深度回归网络下的人脸对齐方法
2018-07-19冯文祥贺建飚
冯文祥,文 畅,谢 凯,贺建飚
(1.长江大学 电子信息学院,湖北 荆州 434023;2.长江大学 计算机科学学院,湖北 荆州 434023;3.中南大学 信息科学与工程学院,湖南 长沙 410083)
0 引 言
近年来,人脸对齐技术取得了巨大的进步,然而由于姿态、光照、表情、遮挡等众多问题影响人脸对齐的效果,尤其在人脸对齐系统中经常遇到的部分遮挡问题,使人脸对齐技术仍然面临巨大的挑战。
目前,深度学习的方法在图像识别领域中取得很好的效果,被得到广泛应用,例如图片分类[1]和特征提取[2]等,将深度学习用在人脸对齐,通过深度学习的方法寻求一系列非线性映射函数来描述人脸图像到人脸形状的非线性关系。Zhang等[3]使用多任务CNN,利用多个卷积神经网络共同学习来提高人脸对齐的精确度,Zhang等[4]提出由粗到精的自编码网络(coarse-to-fine auto-encoder networks,CFAN),级联多级自编码网络来实现人脸对齐,但这两种方法都无法应对大规模姿态变化和遮挡。Yang等[5]提出了头部姿态估计辅助面部对齐(head pose estimation assistant,HPEA)方法,其通过利用卷积神经网络估计头部姿态辅助人脸对齐,来提高系统对姿态变化的鲁棒性,但其对遮挡的人脸效果较差。卷积神经网络在训练过程中,容易出现与实际值偏差较大的异常值而产生训练过程错乱,导致收敛速度慢,不能实现高效的人脸对齐。
