一种中文人名识别的训练架构
2018-07-25王嘉文王传栋杨雁莹
王嘉文,王传栋,杨雁莹
(1.南京邮电大学 计算机学院,江苏 南京 210023;2.南京森林警察学院,江苏 南京 210023)
0 引 言
当前大数据环境下,海量化数据的结构日趋呈现多样化和异构化。然而在许多问题中,数据事实因应用需求的不同,其数据结构的组织形式存在多方差异。为了满足不同数据挖掘任务对数据事实的统一理解,需要建立一种数据的统一内部表示。
在自然语言处理(natural language processing,NLP)[1]任务中,许多高度工程化的NLP系统应用,大都采取基于特定任务特征的线性统计模型,这些模型由应用背景激发、受领域知识的限制,通过面向工程的专用特征发现数据表示。这些特征通常由一些特征提取的辅助工具预处理而得到,是一种监督学习的训练方法。但是这种方法不仅会导致复杂的运行时依赖关系,而且要求研发人员必须拥有大量的语言学知识。
为了减少这种依赖,必须捕捉关于自然语言的更多的一般性,分析语言的元信息,如词性、实体、语法、句法等,以期获取一种更一般的描述方法,减少甚至忽略先验领域知识对模型的影响,用无监督学习的方式,尽量避免工程化特征,在大规模未标记数据上学习产生模型。
文中描述了一种基于深度神经网络的字词训练模型,通过发现其内部表示,尽量避免了工程特征对于模型的限制,采取一种无监督学习方式对中文人名识别进行了研究,最后通过实验验证该模型的合理性。
1 研究现状
20世纪90年代初,国外就已经开始了对命名实体识别的研究。最早采用的大多是基于规则的方法,专家和学者在某些特定领域对于相关文本进行总结和归纳,提取一种易于理解和表达的规则进行命名实体识别,如GATE项目中的ANNIE系统和曾经参加过MUC评测的FACILE系统等,并在小规模文本上取得了较好的效果。但是这种方法需要极富经验的领域专家进行人工干预,会耗费大量的人工成本,在面对大数据量的命名实体识别任务时效率较为低下。
随着机器学习理论的发展以及计算机性能的提升,基于统计的方法开始不再受限于计算量不足而导致的识别率低的问题,逐渐被广大的专家和学者所接受和青睐。自1997年开始,国外的专家依次将隐马尔可夫[2]、支持向量机[3]、条件随机场[4]等模型应用到英文命名实体识别任务中,都取得了较好的效果。
因为中文的特殊性,中文命名实体识别拥有比英文更高的难度,国内专家和学者在借鉴国外研究成果的基础上进行了长期的研究。张华平等引入隐马尔可夫模型[5],根据人工制定的角色编码使用Viterbi算法在分词结果上标注人名构成角色,根据标注的角色序列进行最长模式串匹配,对中文人名识别进行了研究,在开放性测试集中的F1值达到95%左右。张素香等使用专家知识对各类特征进行定义,利用条件随机场建立了相应的语言模型[6],在人民日报语料上进行实验,也获得了超过95%的F1值。这些方法都可以看作是从句中提取一组依靠纯语言学经验的人工设计的特征,再经过不断地修正将其馈送到经典的浅分类算法中。特征选择因应用背景的不同,对每种NLP应用都需要进行额外的研究,任务较为复杂时(比如SRL语义角色标注[7])就需要进行大量关于特征的人工提取。由于受研究人员语言学知识的限制,这些模型随着语料规模的扩大,工作效率会出现显著下降。
