重要度集成的属性约简方法研究
2018-07-20李京政杨习贝窦慧莉王平心陈向坚
李京政,杨习贝,2,窦慧莉,王平心,陈向坚
(1. 江苏科技大学 计算机学院, 江苏 镇江 212003; 2. 南京理工大学 经济管理学院, 江苏 南京 210094; 3. 江苏科技大学 数理学院, 江苏 镇江 212003)
作为粗糙集理论[1-2]研究的核心内容,属性约简[3-4]问题一直是众多学者关心的焦点。所谓属性约简,是在给定某一度量标准的前提下,期望利用较少的属性,能够超越利用原始数据中所有的属性所得到的性能或达到与其基本相当的性能。近年来,根据不同的需求目标以及不同类型的拓展粗糙集模型[5-8],众多研究者提出了诸如信息熵[9]、决策代价[10-11]、分类刻画[12]等类型的度量标准作为属性约简的定义。这些不同类型的属性约简大体上可以被划分为两大类[13-14]:1)面向粗糙集不确定性度量的属性约简;2)面向粗糙集学习性能的属性约简。
为了从数据中获取约简,在粗糙集领域的研究中有两大类方法:穷举法与启发式方法。分辨矩阵与回溯策略是穷举法的典型算法,虽然穷举法可以帮助我们得到所有的约简,但由于其计算复杂度过高,并不适用于现实世界中的大规模数据处理。启发式算法是借助贪心的搜索策略求得数据中的一个约简,虽然启发式算法有可能陷入局部最优,仅能得到超约简,但因其速度优势依然得到了广大研究学者的认可。
在启发式约简求解过程中,属性重要度扮演着重要的角色,在向约简集合不断增加属性的过程中,每次都加入重要度最大的属性,直至满足所定义的约简标准。但不难发现属性重要度的计算都是基于计算所有样本的基础上,这会带来两个问题:1)每次计算都需要扫描所有样本,时间消耗过大;2)未考虑数据扰动带来的属性重要度变化问题。虽然王熙照等[15]已经提出了利用边界样本求解属性重要度的方法,这一思想可以进一步降低启发式约简求解的时间消耗[16],但他们没有考虑数据扰动问题。微小的数据扰动有可能会使约简的结果大相径庭,这不仅表明约简本身不具备稳定性,而且也会致使根据约简所得到的分类及预测等结果也呈现不稳定性。针对上述问题,笔者期望利用启发式算法,求得具有较高稳定性的约简。借助集成学习[17-18]的基本思想,可以设计一种集成属性重要度的计算方法,对由不同边界样本所得到的属性重要度进行集成,其目的是使属性重要度的输出更为鲁棒。
1 邻域粗糙集
在粗糙集理论中,一个决策系统可以表示为二元组 D S=〈U,AT∪D〉,其中U是一个非空有限的对象集合,即论域;AT是所有条件属性集合;D是所有决策属性的合集且AT∩D=Ø。
给定论域 U ={x1,x2,···,xn},邻域是建立在某一种度量标准上,通过给定半径考察样本的邻居。不妨假设 M =(rij)n×n为论域上的相似度矩阵,rij表示对象xi与xj之间的距离度量,给定半径δ∈[0, 1],∀xi∈U,xi的邻域区间为