针对以上问题,本文提出了深度回归网络下的人脸对齐方法,该方法通过改进GoogLeNet[6]构造一个深度回归网络,引入图基的双权重函数(Tukey’s biweight fuction)[7]作为训练网络的损失函数,减小训练过程中异常值的影响,提高网络的收敛速度。在进行头部姿态估计并初始化人脸形状后在深度回归网络下结合全局信息进行局部回归微调,避免大规模姿态变化和遮挡造成的对齐精度损失问题,实现复杂环境下的人脸精确对齐。
1 研究背景
1.1 头部姿态估计
头部姿态估计是指使用头部二维图像估计三维头部姿态信息的过程,目前基于回归的方法取得较好的效果,将头部姿态估计问题看作是一个回归问题,通过训练一个回归器R={RL,…,RT}, 对输入的二维人脸图像给定一个初始头部姿态θ0,通过式(1)不断地迭代和更新当前姿态
θt=θt-1+Rt(h(θt-1,I))
(1)
式中:I为输入的人脸图像,h为姿态索引特征函数,θt表示第t次迭代之后的头部姿态,t=1…T,最后输出准确的姿态参数θT。
在使用基于回归的方法解决头部姿态估计问题时,Ratsch等[8]使用支持向量回归(support vector regression,SVR)来训练回归函数,Liu等[9]使用随机森林作为回归器,由于深度学习在解决回归问题时具有很多优势,本文将使用卷积神经网络训练回归函数。
1.2 头部姿态辅助人脸对齐
在进行人脸对齐时,由于头部大规模姿态变化给人脸对齐带来影响,可以通过头部的三维姿态信息和三维平均人脸形状对二维人脸图像进行人脸对齐,从而减少姿态对对齐造成的影响。
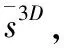
(2)
s0表示初始人脸形状,λ表示边框,θ表示头部姿态信息,这一步并不能得到精确的人脸对齐效果,还需要进行更进一步的处理才能得到更加精确的对齐效果。
2 深度回归网络实现人脸对齐的方法
