优化AUC两遍学习算法
2018-07-20栾寻高尉
栾寻,高尉
(南京大学 计算机软件新技术国家重点实验室, 南京 210023)
曲线ROC下的面积(简称AUC)是机器学习中一种重要的性能评价准则[1-5],广泛应用于类别不平衡学习、代价敏感学习、信息检索等诸多学习任务。例如,在邮件协调过滤或人脸识别中,某些类别的数据显著多于其他类别,而类别不平衡性比例[6]可能为106之多。对AUC的研究可以追溯至20世纪70年代的雷达信号探测分析,之后AUC被用于心理学、医学检测以及机器学习。直观而言,AUC用于衡量一种学习算法将训练数据中正类数据排在负类数据之前的概率。
由于AUC的广泛实际应用,出现了很多优化AUC学习方法,如支持向量机方法[7-8]、集成学习boosting算法[9-10],以及梯度下降算法[11]。这些方法需要存储整个训练数据集,算法在运行时需要扫描数据多遍,因此难以解决大规模学习任务。在理论方面,AGARWAL和ROTH[12]给出了优化AUC可学习性的充分条件和必要条件,而GAO和ZHOU[13]则根据稳定性给出了可学习性的充要条件。
针对大规模AUC优化学习,ZHAO等[14]于2011年提出优化AUC的在线学习算法,该方法借助于辅助存储器,随机采取正样本与负样本。而辅助存储器的大小与数据规模密切相关,因此很难应用于大规模数据或不断增加的数据。为此,GAO等[3]于2013年提出优化AUC的单遍学习方法,该算法仅需遍历数据一次,通过存储一阶与二阶统计量优化AUC学习。
在实际应用中,存储与计算二阶统计量依旧需要较高的存储与计算开销。因此,本文提出了一种新的优化AUC两遍学习算法TPAUC (two-pass AUC optimization)。该算法遍历数据两遍:第一遍统计正负样本均值,第二遍通过随机梯度方法进行优化AUC学习。新算法只需计算与存储一阶统计量,而不需要存储二阶统计量,从而有效地提高效率,最后本文通过实验验证了该算法的有效性。
1 TPAUC学习方法
设示例空间 X ⊂Rd和 Y分别表示样本的输入空间和输出空间,本文关注二分类问题, 于是有Y={+1,−1}。 假设D表示空间 X ×Y上潜在的联合分布。假设训练数据集为

其中每个训练样本是根据分布 D 独立同分布采样所得。进一步假设分类器 f :X→R为一个实值函数。给定样本S和函数 f, A UC(f,S)定义为
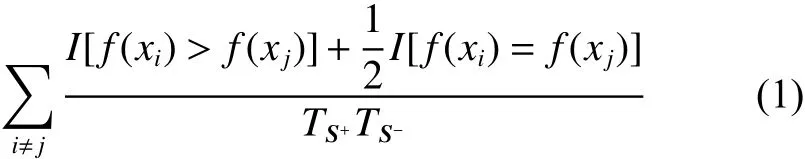
式中: I [·]为指示函数,如果判定为真,其返回值为1,否则为0;分别表示训练集中正、负类样本的样本数。
直接优化AUC往往等价于NP难问题,从而导致计算不可行。在实际应用中,一种可行的方法是对优化表达式(1)进行一种替代损失函数:
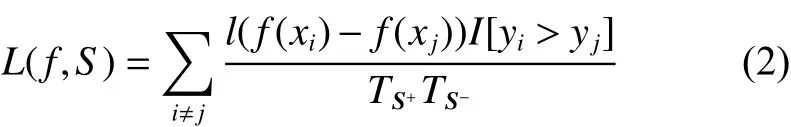
式中 l :R→R+是一个连续的凸函数,常用的函数包括指数损失函数、Hinge损失函数、Logistic损失函数等。由于损失函数定义于一对正样本和负样本之间,该替代函数又被称为“成对替代损失函数(pairwise surrogate loss)”。
借鉴于优化AUC单遍学习算法[3],本文采用最小二乘损失函数,即在式(2)中有
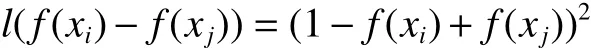
为简洁起见,不妨假设样本总数为 T,其中正样本数为 T+, 负样本数为 T−,以及设优化函数为