定义1[19-20]给定一个决策系统DS,根据D可以得到所有决策类的合集形如{ X1,X2,···,Xn}。 ∀B ⊆ AT,D关于B的下近似和上近似分别定义为
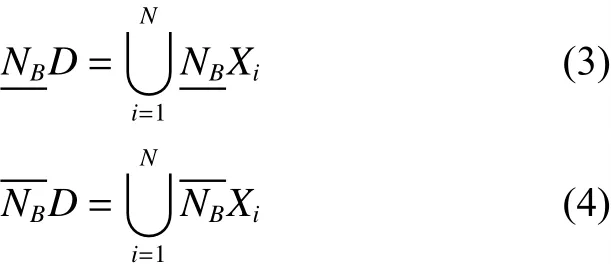
对于任一决策类Xi有
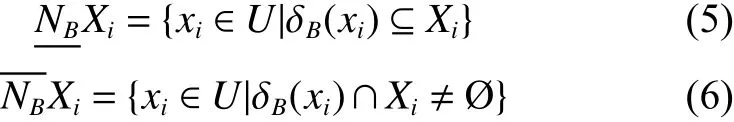
定义2 给定一个决策系统DS,∀ B ⊆ AT,D相对于对B的依赖度为
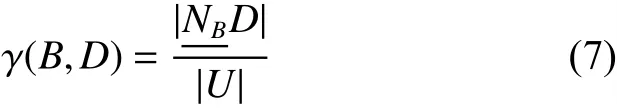
式中|NBD|与|U|分别表示集合NBD与U的基数。
显然 0≤γ(B, D)≤1 成立。γ(B, D)表示属于条件属性B的基础上,某种决策类的样本占总体样本的比例。若越大,则依赖度越高。
2 属性约简
2.1 属性重要度与启发式算法
定义3 给定一决策系统DS, ∀ B ⊆ AT,B被称为一个约简当且仅当γ ( B,D)=γ(AT,D)且 ∀ B′⊆B, γ(B′,D)≠γ(AT,D)。
定义3所示的约简是一个能够保持决策系统中依赖度不发生变化的最小属性子集。根据定义2所示的依赖度,可以进一步考察属性的重要度。
给定一个决策系统DS,∀ B ⊆ AT,且对于任意的a∈AT–B,如果 γ (B∪{a},D)=γ(B,D),那么就表明属性a对于计算依赖度没有带来任何贡献,a是冗余的;如果 γ (B∪{a},D)> γ(B,D),那么就表示加入属性a后可以提高依赖度,从而降低不确定性程度。根据这样的分析,可以构建如式(8)所示的属性重要度:
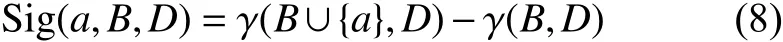
根据上述属性重要度,算法1构建了一个启发式求解过程,其目标是获得以式(8)所示重要度为依据的属性排序序列。
算法1 启发式算法
输入 邻域决策系统 D S=〈U,AT∪D〉。
输出 属性排序seq。
1) seq←Ø,γ(seq, D)=0;
2) 若 AT–seq = Ø,则转至 5),否则转至 3);
3) ∀ai∈AT–seq;
4) 选择 aj,满足 Sig(aj, seq, D)=max{Sig(ai, seq,D): ∀ai∈AT–seq},令 seq=seq∪{aj},返回 2),计算Sig(ai, seq, D);
5) 输出 seq。
2.2 集成属性重要度
算法1在迭代过程中,求解属性重要度是利用全体样本所得到的依赖度差异,如式(8)。但这种重要度计算方法忽视了数据扰动对重要度计算产生的影响,当样本集发生变化时,属性重要度势必也会发生相应的变化,从而导致约简变化。如何降低样本集变化所引起的约简变化程度,其本质是期望所求约简应尽可能稳定、鲁棒,因此需要重新考察属性重要度的计算方法。