如图1为本文提出的人脸对齐方法流程,第一步根据人脸图片获得头部姿态估计和5个关键点坐标,第二步根据头部姿态和5个关键点设定人脸初始形状,第三步利用深度回归网络结合人脸初始形状进行局部微调。
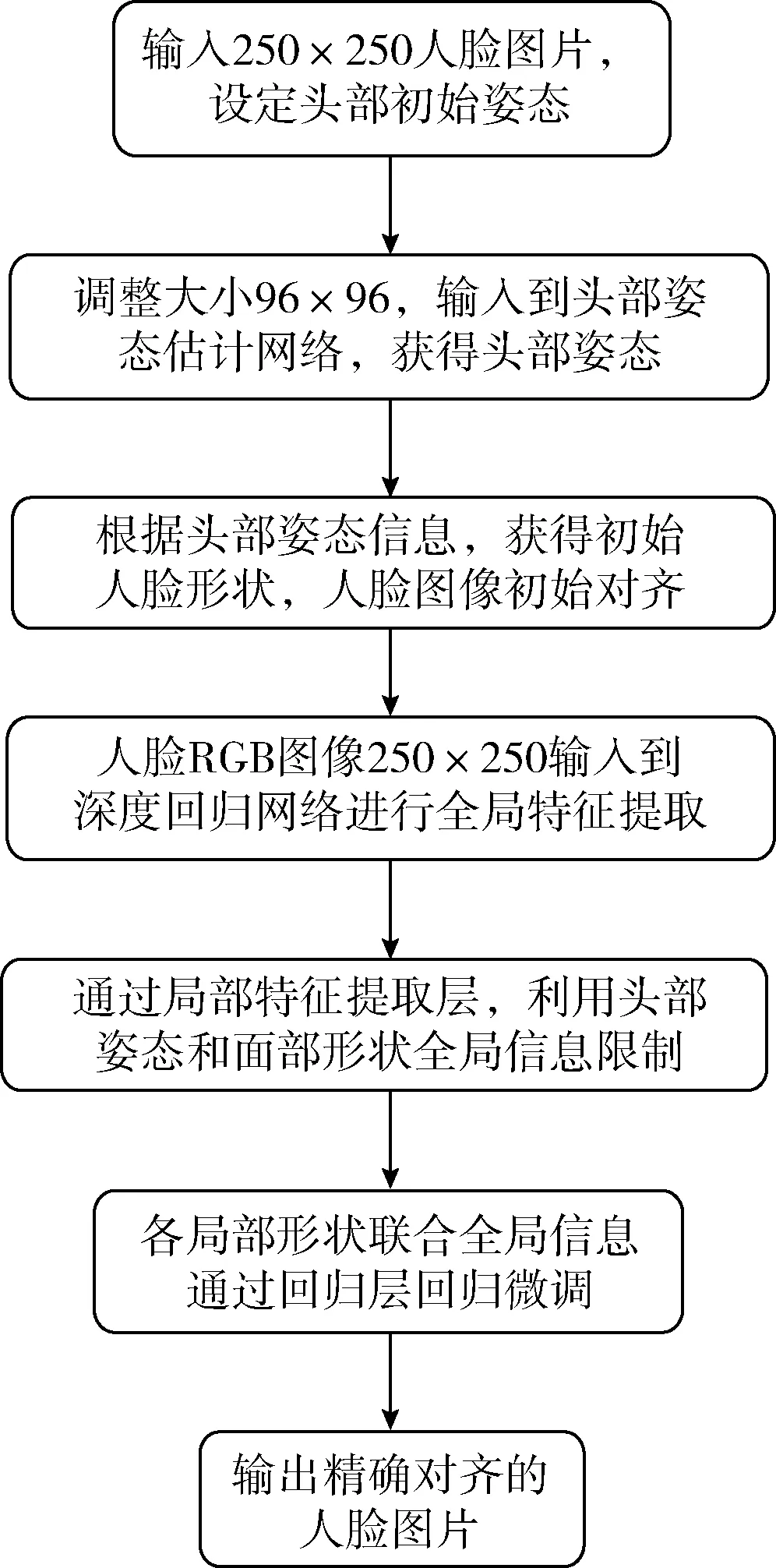
图1 本文方法流程
2.1 头部姿态估计
考虑到人脸图像中人脸的旋转角度、尺度和面部朝向等头部姿态会对人脸对齐造成影响,首先利用卷积神经网络对头部姿势进行估计。
图2为本文用于头部姿势估计的网络模型,其输入为96×96的RGB二维人脸图像,通过得到面部5个关键点(左眼,右眼,鼻尖,和左右嘴角),并根据5个关键点来估计三维头部姿态θ=(θx,θy,θz), 包括滚动角、转动角和平动角[10]。网络由3个卷积层、3个最大值池化层、两个全连接层和一个softmax回归层组成,3个卷积层用于提取特征,每个卷积层有一个大小为5×5像素步长为1的内核组成,最大值池化层用于提高低分辨率图片的性能,卷积之后是两个有300个隐藏单元的全连接层,每一层网络使用dropout来防止过度拟合,卷积层和全连接层由线性变换后接一个非线性变换组成,在输出层中使用softmax函数对头部姿态进行分类。
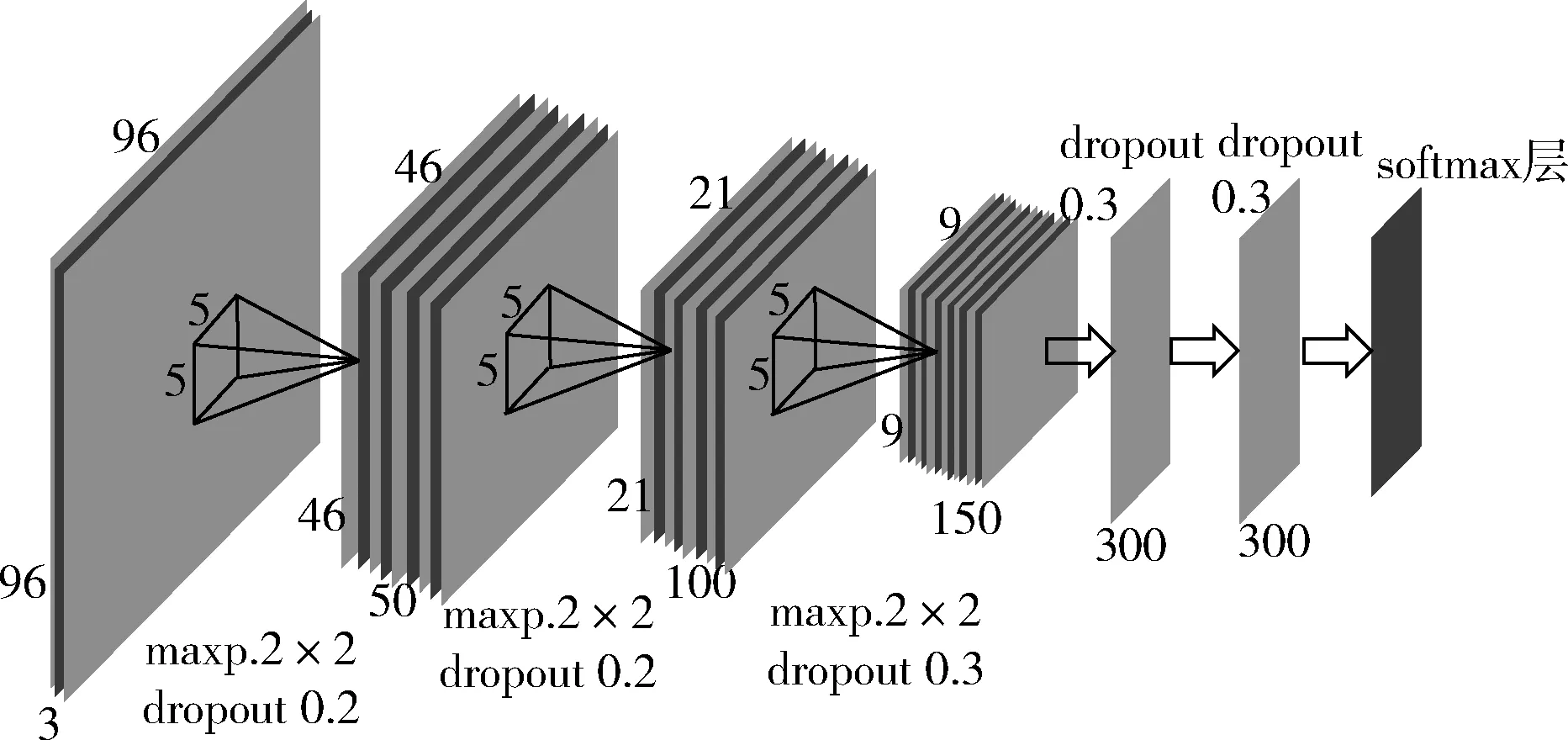
图2 头部姿态估计网络模型
进行卷积时,利用卷积核提取人脸图片特征,通过卷积逐渐将特征抽象化,降低特征的维度使其具有高度可分的特征,便于判断其头部姿态。为了能够预测输入人脸图片头部偏转角度的多个特征,使用卷积核进行操作
(3)
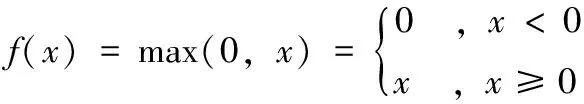
(4)
池化层通过下采样来降低网络的空间分辨率,本文使用最大值池化对特征图进行采样处理,并使用整流线性单元作为激活函数,通过池化有效降低计算的复杂度,提高网络对低分辨输入图像分类的容忍度,其数学表达式如下
