不协调区间值决策系统的最大分布约简
2018-07-20尹继亮张楠童向荣陈曼如
尹继亮,张楠,童向荣,陈曼如
(1. 烟台大学 数据科学与智能技术山东省高校重点实验室,山东 烟台 264005; 2. 烟台大学 计算机与控制工程学院,山东 烟台 264005)
属性约简[1-7]是粗糙集理论[1-3]的核心研究内容之一,在数据挖掘、机器学习、决策分析、智能信息处理等领域取得了诸多研究成果。属性约简的目的是删除冗余属性,只保留使决策表某种分类特征不变的最小属性子集。差别矩阵方法是一种用于求取所有属性约简的有效方法,该方法由Skowron[8]于1982年提出,并将差别矩阵应用于正域约简中。诸多学者在此基础上做了大量的研究工作。Kryszkie-wicz[9]于1999年在不完备信息系统下引入广义决策保持约简的概念,并提出基于差别矩阵的广义决策保持约简方法;2007年,邓大勇等[10]首先分析了不相容信息系统下几种约简目标之间的关系;2009年,Miao等[11]进一步分析了3种约简目标之间的关系,提出不可分辨关系保持约简以及相应的差别矩阵构造方法;Zhou等[12]在2011年对现有的13种属性约简目标进行总结,并将所有约简目标分为4类,完善了现有约简目标之间的关系。
分布约简保持了信息系统约简前后每条规则置信度不变。2003年,张文修等[13]提出了分配约简、分布约简以及最大分布约简的概念,并分别给出了基于差别矩阵的分配约简、分布约简以及最大分布约简方法;2007年,徐伟华等[14]在优势关系下提出了两种约简概念,即分布约简和最大分布约简,同时建立了基于差别矩阵的分布和最大分布约简的具体方法。如某一段时间内的温度、湿度等区间值数据在现实环境中大量存在,它较好地表示了许多不确定类型数据,区间值决策系统是经典Pawlak决策系统的推广,充分地考虑了数据的不确定性,在近几年得到了广泛关注。2009年,张楠等[15]定义了 α-极大相容类的概念,提出了区间值决策系统的广义决策保持约简;2016年,张楠等[16]在不协调区间值决策系统中提出确定性规则保持约简;2016年,张楠等[17]讨论了不协调区间值决策系统中的知识约简并提出了分布约简的概念。
基于上述研究,文献[13]和[14]分别对等价关系和优势关系下的最大分布约简进行了研究,但未有区间值决策系统的最大分布约简讨论。置信度表示了信息系统中规则的可信程度,置信度越大,规则的可信程度越高;置信度越小,规则的可信程度越低,在实际应用中,人们往往关注置信度最大的规则。为此,本文提出了区间值决策系统的最大分布约简概念,为区间值决策系统提供了一种求取所有属性约简的新方法。
1 基本知识
1.1 区间值决策系统的粗糙近似
基于相容关系的区间值粗糙集模型是经典Pawlak粗糙集模型的推广,首先给出相关概念和性质。
给定区间值信息系统[15-18]I S=(U,AT,V,f),其中, U 是有限对象集合, U ={x1,x2,···,x|U|}; A T是有限属性集合, A T={a1,a2,···,a|AT|}; V 是全体属性的值域,即是属性 ak∈ AT的 值域;f:U×AT →V是一个信息函数,它指定论域 U 中每一个对象 xi在属性ak上的区间属性值,即对任意的 xi∈U , ak∈AT,有 f (xi,ak)=ak(xi)=[lki,uki]。
如果属性集 A T由条件属性集C和决策属性集D 组 成,C ={a1,a2,···a|C|}, D ={d}, 即C ∪ D=AT;V =VC∪VD, 其中, VC为 条件属性值集合, VD为决策属性值集合; f :U×C→VC为 区间值映射,f:U×D→VD为单值映射,则称区间值信息系统为区间值决策系统DS=(U,C∪D,V,f)。
定义1 设 η1=[lki,uki]和 η2=[lkj,ukj]为任意两个区间值,则区间值的交运算与并运算如下。
1)区间值交运算为
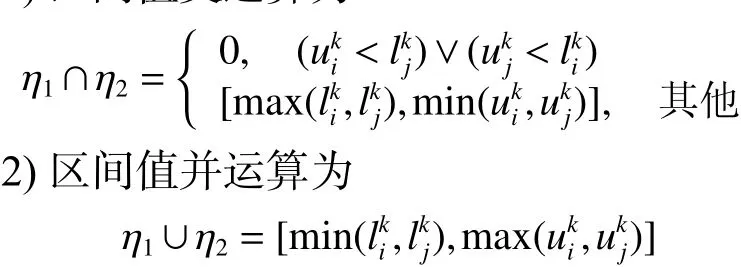
目前,度量区间值相似度比较合理的主要方法有Jaccard相似率、悲观相似率和乐观相似率,本文统一采用Jaccard相似率来度量两个区间值的相似度。
定义2 D S=(U,C∪D,V,f)为区间值决策系统,对 任 意 的 xi,xj∈U , ak∈C , 区 间 值 ak(xi)=和
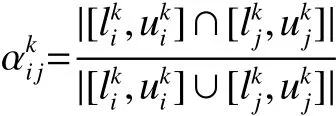
Jaccard相似率为两个区间数的交集与并集长度的比值,它适合度量长度相似的两个区间数。
例1 区间值决策系统 D S=(U,C∪D,V,f),如表1所示,其中, U ={x1,x2,···,x6}为对象的集合,C ={a1,a2,a3,a4}为 条件属性的集合, D ={d}为决策属性。

