一种基于HIVE和分布式集群的大量数据高效处理方法研究
2018-07-24侯晓芳
侯晓芳,王 欢,李 瑛
(北华航天工业学院 计算机与遥感信息技术学院,河北 廊坊 065000)
0 引 言
随着移动设备和互联网业务的快速发展,每天都会有TB级甚至更多的数据量产生。这些数据具有数据量大、增长快速、非结构化等特点,可能隐藏着大量的潜在信息。互联网工作人员可以通过对这些海量数据进行分析处理,从中挖掘出一些有价值的信息,这些信息可以在企业业务拓展、市场营销、产品推荐和企业管理等方面为企业提供一定的决策支持[1],也可以作为对某一行业未来发展趋势判断的依据,大数据产生的价值不可估量。要产生上述方面的意义就离不开海量数据的收集、数据的存储及处理、数据挖掘等技术,面对这些井喷的数据,如何高效的收集、存储、处理并分析这些数据就成为摆在我们面前亟待解决的问题。
随着“互联网+”时代的到来,移动业务快速增长,它提供给我们的不仅是传统通信业务,更多的将是智慧生活和商业服务[2-3]。电信运营商拥有着大量的数据,正是提供这些服务的支撑。面对海量数据的挖掘和处理,传统的关系型数据库和大型高性能计算机显而易见已不能满足现阶段服务的需求,存在着技术上和性能上的瓶颈。这些都给电信运营商提出了巨大的挑战,急需新技术存储、管理和挖掘海量数据。
为了解决这些问题,已经有很多研究者对其进行了研究。文献[4]在MapReduce对海量数据计算范式的基础上,提出了一种基于频繁子图挖掘算法的MapReduce迭代框架。文献[5]基于Hive的任务转化模式,利用Hadoop架构的分布式文件系统和MapReduce并行编程模型,实现海量日志的有效存储与查询。文献[6]根据ERF数据的特点结合分布式框架Hadoop的计算优势,改进了网络数据的解析模式和数据存储模式,完成ERF网络数据自动上传。文献[7]基于Hive的性能优化研究,解决分布式存储系统中文件系统的数据压缩和存储格式问题,通过对MapReduce作业调度和Hive性能调优两个方面对Hive的性能进行了优化。