从分类学习的角度来看,不同样本对学习性能的贡献程度是不相同的。一般来说,那些对于学习性能影响比较重要的样本大都分布在边界区域上[15-16]。从这一考虑出发,可以将边界区域的样本挑选出来,作为计算属性重要度的依据。一个可行且直观的办法是采用聚类算法对原始样本集进行聚类,在各类簇中挑选出距离类簇中心较远的样本,将这些样本组合成一个新的决策系统,这实际上是一个采样的过程(具体描述如算法2所示)。又因为传统的聚类算法,如k-means聚类的结果并不稳定,其初始类簇中心是随机选取的,故可以在原始样本集上通过多次聚类后得到多个决策系统,分别在这多个决策系统上求得各个属性的重要度并进行融合,最后选择融合重要度较高的属性,其具体描述如算法3所示。
算法2 基于k-means聚类的采样
输入 邻域决策系统 D S=〈U,AT∪D〉。
输出 采样后的决策系统 D S′。
1) U′=Ø;
2) 利用k-means聚类获得U上的类簇C ={C1,C2,···,CN},其中N为决策类的个数;
3) for j = 1 to N
①计算类簇Cj中每个样本到类簇中心的平均距离 dj;
②将Cj中到类簇中心的距离大于平均距离dj的 样本挑选出来加入U′;
end for
4) 输出 D S′。
算法3 重要度集成的启发式算法
输入 邻域决策系统 D S=〈U,AT∪D〉,采样次数k;
输出 属性排序seq。
1) seq←Ø,γ(seq, D)=0;
2) for r = 1 to k
利用算法2进行采样得到决策系统DSr;
end for
3) 若 AT–seq = Ø,则转至 7),否则转至 4);
4) for r = 1 to k
∀ai∈AT–seq,计算属性 ai在决策系统 DSr上的重要度Sigr(ai, AT, D);
end for
5) ∀ai∈AT– seq,融合属性 ai在各个决策系统上的重要度:

6) 选择 aj,满足 Sig(aj, seq, D)=max{Sig(ai, seq,D): ∀ai∈AT–seq},令 seq=seq∪{aj},返回 3);
7) 输出 seq。
在邻域粗糙集上求解属性重要度的时间复杂度为O(U2×n),其中U表示论域中对象个数,n代表条件属性个数,算法1的时间复杂度为O(U2× n3)。kmeans聚类的时间复杂度为O(N×T×U),N为类簇个数,T为迭代次数。算法3的时间消耗为k×N×T×U+k×[U]2×n3,其中[U]是一个不确定集,表示每次kmeans聚类采样的对象个数,聚类次数k为常数,故算法3的时间复杂度为O([ U ]2×n3)。通过大量实验表明[U]<U,所以在聚类次数较少的前提下,算法3的时间消耗一般小于算法1。
3 实验分析
为了验证所提算法的有效性,本文从UCI数据集中选择了9组数据,数据的基本描述如表1所示。实验中取k=5,即进行5次聚类采样,由算法3得到的属性序列不仅和传统的启发式算法比较,而且和王熙照等[15]提出的基于样例选取的求解属性重要度算法对比分析。