定义3[15]对于区间值决策系统DS=(U,C∪D,V,f), ak∈C, α ∈[0,1], 则关于条件属性 ak的 α-相容关系定义为

关于条件属性子集 A ⊆U 的 α-相容关系定义为
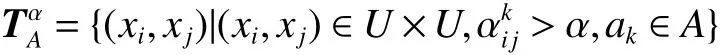
性质1[15]对于区间值决策系统DS=(U,C∪D,V,f), A ⊆C, ak∈A, α ∈[0,1],是属性 ak的 α-相容关系,则关于集合 A的相容关系为
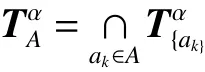
性质2[18]设区间值决策系统DS=(U,C∪D,V,f),A ⊆C , 则具有:
1)自反性:任意 xi∈U,则 (xi,xj)∈。
2)对称性:任意 xi,xj∈U,若 (xi,xj)∈,则(xj,xi)∈。
3)非传递性:任意 xi,xj,xk∈ U , 若满足(xi,xk)∈
定义4[18]设区间值决策系统DS=(U,C∪D,V,f), A ⊆ C, α ∈ [0,1],是属性集A的 α-相容关系,则关于对象xi在属性集A下的 α-相容类定义为

对任意 xi∈U , 区间值决策系统 D S 在 阈值 α下的相容类集合定义为其中 n是论域的个数。

经典粗糙集中对象间的二元关系为等价关系,具有自反性、传递性、对称性,导出的等价类集合是对论域的划分,而定义4中的相容类是对论域的覆盖。
定义5 给定区间值决策系统D S=(U,C∪D,V,f),是 在相容关系下包含 xi的相容类,则对象集合X 关 于α -相容关系的上、下近似[19]分别定义为
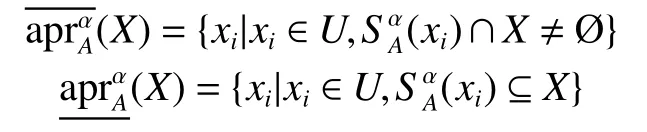
集合 X 关 于 α-相容关系的正域为
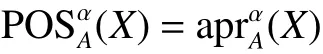
下近似是由肯定属于 X 的对象组成的集合,上近似是由可能属于 X 的对象组成的集合,根据上下近似的概念,决策规则可以分为确定性规则和可能性规则。
定义6[16]给定区间值决策系统D S=(U,C∪D,V,f),X⊆U, A ⊆C , 则条件属性集 A的近似分类精度定义为

近似分类精度表示确定性规则占可能性规则的比例,近似分类精度越大,区间值信息系统中确定性规则越多;反之,确定性规则越少。
定义7[16]对于区间值决策系统DS=(U,C∪D,V,f), A ⊆C , 决策属性D对 U 的划分为U/D ={D1,D2,···,D|U/D|}, 决策属性D关于 α-相容关系的上、下近似分别定义为
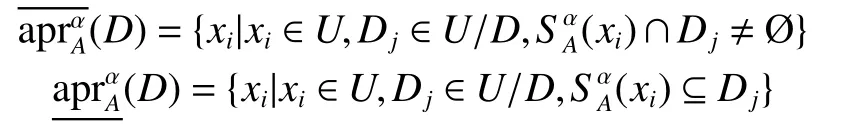
决策属性D关于 α-相容关系的正域定义为

定义8[16]设区间值决策系统DS=(U,C∪D,V,f), A ⊆C , 决策属性D对 U 的 划分为U/D={D1,D2,···,D|U/D|},则在决策属性D下,关于条件属性集A的近似分类精度定为
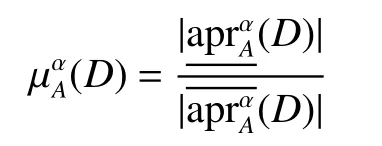
定义5和定义6是关于集合 X的上、下近似和近似分类精度,而定义7和定义8是关于决策属性D的上、下近似和近似分类精度。
定义9[13]对于区间值决策系统D S=(U,C∪D,V,f),对任意 xi,xj∈U , 且 i ≠ j, 若xi和 xj具 有 α-相容关系,且满足 d (xi)=d(xj), 则称 xi∈U 是 关于属性集 A ⊆C的α-协调对象;否则称为α -不协调对象。
若存在一个对象 xi∈U 是 关于 A ⊆C 的 α-不协调对象,那么称 D S为不协调区间值决策表,否则称为协调区间值决策表。
例2 如表1所示的区间值决策系统,令 α =0.6,则相容关系为

根据相似率布尔矩阵,计算阈值 α =0.6下的相容类集合为
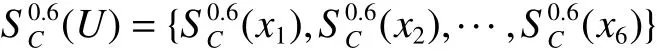
U/D={{x1,x5,x6},{x2,x3,x4}}为决策属性D对U的划分,计算决策属性D关于相容关系 T0.6的上、
C下近似:

计算条件属性集C的近似分类精度:

1.2 区间值决策系统的分布约简
文献[16]提出不协调区间决策系统的分布约简。
定义10 设区间值决策系统DS=(U,C∪D,V,f), A ⊆ U, U /D={D1,D2,···,D|U/D|},则xi∈U对应的概率分布定义为
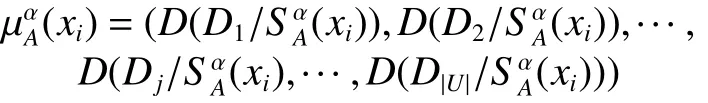
定义11 设区间值决策系统DS=(U,C∪D,V,f),U={x1,x2,···,x|U|}, 则对任意1 ≤ i,j≤ |U|:

定义12 设区间值决策系统 D S=(U,C∪D,V,f),C={a1,a2,···,a|C|},i,j)表 示 可 辨识矩阵中第i行j列的元素,基于 α-相容类的分布可辨识函数定义为与 a1,a2,···,a|C|相对应的 |C |个布尔变量a¯1,a¯2,···,a¯|C|的布尔函数为此函数简称分布可辨识函数。这里的 ∨表示满足 a ∈的全体布尔变量a ¯的析取式。
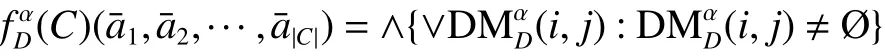
定理1 设区间值决策系统 D S=(U,C∪D,V,f),是分布可辨识函数的形式转化,若A⊆C是分布约简,当且仅当A是的一个蕴含项。
基于可辨识矩阵的分布约简算法(distribution reduction algorithm based on discernibility matrix,DRADM)描述如下。
算法1 DRADM
输入 区间值决策系统 D S,阈值α。
输出 区间值决策系统的所有分布保持约简结果。
1)计算区间值决策系统 D S 的 在阈值 α下的相容类集合 SCα(U);
2)根据每个对象对应的相容类,计算每个对象相对于每一个决策类的概率分布
例3 如表1所示的区间值决策系统,令α =0.6,
根据例2可知相似布尔矩阵以及相容类集合。
计算每个对象对应的概率分布:
计算分布保持约简可辨识矩阵:
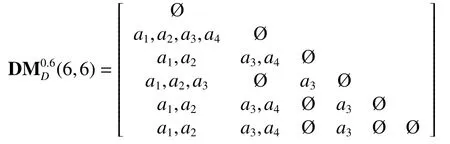
计算分布约简可辨识函数:
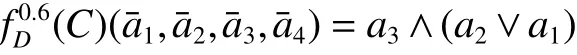
转化后的分布约简可辨识函数为
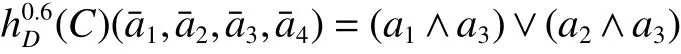
因此分布保持约简为 {a1,a3}和 {a2,a3}。
2 区间值决策系统的最大分布约简
本节在区间值决策系统中引入最大规则置信度的概念,提出了不协调区间值决策系统的最大分布约简算法。
定义13 设区间值决策系统D S=(U,C∪D,V,f),A ⊆ C,U/D={D1,D2,···,D|U/D|}, 则 xi∈ U对应的最大概率分布定义为

若对任意的 xi∈U,有 γαA(xi)=γCα(xi),称 A是DS中基于 α-相容关系的最大分布协调集,简称最大分布协调集。若A是最大分布协调集,且A的任意真子集都不是最大分布协调集,那么称A是DS中基于 α-相容关系的最大分布相对约简,简称最大分布约简。
定义14 设区间值决策系统D S=(U,C∪D,V,f),A⊆C, xi∈U,若属性子集A满足:

