基于深度神经网络的蒙古语声学模型建模研究
2018-07-20马志强李图雅杨双涛张力
马志强,李图雅,杨双涛,张力
(内蒙古工业大学 数据科学与应用学院,内蒙古 呼和浩特 010080)
典型的大词汇量连续语音识别系统(large vocabulary continuous speech recognition,LVCSR)由特征提取、声学模型、语言模型和解码器等组成。声学模型是语音识别系统的核心组成部分,基于GMM和HMM模型构建的GMM-HMM声学模型[1]一度是大词汇量连续语音识别系统中应用最广的声学模型。在GMM-HMM模型中,GMM模型对语音特征向量进行概率建模,然后通过EM算法生成语音观察特征的最大化概率,当混合高斯分布数目足够多时,GMM可以充分拟合声学特征的概率分布,HMM模型根据GMM拟合的观察状态生成语音的时序状态[2-3]。当采用GMM混合高斯模型的概率来描述语音数据分布时,GMM模型本质上属于浅层模型,并在拟合声学特征分布时对特征之间进行了独立性的假设,因此无法充分描述声学特征的状态空间分布;同时,GMM建模的特征维数一般是几十维,不能充分描述声学特征之间的相关性,模型表达能力有限。因此,在20世纪80年代利用神经网络和HMM模型构建声学模型的研究开始出现,但是,当时计算机计算能力不足且缺乏足够的训练数据,模型的效果不及GMM-HMM[4-5]。2010年微软亚洲研究院的邓力与Hinton小组针对大规模连续语音识别任务提出了CD-DBN-HMM的混合声学模型框架[6],并进行了相关实验。实验结果表明,相比GMM-HMM声学模型,采用CD-DBN-HMM声学模型使语音识别系统识别正确率提高了30%左右,CD-DBN-HMM混合声学模型框架的提出彻底革新了语音识别原有的声学模型框架。与传统的高斯混合模型相比,深度神经网络属于深度模型,能够更好地表示复杂非线性函数,更能捕捉语音特征向量之间的相关性,易于取得更好的建模效果[7-12]。蒙古语语音识别研究主要借鉴了英语、汉语以及其他少数民族语言,在语音识别研究上取得了成果,因此蒙古语声学模型建模过程主要以GMM-HMM模型为基础开展研究,也取得了一定的研究成果[13-16]。在特征学习方面DNN模型比GMM模型具有更大的优势,所以本文用DNN模型代替了GMM模型来完成蒙古语声学模型建模任务。
1 蒙古语声学模型研究
在语音识别领域内,DNN主要以两种形式被应用:直接作为声学特征的提取模型,但是这种应用方式仍需要借助GMM-HMM模型才能完成;将DNN与HMM隐马尔科夫模型进行结合,构成混合模型结构,利用深度神经网络代替GMM高斯混合模型进行声学状态输出概率的计算[7-8]。与高斯混合模型相比,深度神经网络有着更强的学习能力和建模能力,能够更好地捕捉声学特征的内在关系,有助于声学模型性能的提升,所以本文通过使用深度神经网络模型对蒙古语声学特征逐层提取,将分类与语音特征内在结构的学习进行了紧密结合,有利于蒙古语语音识别系统正确率的提升。
1.1 DNN-HMM蒙古语声学模型
DNN-HMM蒙古语声学模型就是将深度神经网络技术应用到蒙古语声学模型中,用DNN深度神经网络代替GMM高斯混合模型,实现对蒙古语声学状态的后验概率估算。在给定蒙古语声学特征序列的情况下,首先用DNN模型估算当前特征属于HMM状态的概率,然后用HMM模型描述蒙古语语音信号的动态变化,捕捉蒙古语语音信息的时序状态信息。DNN-HMM蒙古语声学模型结构如图1所示。

图1 DNN-HMM蒙古语声学模型Fig. 1 The Mongolian acoustic model based on DNNHMM.
