基于语义和句法依存特征的评论对象抽取研究
2018-07-18张志远
张志远,赵 越
(中国民航大学 计算机学院,天津 300300)
0 引言
随着移动互联网和电子商务的快速发展,网络购物在人们的生活中越来越普遍。在购买商品之前,人们通常会浏览以前用户发表的评论,了解其优劣后再做决定。分析这些评论数据并了解其中的褒贬态度可为商品购买者提供参考依据,同时对于商家了解自身所售商品情况、提高商品质量、提升服务水平也具有非常重要的意义。评论数据大多为文本形式,由于文本评论的数据量巨大,信息的实时性、不规范性强,仅靠人工方法很难快速地抽取用户的观点信息。因此涉及信息检索、自然语言处理、机器学习等技术的情感分析应运而生[1]。本文主要研究情感分析中的评论对象抽取问题。评论对象是指评价词所修饰的实体本身或者实体属性[2],抽取评论对象是挖掘数据深层价值的基础,因为单条评论中可能涉及褒贬不一的多个评论对象,只有确定了评论对象后才能进行更准确的情感分析。例如,句子“The food of this restaurant is good,but not the service.”中对餐厅食物的评价是正面的,而对其服务的评价则是负面的,不能简单地对整句话进行情感判定。
本文使用条件随机场模型,通过引入语义和句法依存关系特征抽取评论对象,在SEMEVAL竞赛的评测数据中取得了不错的效果。尽管涉及某一领域的评论对象非常多,但其一般都可归纳为几个少量的类别,例如,对于餐厅而言,不管评论对象是pizza还是chicken,都属于food的范畴,两者在语义上都和food相近,因此如果pizza是评论对象的话,则chicken很可能也是。本文设计了七种语义相似性特征用于抽取评论对象。另外,由于评价词一般都带有丰富的情感色彩,同时评论对象和评价词之间通常存在某种句法依存关系,如“The food of this restaurant is good.”中评论对象“food”和评价词“good”之间是主谓关系,“Very nice hotel for business travelers.”中评论对象“hotel”和评价词“very nice”之间是形容词修饰关系等,因此根据评价词和句法依存关系就很可能找到评论对象。
1 相关工作
本文研究点来自于SEMEVAL竞赛*http://alt.qcri.org/semeval2016/,SEMEVAL竞赛主要关注不同的文本分析任务,例如,情感分析、语义消歧、关键词抽取等。其中“Task 12: Aspect Based Sentiment Analysis”提供了评论对象抽取研究所需的数据和参赛者的研究成果。