设正、负样例的协方差矩阵分别为
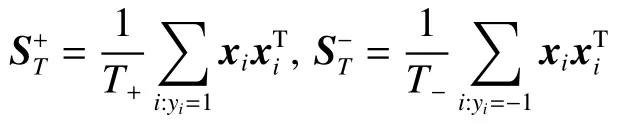
以及设正样例与负样例的均值分别为

因此表达式 L (w)可以进一步化简、分解为

当 yt=1时,有

当 yt=−1时,有

考虑在损失函数中加入正则项,以防止模型过拟合。本文采用随机梯度下降方法[15-19],因此

只需得到关于 wt−1的梯度表达式,而梯度只需对式(3)中 Lt(w)表达式直接求导可得。
本文方法的基本流程可以分为两步:第1步遍历数据,统计正样本和负样本均值和;第2步遍历将利用数据的均值计算得到梯度, 然后利用随机梯度下降法更新 w而完成优化AUC的学习,并在实验中取得很好的效果。
2 实验验证
本文将在标准真实数据集和高维数据集实验验证所提方法的有效性,其中8个标准数据集分别为diabetes、fourclass、german、splice、usps、letter、magic04、a9a。数据集中样本数量从768~32 561不等,样本维度的范围从8~256。所有数据集的特征都被规范到[-1, 1],多分类问题被转变为两分类问题,随机将类别划分成两类。
TPAUC算法的学习率参数 η和正则化参数 λ范围都为 {2−10,2−9,2−8,···,2,4}。首先将数据集划分为训练集和测试集,参数的选择通过在训练集上进行五折交叉验证来确定。选定参数后,再在测试集上进行5遍五折交叉验证,将这25次的结果取平均值作为最终的测试结果。
本文比较了如下5种算法:
1) OPAUC:优化AUC单遍学习算法[3]。
2) OAMseq:优化AUC的在线学习算法[14]。
3) OAMgra:优化AUC的在线学习算法[14]。
4) Online Uni-Exp:优化加权单变量指数损失函数[20]。
5) Online Uni-Squ:优化加权单变量平方损失函数[20]。
实验结果如表1所示,不难发现,本文提出的优化AUC两遍学习方法TPAUC性能与OPAUC相当, 但明显优于 OAMseq、OAMgra、Online Uni-Exp以及Online Uni-Squ。
本文选用8个高维稀疏数据集,分别为realsim、rcv、rcv1v2、sector、sector.lvr、news20、ecml2012、news20.b。数据集中样本数量从9 619~456 886不等。特征维度的范围为20 985~1 355 191。实验设置与标准数据集相似, 实验结果如表2所示。可以发现,TPAUC算法在高维稀疏数据上与其他算法的效果具有可比性或性能更优。

表1 TPAUC在低维数据集上性能比较Table 1 Comparisons of TPAUC on low-dim. datasets

表2 TPAUC在高维数据集上性能比较Table 2 Comparisons of TPAUC on high-dim. datasets
3 结束语
ROC曲线下的面积(简称AUC)是机器学习中一种重要的性能评价准则,由于AUC定义于正负样本之间,传统方法需存储整个数据而不能适用于大数据。为此Gao等提出优化AUC的单遍学习算法,该算法仅需遍历数据一次,通过存储一阶与二阶统计量来进行优化AUC学习。本文致力于减少二阶统计量的计算与存储开销,提出一种新的优化AUC两遍学习算法TPAUC。新提出的算法只需计算与存储一阶统计量,而不需要存储二阶统计量,从而有效地提高效率,最后本文通过实验验证了该算法的有效性。