大数据技术应用主要体现在电信数据分析处理中,即如何全面地解决数据收集、存储、分析和处理等众多问题。本文将从分布式集群部署、日志数据收集、HDFS数据存储、数据清洗、数据业务处理和等方面提出解决关键技术的方法。
1 需求分析
连接到网络中的所有设备,如智能手机、手持电脑、笔记本等通过互联网访问网络资源时,其访问的信息会通过相应电信运营商的基站转发出去,并进行传输,所以从基站可以获取到所有用户访问互联网的日志,这些日志信息就是我们要分析处理的数据,从其中分析出有价值的信息。
从基站得到的用户日志信息可能是通话、短信、即时通信(如QQ、微信等)或者HTTP网络访问等。从访问的链接地址可以分析统计出用户访问各网站的频率,如微信即时通信、支付信息、游戏、阅读、音频视频和导航定位等。还可以统计出用户对同一个网络资源的访问情况、居民上网时间分布、网站访问量排名等。我们可以根据上网人群的日志信息,分析出不同地域、各类人群的用户行为,把这些结论应用在商业背景下将会产生很大的效益,如产品推荐系统就是大数据技术背景下的产物,电信业务数据的处理也有着巨大地潜在利益。
日志信息通常来源于多个基站,首先需要进行日志数据收集,可利用多台服务器通过Flume进行,海量数据将落地在HDFS中。这些数据在分析处理前需要进行数据清洗,抛弃多种原因导致的错误无效日志,清洗出有效的数据,对数据进行分组、合并后,可根据实际业务需求进行处理,得到想要的结果。显然,这一过程不能仅依赖于一台服务器进行,即同时提供海量数据的收集、存储、处理和分析,这样效率太低,且不能满足高可用,故需要采用分布式机器集群系统才能满足需求。图1为搭建的集群部署示意图。
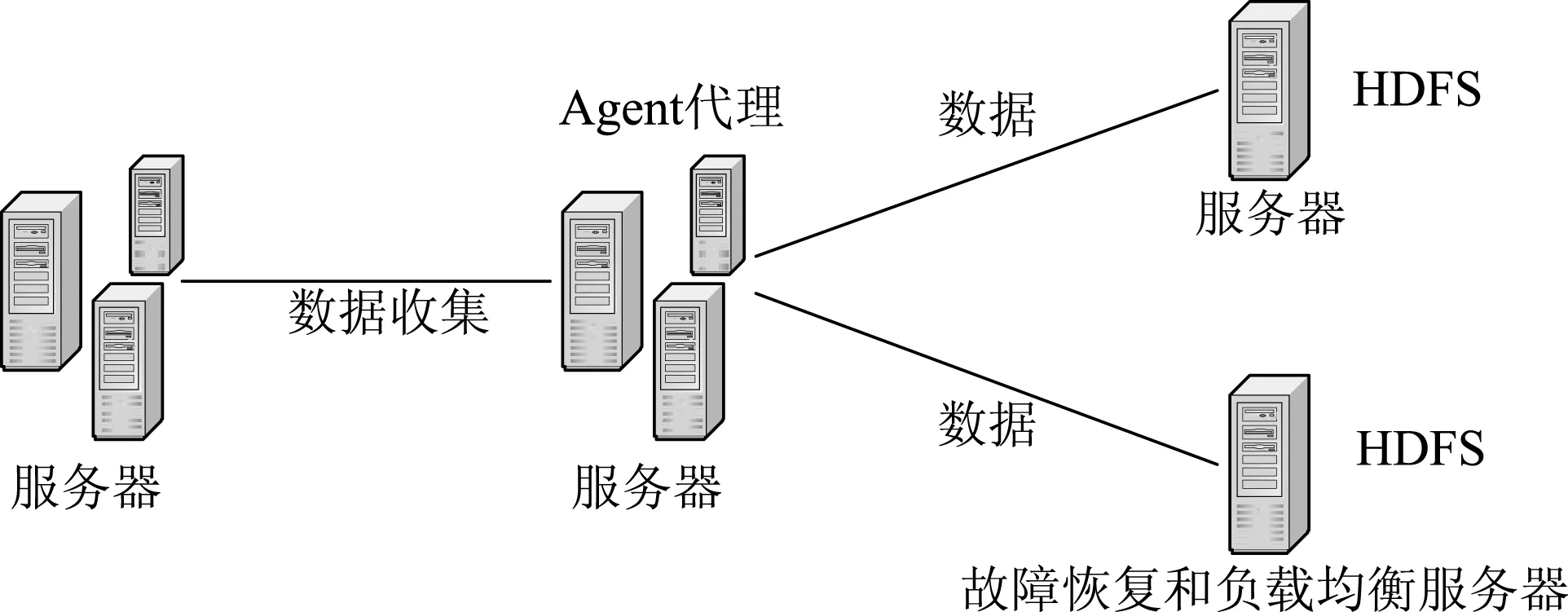
图1 集群部署示意图
电信用户的数据存储在服务器中,这些数据被收集到Flume服务器中。这些服务器负责读取数据并将数据分发到二级服务器中,二级服务器则负责持久化和处理数据。为保证集群正常运行,提高系统可靠性和执行效率,故增加了故障恢复与负载均衡服务。
2 基于HIVE和分布式集群的数据处理