本文主要研究从评论文本中获取用户的评论对象,属于情感分析中的观点挖掘部分[3]。评论对象抽取一般采用有监督的方法,目前应用较多的是基于条件随机场的序列标注方法,不同之处仅在于文本特征的选择。Jakob和Gurevyc[4]首次将评论对象抽取问题建模成序列标注问题,采用条件随机场模型,选取基本的词形、词性等作为文本特征,在电影评论中获得了较好的抽取效果。Toh和Wang[5]通过句法依存分析,总结出评论对象与评价词之间常见的依存关系,如主谓关系,虽然获得了不错的效果,但这些依存关系连接的双方并不一定是评论对象和评价词,也可能是陈述事实,并没有评价色彩。Hamdan[6]等人在词形、词性基础上,加入了形态特征(如单词的前后缀、大小写、是否包含符号数字等)、词根以及情感分数,但单个特征的抽取效果并不显著,且特征数量偏多。徐冰、赵铁军等[7]通过对评论文本进行浅层句法分析,标注出句子中每个词对应的语块,即名词短语、动词短语等,由于语块边界偏大,导致一定程度上影响了系统的性能。Toh和Wang[5]则引入了“Head Word”概念,在语言学中短语的“Head Word”决定短语的句法范畴,如决定“a good place”为名词短语的“place”就是“Head Word”,但只适用于抽取单词级别的评论对象。杜丽萍、李晓戈[8]利用基于词语共现的互信息(PMI)来识别评论对象,优点是没有限制评论对象的边界,克服了浅层句法分析和“Head Word”的缺点,但PMI需依赖较大规模数据集,在小规模数据集上的泛化性能较差。Vicente和Saralegi[9]等人则在词形、词性的基础上加入了聚类特征,效果提升明显,但聚类特征必须依赖大量的同领域外部数据集才能得到比较好的效果,且聚类特征的获取时间会因聚类算法的复杂度和数据量的增大而耗时严重。在2016年的SEMEVAL比赛中,Toh和Su[10]使用循环神经网络(RNN),将评论文本的词向量作为RNN的输入,将RNN的隐藏层值与聚类特征结合,但其最终效果与传统序列标注模型相比仍存在差距。本文使用传统的序列标注模型,结合“评论对象与评价词之间的依存关系”和“情感分数”,提出一种新的“句法情感依存特征”抽取方法,使得提取到的依存关系更加精确;并首次从语义角度出发,提出六种新的评论对象语义特征。两种新特征在不同领域数据上的准确率、召回率及F1分数均高于SEMEVAL比赛最好的成绩。
2 语义及句法依存特征
2.1 语义特征