在DNN-HMM蒙古语声学模型中,DNN网络是通过不断地自下而上堆叠隐含层实现的。其中,S表示HMM模型中的隐含状态,A表示状态转移概率矩阵,L表示DNN深度神经网络的层数(隐含层为L-1层, L0层 为输入层, LL层为输出层,DNN网络共包含L+1层),W表示层之间的连接矩阵。DNNHMM蒙古语声学模型在进行蒙古语语音识别过程建模前,需要对DNN神经网络进行训练。在完成DNN神经网络的训练后,对蒙古语声学模型的建模过程与GMM-HMM模型一致。
1.2 DNN网络的训练
蒙古语声学模型中的DNN网络的训练分为预训练和调优两个阶段。DNN的预训练就是对深度神经网络的参数进行初始化。通常,DNN深度神经网络的预训练方式分为生成式训练和判别式训练。逐层无监督预训练算法就是使用无监督学习方法对网络的每一层进行预训练,它属于生成式训练算法[17]。在DNN-HMM蒙古语声学模型预训练中,采用了逐层无监督训练算法。
DNN模型是一个多层次的神经网络,逐层无监督预训练算法是对DNN的每一层进行训练,而且每次只训练其中一层,其他层参数保持原来初始化参数不变,训练时,对每一层的输入和输出误差尽量减小,这样就能够保证每一层参数对于该层来说都是最优的。接下来,将训练好的每一层的输出数据作为下一层的输入数据,那么下一层输入的数据就比直接训练时经过多层神经网络输入到下一层数据的误差小得多,逐层无监督预训练算法能够保证每一层之间输入输出数据的误差都相对较小。
具体训练过程如图2所示,训练算法见算法1。
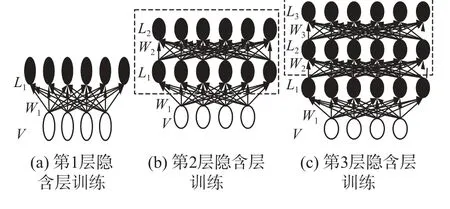
图2 DNN-HMM蒙古语声学模型预训练过程Fig. 2 The pre-training DNN-HMM process for Mongolian acoustic model.
算法1 逐层无监督预训练算法
输入 学习率α,最大迭代次数T,(需要训练的)层数L;各隐含层内的隐单元个数 N =n1,n2,···,nL;训练数据按mini-batch划分后的序列 Xj,其中j =(1,2,···,Max),序列长度Max。
输出 链接权重 Wi, i =(1,2,···,L);偏执向量bi,i=(0,1,···,L)。
1)初始化输入层的偏执向量;
2) For i in 1 to L do;
3)初始化 Wi=0, bi=0;
4) For t in 1 to T do;
5) For j in 1 to Max do;
6) mini-batch = Xj;
7) DNNUpdate (mini-batch, α, Wi, bi, bi−1);
8) End For;
9) End For;
10) End For;
其中DNNUpdate算法采用经典的对比散度算法 (contrastive divergence,CD-K),具体见文献[7]。
通过逐层无监督预训练算法可以得到较好的神经网络初始化参数,然后使用蒙古语标注数据(即特征状态)通过BP(error back propagation)算法进行有监督的调优,最终得到可用于声学状态分类的DNN深度神经网络模型。有监督的调优算法采用随机梯度下降算法进行实现,具体见算法2。
算法2 随机梯度下降算法