命名实体识别应用为了规避这种限制,目前的研究多采用词的向量化[8]对自然语言进行数字化表示,以期刻画词的更一般性。1986年Hinton提出了Distributed Representation[9],将语料中每个词用一个N维向量表示,N个维度代表词的N个不同特征,有效地避免One-hot所造成的维度灾难、数据稀疏等问题,并且能用向量的距离来计算词与词之间意思的远近,刻画了词与词之间所隐藏的关联性,避免了两个词之间的孤立。但是要从大量未标记文本中无监督地提取词向量,还必须借助语言模型。2003年,Bengio等在n元模型的基础上,提出神经概率语言模型-NNLM[10],用一种三层前馈神经网络建模词的上下文关系。后人将词向量和神经网络引入到命名实体识别工作中,极大地减少了维度灾难对模型性能的影响。2007年,为了提高效率,降低算法时间复杂度,Mnih等又提出Log双线性语言模型-LBL[11]。2010年Mikolov等使用循环神经网络模型[12],通过迭代多个隐藏层保存更丰富的上下文信息,提高了命名实体识别的潜力。
2011年Collobert等提出一种灵活的层叠式神经网络架构[13],将训练好的词向量应用于各种NLP任务,避开过多的面向特定任务的特征工程,在降低计算资源的同时保持了优秀的性能。Mikolov在2013年提出CBOW和Skip-gram两个模型[14],以过渡的投影层代替隐藏层,减少了矩阵运算的次数,提高了训练速度,而且用上下文各词的词向量的平均值来刻画目标词,排除了词序对训练的影响。近年来,卷积神经网络(CNM)[15]、Glove模型[16]、时间递归神经网络(LSTM)等模型相继被应用到命名实体识别中,在提高识别效果的同时也不断降低识别过程对语言学知识的依赖,使用无监督学习进行命名实体识别已经成为国外命名实体识别技术研究的新方向。但是由于中文的复杂性,中文命名实体识别在无监督学习方向上的研究目前仍然存在不足。
2 网络架构
文中提出一种基于深度神经网络的中文人名训练架构,如图1所示,图中使用的训练语料和测试数据集均进行了分词预处理。训练可概述为4个模块:
(1)基本词面的向量化训练。仅基于训练语料统计词频,以词频为依据利用连续词袋CBOW模型迭代训练得到基本词面向量。
(2)特征提取及其特征项向量表示。获取包含每个人名特征项的目标词上下文的基本词面向量,构建共现矩阵,提取特征向量作为特征项向量。
(3)中文人名识别的模型参数训练。以目标词的基本词面向量与各特征向量的拼接作为输入,构建前向全连接的深度神经网络,使用梯度下降法迭代更新训练参数,并用Viterbi算法返回最佳路径,最终获得稳定的模型参数。
(4)使用测试语料进行模型测试。测试模块使用训练好的稳定参数构建中文人名识别模型,根据Viterbi算法返回的最优路径,设定阈值提取标签结果并进行分析。
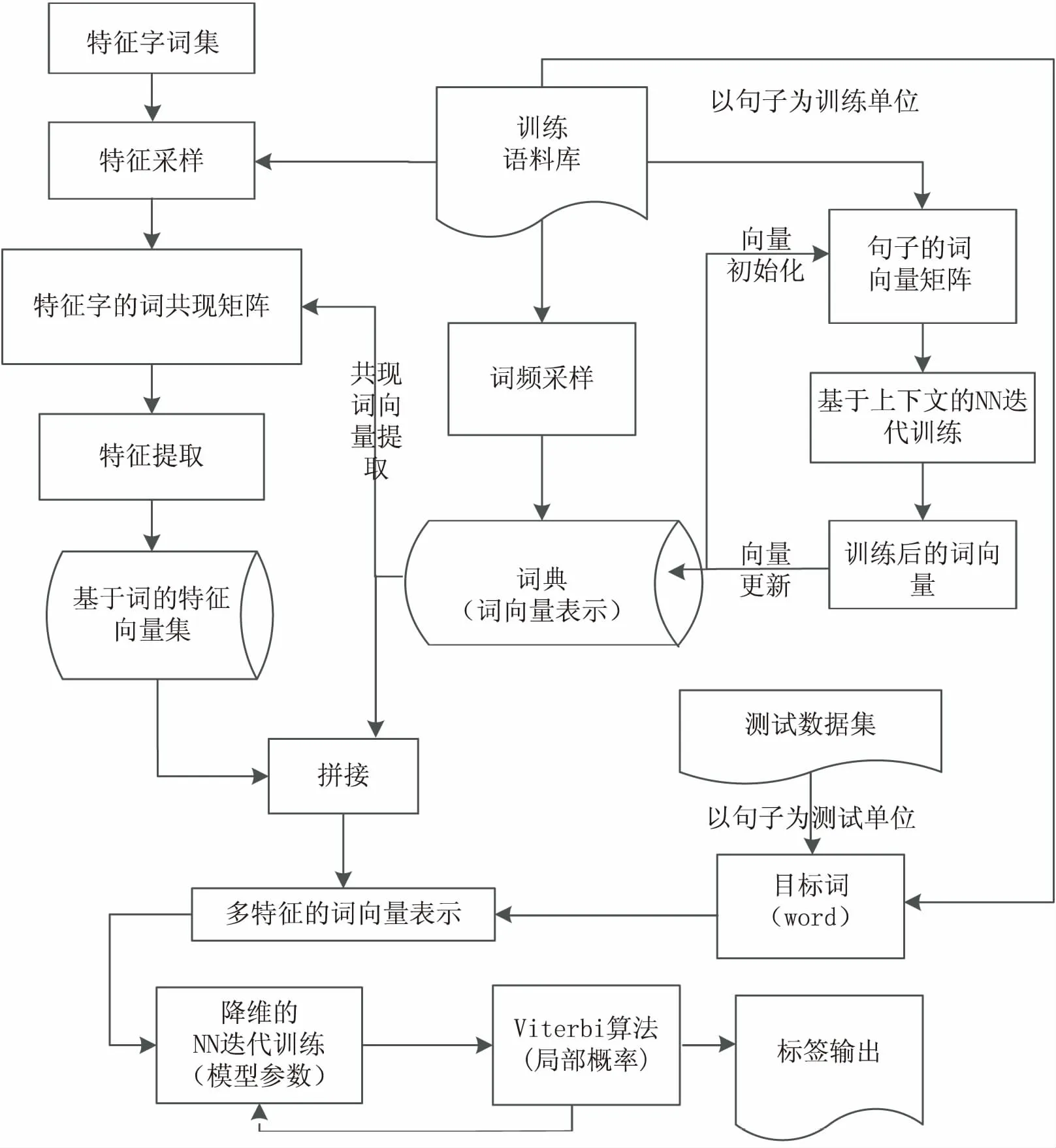