那么称属性子集A为区间值决策系统基于相容关系的最大分布约简。DS的所有约简集合记为 α-Reduct, 所有约简的交集称为DS的核,记为 α-C ore。
定理2 设区间值决策系统 D S=(U,C∪D,V,f),A⊆C , 则A是最大分布协调集当且仅当任意 xi,xj∈U,
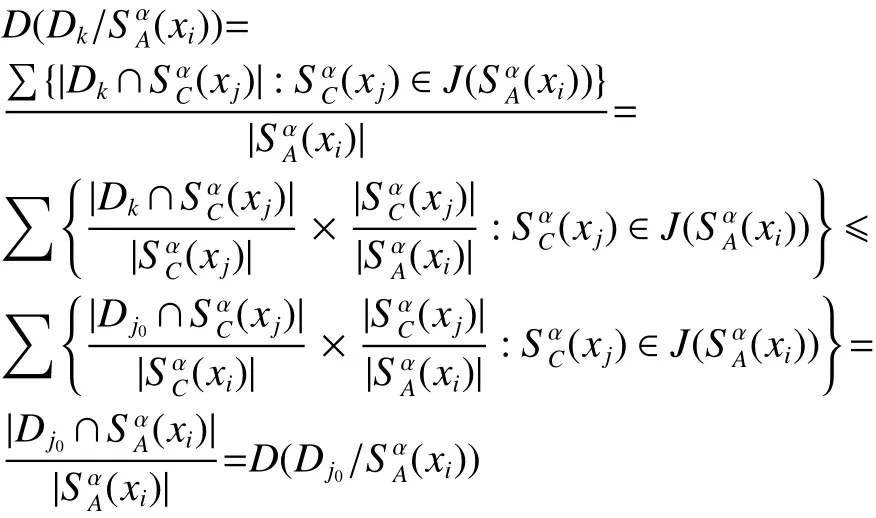
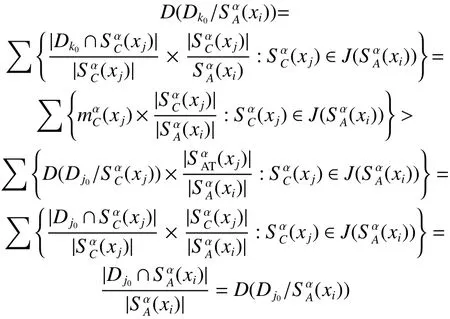
定义15 设区间值决策系统 D S=(U,C∪D,V,f),U={x1,x2,···,x|U|}, 则对任意 i≥ 1,j≤ |U|:
基于α-相容类的最大分布可辨识矩阵是一个相对于主对角线对称的矩阵,在进行运算时只需考虑其上三角或下三角部分即可。
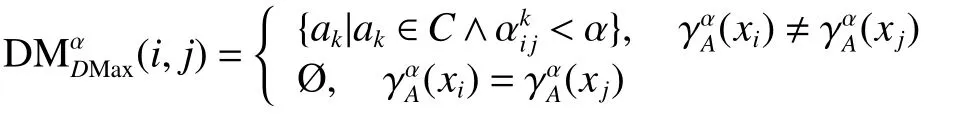
定理3 设区间值决策系统 D S=(U,C∪D,V,f),A⊆C , 则A是最大分布协调集当且仅当任意 xi,xj∈U,
“⇐ ”:假设存在 xi,xj∈U,满1得 A不是最大分布协调集。定理得证。
定义16 设区间值决策系统D S=(U,C∪D,V,f),阵中第i行 j列的元素,基于α-相容类的最大分布可辨识函数为与 a1,a2,···,am相对应 |C |个布尔变量a¯|C|(i,j)≠ Ø}, 为基于 α-相容类的最大分布约简可辨识函数,简称最大分布可辨识函数。(i,j)表示满足(i,j)的全体布尔变量 a¯的析取式。
基于差别矩阵的分布约简算法(maximum distribution reduction algorithm based on discernibility matrix,MDRADM)描述如算法 2。
算法2 MDRADM
输入 区间值决策系统DS,阈值 α。
输出 区间值决策系统的所有最大分布保持约简结果。
2)根据每个对象对应的相容类,计算每个对象相对于每一个决策类的概率分布
3)根据每个对象的概率分布,计算所对应的最大分布 γCα(xi)。
算法2是通过可辨识矩阵求得区间值决策表的所有最大分布保持约简,因此算法在最坏情况下的时间复杂度为 O (|C||U|2), |C |为 条件属性的个数, |U |为对象的个数。
例4 如表1所示的区间值决策系统,令α=0.6,根据例2可知相似布尔矩阵以及相容类。
计算决策属性 D 对 U 划分:
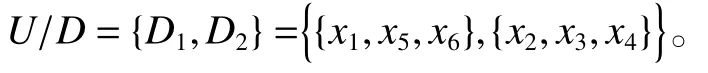
计算每个对象对应的概率分布:
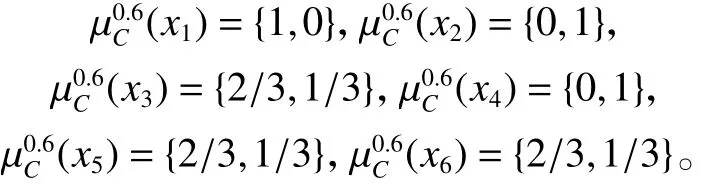
计算每个对象对应的最大分布:
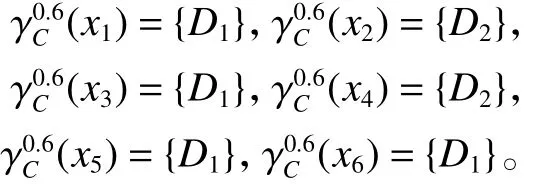
计算最大分布约简可辨识矩阵:
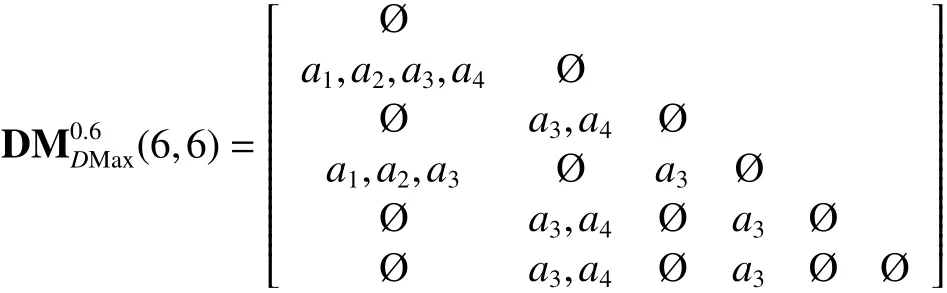
计算最大分布约简可辨识函数:

因此,最大分布保持约简结果为{a3}。
例5 如表1所示的区间值决策系统,令 α分别为0.4,0.5,0.6,0.7,则分布保持约简结果为

最大分布保持约简结果为
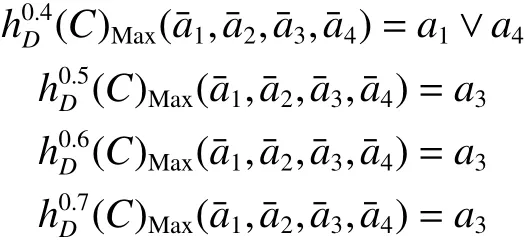
性质3 设区间值决策系统 D S=(U,C∪D,V,f),H=h1∨h2∨···∨hm和 K=k1∨k2∨···∨kn分别是分布约简和最大分布约简结果,则在阈值 α 下 ,对于 K 中任意一个蕴含项 kj, H 中 存在一个蕴含项 hi满足
3 实验验证与分析
本节对提出的最大分布约简算法进行实验验证,实验包括两部分:1)比较最大分布约简方法和其他约简方法的约简结果,验证了性质3的正确性;2)比较了最大分布保持、分布保持和正域保持3种约简算法的约简效率。采用UCI标准测试集进行实验。实验环境为PC机,操作系统为Windows 7旗舰版64 位;内存为6.0 GB DDR3,CPU为Intel i5-3470。
实验选取8组标准UCI数据集,对缺失数据通过将对应属性下占多数属性值进行替换,对名词性数据采用{0,1}替换,对连续型数据采用等频分割[19]的方法,所有数据预处理均在WEKA3.6进行,数据集信息如表2所示, |U |表示对象数,|AT|表示条件属性数, |D |表示决策属性将对象分类个数。