输入 训练集set,批量大小batch_size;学习率α,循环次数epoch。
输出 模型参数weight。
1) weight←initWeight();
2) For j in 0 to epoch do;
3) batch←randomSelect(set, batch_size);
4) weight←getWeightFromMaster();
5) Δ W←miniGradient(batch, weight);
6) weight←weight- α * Δ W;
7) End for;
1.3 蒙古语语音数据识别
通过对DNN网络的预训练和调优后,可以利用DNN-HMM声学模型对蒙古语语音数据进行识别,具体的过程如下。
首先,根据输入的蒙古语声学特征向量,计算DNN深度神经网络前L层的输出,即

式中: zα表示激励向量, zα=Wαvα−1+bα且 zα∈ RNαX1;vα表 示 激 活 向 量 , vα∈ RNαX1;Wα表 示 权 重 矩 阵 ,α层的神经节点个数且 Nα∈R; V0表示网络的输入特征, V0=o∈RN0X1。在DNN-HMM声学模型中,输入特征即为声学特征向量。其中 N0=D表示输入声学特征向量的维度, f (·):RNαX1→ RNαX1表示激活函数对激励向量的计算过程, f (·)表示激活函数。
然后,利用L层的softmax分类层计算当前特征关于全部声学状态的后验概率,即当前特征属于各蒙古语声学状态的概率:
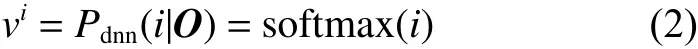
在DNN-HMM蒙古语声学模型中,DNN深度神经网络用于估计每个HMM状态的后验概率,所以DNN的输出是按照HMM隐含状态进行分类输出的,实质上属于多分类任务,因此DNN的输出层通常是softmax分类层。而且softmax分类层的神经单元个数与HMM声学模型中的隐含状态个数相同。在式(2)中, i =1,2,···,C , 其中C 表示声学模型的隐含状态个数,vi表 示softmax分类层第 i 个神经单元的输出,即输入声学特征向量O关于声学模型第i个隐含状态的后验概率。得到隐含状态的后验概率后,利用维特比解码算法进行解码得到最优路径。在直接解码前需要根据贝叶斯公式,将各个状态的后验概率除以其自身的先验概率,得到各状态规整的似然值。隐含状态的先验概率计算较为简单,仅通过计算各状态对应帧总数与全部声学特征帧数的比值即可得到。
2 蒙古语声学模型的调优训练
由于DNN模型在调优时需要对齐的语音帧标注数据,同时标注数据质量往往影响DNN模型的性能,因此,在DNN网络调优阶段,通过使用已训练好的GMM-HMM蒙古语声学模型生成对齐的蒙古语语音特征标注数据。
所以,DNN-HMM蒙古语声学模型的训练过程为:首先训练GMM-HMM蒙古语声学模型,得到对齐的蒙古语语音特征标注数据;然后在对齐语音特征数据的基础上对深度神经网络(DNN)进行训练和调优;最后根据得到的蒙古语语音观察状态再对隐马尔科夫模型(HMM)进行训练。具体见DNNHMM蒙古语声学模型训练过程。
DNN-HMM蒙古语声学模型训练过程:
输入 蒙古语语料库。
输出 DNN-HMM声学模型。
1)进行GMM-HMM蒙古语声学模型训练,得到一个最优的GMM-HMM蒙古语语音识别系统,用gmm-hmm表示。