图1 中文人名识别的训练框架
2.1 基本词面的向量化训练
训练以句子为单位迭代进行,训练的前期工作是遍历语料统计词频信息,以词频对所有词降序排序,并建立词典的hash索引以应对训练中的频繁查询。
对目标词w来说,Context(w)表示其由m个词组成的上下文,训练中去除上下文中的词序信息,使用上下文中各个词向量的均值作为输入,具体表示为:
(1)
模型为了提高训练速度,摈弃传统隐含层以减少矩阵运算,直接从神经网络结构转化为与Logistic回归一致的Log线性结构,用二分类的思想以式2所示的目标函数为优化目标:
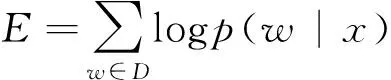
(2)
输出层是对于特征函数值进行一个二分类的处理以得出其发生的条件概率。在实际训练中,将任意一个目标词作为叶子节点,取其词频作为权值来构造Huffman树。从根节点到该目标词的叶子节点路径上的每个分支节点,都是一个影响目标词最终语义的隐式二分类器。训练中构造与每一个分支节点对应的权值向量,组成权值矩阵作为训练参数,这个参数矩阵在迭代训练中得到更新。为此,在模型构造中引入Sigmoid函数:
(3)
对于某一个目标词w,其Huffman树路径中的每一个分支节点,通过权值向量θ计算其与上下文环境向量x语义距离xTθ,依据Sigmoid函数,可将分支节点对目标节点的概率贡献归结为正类概率p(L=1|x,θ)=g(xTθ)或负类概率p(L=0|x,θ)=1-g(xTθ)。其中L可视为最终的标签输出,取值为1表示正类,取值为0表示为负类,二式可统一写为:
p(L|x,θ)=g(xTθ)L·[1-g(xTθ)]1-L
(4)
由此,可得到目标词w受上下文的语义影响产生的隐含条件概率为:
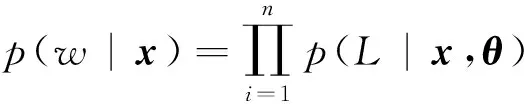
(5)
其中,n为目标词Huffman编码的长度,也就是从根节点到目标词节点路径中的父节点个数,由式2、4与5可推出目标函数:

g(xTθ)])}
(6)
接下来使用随机梯度下降法对E更新,函数E关于参数θ的梯度计算为:∂E/∂θ=[L-g(xTθ)]x,由此得到参数θ的更新公式为:θ←θ+η[L-g(xTθ)]x。同理得到参数x的更新公式为:x←x+η[L-g(xTθ)]θ。训练目标是使得目标词受上下文环境影响的编码概率最大,向量x与θ的更新仅用于训练迭代计算,因为x是目标词w的上下文向量的累加的均值,因此目标词的向量v(w)的更新是一次迭代训练完成后,将梯度的累加更新到向量的每一个分量中,如式7所示:
(7)
其中,η表示学习率。训练中η随着模型处理而动态调整,直到达到阈值ηmin为止,目的在于缓解梯度更新中的波动,使更新过程更加平稳。根据上述的迭代算法依次对所有的目标词和它们的词频进行训练,通过神经网络的反复迭代,网络对于输入的响应达到预定的目标范围后,w(v)就是训练好的最后的词向量。
2.2 特征提取及其特征项向量表示