充分理解评论对象的语义是准确抽取评论对象的关键。以英文语义词典WordNet为基础,借助词网中的上下位和同义关系,提取评论对象的语义特征。与以往研究[11]中的语义特征不同的是,本文更注重研究与评价对象相关的语义特征,即考虑到评论对象与其领域信息的密切联系,充分利用每种领域数据独有的视角,同时考虑到上下文的语义环境,更有效地提取短语级别的评论对象。图1展示了单词“risotto”“pizzza”“battery”“screen”“drive”作为名词时,在WordNet中的上下位信息及同义信息。我们认为词语的上位词中隐含着一定的视角信息,如“food”是餐厅评论中的主要视角,而“risotto”和“pizza”的上位词中就存在“food”,因此它们很可能是评论对象。另外,同义词意味着同类事物,如果“hard drive”是评论对象,则与其同义的“RAM disk”很可能也是评论对象。

图1 部分单词在WordNet中的连接关系
基于上位词及同义关系提出两个语义特征S1和S2,如表1所示。
可以看出,单词的上位词和同义词并不唯一,例如,对于“pizza”的三个上位词“dish”“nutriment”和“food”来说,我们更关心第三个上位词“food”,因为它才是餐厅评论数据中的重要视角之一。本文对训练集中的所有标签进行提取,将所有评论对象单词化,去除停用词,即构造一个评论对象词典。运用WordNet找到所有评论对象单词的父节点和兄弟节点,并统计其频率,策略是选择高频率父节点和兄弟节点。
对于高频率父节点出现在同一路径上的情况,例如,“dish”“food”“nutriment”,优先取频率最高的父节点作为视角词,其余则不列入视角词集。若频率相同,则取其中最靠近词网边缘的父节点,使父节
点涵盖的语义范围更精确。最终取出频率最高的七个上位词列入语义相关视角词集。取兄弟节点频率最大的前七个单词作为语义相似性视角信息,频率较高的兄弟节点代表最常出现的评论对象。
其中餐厅的语义相关性视角为“restaurant”“food” “cut”“plant”“pasta”“condition” “attendant”,语义相似性视角为“pizza” “potato” “place”“atmosphere”“cake”“carte” “salad”;电子产品领域语义相关性视角为“process” “system” “quantity”“move”“device”“property” “business”,语义相似性视角为“business” “function” “software”“picture”“memory”“screen” “computer”;旅馆领域语义相关性视角为“furniture” “attendant” “region”“meal”“room”“building” “condition”,语义相似性视角为“place” “check”“business”“bed”“breakfast”“room” “bath”。