2.1 日志初步处理
具体电信日志数据处理的步骤为:
(1)利用Flume收集数据存储到HDFS中。共配置三台虚拟机,其中一台接受外部数据源传递给它的事件,Source从指定的文件夹下定时地扫描拷贝文件,扫描到Flume中,通过Memory Channel连接到Avro sink,将数据发送给第二台虚拟机,此时数据存储到了第二台虚拟机的HDFS中。第三台虚拟机作为第二台虚拟机的备份,负责负载均衡或故障恢复,此处也可增设一台服务器都做配置。虚拟机之间关系及配置如图2所示。
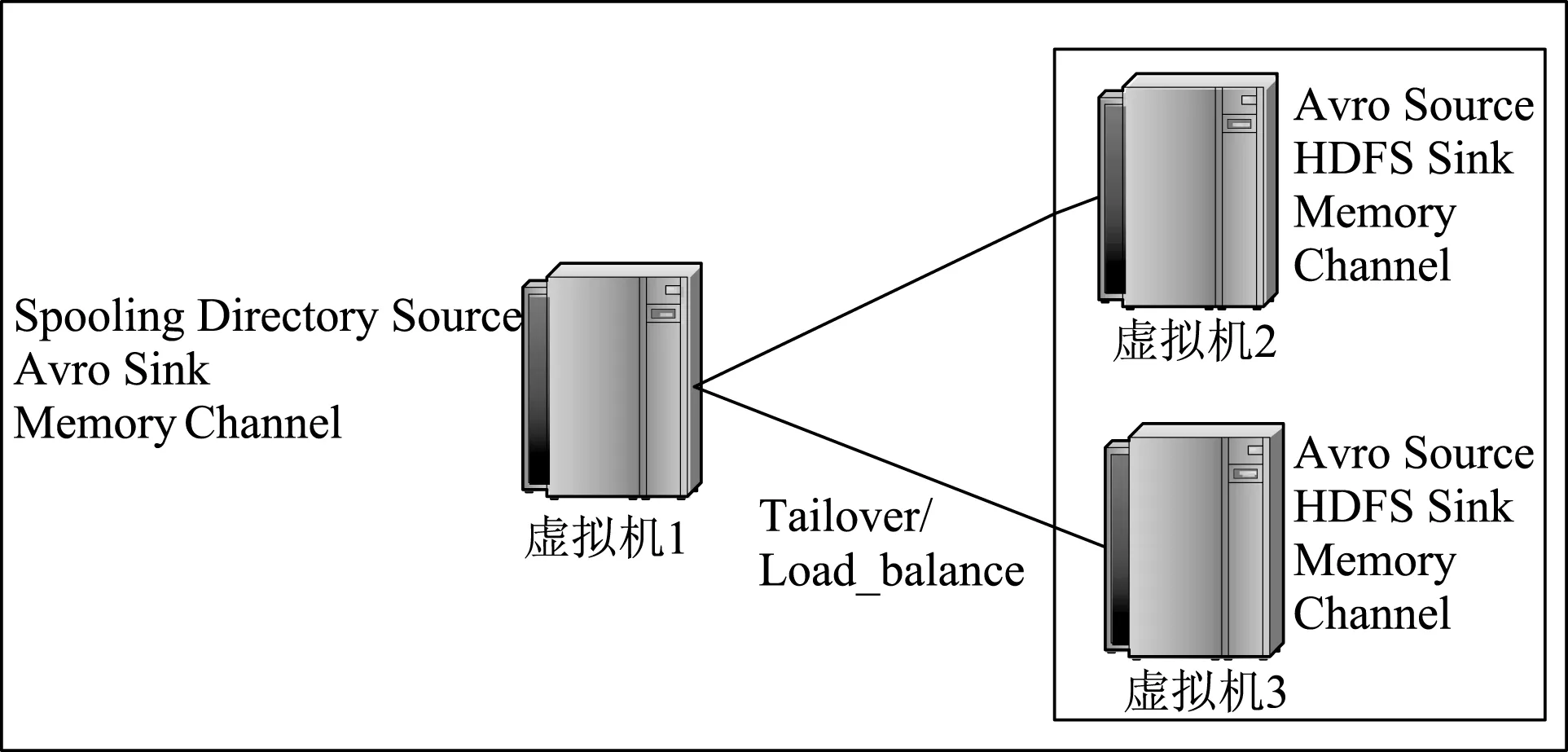
图2 虚拟机之间的关系及配置
(2)创建HIVE[8]外部表管理HDFS中的日志数据。
(3)利用HIVE清洗数据,过滤掉错误日志,新建一个Hive表保存清洗过的有效数据。
(4)对有效数据进行分组,根据实际需求进行业务逻辑处理。例如,假设要统计用户对某一网址的访问情况,就将所有访问HTTP请求的记录存储在一张数据表中,数据表代表访问次数的相应字段设为1。根据网址字段值的不同,合并记录做累加将结果保存到新数据表中,数据仍然存储在HDFS中。
(5)可使用Sqoop将HDFS中处理后的数据导出到Mysql数据库中。
2.2 虚拟机配置
虚拟机1要实现将日志数据传输到虚拟机2的HDFS中,虚拟机3作为故障恢复或负载均衡服务器,当虚拟机2无法正常工作时,虚拟机3开始工作。故在虚拟机1中Flume需要配置sink processor,其type设可为failover或load_balance。该processor需要两个sink,优先级高的sink通过通道连接虚拟机2,优先级低的连接虚拟机3,相关配置如下:
a1.sinkgroups.g.processor.type=failover
a1.sinkgroups.g.processor.priority.s1=5
a1.sinkgroups.g.processor.priority.s2=1