在中文人名识别领域,特征的提取主要考虑人名的姓氏特征、称谓修饰特征与特殊人名特征,通过构建特征知识库,以特征的每一个特征项为单位,从训练语料中匹配其窗口上下文,从前一个模块的训练结果中提取拥有该特征项的目标词向量,构建特征项的共现矩阵R。对于特征项共现矩阵R,求其协方差矩阵CR=1/n*RRT。
利用公式CRμ=λμ求得协方差矩阵的所有特征值与所有特征向量μ,对所有非0的特征值所对应的特征向量取均值,即为所求的特征项向量。
2.3 中文人名识别的模型参数训练
训练以句子为单位,使用统一的模型架构,分三种方案组织输入向量St(t∈(1,n))训练三组模型参数,以评估人名识别的特征提取对于标签结果的影响。方案一,仅以词频训练的基本词面向量作为输入。方案二,在基本词面向量的基础上,融入姓氏特征和称谓修饰特征等人名的基本特征,携带更多的上下文信息。方案三,在方案二的基础上再引入特殊人名知识库,结合特殊人名特征进行强化学习,以期得到更佳的模型参数。特别需要指出的是,在训练中使用UNKNOWN关键词作为未识词和未识特征项的初始向量。将这个目标词组合向量作为训练模型输入,在后续的神经网络层中进行运算。
图2是中文人名识别的模型参数训练架构。
图2 中文人名识别的模型参数训练架构
对于输入目标词向量St,在架构的一个或多个神经网络的隐藏层中做如下的映射变换进行降维操作,如图中的步骤①所示:
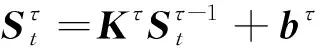
(8)
其中,K和b分别表示权值矩阵和偏置向量;τ表示堆叠的隐藏层的层数。
将这多个隐藏层进行堆叠,对输入向量St进行降维,将其转化成一个向量z以获取非线性特征。这里要添加一个硬性的双曲正切函数h(z)作为激活函数,用以保证模型的非线性,最终得到隐藏层向量y,如图中的步骤②所示。

(9)
激活函数的优点在于能够在不增加过多的计算量的同时保证泛化性能基本不变。
类似输入层到隐藏层的处理,对于隐藏层向量y,同样对它在后续的一个或多个神经网络的隐藏层中做映射变换,从而进行降维,最终获得输出层向量o,如图中的步骤③所示。这里的权值矩阵和偏置向量为K'和b'。
根据逻辑回归的二分类可以得到条件概率p(L|St,φ)。
p(L|St,φ)=[g(St·φ)]L·[1-g(St·φ)]1-L
(10)
以输出向量o为观察序列,用随机梯度下降法对所有的参数φ进行梯度更新,在更新的同时用一个反向指针保存更新的路径:
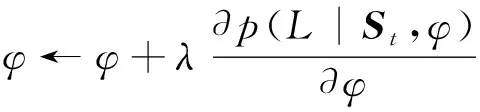
(11)
其中,φ是参数更新过程中所有参数组成的集合;L是二分类的标签。与前面一样,引入一个学习率λ来减少梯度更新中的波动。
Viterbi算法是解决分类标签标注问题的理想选择。使用式11每进行一次更新,都能通过反向指针,对Viterbi算法的初始概率矩阵和状态转移概率矩阵进行更新,参数更新终止条件是Viterbi算法中最终局部概率达到最大,即人名识别的条件概率达到局部最优。达到局部最优时的参数集就是模型最佳时的稳定参数集φ*,φ*={K,b,K',b',π,A},通过φ确定最佳的中文人名识别模型,根据输入向量St的三种不同组织方案最终获得三种最佳模型。