基于此,提出两个视角语义特征S3和S4,如表1所示。其中语义相关度S3的计算采用Michael E.Lesk[12]提出的lesk算法,即两个单词在WordNet中词义解释的重复程度,例如,“pizza”和“food”的重复数为31。语义相似度S4的计算采用Leacock和Chodorow[13]提出的lch算法,如式(1)所示。
(1)
其中,Dist(wi,wj)代表两个单词在WordNet中的最短路径上节点的个数,D为常量16,即WordNet中名词的最深层次。算法规定,属于同一个同义词集的两个词Dist(wi,wj)为1。
除单词级评论对象的语义信息外,还需考虑单词与上下文的语义关系,用于抽取短语级别的评论对象。不同于基于句法的浅层句法分析[7]和基于词语共现的PMI[8]方法,本文从语义出发,研究上下文环境中语义特征在评论对象抽取任务中的影响和效果,提出基于语义相关/相似度的上下文特征S5和S6,如表1所示。

表1 评论对象的语义特征
2.2 句法依存特征
句法分析揭示语言的内部结构,它显示句子中可能存在的各种谓语论元的依存关系[14]。由于使用机器学习方法对领域数据进行建模,单纯考虑语义特征很可能导致模型与领域数据的过拟合,而忽略评论文本特有的句法结构,例如评论文本表述简短或句法不规范的情况。因此,对文本进行句法依存特征提取,可有效解决模型与领域数据过拟合问题,增强模型的泛化能力。
以往研究中的句法依存特征提取存在以下问题: 第一,默认评价词是形容词,只考虑名词与形容词之间的句法依存关系,忽略了其他词性作为评价词的可能[15];第二,使用常见的依存关系分析所有的评论文本,导致不含任何情感的陈述性语句也被考虑在内[5];第三,借助只标识正或负的情感词典找到评价词,但并没有为不同情感程度的评价词赋予不同权重,导致微情感词干扰最终的评论对象抽取效果[16]。针对以上问题,本文提出了句法情感依存特征,首次将句法依存分析和评价词识别结合,提取评价词与评价对象之间句法依存关系,从而更精确地找到评价对象。
例句“I like the samosas.”的整体句法依存关系如图2所示,其中“dobj”代表“直接宾语”。
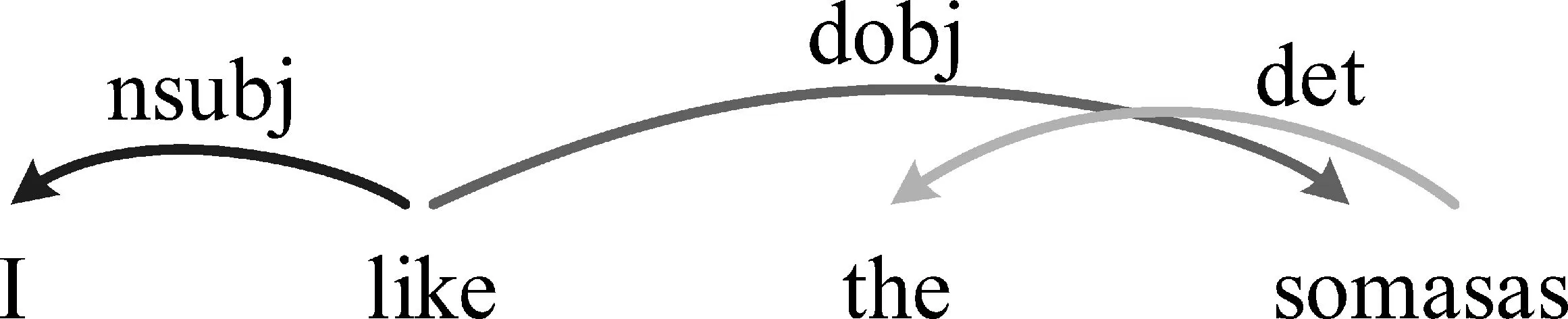
图2 句法依存关系示例
可以看出,“dobj”所连接的“like”和“somosas”正是评价词和评论对象。基于对自然语言的理解,评价词与评论对象的关系还有可能是D={“iobj”,“nsubj”,“nmod”,“amod”,“comp”,“compound”},分别代表“间接宾语”“名词性主语”“名词修饰”“形容词修饰”“补足语”以及“名词复合语”。