表2 UCI数据集信息Table 2 UCI data sets information
由于表格有限,表3~10中数据集名称均为相应数据集名称的缩写。
由于采用的UCI数据集都是单值数据,因此需将单值数据转换为区间值数据,单值数据转换为区间值数据的方法在文献[19]中已经描述,先将该方法改进,引进阈值 λ,该值可调节振幅,即区间值的长度。
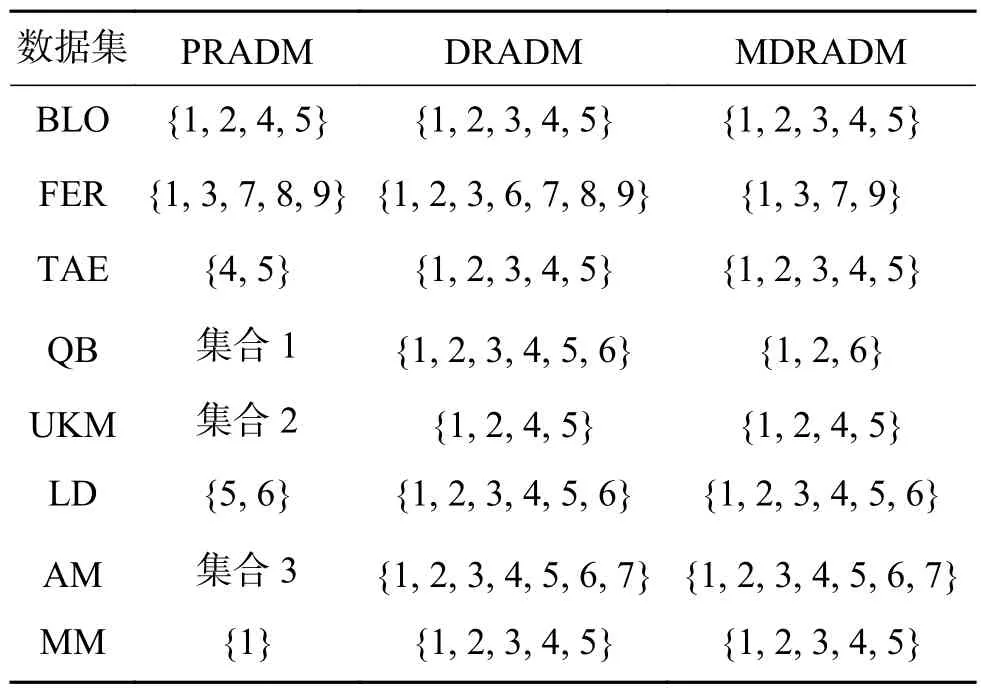
表3 约简结果对比(λ =2.4,α=0.4)Table 3 Comparison of reduction results (λ =2.4,α=0.4)
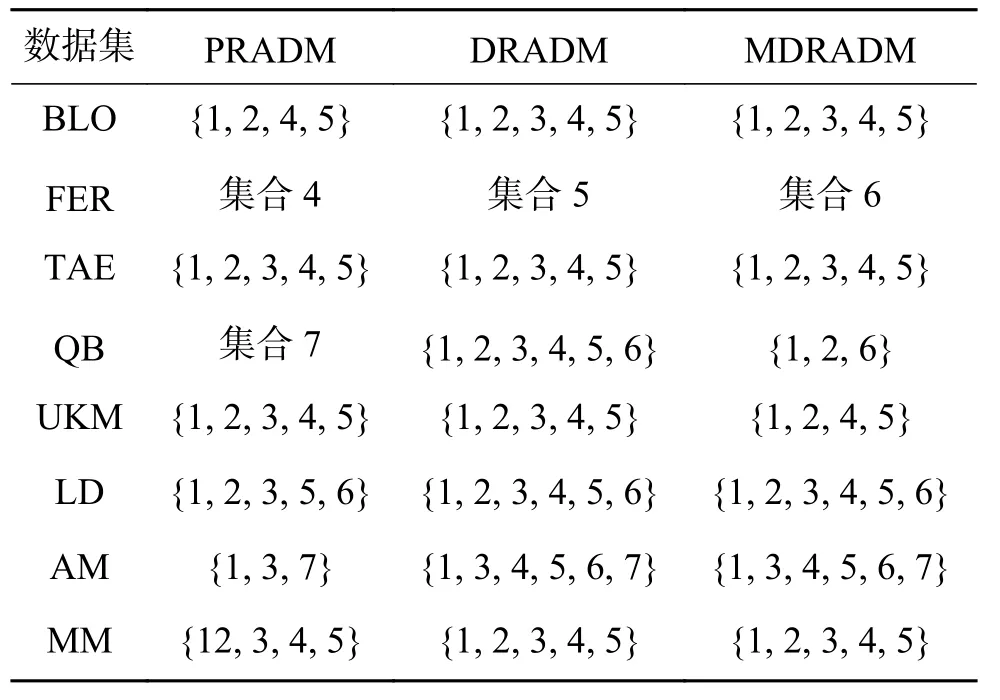
表4 约简结果对比(λ =2.4,α=0.5)Table 4 Comparison of reduction results(λ =2.4,α=0.5)