2.4 使用测试语料进行模型测试
确定最佳的中文人名识别模型后,引入测试数据集,以句子为单位进行人名识别测试。首先将测试句进行分词等预处理操作,随后获取句子中每个词的基本词面向量,根据2.3节提到的三种方案训练得到的三种最佳模型分别获得句子中每个词的输出向量。
对于每一种方案,将所有词的输出向量序列作为Viterbi算法的观察序列进行输入,根据φ*中最优模型的初始概率矩阵和状态转移概率矩阵,得到一条最优路径,最优路径上的每个概率值都是对应目标词是人名的最优概率,随后人工设置一个阈值对其进行判断。对每个词来说,是人名的概率大于这个阈值即判断其为人名,否则判断其不是人名。
最后根据每种方案的不同结果对三种模型的效果分别进行一个评价。
3 实验与分析
3.1 实验语料
使用的训练语料是来自2008年的搜狐新闻总计超过1.2 GB的中文文本,总计文本的句子数目共计26 964条,使用20 223条进行训练,6 741条用于测试,采用中科院ICTCLAS分词系统进行分词操作,分词后统计获得的词面数共有89 464个。
3.2 评价标准
对于实验结果,采用识别率P、召回率R和它们的调和平均值F1值作为评价标准。识别率表示正确识别出的人名占总计识别出的人名的百分比,衡量模型排除非相关信息干扰的能力;召回率表示正确识别出的人名占语料中所有人名的百分比,衡量模型获得相关信息的能力;F1值作为识别率和召回率的调和平均值,是对模型性能的综合考量。
记正确识别出的人名的个数为α,总计识别出的人名的个数为β,语料中所有人名的个数为γ,则具体公式如下:
(12)
(13)
(14)
3.3 实验结果
根据2.3节中提到的三种方案训练得到的三种最佳模型进行人名识别,共获得三个实验结果。使用文献[9]的隐马尔可夫模型和文献[10]的条件随机场,在文中所使用的训练语料中进行实验所得到的结果作为对照,进行对比分析。具体实验结果如表1所示。

表1 各模型的人名识别结果 %
通过表1不难得出,方案1在只考虑词频特征时,识别率、召回率、F1值都十分低下,甚至劣于隐马尔可夫模型和条件随机场的识别效果。但方案2在添加了人名的基本特征后,识别效果得到很大的提升,优于传统的识别方法。而方案3在引入了人工离散特征之后,识别效果获得了进一步的提升,其F1值甚至能达到89.07%。说明文中提出的模型在中文人名识别中,能够在尽量避免工程化特征影响的同时保持较好的识别效果,并能够在添加少量人工特征时获得更好的性能,在高度工程化的实际应用中也非常有效。
4 结束语
以词向量为媒介,设计深度神经网络架构,将复杂的命名实体识别工作转移到多层的前向全连接的神经网络中实现,尽可能避免工程化特征的影响,有效提高了识别效率。但随着计算机技术的发展,递归神经网络等更先进的技术也开始逐渐应用到命名实体识别任务之中,笔者在对这些先进技术的调研中发现这些新技术在命名实体识别领域的应用尚处在开始阶段,效果并不能达到预期的要求。下一步的工作中,将对递归神经网络做进一步的研究,用其对现在的前向全连接网络进行改造,以期望获得更好的识别效果。