(5)
β为权重,down为下采样函数。全连接层通常容易过度拟合,dropout层可以避免过度拟合,softmax层被用作卷积神经网络最后一层的线性分类器,用来区分输入人脸图片的角度,其表达式如下
(6)
式中:I是输入向量,Ci是第i个神经元的相应核向量。Q是Q类对应的神经元总数。输出φ是第i个输入类的概率,预测类包含最高概率值。
2.2 设定人脸初始形状
利用头部姿态信息获得若干个初始形状来提高系统的鲁棒性,头部姿态信息和面部初始形状,将会作为全局信息用于局部对齐,提高局部对齐的性能。将由L个点构成的三维平均人脸形状D映射到二维平面上,用一组向量s={p1,…,pl,…,pL} 表示人脸形状,其中pl=(xl,yl) 表示第l个关键点的二维坐标,生成初始形状
(7)
s0包含头部姿态估计网络中得到5个关键点,R是旋转矩阵,P是正交投影矩阵,θ为头部姿态,U(i,j)是来自均匀分布的采样值,其代表unif(i-j,i+j),εθ和εs表示均匀分布的扰动值,取值分别为εs=0.05s0,εθx=εθy=10°,εθz=5°。由于头部姿态估计网络的初始预测可能包含错误,从均匀分布获得多个初始形状可能有助于增强估计的鲁棒性,通过平均多个初始形状的结果来获得最终估计
(8)
2.3 局部微调
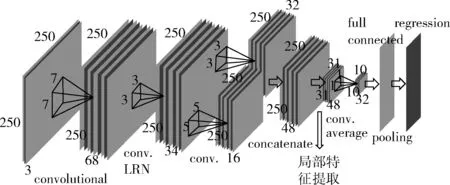
图3 深度回归网络模型
网络的输入为250×250像素的RGB人脸图像,在局部特征提取之前不会减少数据块的长度和宽度,卷积过程中使用线性整流函数作为激活函数来加速收敛。在第二个卷积层采用局部响应归一化(local response normalization,LRN)[1]提高网络的泛化能力。