仅考虑以上依存关系并不能精准地提取评价词与评论对象之间的依存关系,如“The restaurant has pizza.”并没有评论任何事物,只是陈述事实,但却有“dobj(has,pizza)”。为避免这种情况,在上述可能的依存关系基础上,需找到包含评价词的依存关系。
由于评价词在某种程度上蕴含着评价者的情感,所以本文借助情感词典进行评价词的判定。SentiWordNet[17]是一个用于观点挖掘的情感词典,它为每一个同义词集分配三个情感分数: 正向分数,负向分数和客观分数,三者之和为1。SentiWordNet按词性不同分配了不同的分数,并对同一意义下的不同单词进行排名。表2为单词“great”在SentiWordNet中的分布情况。例如,第1行代表great作为形容词时的第四种解释是“非常好”(great#4 very good),该义项下还有not_bad,nifty等单词。
本文根据SentiWordNet中单词的义项分布,使用基于权重的单词情感分数计算方法,如式(2)所示。
(2)
其中,score(wip)表示当单词wi在句中词性为p时的情感分数,本文只考虑形容词(a)、名词(n)和动词(v);nwip表示单词wi词性为p时的义项个数;Pr和Nr分别表示当单词wi词性为p且排名为r时的正向情感分数和负向情感分数,例如“great”的词性为“a”,并且排名为3(“great#3”)时,Pr和Nr都等于0.25;r代表排名,1/r代表权重。该文比较了基于权重的单词情感分数计算方法与传统情感分数计算方法[18],实验结果表明基于权重计算规则的评论对象抽取效果更好。

表2 单词“great”在 SentiWordNet中的义项分布
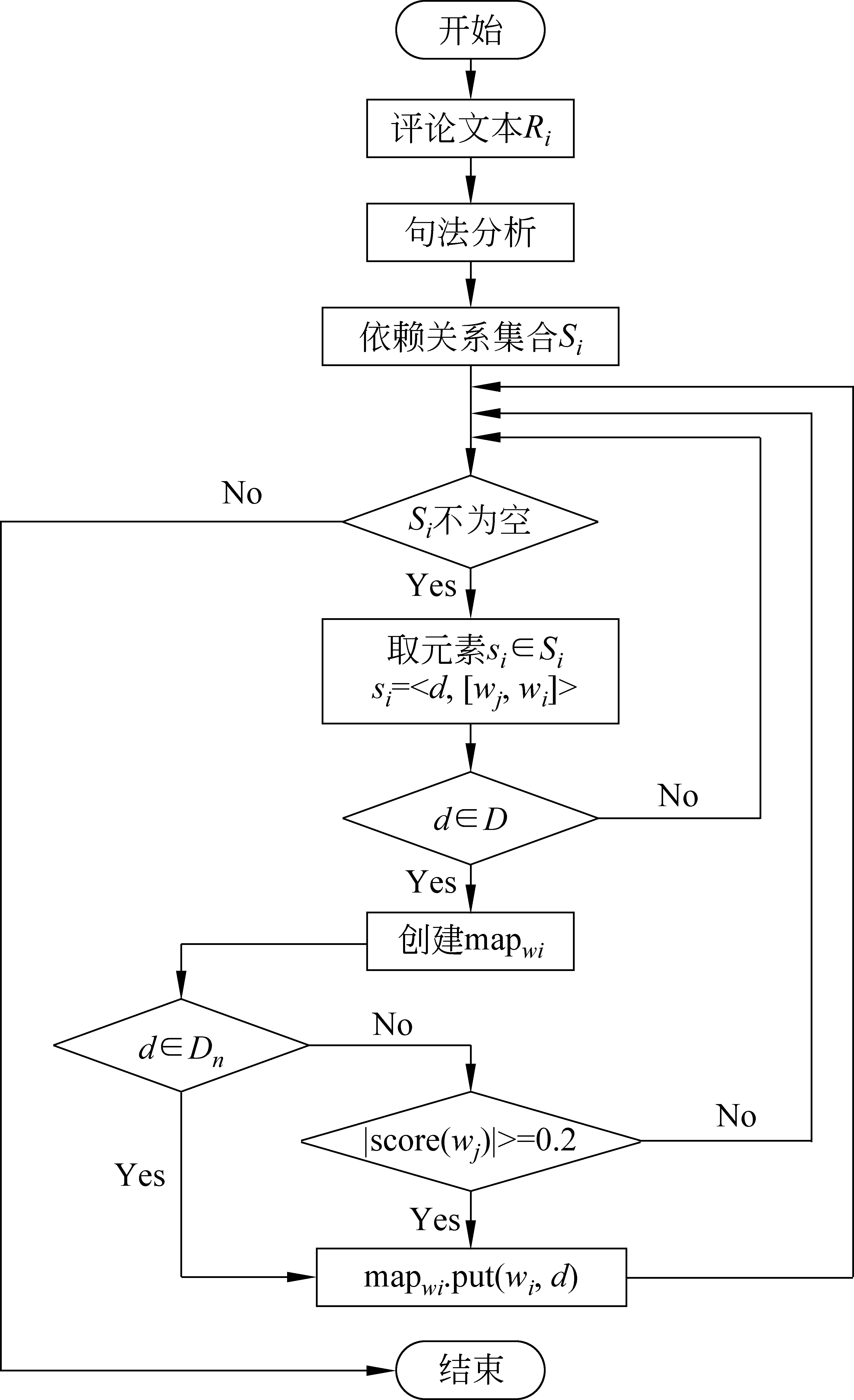
图3 句法依存特征的抽取过程
由于这种计算方法并不依赖上下文,若词语本身是正向词,但前面有否定词修饰的话,则计算的情感分数会产生较大偏差。为此采用Christopher Potts的否定区域标注算法[19]对否定词之后,标点符号(; ,. ! -)之前的词语情感进行取反,即“not great”中“great”的分数为-0.26,不再是0.26。句法依存特征的抽取过程如图3所示,其中Dn={“nmod”,“ncomp”,“compound”},分别表示名词修饰、名词补语和多个名词组成的复合短语,由于其一般不存在评价词修饰(如下句中的“wine list”),所以不需要计算情感分数。针对当前词每个可能的依存关系,为避免微程度情感词的干扰,只考虑对应词情感分数大于0.2或小于-0.2的依存关系。