虚拟机1的Source应配置为 spooling directory source,用来监视存储日志信息的文件目录,Sink配置为avro sink,Channel配置为memory。由于Flume数据收集不需要Hadoop支持,所以该虚拟机不需要安装Hadoop组件。
虚拟机2 Flume的Source应配置为avro source,对接虚拟机1的Sink,监听虚拟机1的avro sink端口。虚拟机2的Sink应配置为hdfs sink,此Sink将把数据写到Hadoop的HDFS分布式文件系统中。虚拟机2利用Flume与HDFS通信,要求Hadoop必须安装配置好。虚拟机3与虚拟机2配置基本相同,核心配置为:
a1.sinks.s1.type=hdfs
a1.sinks.s1.hdfs.path=hdfs://[hostname]:9000/mydata
为了方便数据处理,可以在虚拟机1的Source配置中增设Timestamp拦截器,给每条收集到的日志加上时间戳,这样我们就可以利用这一时间戳将日志数据按时间落在不同的HDFS文件夹中。实验设置每天的数据在一个文件夹中。虚拟机1中增加Source拦截器的配置,如下:
a1.sources.r1.interceptors=i
a1.sources.r1.interceptors.i.type=timestamp
HDFS数据存储路径配置可改为:
a1.sinks.s1.hdfs.path=hdfs://[hostname]:9000/mydata/time=%Y-%m-%d-00-00-00
分别启动每台虚拟机的Agent,上传实验数据到虚拟机1的Agent监视目录,数据正常落到了虚拟机2的HDFS上,可以通过命令查看到生成的日志文件,路径为Path指定的目录。
2.3 数据处理优化
HIVE是基于Hadoop[6-7]的一个数据仓库工具,是Facebook公司创建的数据仓库应用。它可以将结构化的数据映射成一张数据表,提供HQL语句进行查询、删除等简单操作,对于复杂的业务逻辑提供了内置函数及JAVA API接口去自定义实现。这些HIVE的操作底层均是转为MapReduce任务去执行,可以方便地实现海量数据的统计分析[9]。