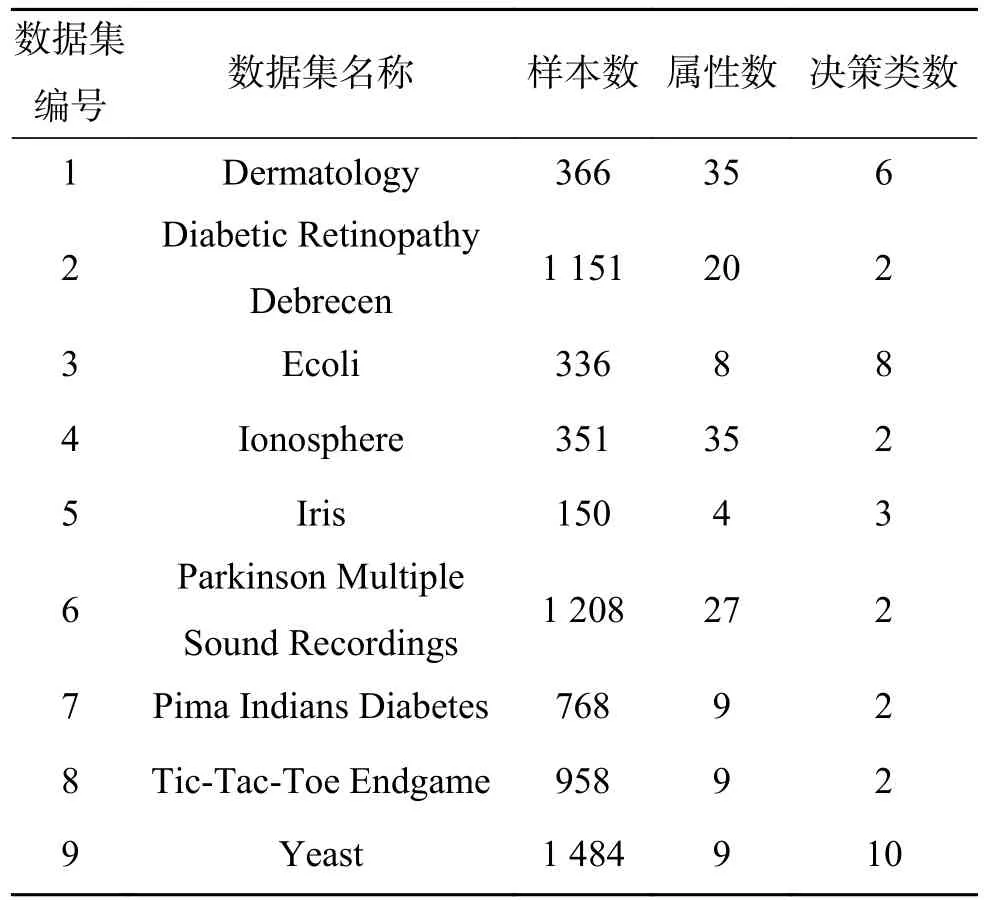
表1 实验数据的基本信息Table 1 Data sets description
为了比较3种约简算法在样本扰动情况下属性的排序结果,采用了5折交叉验证来实现。具体过程为:在每个数据集上,将数据集随机地平均分成5份,即 U1,U2,···,U5。 第一次使用U2∪U3∪···∪U5求得属性排序结果seq1;第二次使用U1∪U3∪···∪U5求得属性排序结果seq2;依次类推,第5次使用U1∪U2∪···∪U4求得属性排序结果seq5。
3.1 属性序列的稳定性比较
度量属性序列的稳定性,就是在样本扰动时度量不同属性序列之间的相似性,相似性越高,说明所得到的属性序列越稳定,可使用式(9)[21]计算属性序列的相似性:
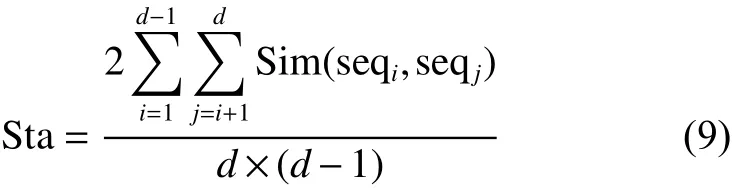
式中: s eqi与 se qj表示第i和第j个属性排序结果;d=5表示5折交叉验证;Sim表示序列之间的相似性,可采用Spearman排序关联系数进行计算:
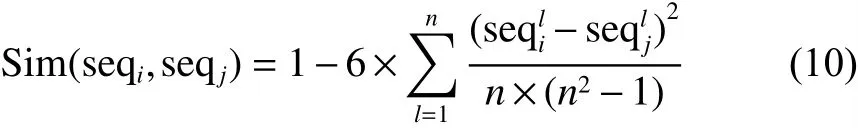
表2列出了4个不同的邻域半径下3种约简算法所求得的属性序列的稳定性结果。
观察表2可以发现,在大多数的半径参数δ下,利用算法3所求得的属性序列相似度都比利用算法1及文献[15]算法所求得的属性序列相似度高,这说明算法3在增加属性的过程中所得到的属性序列是比较稳定的。

表2 属性序列的稳定性对比Table 2 Comparisons of stabilities of attribute sequences
此外,为了检验新算法约简结果稳定性在统计学上是否具有显著性差异,对各算法的属性序列稳定性的值,采用Friedman检验[22]分别计算它们的秩及APV(adjusted p-value),判断其是否拒绝原假设。其中,显著性水平α设为0.05。统计分析结果如表3所示。
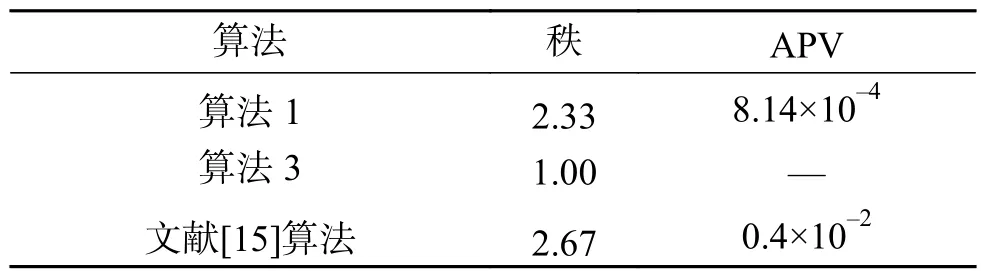
表3 各个算法的统计结果Table 3 Statistical results of various algorithms
从表3可以看出,算法3在各个算法里的秩最小,这表明算法3性能最好。此外,算法1与文献[15]的算法的APV值均小于显著性水平α=0.05,这意味着算法3与其余两种算法有着显著性的差异。
3.2 分类结果的一致性比较
在求解属性排序序列的过程中,将重要度较大的属性逐个添加到约简结果中。在属性序列逐步增长的过程中,不同序列在同一分类器上也会产生不同的分类结果。借助交叉验证,由属性序列可构造联合分布矩阵,如表4所示。

表4 联合分布矩阵Table 4 Joint distribution matrix