利用头部姿势信息和面部初始形状来进行局部特征提取,提取局部特征之后经过均值池化层得到特征图,并由全连接层得到面部特征向量,回归层的回归过程相当于最小化下列函数
(9)
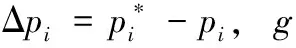
F(x)=xW+b
(10)
W为回归矩阵,b为偏执矩阵,网络训练的过程就是求取回归矩阵W的过程,使用图基的双权重函数作为损失函数,其表达式如下
(11)
式中:a是调谐常数,在训练样本时得到更可靠的调谐常数,通过计算中值绝对偏差(median absolute deviation,MAD)[11]来缩放残差Δp,MAD测量训练样本的可变性
(12)
i∈{1,……,L},L为关键点的个数,M为训练样本的总数,下标j和k对训练样本进行索引,MAD估计用于获得单位方差的残差的比例参数。通过将MAD 与残差进行整合得到
(13)
在这里将MAD 放大1.4826倍,使MAD成为渐近一致的估计量,用于估计标准偏差,并利用MAD缩放来修正调谐常数,所以损失函数中没有参数。局部微调网络的参数最终通过最小化下列目标函数求得
(14)
3 实验结果与分析
为验证本文提出的人脸对齐方法在复杂环境下人脸对齐的效果,在操作系统为Windows10 x64,CPU为i7-6300H,内存为16 G下使用MATLAB 2017编程环境进行实验。
选择300W[12]和COFW数据集,300W数据集包含有AFW、LFPW、HELEN和IBUG共3148个训练样本和689个测试样本,LFPW和HELEN数据集作为普通集(common subset),IBUG数据集作为挑战集(challenging subset),挑战集相比普通集包含更多受遮挡、光照、姿态影响的人脸,COFW中包括500张训练样本和507张测试样本。