利用HIVE处理HDFS上的数据,首先需要创建外部表来管理这些数据,数据经清洗后存储在新的数据库表中,按照实际业务需求对新表数据做分组合并操作,可映射成多个数据库表。具体过程如下。
(1)创建外部表关联文件与数据采集
首先依次启动Hadoop、HIVE,建立数据库、建立外部数据表dx_data,将HDFS中的记录插入到该表中,这个过程会转换成MapReduce执行。由于原始数据字段较多,此处不再列出详细表结构。在数据采集过程中,通过FTP下载的方式将源系统中的数据采集到Hadoop集群服务器上,是一种完全分布式的数据采集方式。
(2)数据清洗
本文只统计分析HTTP网络访问情况,根据需求取出相关字段新建表dx_newdata。对表dx_data做查询,利用HIVE的Insert操作,将结果保存在新表dx_newdata中。数据库表dx_newdata相关字段如表1所示。
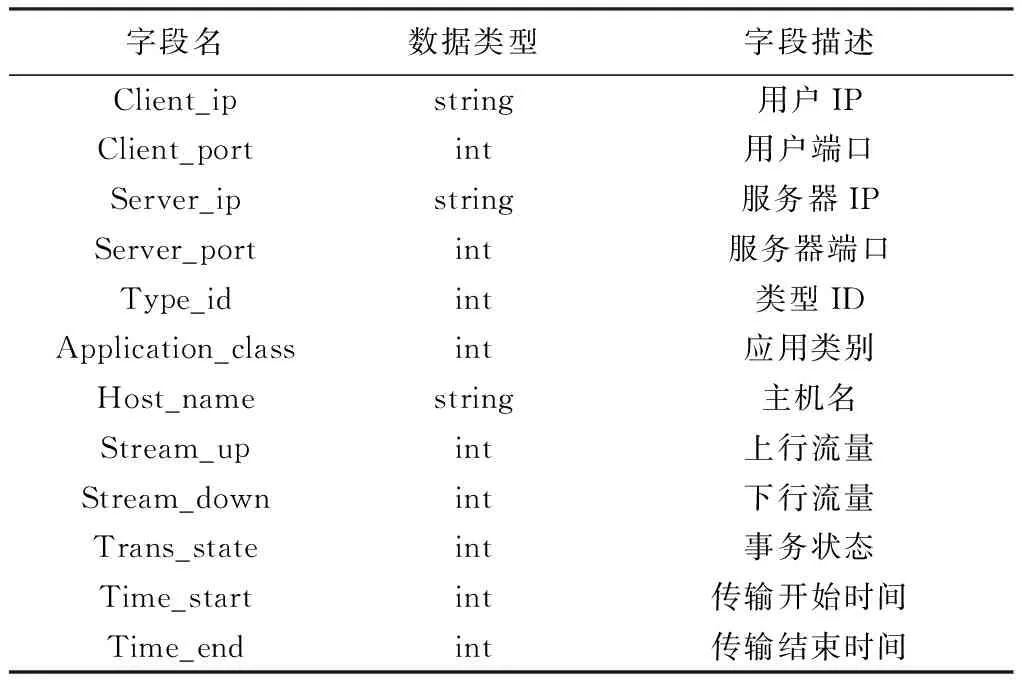
表1 dx_newdata
(3)业务逻辑处理
新建业务逻辑表dx_businessdata,前7个字段是原有字段,剩余3个字段需利用Hive内置函数对dx_newdata表中数据做运算,表结构如表2。每条记录当Trans_state字段值有效时,说明链接成功,接收次数Receive_num值置为1,否则置为0;总流量Stream_total值为Stream_up与Stream_down值之和;Trans_state字段值有效时访问时长Time_total值为Time_end与Time_start之差,否则为0,结果插入到新表dx_businessdata中。

表2 dx_businessdata
业务逻辑处理需要根据需求进行,不同的需求处理不同。对应HQL语句为:
insert overwrite table dx_businessdata select Client_ip,Client_port,Server_ip,Server_port,Host_name,Type_id,Application_class,if(Trans_state==1,1,0),sum(Stream_up+Stream_down),if(Trans_state==1,Time_end-Time_start,0) from dx_newdata;
(4)数据分组、归并
这一过程仍要根据需求进行,下面以统计网站访问排名为例来说明。对表dx_businessdata以字段Server_ip和Host_name进行分组,建立新数据表结构如表3,插入数据到对应字段。HQL语句为:
insert overwrite table dx_host select Server_ip, Host_name,sum(Receive_num),sum(Stream_total), sum(Time_total) from dx_businessdata group by Server_ip, Host_name;

表3 dx_host
这一过程相当于MapReduce框架的Shuffle,根据相同的主机名和服务器IP对记录进行归并,得到类似
3 实验结果与分析
本文实验硬件设备为intel core i7 四核处理器、6G内存、64位操作系统。虚拟机软件环境为CentOS6.5、JDK8、hadoop2.7.1、flume1.6.0、Hive1.2.0和mysql5.1.38。为了体现所提方法的优异性,将文献[6]和文献[7]技术视为对照组。
3.1 数据采集比较
为了研究数据采集方面的性能,本文对不同大小的文件作为采集对象,大小有5 M、100 M、500 M,采集时间如表4-6所示,对照组是文献[6]采用的传统采集方式、文献[7]采用的伪分布式。