表5 约简结果对比(λ =2.4,α=0.6)Table 5 Comparison of reduction results (λ =2.4,α=0.6)
设区间值决策系统( U ,C∪D,V,f), 对任意的 xi∈U,at(xi)为 xi在 属性t上的取值 U /D={D1,D2,···,D|U/D|},Dk∈U/D,则单值性数据转换为区间值数据的振幅为
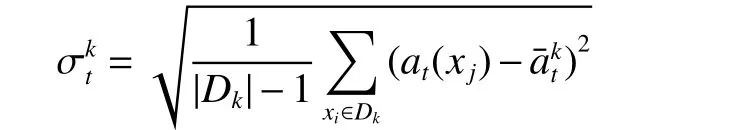
式中
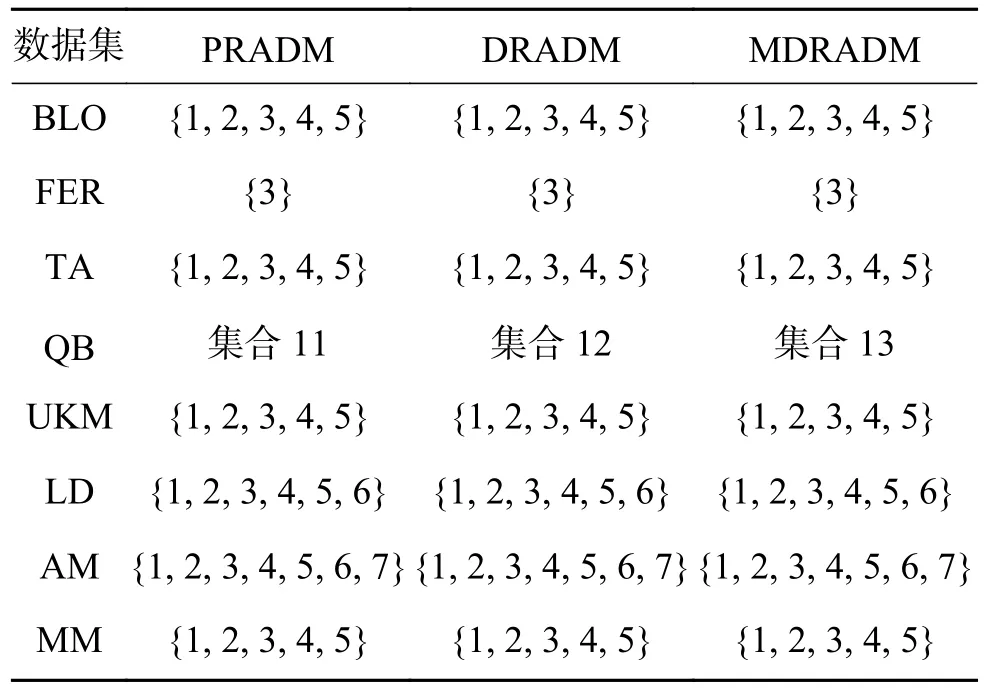
表6 约简结果对比(λ =2.4,α=0.7)Table 6 Comparison of reduction results (λ =2.4,α=0.7)
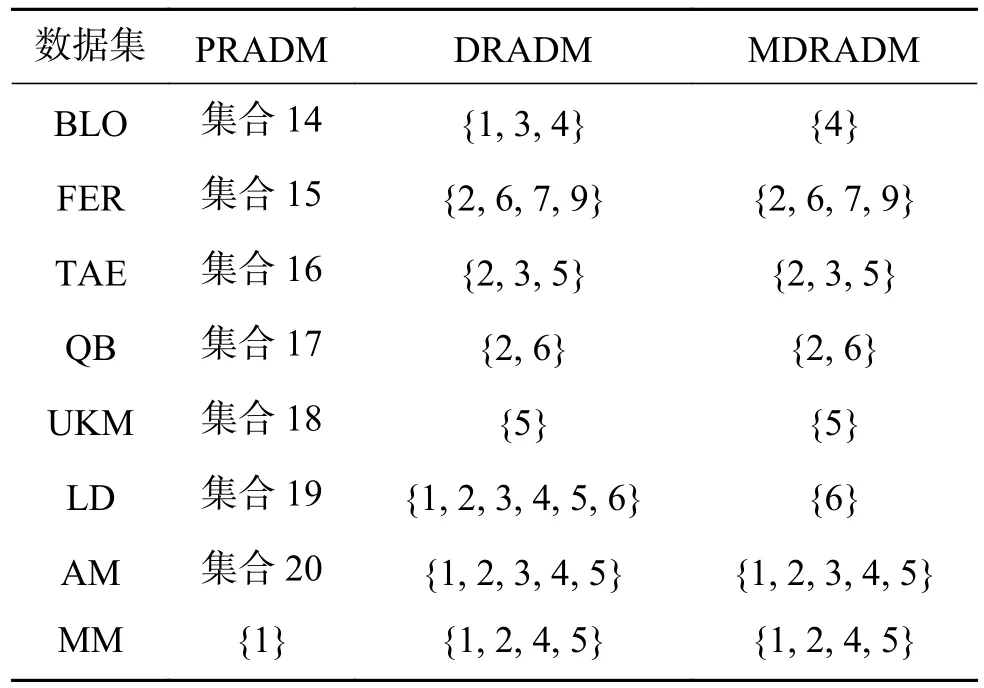
表7 约简结果对比(λ =3.5,α=0.4)Table 7 Comparison of reduction results (λ =3.5,α=0.4)
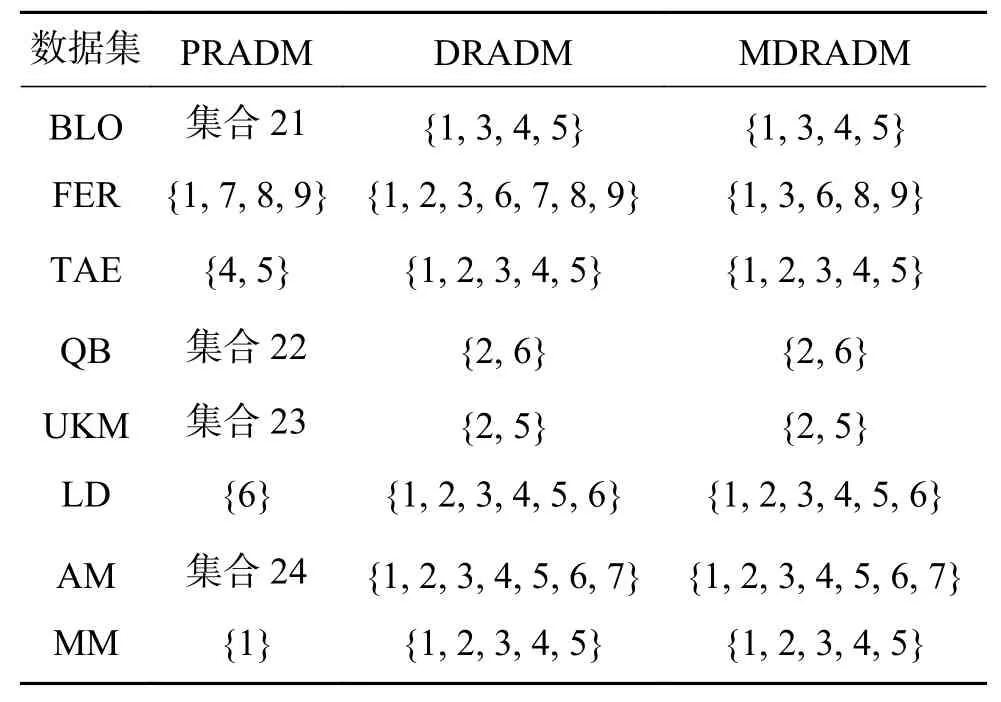
表8 约简结果对比(λ =3.5,α=0.5)Table 8 Comparison of reduction results (λ =3.5,α=0.5)
区间值的左右区间分别为
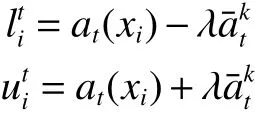
式中 λ为调节区间值长度的值。
3.1 约简结果对比
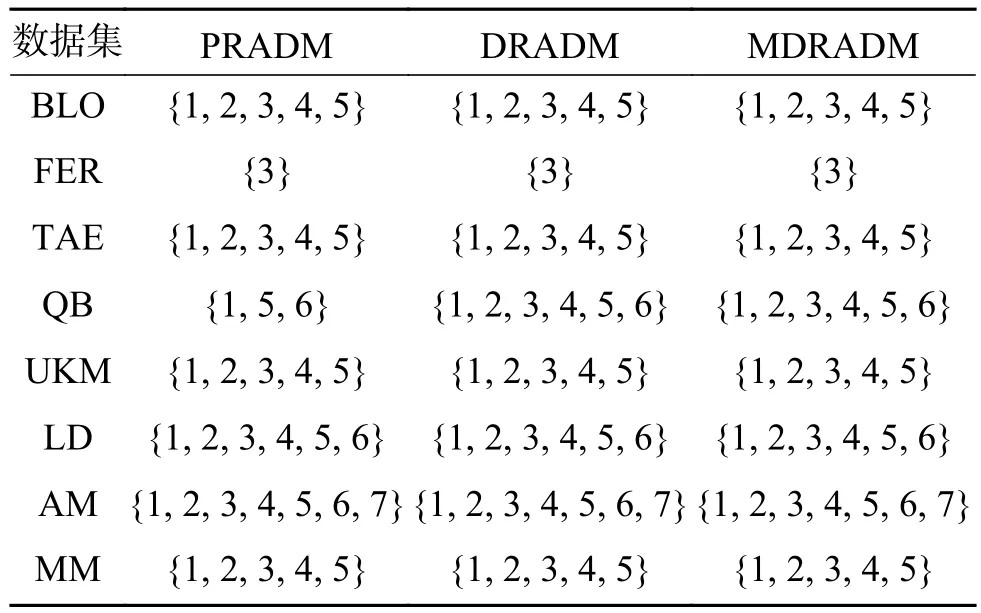
在本节中,讨论了最大分布约简与其他约简方法之间的关系[20],选取正域保持约简算法(PRADM)[17]和分布保持约简算法(DRADM)。 λ 分 别取 2 .4和3.5, α 分 别取 0 .4、0.5、0.6、0.7,共进行了8组实验,实验结果如表3~10所示,其中:集合1=集合7=集合17=集合19=集合22=集合28={{1}, {2}, {3},{4}, {5}, {6}};集合 2=集合 14=集合 16=集合18=集合21=集合23={{1}, {2}, {3}, {4}, {5}};集合3=集合20=集合24={{1}, {2}, {3}, {4}, {5}, {6},{7}};集合 4=集合 6={1, 3, 4, 5, 6, 7, 8, 9};集合5=集合8=集合9=集合10=集合26=集合27={1, 2,3, 4, 5, 6, 7, 8, 9};集合11=集合12=集合13={{1, 3,5},{2, 3, 5},{3, 4, 5},{1, 2, 3, 4, 6},{1, 5, 6},{2, 5,6},{3, 5, 6}{4, 5, 6}};集合15={{1}, {2}, {3}, {4},{5}, {6}, {7}, {8}, {9}};集合 25={1, 2, 3, 4, 5, 7, 8, 9}。