使用300W和COFW训练集的3648个样本中已标定的68个关键点创建一个包含头部姿态的数据集,对卷积神经网络进行训练。使训练集产生10个不同方向的抖动,进行镜像翻转后共得到72 960张人脸图片作为训练样本,训练得到最优网络模型,再使用300W和COFW测试集进行实验。
3.1 实验结果评估指标
使用平均速度、平均误差和失败率作为本次实验的评估指标,平均速度以每秒定位的人脸图像数目评估,归一化欧式距离误差得到平均误差error,计算公式如下
(15)
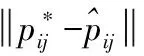
(16)
通过绝对平均误差对头部姿态进行评估,头部姿态有3个方向:滚动角、转动角和平动角用θ表示,定义平均误差如下
(17)
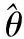
3.2 头部姿态估计对比
选择传统的SVR方法和随机森林方法与本文的卷积神经网络方法在300W测试集下对头部姿态估计作对比,使用HoG特征分别对随机森林和支持向量回归训练模型,随机森林设置为100棵树,HoG提取器的单元大小设置为8×8,实验结果见表1。
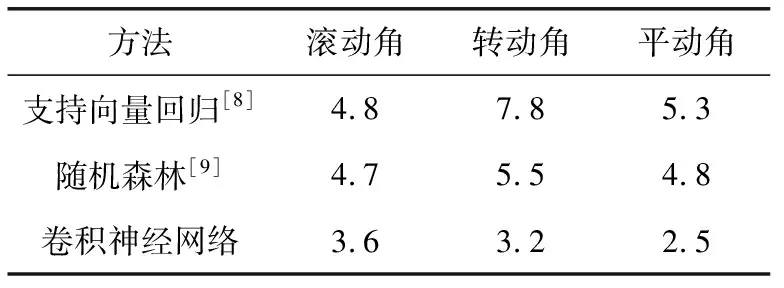
表1 头部姿态估计的平均误差(e×100)比较
从1表可以看出,相比传统的随机森林回归,卷积神经网络方法下的准确度在3个方向上分别提高了25%、41%和 47%,优于传统方法。
3.3 累积误差曲线对比
使用ESR[14]、TCDCN[3]、HPEA[5]和DRN(本文提出的方法),在300W数据集下的普通集和挑战集的累积误差曲线分别如图4、图5所示。