例如,“The wine list is interesting and has many good values .”中的评论对象为“wine list”和“values”,评价词为“interesting”和“good”,对比情感分数: 0.0,0.0,0.0,0.04,0.38,0.0,0.05,0.0,0.63,0.13,可以看到距离评论对象“wine list”最近的情感词是“is”,但“interesting”才是真正的情感词。针对上述例句,算法的提取结果为“compound(list,wine)”,“nsubj(interesting,list) ,amod(values,good)”,不仅包含了评价对象和评价词,对应的依存关系也可解释,并且避免了“dobj(has,values)”和“amod(values,many)”的干扰。
3 实验设置与结果对比分析
3.1 数据预处理及实验设置
本文的训练数据、测试数据以及评价系统均来自SEMEVAL竞赛。由于竞赛旅馆数据量较少(527条),因此在评论网站Yelp*https://www.yelp.com/sf上进行旅馆评论爬取,对旅馆数据量进行扩充,并使用MMax*http://sourceforge.net/projects/mmax2/files/对评论对象进行标注。数据信息如表3所示。
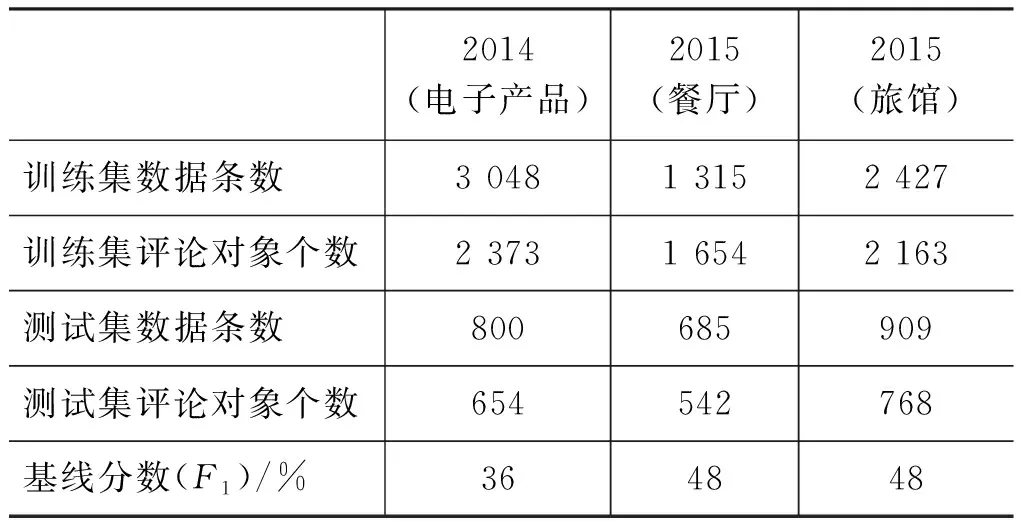
表3 历年SEMEVAL比赛数据
原始数据为XML格式,使用Stanford NLP Corenlp对评论文本进行分句、分词和句法分析。由于系统分词过细,可能将一些重要信息分开,例如“$30”会被分成“$”和“30”,这样一个代表钱的单词就被分成了单纯的符号与数字,在编码XML文件时我们将其重新组合成一个词。其次,实验中未去除停用词,因为停用词本身有可能是评论对象的一部分,如“tuna of gari”中的“of”。
实验中将词形、词性、前后缀作为基础特征(记为B1),并在特征模板里为词形和词性设置Unigram、Bigram和Trigram,其他特征设置Unigram,窗口大小为4。
本实验的评价标准是准确率、召回率和F1分数。2014年和2015年的基线F1分数分别为36%、48%和48%。由于SEMEVAL比赛中并没有提供参赛者在旅馆数据上的测试结果,只给出了基线分数,所以本文只与基线进行比较。
3.2 结果对比分析