λ=3.5,α=0.6表9 约简结果对比( )λ=3.5,α=0.6Table 9 Comparison of reduction results ( )
表3~6为 λ 取 2 .4, α 分别取0.4、0.5、0.6、0.7时,正域保持、分布保持和最大分布保持约简算法的约简结果。实验结果表明,MDRADM约简结果为DRADM约简结果的子集,即验证了性质3的正确性,而PRADM约简结果和MDRADM约简结果没有明显关系。这是因为,当正域为空时,正域约简结果为条件属性中任意一个属性,故PRADM的约简结果和MDRADM的约简结果不存在包含关系。当 λ =3.5,α=0.4时,对于大部分数据集,DRADM的约简结果最短,Fertility数据集则在λ=2.4, α =0.7时最短,但Liverdisorders数据集在任何阈值下均没有冗余属性。
λ=3.5,α=0.7表10 约简结果对比( )λ=3.5,α=0.7Table 10 Comparison of reduction results ( )
3.2 约简效率对比
本节选取Mammographic Mass数据集,对比两个算法随对象数量的增加耗时变化情况。图1~5为 λ 取 2 .4, α分别取0.4、0.5、0.6、0.7、0.8时,3个算法的时间耗费情况;横坐标表示Mammographic Mass数据集的对象数量,纵坐标表示运行时间,单位为s。
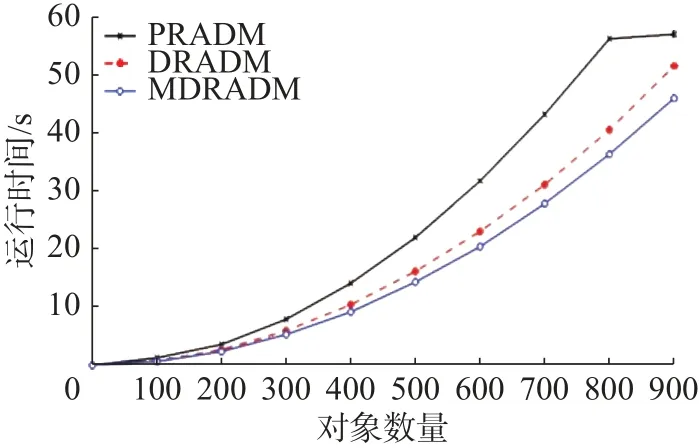
图1 约简效率对比 (α =0.4)Fig. 1 Comparison of reduction efficiency (α =0.4)
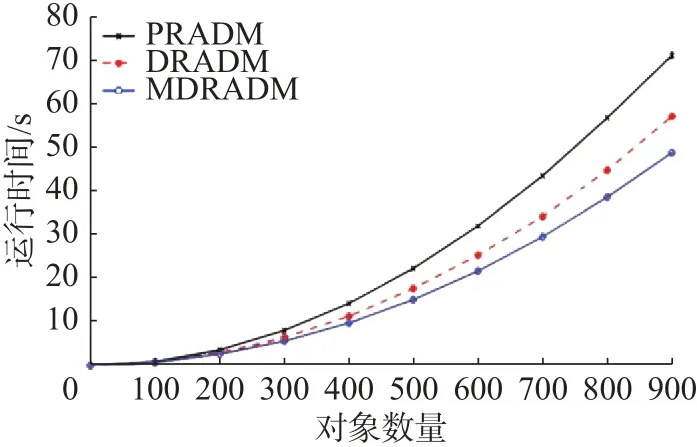
图2 约简效率对比 (α =0.5)Fig. 2 Comparison of reduction efficiency (α =0.5)

