi分别为词语在序列A、P中的位置;Ii为该词语的广告微博关键词倾向性。计算所有实验语料中所涉及的关键词,按照关键词倾向性排序,得到的前10位关键词如表4所示。由表中数据可看出前10位关键词都与购物类广告有关,表明Ii作为广告倾向性的衡量标准具有有效性。

表4 关键词广告倾向性排序Tab.4 Advertising tendency ranking of keywords
而针对某一用户的广告关键词倾向性,本文使用上文提到的用户关键词序列W,并将W中每一个关键词的广告微博关键词倾向性相加,得到用户的广告倾向值。
2)广告元素数量。
由于自身宣传需要,微博广告发布者通常需要多平台多渠道宣传,为了能够促进多平台互通,许多广告发布者会在个人介绍中加入多种联系方式,包括网址URL、邮箱、手机号、QQ、微信等。而随着个人隐私意识的不断加强和垃圾信息对人们生活影响的不断加深,普通用户对于私密性较强的微信号、QQ等信息的保护意识也在加强,所以,普通用户一般不会在个人信息中透露其他联系方式。因此,会呈现出广告发布者的个人介绍广告元素远多于普通用户的现象,如图1所示。
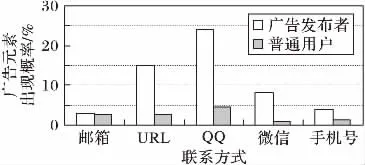
图1 广告元素出现频率对比Fig.1 Frequency contrast of advertising elements
图1中可以看出,广告发布者账号对应的个人介绍中,含有链接(URL)、QQ号、微信号、手机号的比例远高于普通用户。基于此特点,本文统计每个用户个人介绍中推广元素的数量,并以此作为聚类中的一项特征值。
2 聚类算法选择及实验设计
2.1 聚类算法DBSCAN
如上文所述,微博广告发布者在多个特征维度上与普通用户相比具有较为明显的差异;而考虑广告发布者的内部差异,不同的广告发布者,其发帖习惯也有较大区别,这会导致其行为模型的多样化。在这种情况下,为筛选出样本中的微博广告发布者,将其独立为一个或多个簇显然是不合适的,于是本文着眼于聚类问题中的离异点查找,即将聚类方法中的离异点标注为广告发布者。基于这样的要求,本文选取DBSCAN作为本实验所使用的聚类方法。DBSCAN算法为基于密度的聚类算法,与传统的基于层次的聚类算法不同,该算法可以发现任意形状的聚类簇,且可以在需要时输入过滤噪声的参数[12]。
2.2 实验设计
实验设计如图2所示。
1)数据清洗:针对用户,将发帖数小于10的用户不纳入计算范围;针对单条微博,将微博中带有转发含义的字段及“@”符号后的内容进行删除。
2)数据标注:对用户进行手动标注以便于评判实验的准确度,标注分为微博广告发布者和普通微博发布者两类。微博广告发布者的行为特征为:发布内容带有强烈的商业色彩或转发大量低质信息等。
3)参数选择:由于DBSCAN中当Eps过大或MinPts过小时,聚类结果将趋近于一个簇,所以本文定义Eps的范围是0.1 ~1.5,MinPts的范围是3 ~ 50。
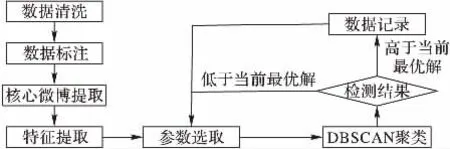
图2 实验流程Fig.2 Process of experiment
3 实验与结果分析
3.1 实验数据及评价标准
目前在微博过滤领域,尚无国际公认的标准测试语料库。本实验使用2755名微博用户的310万条微博数据,提取其中微博文本、用户信息和传播关系信息,并手动标注了2755名微博用户属性,共计2099名普通用户及656名微博广告发布者,所有的用户标注仅用来评判实验的准确度,并未在实验中使用。所有实验都以此作为实验语料,在相同的实验环境下进行。
本文采用准确率(precision)、召回率(recall)、F值(F-measure)来评价算法性能[13]。计算公式如下:

其中:A为正确识别广告发布者的数量,CA为实验结果中被标记为广告发布者的总量,TA为数据集中实际广告发布者的总量。
3.2 特征值权重与聚类参数选取
实验中主要涉及聚类参数有:DBSCAN算法中的半径(Eps)和以点P为中心的邻域内最少点的数量(MinPts)。此外,由于不同特征值对结果的影响程度不同,需要对各个特征值赋予权重。本实验对特征值权重与聚类参数的不同组合进行分析,使用同一组数据,测试在不同特征值权重与聚类参数的组合下的准确率、召回率和F值。测试结果如表4所示,其中P1、P2、P3、P4分别代表文本相似度、时序相似度、广告微博关键词倾向性、广告元素数量的权重,且P1+P2+P3+P4=1;P表示准确率,R表示召回率,F表示F值。
通过大量实验发现,当DBSCAN中的半径(Eps)为0.1,以点P为中心的邻域内最少点的数量(MinPts)分别为4或20时,准确率有较为良好的表现。这是因为当Eps过大或MinPts过小时,表示将一个样本识别为离异点的条件趋于宽松,造成漏识别离异点,导致召回率降低;而MinPts过大会导致大量具有独立特性的普通样本被标记为离异点,导致准确率降低。当Eps和MinPts分别为0.1和20时,结果显示,当P1、P2、P3、P4 分别取 0.3、0.2、0.4、0.1 时,F 值达到峰值0.95,表明文本相似度和广告微博关键词倾向性比对于结果的影响要优于时序相似度和广告元素数量。但当分别删去时序相似度和广告元素数量进行实验(即P2=0或P4=0),结果显示召回率急剧下降,说明这两个特征对于识别广告发布者具有重要作用。

表5 特征值权重与聚类参数对实验结果的影响Tab.5 Influence of eigenvalue weight and clustering parameters on experimental results
3.3 对比实验
本文提出了核心微博序列的概念,提取出微博序列中占较大比重的微博主题,从而去除由普通微博与广告微博混杂带来的影响。在此,本文分别使用原微博序列与核心微博序列进行实验对比,使用相同区间的特征值权重与聚类参数进行组合分析。实验结果显示,当特征值权重与聚类参数分别为表6所示的数值时,F值达到峰值。

表6 使用核心序列和原序列准确率对比Tab.6 Comparison of accuracy between core sequences and original sequences
从表6可以看出,使用了核心微博序列的实验结果,其准确率、召回率和F值均明显高于使用原微博序列的实验结果。即可证明,使用核心微博序列可以有效地排除用户微博序列中的噪声干扰,提高聚类的准确率。
4 结语
本文分析了中文广告型微博的文本特征以及用户特征,提出了一种广告型微博发布者识别方法,算法效率较高,效果理想。与现有的微博文本过滤算法相比,创新地提出了核心微博序列的概念和聚类算法进行实验,有效解决了分类算法带来的数据标注困难问题。而对比垃圾微博的过滤方法,本文着重关注其中的广告微博,通过核心微博序列及多维特征提取,较为精确地过滤出微博用户中的微博广告发布者。这对于今后的研究,包括微博广告发布者行为建模,情感分析等具有重要意义。
同时,由于微博空间信息量巨大,传播速度快[14],越来越多的数据必然会使算法效率降低,如何提升算法效率和针对微博数据流进行聚类将成为接下来的工作重点。