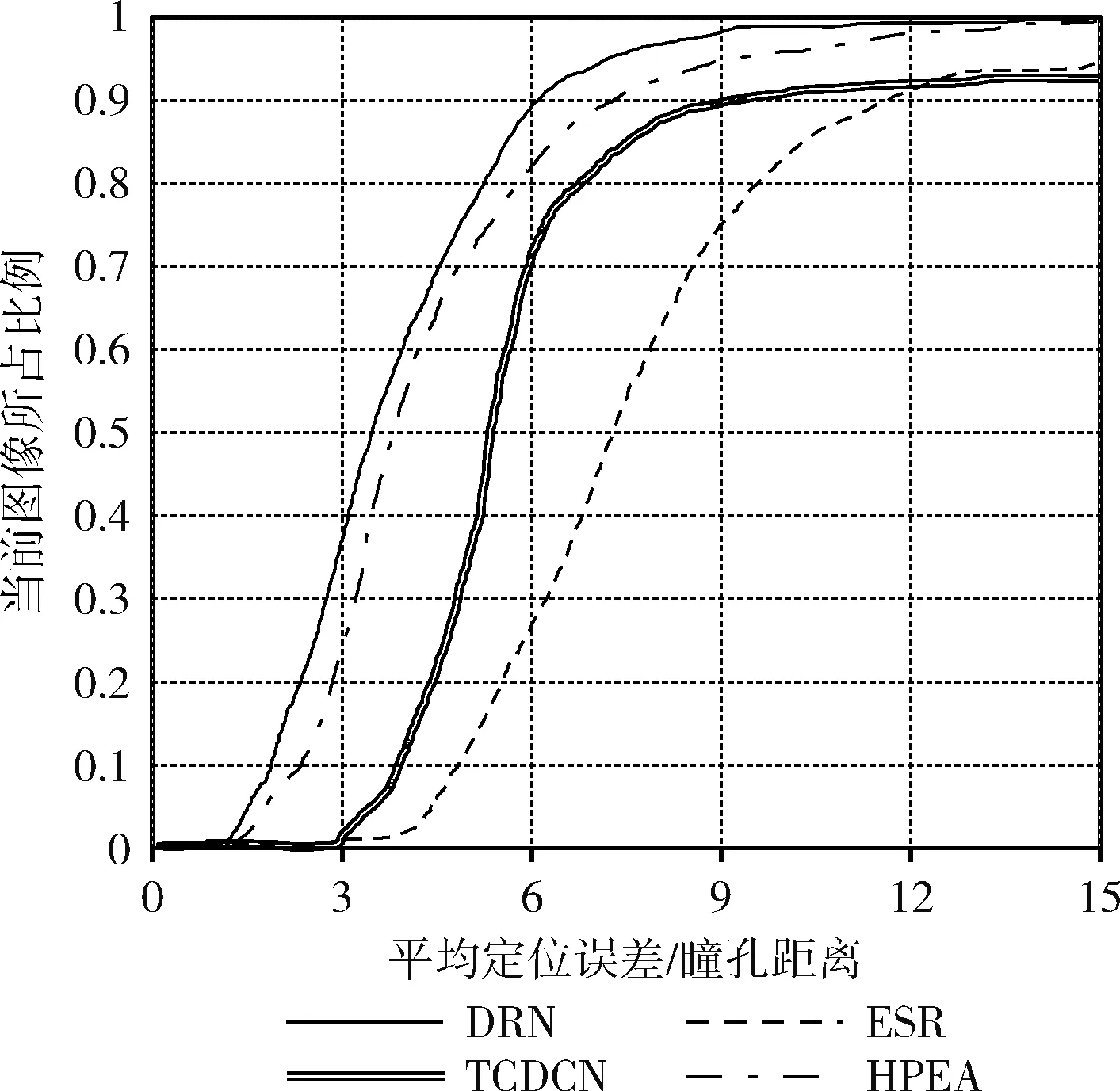
图4 普通测试集下的累积误差曲线
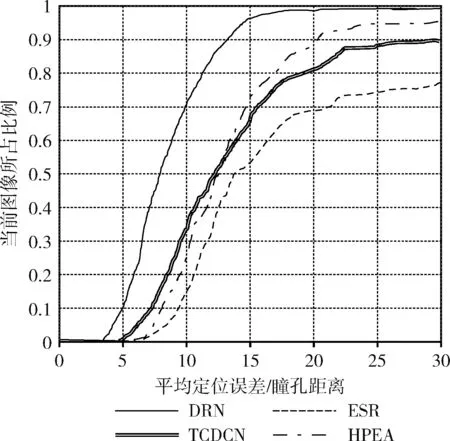
图5 挑战测试集下的累积误差曲线
图4和图5表明DRN方法相比其它几种方法具有明显的优势,尤其在大规模姿态变化和遮挡较多的挑战集下。HPEA方法引入了头部姿势估计辅助对齐,其在普通集中的效果相比另外两种有较好的效果,而在挑战集的效果相对较差,可能是由于挑战集中的人脸大面积遮挡造成的。
3.4 速度与失败率对比
选择300W和COFW数据集,使用不同的方法进行测试,实验结果见表2、表3(error×100)。
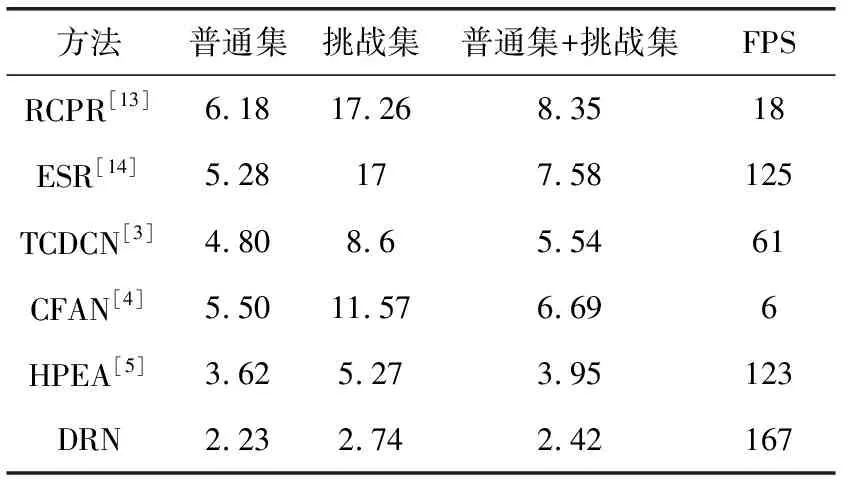
表2 300W数据集下的测试结果
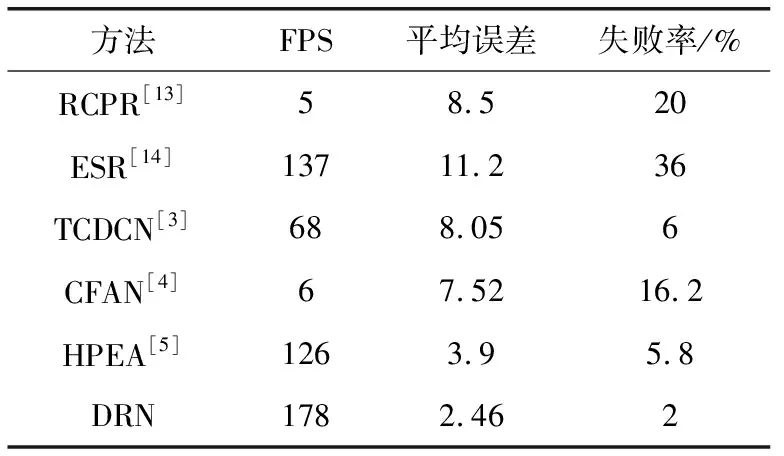
表3 COFW数据集下的测试结果
表2的实验结果表明DRN方法无论在300W中的普通集,还是复杂情况较多的挑战集上其平均误差均低于3,速度可达到167 fps,相比HPEA方法平均误差降低了38.40%~48%,速度提高了35.77%,相比RCPR、TCDCN和CFAN方法有着明显的优势,而CFAN方法由于级联次数较多造成速度较慢。
表3的实验结果表明在COFW数据集下DRN方法的失败率为2%,速度为178 fps,相比HPEA失败率降低了3.8,速度提升了41.27%。虽然TCDCN的失败率也较低,但其速度要远差于其它方法,且平均误差相对较高。ESR方法的算法较为简单所以其速度相对较快,平均误差较高。可以看出DRN方法可以实现复杂环境下的人脸对齐,对面部遮挡、复杂光照、复杂表情和多变的姿态有很强的鲁棒性。