表4显示了在B1中分别加入单个语义特征(S1-S6)及句法情感依存特征(D1)后的评论对象抽取结果,以及和其他特征的对比。对比特征包括: 词根(文献[4],记作M1)、headword(文献[3],记作M2)、句法依存(文献[3],记作M3)、情感分数(文献[4],记作M4)、浅层句法分析(文献[5],记作M5)和PMI(文献[6],记作M6)。可以看出,所有特征的结果均优于基线和基础特征,且本文特征除电子产品数据中的准确率低于M5,旅馆数据中准确率低于M1,其他评价标准均高于对比特征。
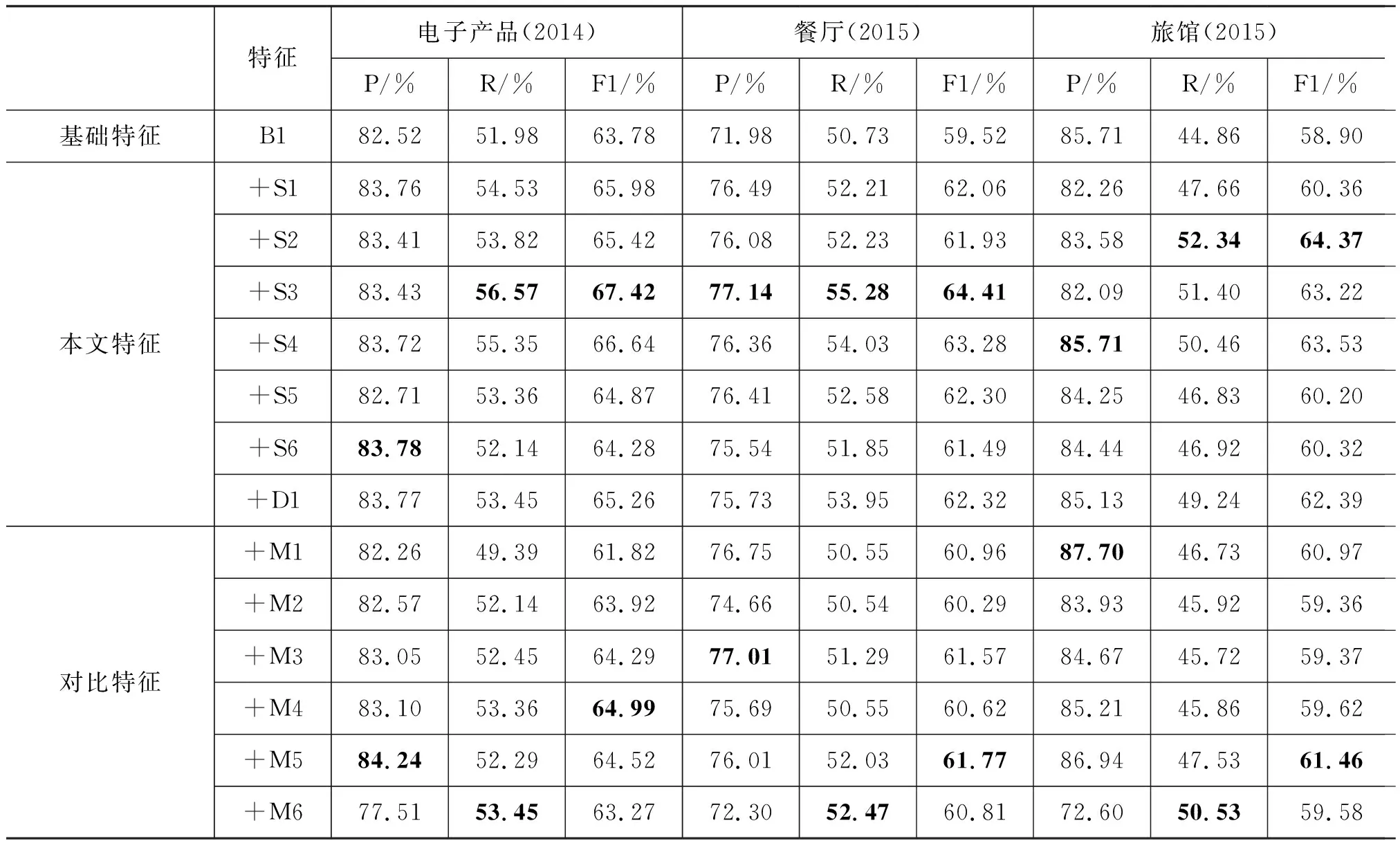
表4 基于基础特征的单个特征测试结果
在电子产品数据中,本文特征准确率较B1提高1%~2%,召回率较B1提高1%~4%,F1分数提高1%~3%;餐厅数据中,准确率较B1提高2%~5%,召回率较B1提高1%~4%,F1分数提高1%~4%;旅馆数据中,召回率较B1提高1%~8%,F1分数提高1%~6%;从表3可以看出,电子产品数据量是餐厅数据的2.3倍,这说明当数据量明显降低时,本文特征表现仍良好,当数据量增大时,各项指标平稳上升。
视角语义相关性特征S3在电子产品和餐厅数据集中的F1分数最高,在电子产品数据中的F1分数较B1高3.64%,较对比特征的最优值高2.43%;在餐厅数据集中的F1分数较B1高4.89%,较对比特征的最优值高2.64%。在旅馆数据集中S2的F1分数较B1高5.47%,较对比特征的最优值高2.91%。注意到S3和S4在电子产品和餐厅数据中的召回率和F1分数是所有特征中最高的,在旅馆数据集中各项指标仅次于S2。这是由于利用语义网自动选取的视角词覆盖了大部分评论对象的范畴,因此基于视角的语义特征能提高召回率,与预期结果一致。
从抽取评论对象是单词还是短语的角度来看,M1、M2主要用于抽取单词级别的评论对象,但其F1分数比S1、S2低2%~3%。这也在情理之中,因为基于上位词和同义词的S1和S2比基于词根的M1包含了更多的语义信息。M5、M6、S5和S6主要用于抽取短语级别的评论对象,其中S5的F1分数略高于M5和M6,S6的F1分数高于M6但低于M5。M5基于浅层句法分析特别是组块分析,用于发现短语级别的评价对象,而M6基于PMI,在小规模数据集上表现欠佳。
将所有的特征进行组合测试,结果如表5~表7所示。在电子产品数据中,语义和句法情感依存特征组合使B1准确率上升3.91%,召回率提高7.22%,F1分数提高6.49%,说明预测数量和预测正确的数量都大幅增加。在餐厅数据中,语义和句法情感依存特征组合使B1准确率上升6.44%,召回率提高6.1%,F1分数提高6.38%。在语义特征的基础上,加入句法情感依存特征可进一步提高系统性能。在旅馆数据中,语义和句法情感依存特征组合使B1召回率提高9.35%,F1分数提高7.38%。虽然SEMEVAL比赛中并没有提供旅馆数据的测试结果,但不难发现,本文特征组合的F1分数较之基线分数高出18%,且在三个领域数据中F1分数表现平稳。