从表4-6中可以看出,本文通过完全分布式方法将源系统中的数据采集到Hadoop集群服务器上,整体上速度最快。文献[7]的伪分布方式次之,这主要是因为在完全分布式模块中,单个任务节点可以给三个工作节点分配任务,整体效率更高。从表4的前2行数据、表5的前3行数据、表6的前2行数据中还可以看出,文献[7]的伪分布Hadoop方式比传统方式更优,这主要是因为Hadoop的管理机制会为数据的处理预留一定的缓存空间,但并没有被完全使用,因此,数据量较小时,其优势难以体现。
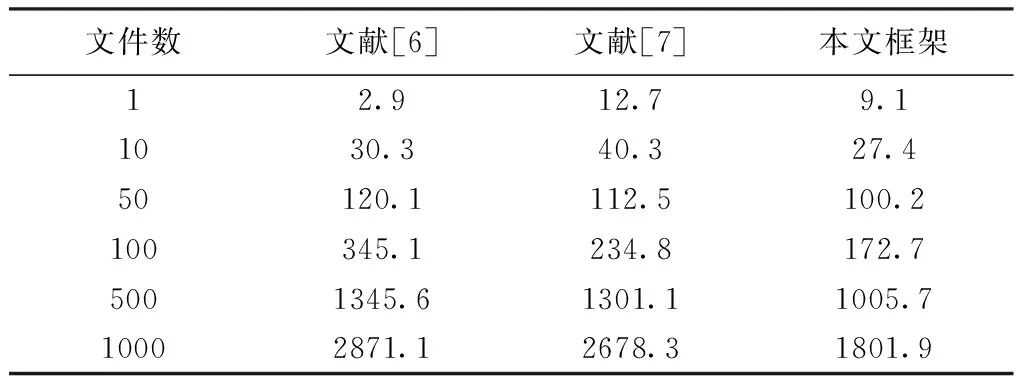
表4 文件大小约为5 M的数据采集时间/s
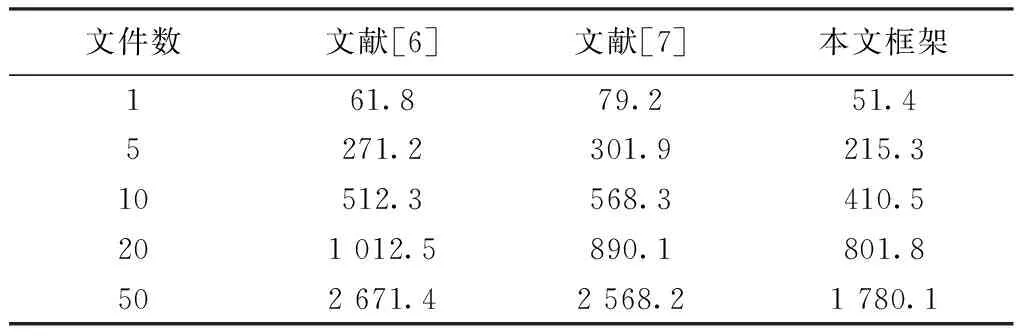
表5 文件大小约为100 M的数据采集时间/s

表6 文件大小约为500 M的数据采集时间/s
3.2 日志处理比较
根据日志文件,访问排名前五网站的情况如图3所示,可以看出,本文配置下的MapReduce的CPU耗费时间为8.75 s,总耗时为114.81 s(这里没有考虑数据采集时间)。由于处理时间与机器硬件配置有关,因此对于不同实验环境,结果可能有所不同。本文对其他方法尽最大可能进行重复实现,对不同大小的文件,文件数为1个,总耗时情况如图4所示。可以看出本文框架,随着文件大小的增加,总处理时间的优势越明显,这主要得益于数据处理与优化过程。
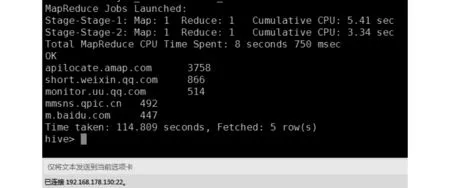
图3 网站访问排名
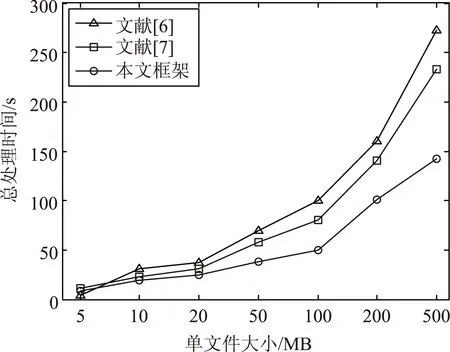
图4 对不同大小文件各方法的耗时情况
另外,还可以查询某一区域或居民社区的网站访问量与排名。图5就是统计某一地区网站的访问情况,此处的日志文件数据量较小。值得一提,根据日志中各应用类别消耗的总流量情况可统计出最热门的应用类别排名,具体如图6所示。图中第一列为应用类别编号,第二列为对应的总流量,第三列为总消耗时间。这些结果可作额外参考。

图5 区域内网站访问情况
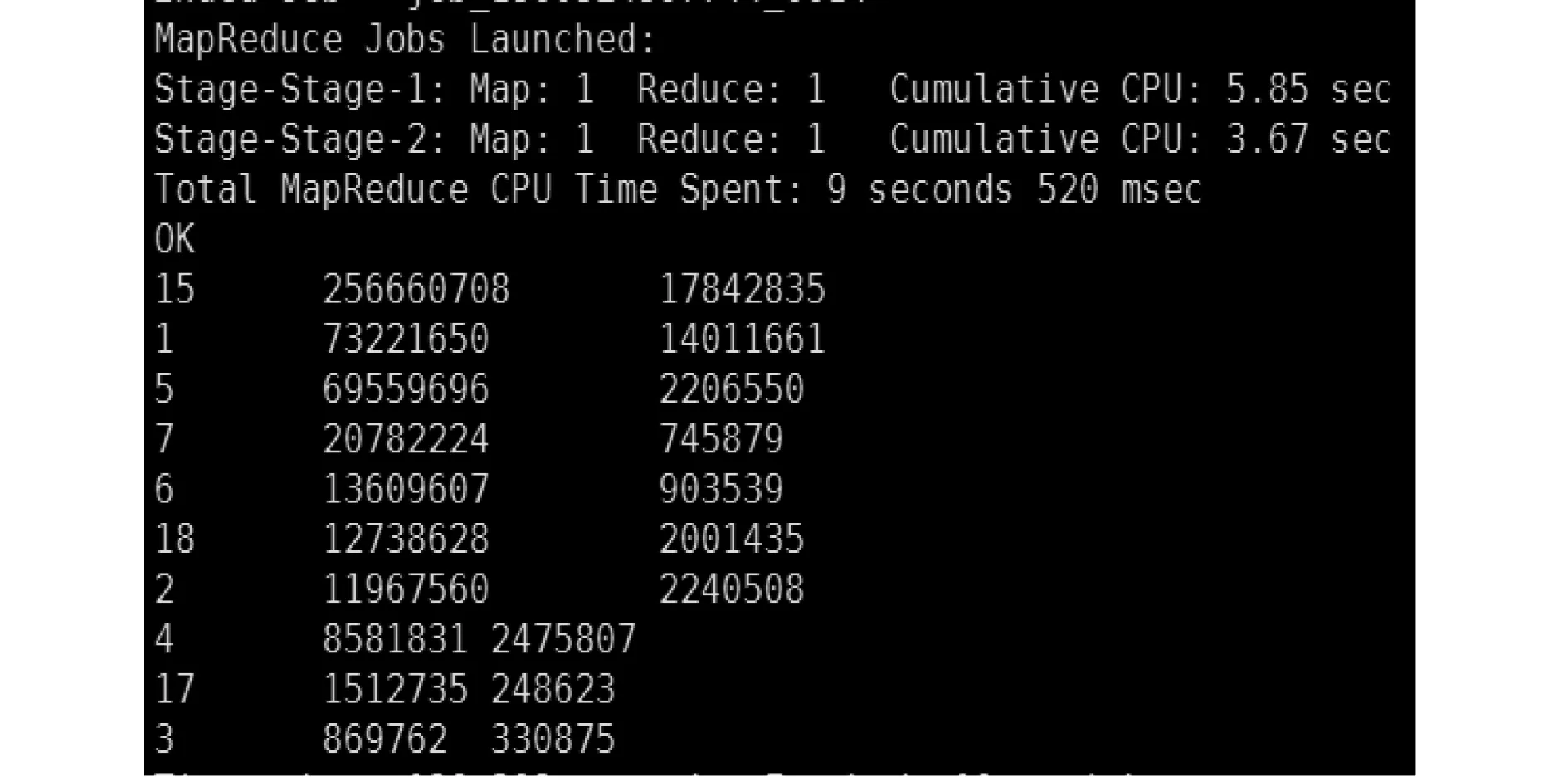
图6 应用类别统计排名
3.3 关于易用性分析