3.5 对齐效果对比
为了进一步将本文提出的方法与已有的方法作对比,从测试数据集挑选了姿态、表情、光照和遮挡等较为严重下的人脸图片,选择ESR、CFAN、HPEA和本文提出的DRN方法进行测试,测试结果如图6所示。
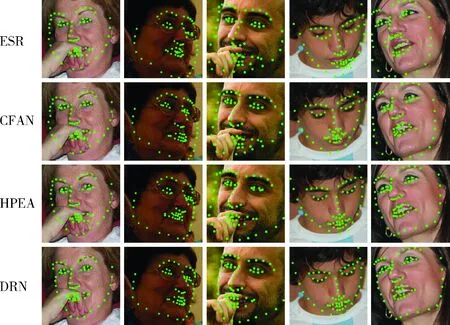
图6 对比测试效果
由图6可以看出,ESR人脸对齐方法,在人脸受到遮挡的情况下对齐效果明显降低,且极易受到人脸姿态的影响。CFAN人脸对齐方法,在复杂的环境下能实现基本的人脸对齐,然而对齐的准确度较低,非常容易受到面部表情的影响。HPEA人脸对齐方法与ESR和CFAN方法相比有较好的对齐效果,但与本文提出的DRN方法比较,在对面部姿态和复杂表情下的人脸进行对齐时,DRN有明显的优势。与ESR、CFAN、HPEA人脸对齐方法相比,本文提出的DRN方法相对较稳定,在复杂环境下也能实现精确的对齐效果,具有较强的鲁棒性。
图7为利用DRN方法对IBUG数据集进行测试的效果图,其中还包括头部姿态信息,从图中可以进一步看出DRN方法能够实现精确的人脸对齐。

图7 对齐效果
4 结束语
本文针对复杂环境下的人脸对齐,提出了一种使用深度回归网络实现人脸对齐的方法,通过使用卷积神经网络得到头部姿态的信息进而预测到面部的大致形状,减小了头部姿态造成的影响,利用初始人脸形状在深度回归网络下结合全局信息进行回归微调,减少面部遮挡的影响,实现了复杂环境下的人脸对齐,使用图基的双权重函数作为训练网络的损失函数提升了网络的性能。实验结果表明,该方法相比现有的人脸对齐方法,在速度和精度上有明显的优势,具有很强的抗干扰能力,但本文提出的方法对复杂光照下的人脸难以实现精确对齐,后续将会对该问题进行深入研究。