2)利用维特比解码算法解析gmm-hmm,对gmmhmm蒙古语声学模型中的每一个senone进行标号,得到senone_id。
3)利用gmm-hmm蒙古语声学模型,将声学状态tri-phone映射到相应的senone_id。
4)利用gmm-hmm蒙古语声学模型初始化DNNHMM蒙古语声学模型,主要是HMM隐马尔科夫模型参数部分,最终得到dnn-hmm1模型。
5)利用蒙古语声学特征文件预训练DNN深度神经网络,得到ptdnn。
6)使用gmm-hmm蒙古语声学模型,将蒙古语声学特征数据进行状态级别的强制对齐,对齐结果为align-raw。
7)将align-raw的物理状态转换成senone_id,得到帧级别对齐的训练数据align-frame。
8)利用对齐数据align-data对ptdnn深度神经网络进行有监督地微调,得到网络模型dnn。
9)根据最大似然算法,利用dnn重新估计dnnhmm1中HMM模型转移概率得到的网络模型,用dnn-hmm2表示。
10)如果dnn和dnn-hmm2上测试集识别准确率没有提高,训练结束。否则,使用dnn-hmm2对训练数据再次进行状态级别对齐,执行7)。
在训练过程中,首先训练一个最优的GMM-HMM蒙古语语音识别数据准备系统,目的是为DNN的监督调优服务。在训练GMM-HMM蒙古语声学模型时,采用期望最大化算法进行无监督训练,避免了对标注数据的要求;然后利用蒙古语声学特征对深度神经网络进行预训练;在深度神经网络训练的第二阶段(即有监督调优阶段),利用已训练的GMMHMM蒙古语声学模型进行语音特征到状态的强制对齐,得到标注数据;最后利用标注数据对DNN深度神经网络进行有监督的调优。DNN深度神经网络训练完成以后,根据DNN-HMM在测试集上的识别结果决定其下一步流程。
3 实验与结果
3.1 实验方案设计
为了验证提出的DNN-HMM蒙古语声学模型的有效性,设计了3组实验。在实验中,将未采用dropout技术的DNN-HMM声学模型定义为DNNHMM,将采用dropout技术的DNN-HMM声学模型定义为dropout-DNN-HMM。
1)开展GMM-HMM、DNN-HMM蒙古语声学模型建模实验研究,主要观察不同声学建模单元对声学模型的性能影响,以及对比不同类型声学模型对语音识别系统的影响。
2)通过构建不同层数的深度网络结构的DNNHMM三音子蒙古语声学模型,开展层数对蒙古语声学模型,以及对过拟合现象影响的实验研究。
3)在构建DNN-HMM三音子蒙古语声学模型时,通过采用dropout技术开展dropout技术对DNNHMM三音子蒙古语声学模型过拟合现象影响的实验研究。
3.2 数据集
蒙古语语音识别的语料库由310句蒙古语教学语音组成,共计2 291个蒙古语词汇,命名为IMUT310语料库。语料库共由3部分组成:音频文件、发音标注以及相应的蒙文文本。实验中,将IMUT310语料库划分成训练集和测试集两部分,其中训练集为287句,测试集为23句。实验在Kaldi平台上完成。Kaldi的具体实验环境配置如表1所示。
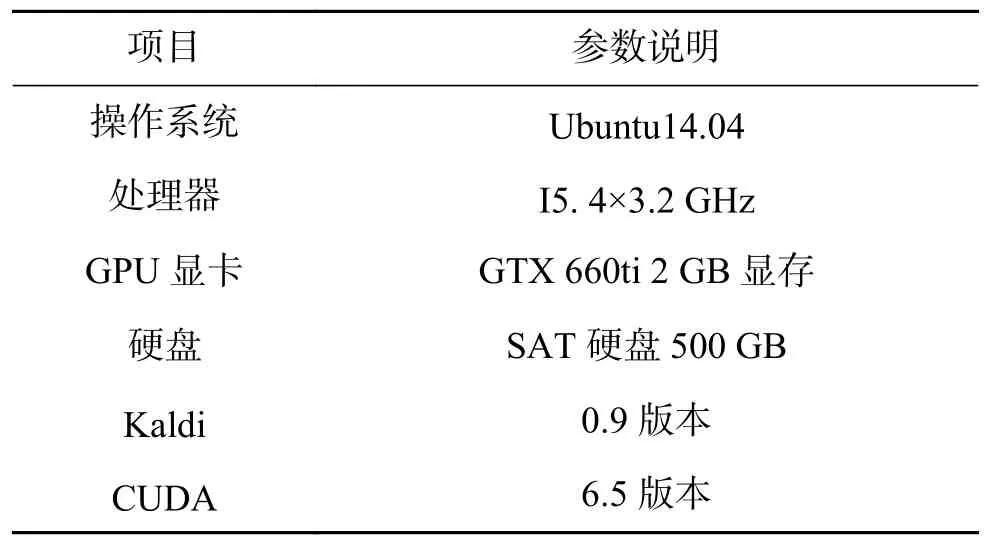
表1 实验环境Table 1 Experimental environment