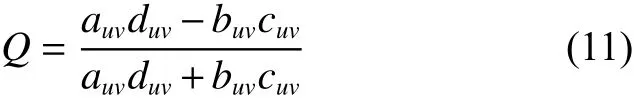
式中Q的取值范围为[−1, 1]。Q值为0时,表示两个排序序列在同一分类器上的预测结果毫不相关;Q值越大,表示当前两个排序结果在同一分类器上的预测结果的一致性越高。整体的一致性可取平均值作为分类结果的稳定性指标。实验中采用KNN分类器去分类,因为不同的数据集对 K 的敏感程度不一样,为了降低K 的取值对分类结果影响,每个数据集对K 寻优,在最佳的K值情况下,再比较各个算法下的分类性能。按照表1顺序,K分别取值为 3、5、9、3、5、9、7、3、5。为了能直观比较3种约简算法分类结果的一致性,以及不同邻域半径参数下对分类结果一致性的影响,分别在邻域参数δ=0.1与δ=0.4时完成本组实验。实验结果如图1所示。

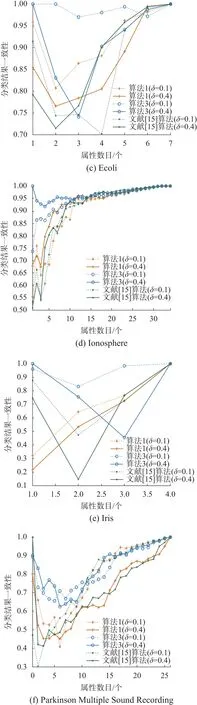

图1 分类结果一致性的对比Fig. 1 Comparisons of classification agreements
由图1可知,随着属性逐个加入排序序列中在相同的邻域半径参数下,算法3在依次增加属性时做出分类结果的一致性总体比算法1以及文献[15]算法要高,验证了由算法3求得属性序列做出分类结果的稳定性要高于算法1以及文献[15]算法。
3.3 分类精度比较
随着当前重要度最大的属性逐渐加入到属性序列中去,进一步考虑当前属性序列的分类精度,对此,分别在邻域参数δ=0.1与δ=0.4时比较了3种约简算法的分类精度,实验结果如图2所示。
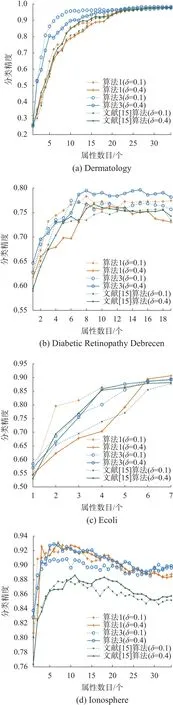


图2 分类精度的对比Fig. 2 Comparisons of classification accuracies
通过图2可知,在相同的邻域半径参数下,随着属性逐个加入到排序序列中,其分类精度也在不断提高,当属性达到一定个数时,分类精度也趋于平稳。总体来说,由算法1、算法3和文献[15]的算法得到的属性序列的分类精度是差不多的。尽管算法3得到的属性序列在样本扰动下的稳定性以及分类结果的一致性较算法1和文献[15]的算法能够得到提升,但是未能有效提升属性序列的分类精度。
4 结束语
利用邻域粗糙集求解约简时,提出了一种可以得到稳定约简的启发式算法框架。这种新的算法在多次采样基础上利用集成的思想求解属性重要度,从而可以用来提高约简的稳定性。实验结果表明,新算法在有效地提升约简稳定性的同时,亦能提高由约简所做出分类结果的稳定性。在本文工作的基础上,下一步工作主要有:1)针对稳定的属性约简与分类度量指标之间的关系进行深入讨论,以期能够在获得稳定约简的基础上,提升分类精度等相应的学习性能;2)文中聚类采样方法未能考虑到原始样本分布情况,对于某些非凸型分布的样本,或许不能有效地抽取到边界样本。进一步考虑数据的分布情况,寻求更有效的方法抽取到边界样本也是笔者的下一步工作。