表5 2014年电子产品数据特征组合及结果
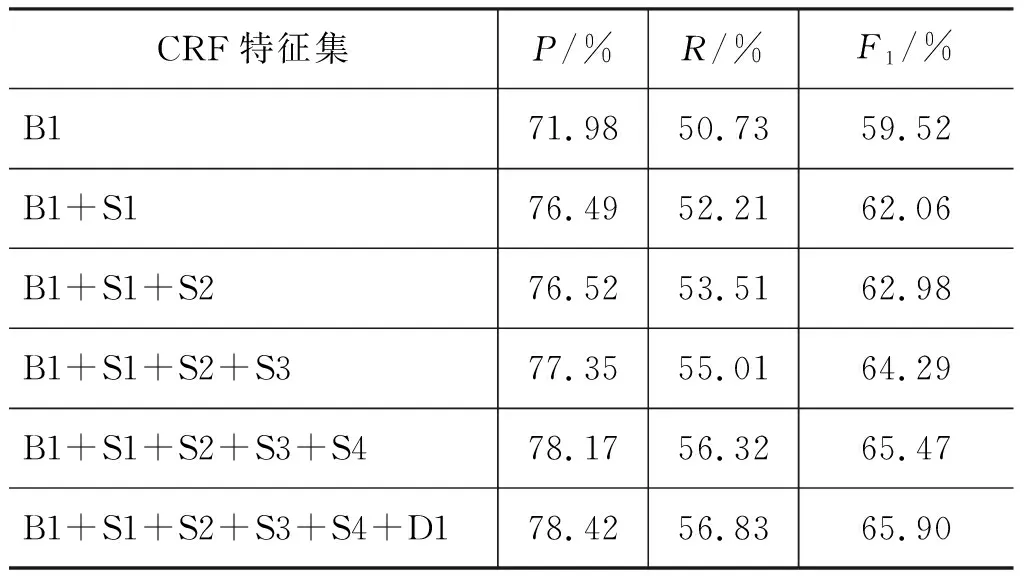
表6 2015年餐厅数据特征组合及结果
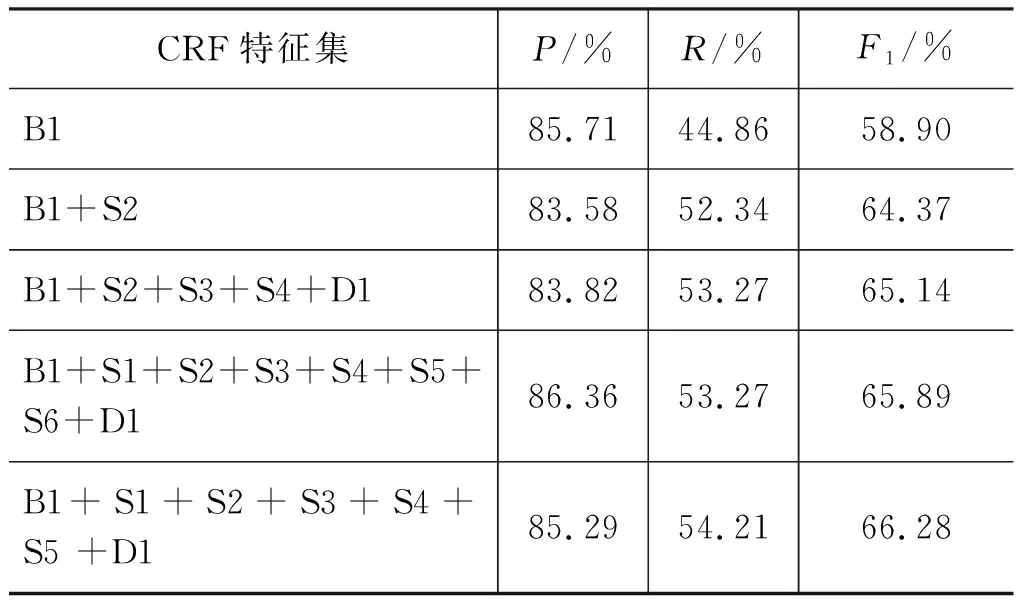
表7 2015年旅馆数据特征组合及结果
条件随机场模型的实现采用CRF++0.53,基于最终特征组合进行参数调优,效果详见表8。其中参数a代表训练算法选择,默认是CRF。参数c设置CRF的hyper-parameter。c的数值越大,CRF拟合训练数据的程度越高。参数f设置特征的cut-off threshold。训练数据中至少出现f次的特征,默认值为1。参数m设置CRF中LBFGS算法的迭代次数,默认为10K。参数H设置迭代变量达到最优前的收缩值,默认为20。
需要说明的是,SEMEVAL竞赛中有两种评价对象系统设计,一种是非限制性系统,即所选特征可以依赖大量外部领域数据或语料,如聚类、词向量等,反之则是限制性系统。如表9所示,电子产品数据中,本文最终参数调优特征组合结果的F1分数分别高出SEMEVAL竞赛限制性系统最好成绩4.34%。餐厅数据中,组合结果的F1分数分别高出SEMEVAL竞赛限制性系统最好成绩3.23%。
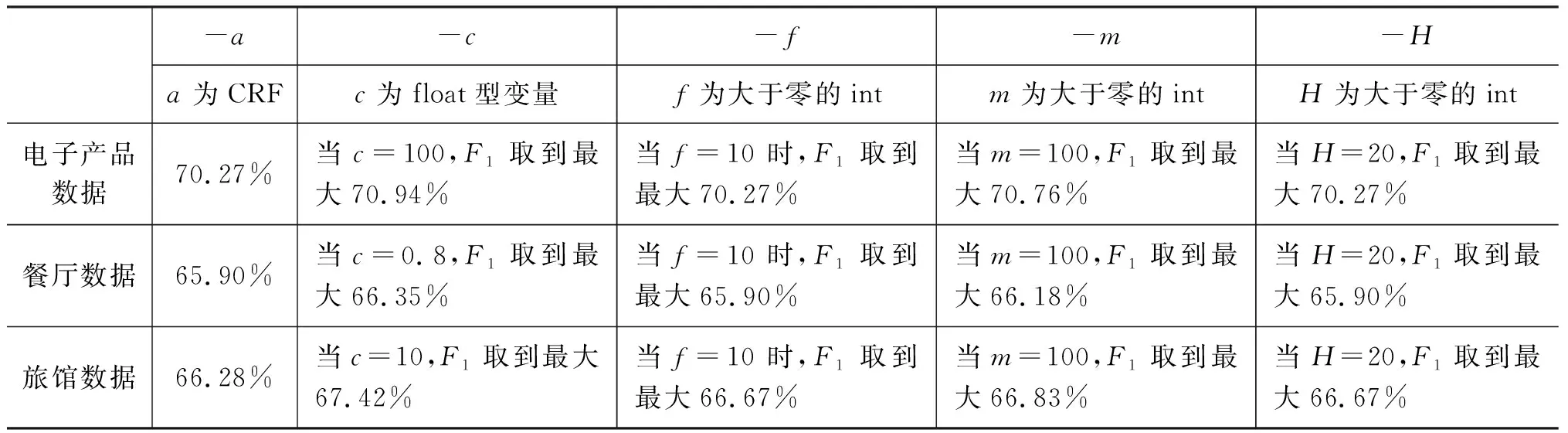
表8 特征组合参数调优结果
为证明本文特征的稳定性和优势,表10显示了加入聚类特征(Brown聚类和K-Means聚类),即变为非限制性系统后的评论对象抽取结果。与SEMEVAL竞赛非限制性系统最高分相比,电子数据高出1.8%,餐厅数据高出2.57%。并且数据分别属于三个领域,所以视角语义特征可灵活应用于不同领域数据上进行评价对象抽取。
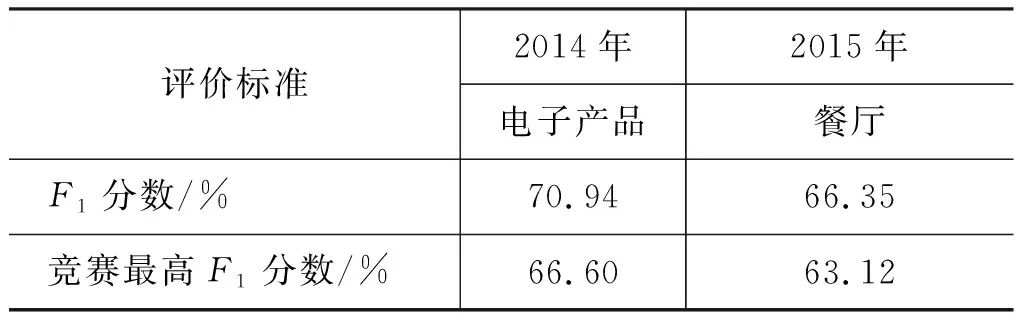
表9 2014—2015年限制性系统与该文结果比较
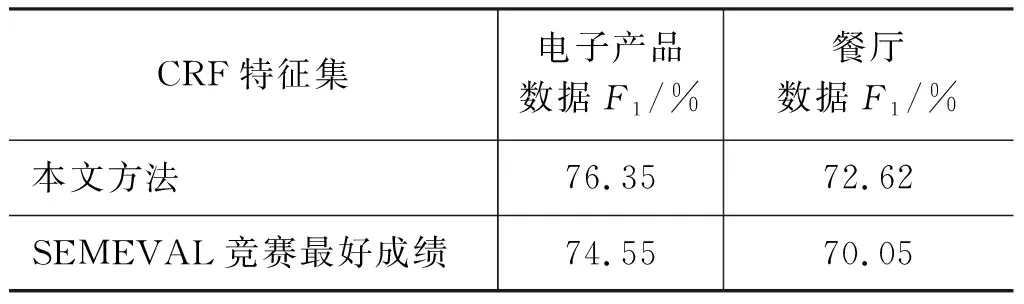
表10 2014—2015年非限制性系统与本文结果比较
4 结束语
本文重点提出了两种新的评论对象抽取特征: 评论对象语义特征和句法情感依存特征。在基于条件随机场的多评论对象抽取过程中,两种特征对抽取结果均有不同程度的提高,其中基于视角的语义特征表现最为突出。针对SEMEVAL竞赛中电子产品、餐厅和旅馆评论数据,两种特征的组合均取得了较好的结果,无论是限制性系统还是非限制性系统,均优于竞赛最高成绩,说明正确理解单词含义在评论对象抽取过程中的作用明显。