实验过程中,蒙古语声学特征采用MFCC声学特征表示,共有39维数据,其中前13维特征由12个倒谱特征和1个能量系数组成,后面的两个13维特征是对前面13维特征的一阶差分和二阶差分。在提取蒙古语MFFC特征时,帧窗口长度为25 ms,帧移10 ms。对训练集和测试集分别进行特征提取,全部语音数据共生成119 960个MFCC特征,其中训练数据生成的特征为112 535个,测试数据生成的特征为7 425个。GMM-HMM声学模型训练时,蒙古语语音MFCC特征采用39维数据进行实验。单音子DNN-HMM实验时,蒙古语MFCC语音特征为13维(不包括一、二阶差分特征)。三音子DNN-HMM实验时,蒙古语MFCC的特征为39维。
DNN网络训练时,特征提取采用上下文结合的办法,即在当前帧前后各取5帧来表示当前帧的上下文环境,因此,在实验过程中,单音子DNN网络的输入节点数为143个(13×(5+1+5)),三音子DNN网络的输入节点数为429个(39×(5+1+5))。DNN网络的输出层节点为可观察蒙古语语音音素个数,根据语料库标注的标准,输出节点为27个;DNN网络的隐含层节点数设定为1 024,调优训练次数设定为60,初始学习率设定为0.015,最终学习率设定为0.002。
3.3 实验和结果
为了验证深度神经网络能够更好地捕捉蒙古语语音的声学特征,具备更好地建模能力。本文设计了4个实验,分别是单音子GMM-HMM、三音子GMM-HMM、单音子DNN-HMM和三音子DNNHMM实验。采用3.2中的实验参数设置进行了实验,实验结果数据见表2。
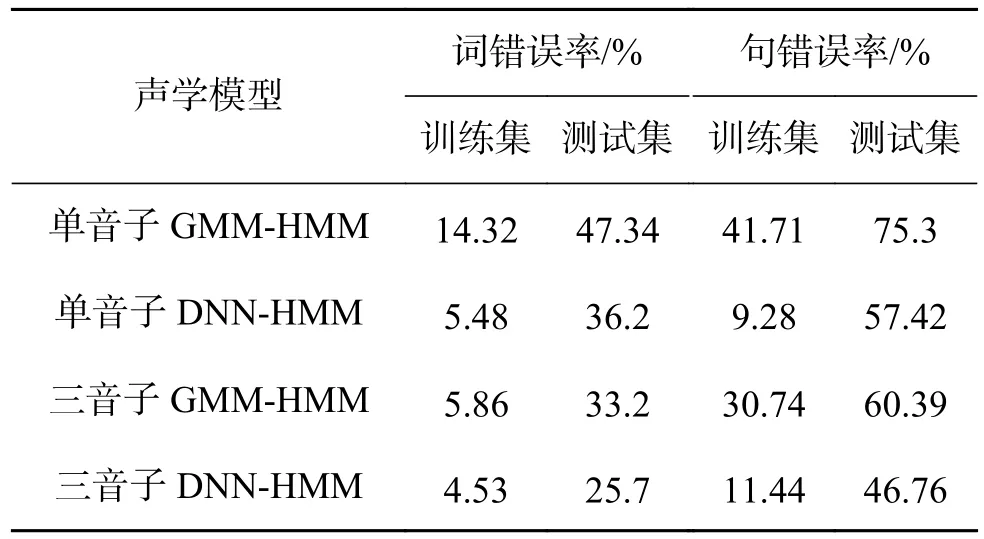
表2 GMM-HMM与DNN-HMM蒙古语声学模型实验数据Table 2 The experimental data of Mongolian acoustic mode from GMM-HMM and DNN-HMM
从图3(a)中可以发现,相对于单音子GMMHMM蒙古语声学模型,单音子DNN-HMM蒙古语声学模型在训练集上的词错误率降低了8.84%,在测试集上的词识别错误率降低了11.14%;但是,对于三音子模型来说,三音子DNN-HMM蒙古语声学模型比三音子GMM-HMM蒙古语声学模型在训练集上的词错误率降低了1.33%,在测试集上的词识别错误率降低了7.5%。由图3(b)发现,单音子模型在训练集上的句识别错误率降低了32.43%,在测试集上的句识别错误率降低了17.88%;对于三音子模型来说,三音子DNN-HMM蒙古语声学模型比三音子GMM-HMM蒙古语声学模型在训练集上的句识别错误率降低了19.3%,在测试集上的句识别错误率降低了13.63%。

图3 相对于GMM-HMM声学模型的实验对比结果Fig. 3 The experimental results are compared with the GMM-HMM acoustic model
从以上分析可以得出:单音子DNN-HMM蒙古语声学模型明显优于单音子GMM-HMM蒙古语声学模型;对于三音子模型来说,三音子DNN-HMM蒙古语声学模型比三音子GMM-HMM蒙古语声学模型的识别率还要高。