利用JAVA代码虽能够实现数据收集、业务处理、统计分析这些功能,但其数据处理过程复杂、编写代码量大,主机间协调调用都需用代码实现,而且其仅适用于数据文件小的情况,海量数据难以处理[10-11]。利用JAVA编程实现只适用于有JAVA开发背景且熟悉相关API接口的IT技术人员,对行业内部人员不适用。电信数据和很多行业数据一样,其难度并不在于业务复杂性上,而在于海量数据上。数据量太大了,再简单的数据处理也会变得很困难,这正是基于Hadoop平台海量数据处理应用产生的背景,数据存储、数据处理、数据统计等都需要用分布式集群来解决问题。
解决大规模数据的分布式存储,Hadoop 集群支持上千个节点,支持可扩展,在规模上是普通集群无法比拟的,数据吞吐量大[12]。但MapReduce仍然是在JAVA开发环境中用JAVA语言开发Map、Reduce程序,只是省了少部分协调的代码,数据业务处理、数据统计分析等大部分代码依旧需要,JAVA编程的弊端仍然存在。
而HIVE是数据仓库工具,可以通过编写和执行HQL语句直接对数据库表进行操作,能够新建数据表筛选数据直接插入,能够方便快速清洗、查询数据,语句执行自动转换成MapReduce任务,计算速度快,数据吞吐量大,非常适合海量数据应用场景。HQL语法类似于数据库查询语言,具有易学易用的特点,适合非IT业人员。对于复杂的应用HIVE也提供了自定义内置函数和API接口,可灵活使用,对HIVE进行合理配置和参数优化,可以提高任务执行效率。
4 结 语
本文以电信日志文件为具体应用背景,以统计分析网站的访问排名为需求,介绍海量数据的处理方法。主要对数据进行清洗、逻辑处理、分组合并;最后,完成查询分析。借助HIVE进行大数据处理,这种方法比仅使用MapReduce计算框架更优,因为它不需要编写大量的Java代码来处理业务逻辑,对于不同语言背景或不熟悉JAVA API接口的人员使用更方便。HIVE的这些特性使得大数据处理更方便,适合于不同行业背景的人来使用,没有Java编程经验的人也可以顺利完成。
未来考虑在实验中,对HIVE内部进行优化,如Map数量、Join的优化、合并小文件等方式,进一步提高数据的执行效率。