图3 约简效率对比 (α =0.6)Fig. 3 Comparison of reduction efficiency (α =0.6)
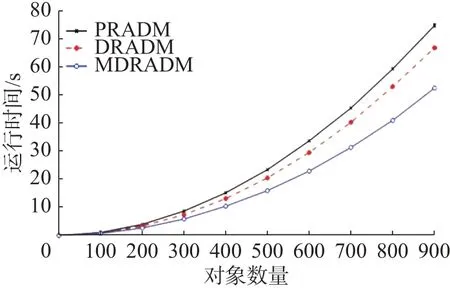
图4 约简效率对比 (α =0.7)Fig. 4 Comparison of reduction efficiency (α =0.7)

图5 约简效率对比 (α =0.8)Fig. 5 Comparison of reduction efficiency (α =0.8)
图1 ~5中虚线表示PRADM随着对象数量增加运行时间变化曲线,空心圆点实线表示MDRADM随着对象数量增加运行时间变化曲线,交叉点实线表示DRADM随着对象数量增加运行时间变化曲线。实验结果表明,在对象数较少情况下,由于差别矩阵较简单,PRADM、DRADM和MDRADM运行时间几乎没有差别,但随着对象数量的增加,3种算法的运行时间差异越来越明显;由于MDRADM差别元素是DRADM差别元素的一个子集,PRADM的差别矩阵为非对称矩阵,故MDRADM的运行时间小于PRADM和DRADM运行时间。当 α分别取 0.5、0.6、0.7、0.8时,Mammographic Mass数据集随着对象的增加,3个算法的耗时差距增大,这是由于随着对象的增加差别矩阵愈加复杂,计算量越大造成的;当 α =0.4时,也呈现这样的趋势,但当对象数达到900时,利用吸收率和结合律运算的差别矩阵较简单,造成时间增长率减小。当 λ 取 3. 5,α分别取 0.4、0.5、0.6、0.7、0.8时,3个算法的时间耗费情况跟 λ 取 2. 4时的折线图大致相同,所以本文不作详细描述。
4 结束语
属性约简是粗糙集理论研究的热点问题之一,在实际应用中具有重要意义,主要作用有:1)提取更加泛化的规则;2)针对应用中的海量数据,能够压缩数据集规模。分布保持约简能够保持信息系统在约简前后置信度不变,而人们往往只关注置信度最大的规则,具有广泛的应用价值。
本文在相关研究成果的基础上,在不协调区间值决策系统中提出最大分布约简的概念,构造了基于可辨识矩阵的最大分布约简算法,该算法保持了在知识约简前后各个规则的最大置信度不变。实验选取8组UCI数据集将本文算法与已有的两种约简算法的约简结果和效率进行对比。实验结果表明,分布约简包含最大分布约简,并且最大分布约简算法比其他两种算法具有更高的效率。由于本文提出的算法是在可辨识矩阵基础上的,其时间和空间复杂度较高,不利于在实际应用中推广,故提出高效率的约简算法是未来研究方向之一。