另外,为了研究隐含层层数、dropout技术[18-20]对DNN-HMM三音子蒙古语声学模型的影响,本文以未采用dropout技术的4层三音子DNN-HMM蒙古语声学模型为基准实验,分别进行了关于隐含层层数以及dropout技术的对比实验,实验结果数据见表3。
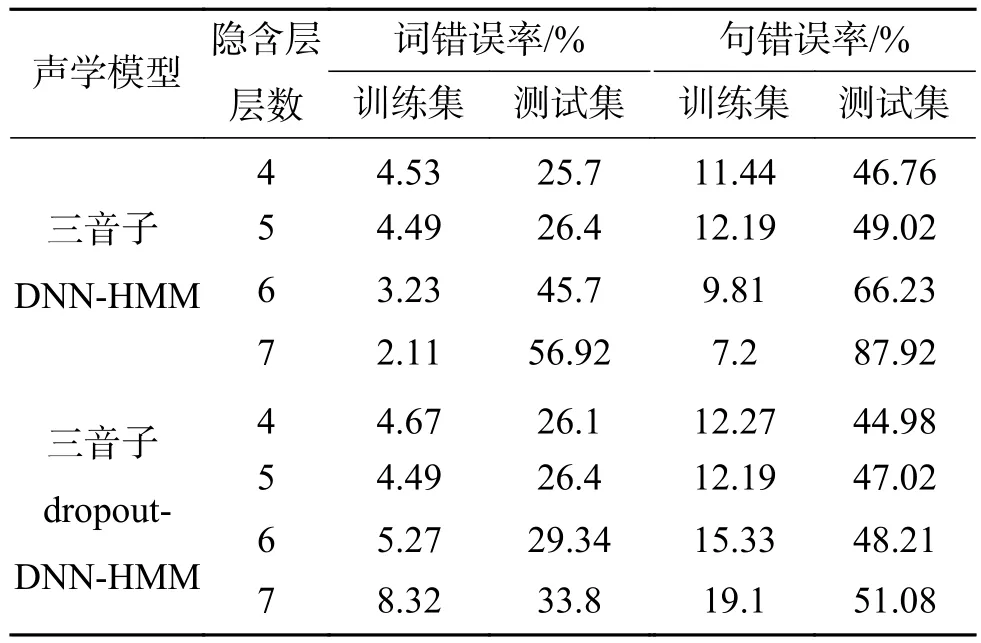
表3 三音子DNN-HMM声学模型上dropout实验Table 3 Dropout experiment on Triphone DNN-HMM acoustic model
为了表示过拟合现象的程度,本文定义了一个模型的过拟合距离,在语音识别中,过拟合往往是通过训练集和测试集上的识别率来进行判断的,当数据在训练集上的识别率很高,而在测试集上的识别率很低时,那么,就表示该模型有着严重的过拟合现象,我们用模型在测试集上的评价指标和模型在训练集上的评价指标的差值的绝对值来表示过拟合现象的程度,所以,将它的计算公式定义为

从图4深色部分中可以发现,在未采用dropout技术训练得到的DNN-HMM蒙古语声学模型中,当隐含层网络层数由4层增加至7层时,对词识别的过拟合距离从21.17%增长到了54.81%;对句识别的过拟合距离从35.32%增长到了80.72%。由此可以看出,随着隐含层网络层数的增加,模型的过拟合距离越来越大,过拟合距离的变大说明DNN网络构建的蒙古语声学模型已经严重过拟合,那么,DNN-HMM的表现就会越来越差。
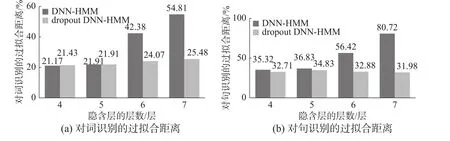
图4 dropout技术和隐含层层数对DNN-HMM模型过拟合距离的影响Fig. 4 Influence of dropout technique and hidden layers on the over - fitting distance of DNN-HMM model
在图4中,通过深浅两种颜色的对比可以看出,采用dropout技术后,当隐含层网络层数由4层增加至7层时,对词识别的过拟合距离分别是21.43%、21.91%、24.07%和25.48%。而未采用dropout技术,对词识别的过拟合距离分别是21.17%、21.91%、42.38%、54.81%。由此可知,采用dropout技术后的过拟合距离要比未采用dropout技术后的过拟合距离小,这一点,在对句识别的过拟合距离上同样存在。所以,在加入了dropout技术后,有效地缓解了因隐含层数增加而导致的过拟合现象,从而提高了模型的识别性能。
4 结束语
在蒙古语语音识别声学建模中,本文给出了DNN-HMM蒙古语声学模型、无监督与监督算法相结合的蒙古语声学模型的训练算法以及以GMMHMM为基础的DNN-HMM蒙古语声学模型的训练过程。在Kaldi实验平台上使用小规模的蒙古语语音语料库IMUT310开展了实验研究,实验结果表明:1)在不同建模单元(单音子和三音子)下,DNN-HMM蒙古语声学模型不论词错误率还是句错误率都优于GMM-HMM蒙古语声学模型,具体表现为三音子DNN-HMM声学模型比三音子GMM-HMM模型在测试集上的词识别错误率降低了7.5%,句识别错误率降低了13.63%;2)在训练DNN-HMM三音子蒙古语声学模型时,加入dropout技术可以有效避免随着隐含层层数增加带来的过拟合影响。
